


please indicate the source when reprinting it, please indicate the source: The path to the growth of the back-end system architecture of the News APP - High-availability architecture design
Due to work arrangements, some seniors from the original APP backend were transferred to other business departments. They began to take over the client backend work at the end of 2015. Entering the Holy Land for the first time was like entering purgatory.
At that time, because there was still a lot of business development work at hand that needed the continued support of my friends, I had no choice but to break into APP back-end development alone.
From content business development, which I used to be comfortable with, to APP back-end interface development, I still don’t know a lot of professional knowledge about APP. I can only consult and learn from my classmates on the end. At the same time, I would like to thank my classmates on the end for their help. help. Despite facing various difficulties, the business will continue to move forward, and version iterations are still in progress.
In this way, I was coding and fixing bugs every day while dealing with the various needs of more than a dozen beautiful product girls.
The old API was developed in early 2012. By the end of 2015, it had been handled by four groups of people in nearly four years. You can imagine how many pitfalls there were. It was common to get up in the middle of the night to fix online bugs.
At the same time, the performance problems of the old API were not optimistic. The interface response time was measured in seconds. The business scale was still small at that time, and the original developers did not pay special attention to service architecture and optimization. As the number of users grows rapidly, once PUSH is launched, the service will be down, and we have no choice but to carry it out. In this way, while supporting intense version iterations, while stepping into and filling pitfalls, and of course silently digging holes, this lasted for more than a month.
After fully understanding the entire old API code, I found that within four years, dozens of versions of the APP had been released. The original excellent code written by the masters and seniors had been changed beyond recognition by several waves of people in four years. It seriously violates the original intention of the design. The API code is all version code compatible, and there is no separation between versions. There are more than ten IF ELSEs in a single file, and it can no longer be expanded. It can be said that one hair can affect the whole body, and just adjust a few lines of code. This may cause the overall service of all versions to be unavailable. If it continues to be maintained, it can only last for a year and a half or even less. However, the longer the time, the more chaotic the business code will be, and it will face a more passive state by then.
If you don’t change, it won’t last long! We can only make up our minds and completely reconstruct!
However, business development and version iteration cannot stagnate. I can only transfer two classmates from the original content business development to continue to support the development of the old API. At the same time, I began to investigate the design of the new interface architecture.
Due to lack of experience and limited skills in APP development, I started to find a blank in interface reconstruction. I stayed up late and wrote several sets of frameworks for two consecutive weeks. I discussed with my classmates during the day and found various problems and overturned them one by one.
I had no choice but to look up various information, learn from the experience of major Internet applications, and visit famous teachers at the same time [Thanks to: @青哥, @雪大夫, @京京, @强哥 @太哥 and friends on the APP and WAP sides. Guidance], through a lot of learning, I slowly developed an overall plan for the entire new interface architecture construction idea, and I feel like I have seen the light of day.
After a week of working day and night, I have initially built the overall frame structure. I am working non-stop and don’t dare to stop, so let’s start leading my friends to work!
Although we have a general idea of the overall design, the interface reconstruction is also facing big problems, and it requires the full support of APP, product, and statistics students to proceed.
The new interface is completely different from the old interface in terms of calling method and data output structure, resulting in a large number of modifications to the APP code [Thanks @Huihui @明明 for your support and cooperation]
Of course, statistics also faces the same problem. All the interfaces have changed, that is, all the original statistical rules need to be modified. At the same time, I would also like to thank [@婵女@statistics department @product classmates] for their strong cooperation. Without the support of both ends, products, and statistics, the progress of the interface reconstruction work would be impossible. At the same time, we would like to thank all leaders for their strong support to ensure that the reconstruction work proceeds as scheduled.
The new interface is mainly designed from the following aspects:
1, security,
1>, Add signature verification to interface requests, establish an interface encryption request mechanism, generate a unique ID for each request address, and use two-way encryption on the server and client to effectively avoid malicious interface brushing.
2>, Registration system for all business parameters, unified security management
2, Scalability
High cohesion and low coupling, forced version separation, flat development of APP versions, while improving code reusability, small versions follow the inheritance system.
3, Resource Management
Service registration system, unified entrance and exit, all interfaces need to be registered with the system to ensure sustainable development. Provide guarantee for subsequent monitoring and scheduling downgrade.
4. Unified cache scheduling and allocation system
The new interface was launched as scheduled with the release of version 5.0. I thought everything would be fine, but who knew that a big pit had been waiting for me silently in front.
The APP has a PUSH feature. Every time a PUSH is issued, a large number of users will be instantly recalled to visit the APP.
Every time the new interface sends PUSH, the server will hang up, which is tragic.
Fault performance:
1. php-fpm is blocked, and the overall status of the server is normal.
2. nginx is not down and the service is normal.
3. Restart php-fpm. The service will be normal for a while, but will die again after a few seconds.
4. The interface responds slowly, or times out, and the app refreshes without content
Troubleshooting guesses
At first I doubted the following questions,
1. MC has a problem
2. MYSQL is slow
3. Large request volume
4. Some requests are old interfaces of the proxy, which will cause the requests to double
5. Network problem
6. Some dependent interfaces are slow and drag the service to death
However, due to the lack of log records, no basis was found.
Problem tracking:
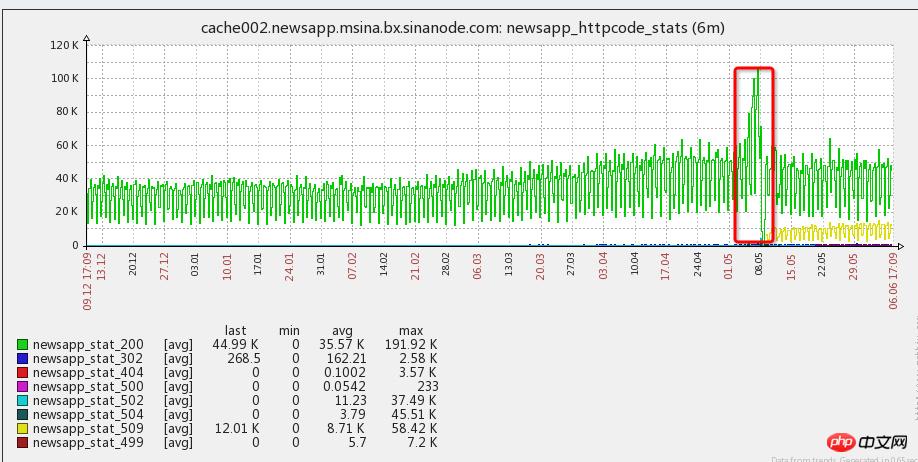
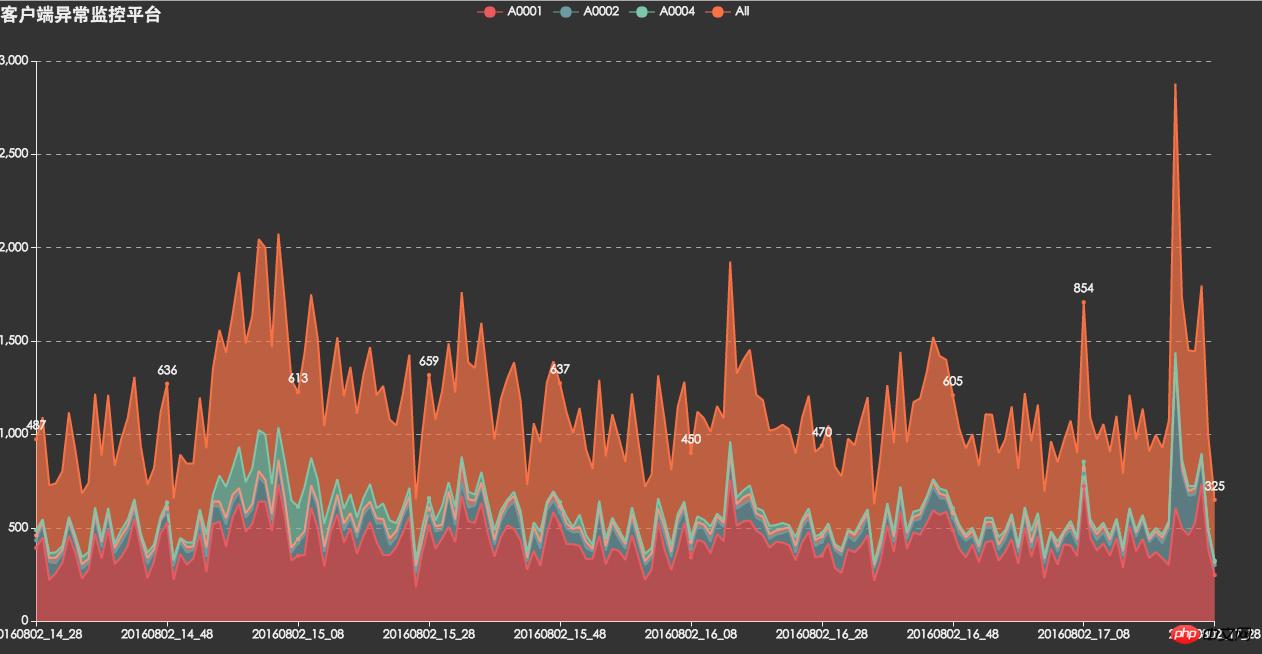
1. When pushing, a large number of APP users will be recalled. When the client is opened at the same time, the number is 3-5 times that of usual times (as shown in the figure (morning and evening peaks will be superimposed))
2. When the client opens PUSH, it is a cold start. Pulling up users will call a lot of interface resources, and the new API did not fully communicate with APP-side classmates when it was launched, resulting in a huge number of interface requests in an instant, including a lot of real-time interests, advertisements, etc. that cannot be cached and a large number of back-end interfaces streaking, and MYSQL and other resources, resulting in a lot of waiting.
3. The timeout for the interface request backend resource is set too long, and the slow interface request is not released in time, resulting in a large number of interface requests waiting in queue
4. The user scale is growing, and the APP user scale has been the same as at the beginning of the year Compared to doubling the number, the focus of work has been on code reconstruction, but server resources have been ignored, and there have been no new machines, which is also a reason for this failure. [Note: Hardware investment is actually the lowest cost investment]
Then, and then it died. . .
problem solved:
1, Optimize the NGINX layer cache, cache content [such as text], do CACHE in the NGINX layer, reduce back-end pressure
2, Disable unnecessary interface processing [such as statistics] ], NGINX returns directly without using PHP, reducing the pressure on PHP-FPM
3. Reorganize the requested back-end interface resources, prioritize them according to business importance, and strictly control the timeout.
4, add new equipment, recalculate and configure server resources based on user scale
5. Record resource call logs and monitor dependent resources. Once there is a problem with the resource, find the provider to solve it in time
6. Adjust the MC cache structure to improve cache utilization
7. Fully communicate with the client to carefully sort out the order and frequency of interface requests by the APP to improve effective interface utilization.
Through this series of improvement measures, the effect is still relatively obvious. The performance advantages of the new API compared with the old API are as follows:
Old: Requests less than 100ms account for 55%
 Old API response time
Old API response time
New: More than 93% response time is less than 100ms
 New API response time
New API response time
conclusion of issue:
The root causes are mainly as follows: 1. Insufficient response, 2. Lack of repeated communication, 3. Insufficient robustness, 4. PUSH characteristics
1>, inadequate response
The number of users has more than doubled from the beginning of the year to that time, but it failed to attract enough attention. The interface reconstruction progress was still a bit slow, leaving no sufficient time for optimization and thinking. It went directly to the battlefield and did not add server equipment resources in a timely manner. , leading to a big pitfall.
2>, lack of communication
I did not maintain sufficient communication with my classmates on the APP side and the operation and maintenance department, and I only cared about what was happening at my feet. Be sure to maintain sufficient communication with the terminal and operation and maintenance students and integrate them into one. According to the existing resource conditions [hardware, software, dependent resources, etc.], the timing and frequency of various resource requests are agreed in detail, and non-main application interface requests are appropriately delayed to ensure that the main business is available and make full use of service resources.
Note: It is especially important to maintain good communication with classmates Duanshang. During development, classmates request interfaces based on the business logic needs of the APP. If too many interfaces are requested, it will be equivalent to your own APP launching a large number of Ddos attacks on your own server, which is very serious. horrible. .
3>, insufficient robustness
Over-reliance on trusted third-party interfaces, unreasonable timeout settings for dependent interfaces, insufficient cache utilization, no disaster backup, and problems with dependent resources can only lead to death.
Note: Principle of Distrust, do not trust any dependent resources, be prepared for dependent interfaces to hang up at any time, be sure to have disaster recovery measures, set a strict timeout, and give up when it is time to give up. Make a good service downgrade strategy. [Reference: 1. Business downgrade, add cache to reduce update frequency, 2. Ensure main business, eliminate unnecessary business, 3. User downgrade, abandon some users, and protect high-quality users]. Logging, logs are the eyes of the system. Even if logging consumes part of the system performance, logs must be recorded. Once there is a problem with the system, the problem can be quickly located and solved through the logs.
4>, sudden large traffic
PUSH and third parties bring huge amounts of traffic instantly, which is unbearable for the system and lacks effective circuit breaker, current limiting and downgrading self-protection measures.
Summary: I also learned a lot through this question and gained a deeper understanding of the overall system architecture. At the same time, I also realized some truths. Some things are not so easy to take for granted. You must make full and detailed preparations before doing anything. Refactoring is not just about rewriting the code. It requires a full understanding and awareness of the entire upstream and downstream system resources, as well as complete preparations. Failure to do so will inevitably lead to pitfalls.
Looking forward to it, looking forward to it, the traffic is coming, the Olympics are approaching!
BOSS Brother Tao said: If the Olympics does not go wrong, I will treat the students to a big meal! If something goes wrong at the Olympics, treat Brother Tao to a feast! So there must be no problems with the feast!
We have been in a state of preparation before the Olympics and have carried out a lot of optimization work to ensure that we can perfectly survive the Olympic traffic peak.
1. All dependent resources were carefully sorted out, and key business interfaces were carefully monitored
2. Deploy the log reporting module on the APP side to report abnormal logs in real time for monitoring
3. Upgrade and expand the MC cluster and uniformly optimize and manage the system cache
4. Launch multi-level business circuit breaker and downgrade strategy
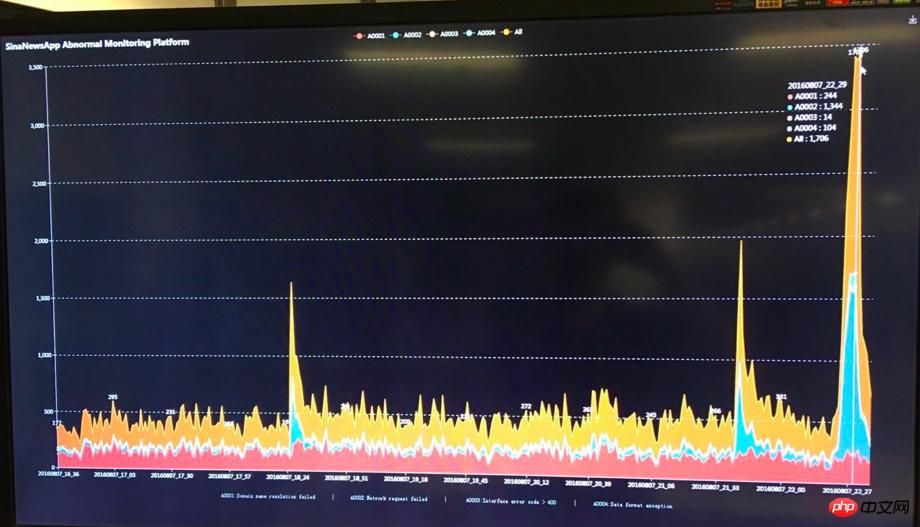
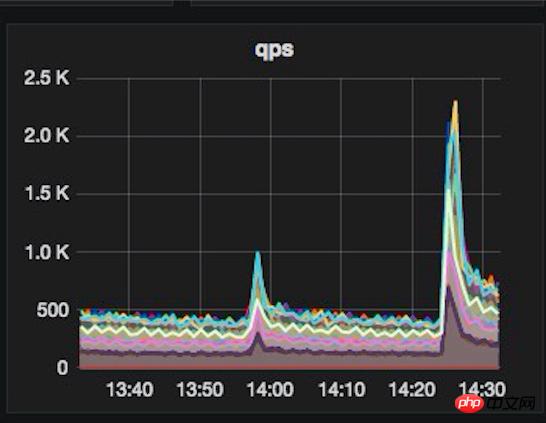
But the Olympics are really coming, and the system still faces a great test. At the beginning of the Olympics, in order to ensure that all indicators of the system operate normally without any problems, we arranged for engineers to be on duty in the company 24 hours a day. PUSH, the first Olympic gold medal, lived up to expectations and brought instant success. With more than 5 times the usual traffic, various resources were tight and the server began to operate at full capacity. Our previous preparations came into play at this moment. The engineer on duty always paid attention to the large monitoring screen, adjusted the system parameters at any time according to the monitoring data and server load status, and at the same time warmed up various data in advance, and successfully passed the first Olympic gold medal! After the first gold medal, I observed during the Olympics that the traffic brought by other gold medal events was not too large compared to the first gold medal. I naively thought that the peak traffic peak of the entire Olympic Games had been passed safely. [The first gold abnormality monitoring chart is as follows]
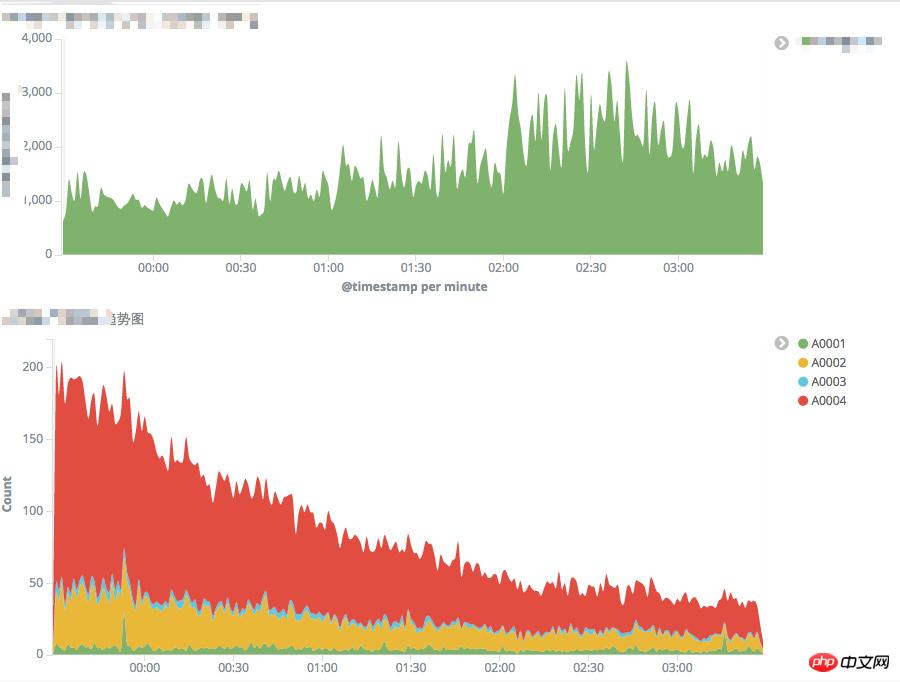
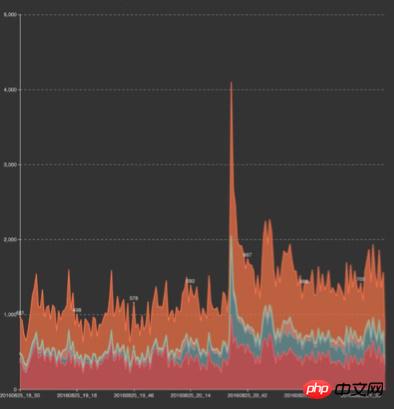 Baby event PUSH and Olympic Games overlay traffic
Baby event PUSH and Olympic Games overlay traffic
We immediately activated an emergency plan to protect the system from overload, and downgrade services in order of importance [generally including: reducing the update frequency, extending the cache time, and deactivating] to protect the overall availability of the system from being affected and ensure that the system can smoothly pass the traffic peak. . After downgrading is manually enabled, the system begins to rapidly release a large amount of resources, the system load begins to decrease steadily, and the user-side response time returns to normal levels. After the PUSH has passed [the peak usually lasts about 3 minutes], manually cancel the downgrade.
Although the baby incident suddenly occurred during the Olympics, we managed to get through it smoothly, there were no problems with the overall service, and the overall business data of the APP also improved greatly with these two incidents.
BOSS also invited the students to have a feast and have a happy time!
Summary: 1. The monitoring system needs to be more detailed, and resource monitoring needs to be added, because through post-mortem analysis, it is found that some of the problems seen are not caused by traffic, but may be due to dependence on resource issues, causing system congestion and amplifying the impact. 2. Improve the alarm system. Due to the unpredictable occurrence of emergencies, it is impossible for someone to be on duty 24 hours a day. 3. The automatic downgrade mechanism service management system is waiting to be established. If it encounters sudden traffic or sudden abnormalities in dependent resources, it will automatically downgrade unattended.
The rapidly developing business has also placed higher requirements on various indicators of our system. The first is the server-side response time.
The response speed of the two core functional modules of the APP, the feed stream and the text, has a great impact on the overall user experience. According to the leadership's requirements, first of all, we have an early goal. The average response time of the feed stream is 100ms. At that time, the overall response time of the feed It is about 500-700ms, which is a long way to go!
The feed streaming business is complex and relies on many data resources, such as real-time advertising, personalization, comments, image transfer, focus images, fixed position delivery, etc. Some resources cannot be cached. For real-time calculation data, we cannot rely on caching. We can only find another way and solve it through other means.
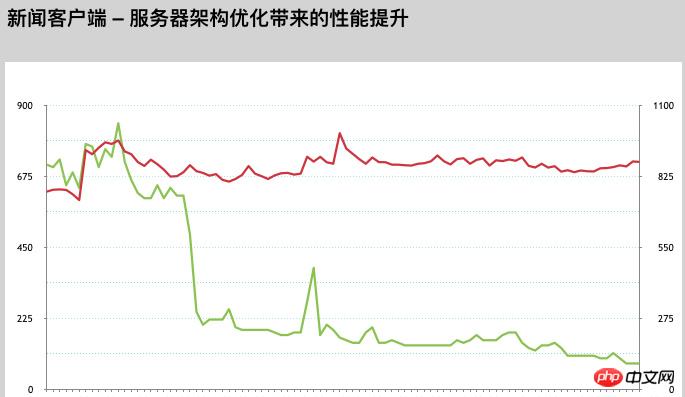
First, we worked with the operation and maintenance team to upgrade the server software system environment as a whole, upgraded Nginx to Tengine, and then upgraded PHP. The upgrade effect was quite obvious, and the overall response time was reduced by about 20%, to 300- 400ms. Although the performance has been improved, it is still far from the target. As the optimization continues, we conduct log analysis on the entire business link of the feed to find out the areas that consume the most performance and defeat them one by one.
The original server structure is as follows:
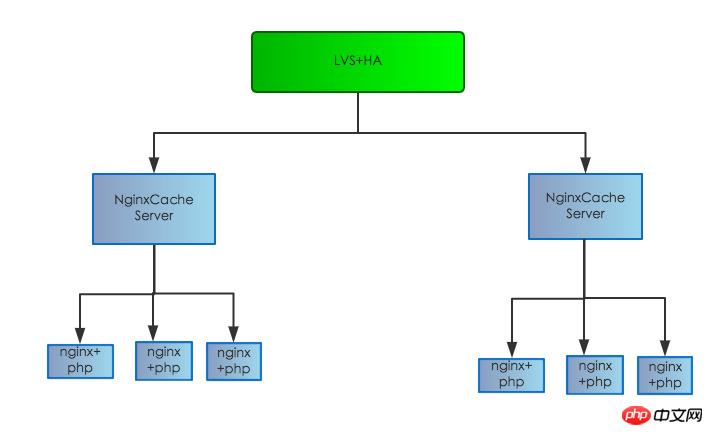
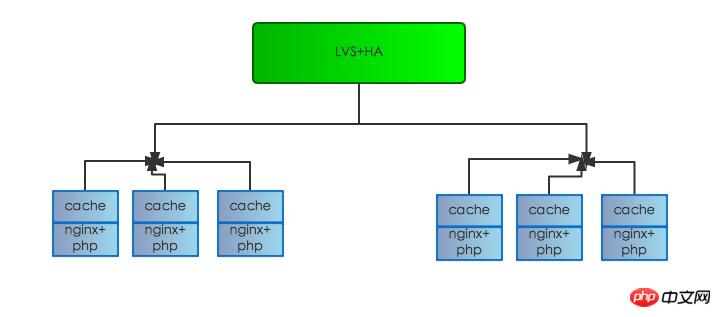
After the server structure adjustment is completed, the feed response time has also been greatly reduced, and the performance has been significantly improved, reaching around 200-350ms. Getting closer to the set goal, but still not achieving the set goal.
One day, our engineers accidentally discovered a problem while debugging the code. The millisecond timeout set by PHP-CURL was invalid. We verified through a large number of tests that the default CURL library that comes with PHP does not support milliseconds. By querying the official PHP documentation, we found that the old version PHP libcurl library has this problem [later found that most business PHP version environments in the company have this problem] This means that the precise control of the large number of dependent interface timeouts we made in the system did not take effect, which also caused the system performance to be delayed. An important reason for the delay. Solving this problem will definitely bring a great improvement to the overall performance. We will immediately start online grayscale verification testing with the operation and maintenance students. After several days of online testing, No other problems were found, and the performance really improved a lot, so we gradually expanded the scope until all servers were online. The data showed that after the libcurl version library was upgraded, the server feed response time directly reached 100-100 without any other optimization. About 150ms, very obvious.
The server structure layer and the software system environment layer have done everything they can, but they have not yet reached the set requirement of 100ms for the average feed response time. They can only start with the business code. At that time, the online feed flow request relied on resources that were executed sequentially. Congestion of a resource will cause subsequent requests to be queued, causing the overall response time to increase. We began to try to change PHP CURL to multi-threaded concurrent requests, change serial to parallel, and request multiple dependent resource interfaces at the same time without waiting. Through the technical research of our friends, we rewrote the CURL class library to provide To avoid problems, we conducted a large number of grayscale tests for a long time and verified them. The tests passed and were released to the online production environment. At the same time, the efforts of our friends were rewarded. The server feed stream response time dropped directly to less than 100ms. At the same time, the text The average response time of the interface is controlled to within 15ms.
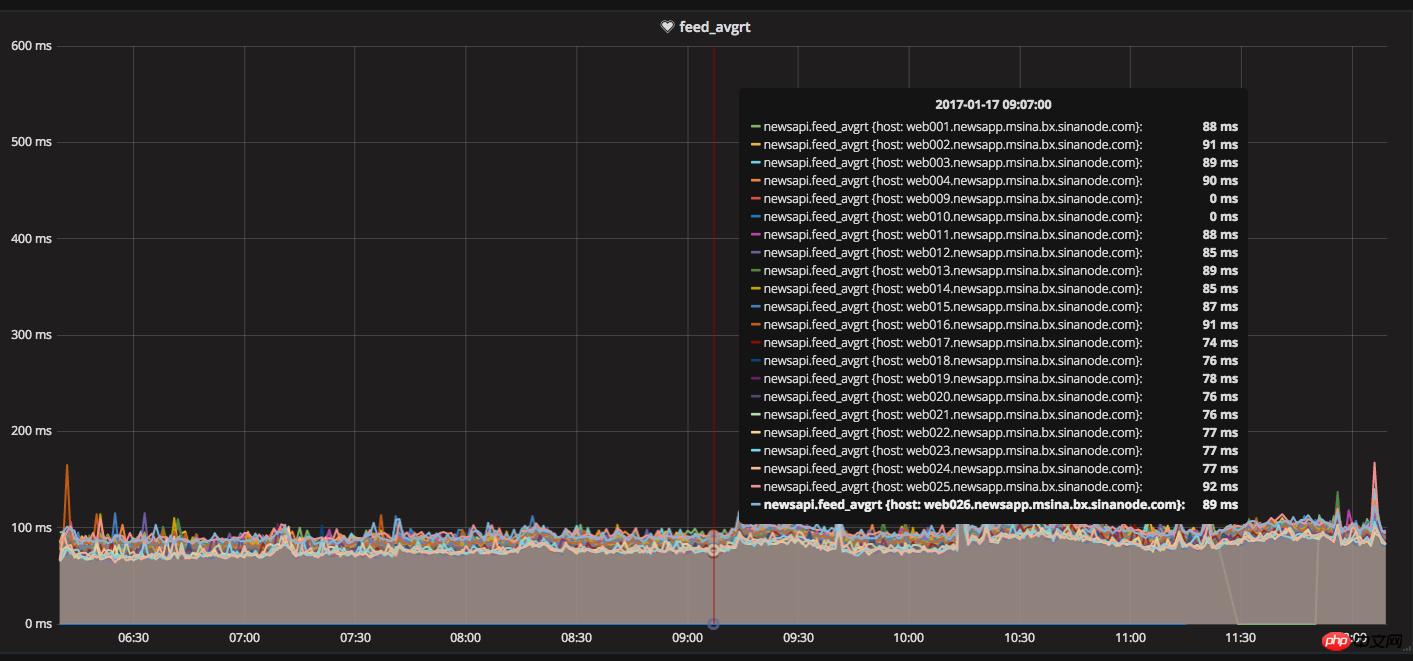
## Feed stream response time
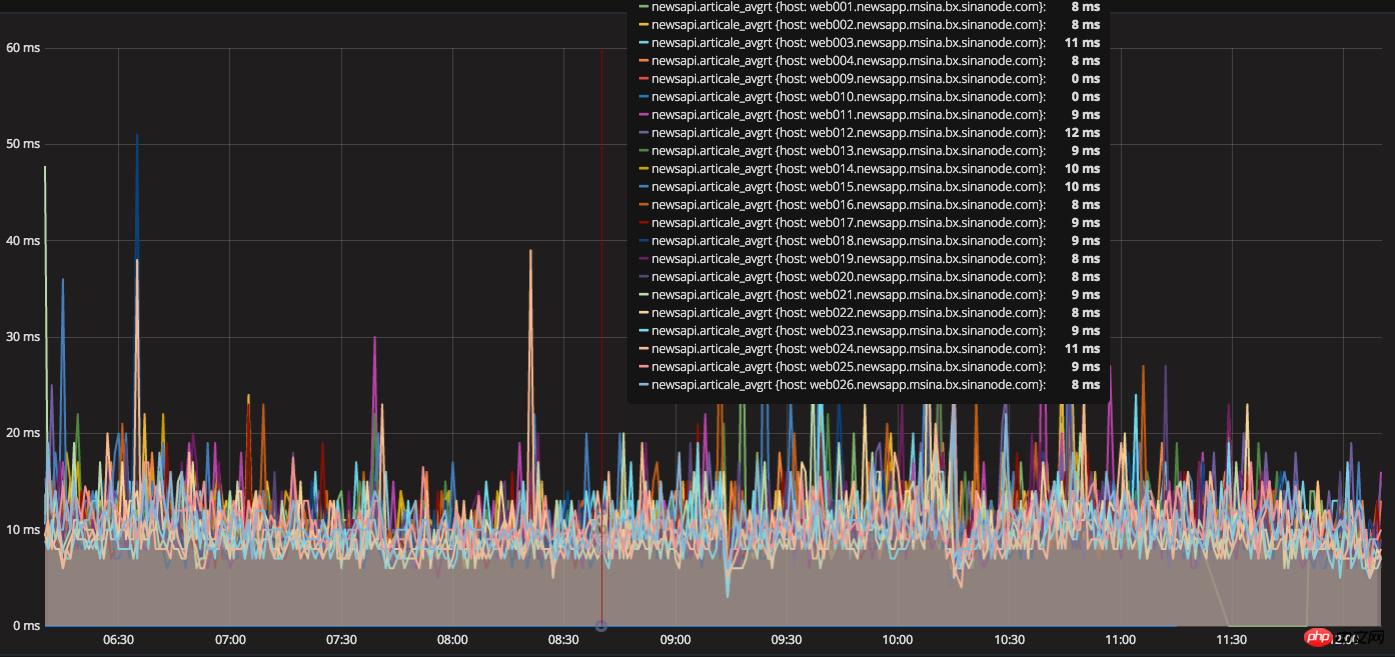 Text average response time
Text average response time
Only by strategizing can we win a thousand miles.
News APP interfaces currently rely on hundreds of third-party interfaces and resources. Once a problem occurs with one or more interfaces and resources, it will easily affect system availability.
Based on this situation, we designed and developed this system. The main system modules are as follows:
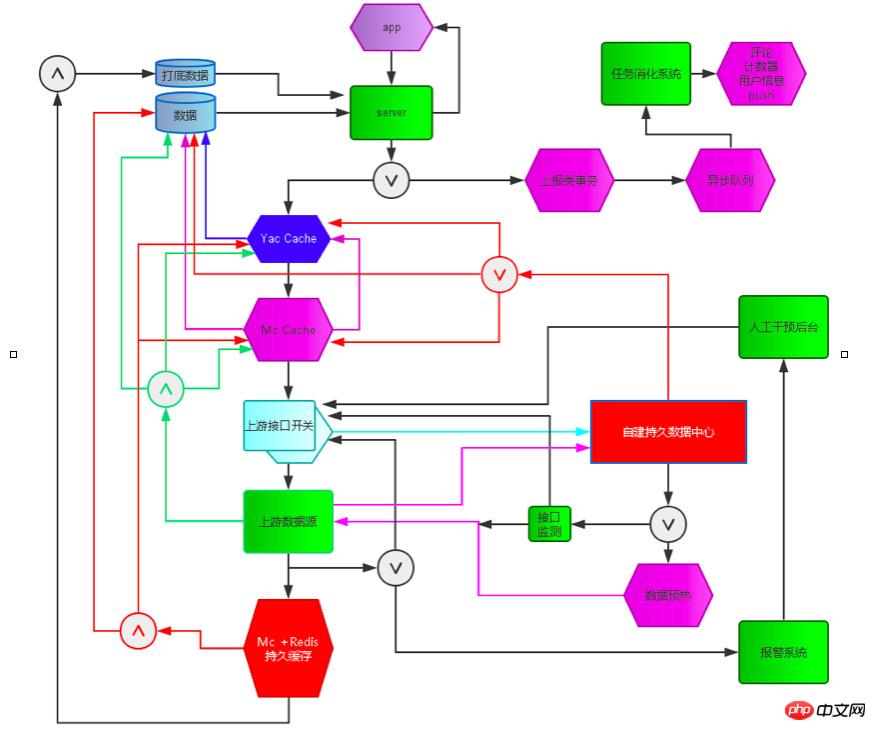
Service self-protection, service degradation, error analysis and call chain monitoring, monitoring and alarming. Self-built offline data center, relying on the resource life detection system, interface access scheduling switch, the offline data center collects key business data in real time, the life detection system detects resource health and availability in real time, the interface access scheduling switch controls the request for the interface, once the life detection When the system detects a problem with a resource, it will automatically downgrade and reduce access frequency through the interface access control switch, and automatically extend the data cache time. The life detection system continuously detects the health of the resource. Once the resource is completely unavailable, the control switch will completely Close the interface to request access for automatic service degradation, and enable the local data center to provide data to users. After the life probe detects that the resource is available, resume the call. This system has successfully avoided heavy reliance on resources [such as CMS, comment systems, advertising, etc.] many times Faults The impact on the availability of news client services. If the dependent resources fail, the business response will be delayed. The client is basically unaware. At the same time, we have established a complete exception monitoring, error analysis and call chain monitoring system to ensure that problems can be predicted, discovered, and solved as soon as possible [detailed in Chapter 7 Server High Availability].
At the same time, the client business continues to develop rapidly, and each functional module is updated and iterated quickly. In order to meet the rapid iteration without any serious code problems, we have also increased the code grayscale and release process. When a new function is launched, it will first undergo grayscale verification. After passing the verification, it will be launched to full capacity. At the same time, a new and old switching module is reserved. If there is a problem with the new function, it can be switched to the old version at any time to ensure normal service.
 ##Service governance platform technology implementation
##Service governance platform technology implementation
Definition of high availability:
The definition formula of system availability (Availability) is: Availability = MTBF / ( MTBF + MTTR ) × 100% MTBF (Mean Time Between Failure), which is the mean time between failures, is an indicator that describes the reliability of the entire system. For a large-scale Web system, MTBF refers to the average time for the entire system's services to run continuously without interruption or failure. MTTR (Mean Time to Repair), which is the average system recovery time, is an indicator that describes the fault-tolerant capability of the entire system. For a large web system, MTTR refers to the average time it takes for the system to recover from the fault state to the normal state when a component in the system fails. It can be seen from the formula that increasing MTBF or reducing MTTR can improve system availability.So the question becomes, how to improve system availability through these two indicators?
From the above definition, we can see that an important factor in high availability: MTBF is system reliability [mean time between failures].
Then let’s list what issues will affect MTBF. Possible factors are: 1. Server hardware, 2. Network, 3. Database, 4. Cache, 5. Dependent resources, 6. Code errors, 7. Sudden large traffic High concurrency As long as these problems are solved, failures can be avoided and MTBF can be improved.
Based on these questions, how does the news client currently do it?
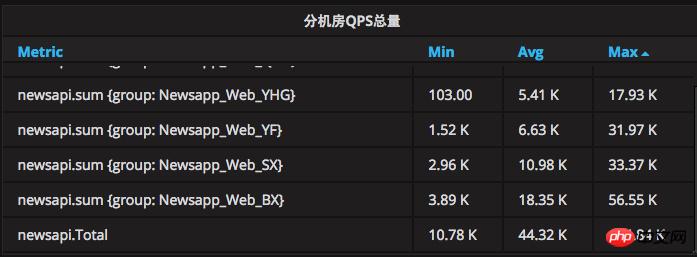
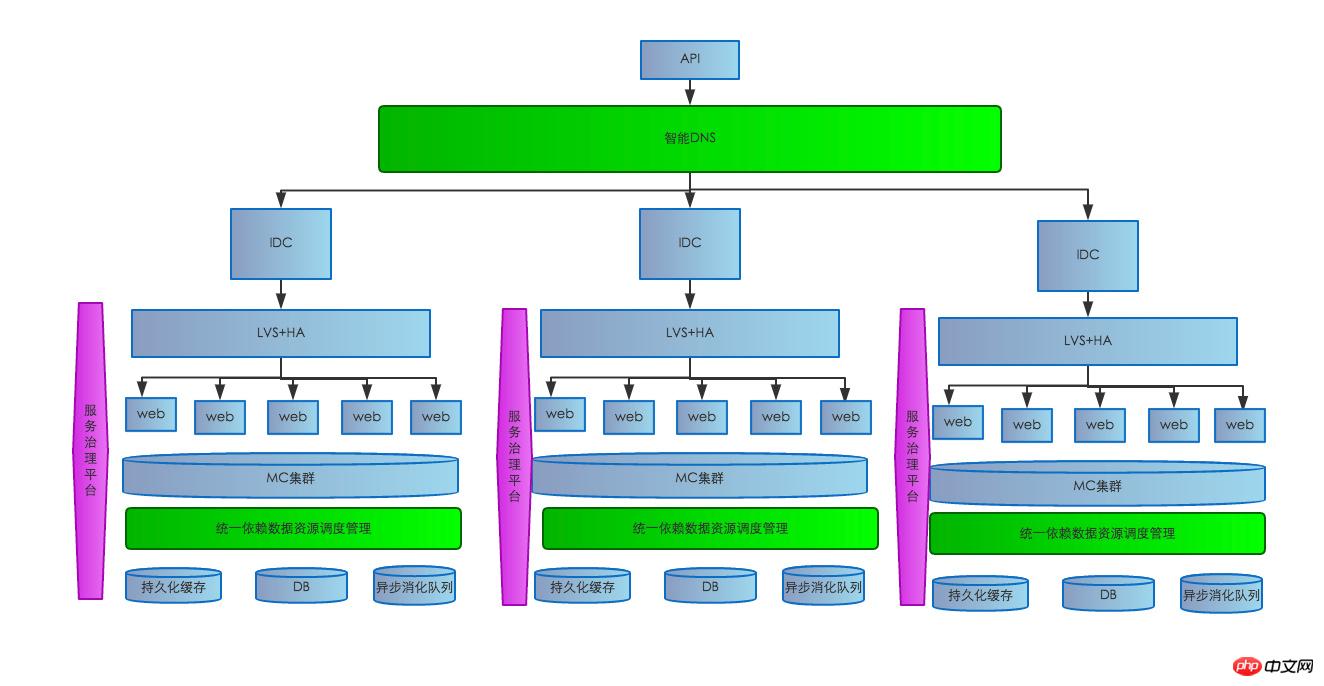
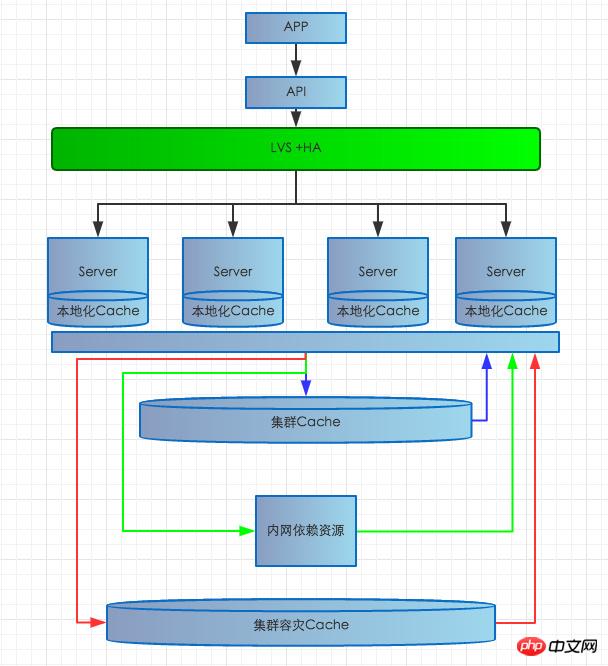
The first server hardware failure: If a server hardware failure will cause the service on this server to be unavailable, the structure is as shown below. The current system is LVS+HA with multiple MEMs attached. There is a life detection system on the server, LVS+HA. If an abnormality is detected, it will be removed from the load balancing in time to prevent users from accessing the problematic server and causing failure.
The second internal network problem: If a large-scale internal network failure occurs, a series of problems will cause failure to read dependent resources, failure to access the database, and failure to read and write the Cache cluster. etc., the scope of impact is relatively large and the consequences are serious. Then we will write more articles this time. Generally speaking, network problems mainly occur when cross-computer room access is blocked or blocked. It is extremely rare for the network in the same computer room to be disconnected. Because some dependent interfaces are distributed in different computer rooms, cross-computer room network problems will mainly affect the slow response or timeout of the dependent interfaces. For this problem, we adopt a multi-level caching strategy. Once the dependent cross-computer room interface is abnormal, the real-time localized cache will be taken first. If For localized cache penetration, immediately access the real-time cache of the Cache cluster in the local computer room. If the real-time cache of the cluster is penetrated, access the persistent defense cache of the local computer room. Under extremely harsh conditions, if there is no hit in the persistent cache, the backup data source will be returned to the user. At the same time, the preheated backup data source is only cached persistently, so that users are unaware of it and avoid large-scale failures. To solve the problem of database delays caused by network problems, we mainly use asynchronous queue writing to increase the reservoir to prevent database writing from being congested and affecting system stability.
##The sixth code error : There have been cases of bloody online failures caused by coding errors in the past, and many problems were caused by low-level errors, so we have also focused on doing a lot of work in this area.
First of all, we need to standardize the code development and release process. As the business grows, the requirements for system stability and reliability are also getting higher and higher. The number of development team members is also increasing. It is no longer like the primitive social state of slash-and-burn farming and working alone. All operations require Be standardized and process-oriented. We have improved: development environment, test environment, simulation environment, online environment and online process. After the engineer completes the self-test in the development environment, he mentions the test environment and the testing department conducts the test. After passing the test, he goes to the simulation environment and conducts the simulation test. If the test passes, he mentions it to the online system. The online system must be approved by the administrator before it can be used. Online, after the online regression is completed, online regression verification is performed. If the verification is passed, the code online process is closed. If the verification fails, the online system can be rolled back to the pre-launch environment with one click.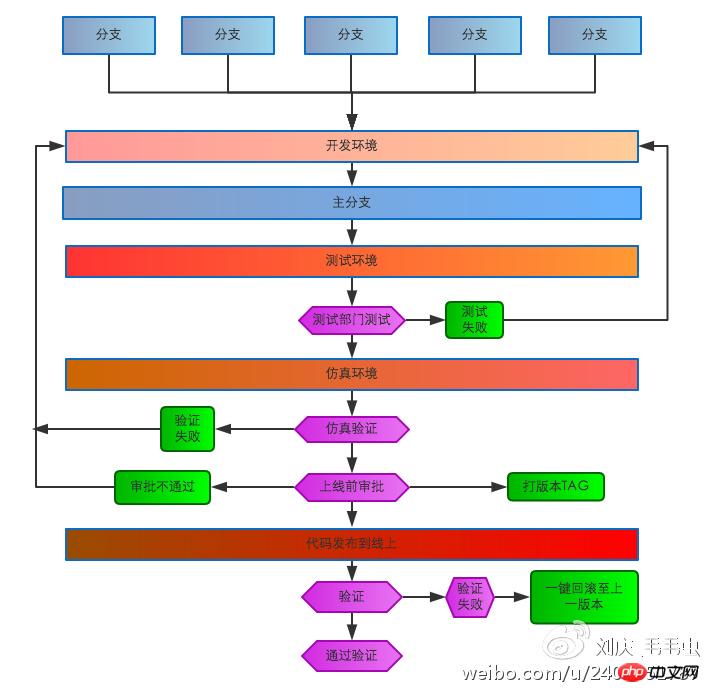 Code development and release process
Code development and release process
So how do we deal with Article 7: sudden large traffic and high concurrency?
We generally define sudden large traffic as hotspots and emergencies that bring a large number of access requests instantly in a short period of time, which far exceeds the expected load range of system software and hardware. If not handled, it may affect the overall service. This situation lasts for a short time. If it is too late to temporarily add a new online machine, it will be meaningless after the machine is online and the traffic peak has passed. If a large number of backup machines are prepared online at any time, these machines will be idle 99% of the time, which will waste a lot of financial and material resources.
In such a situation, we need a complete traffic scheduling system and service circuit breaker and current limiting measures. If sudden large traffic comes from certain specific areas, or is concentrated in one or more IDC computer rooms, you can split part of the traffic from the computer room with higher load to the computer room with idle traffic to share the pressure. However, if traffic segmentation is not enough to solve the problem, or the traffic load of all computer rooms is relatively high, then we can only protect the overall system service through circuit breakers and current limiting. First, sort according to the priority of the business module, and then proceed according to the low-priority business. Downgrade. If the business downgrade still cannot solve the problem, then we will start to deactivate low-priority services one by one to keep important functional modules and continue to provide external services. In extreme cases, if the business downgrade cannot survive the traffic peak, then we will take current limiting protection measures. Temporarily Abandon a small number of users to maintain the availability of most high-value users.
Another important indicator of high availability is the MTTR system average recovery time, which is how long it takes for the service to recover after a failure.
The main points to solve this problem are as follows: 1. Find the fault, 2. Locate the cause of the fault, 3. Solve the fault
These three points are equally important. First, we must detect faults in time. In fact, it is not terrible if a problem occurs. What is terrible is that we did not find the problem for a long time, which caused a large number of user losses. This is the most serious thing. So how to detect faults in time?
The monitoring system is the most important link in the entire system, and even in the entire product life cycle. It provides timely warnings to detect faults beforehand, and provides detailed data afterwards for tracing and locating problems.
First of all, we must have a complete monitoring mechanism. Monitoring is our eyes, but monitoring is not enough. We also need to issue alarms in time, and notify relevant personnel to deal with problems in a timely manner. In this regard, we have established a supporting monitoring and alarm system with the support of the operation and maintenance department.
Generally speaking, a complete monitoring system mainly has these five aspects: 1. System resources, 2. Server, 3. Service status, 4. Application exceptions, 5. Application performance, 6. Exception tracking system
1. System resource monitoring
Monitor various network parameters and server-related resources (cpu, memory, disk, network, access requests, etc.) to ensure the safe operation of the server system; and provide an exception notification mechanism to allow system administrators to quickly locate/solve various existing problems. .
2. Server monitoring
Server monitoring is mainly to monitor whether the request responses of each server, network node, gateway, and other network equipment are normal. Through the scheduled service, each network node device is regularly pinged to confirm whether each network device is normal. If any network device is abnormal, a message reminder is issued.
3. Service monitoring
Service monitoring refers to whether the services of various web services and other platform systems are running normally. You can use scheduled services to request related services at regular intervals to ensure that the services of the platform are running normally.
4. Application exception monitoring
Mainly include abnormal timeout logs, data format errors, etc.
5. Application performance monitoring
Monitor whether the response time indicators of the main business are normal, display the performance curve trend of the main business, and timely discover and predict possible problems.
6. Exception tracking system
The exception tracking system mainly monitors the resources that the entire system relies on upstream and downstream. By monitoring the health status of dependent resources, such as changes in response time, changes in timeout rate, etc., it can make early judgments and deal with possible risks in the entire system. It can also quickly locate faults that have occurred to see if they are caused by a dependent resource problem, so as to quickly resolve the fault.
The main monitoring systems we currently use online are as follows:
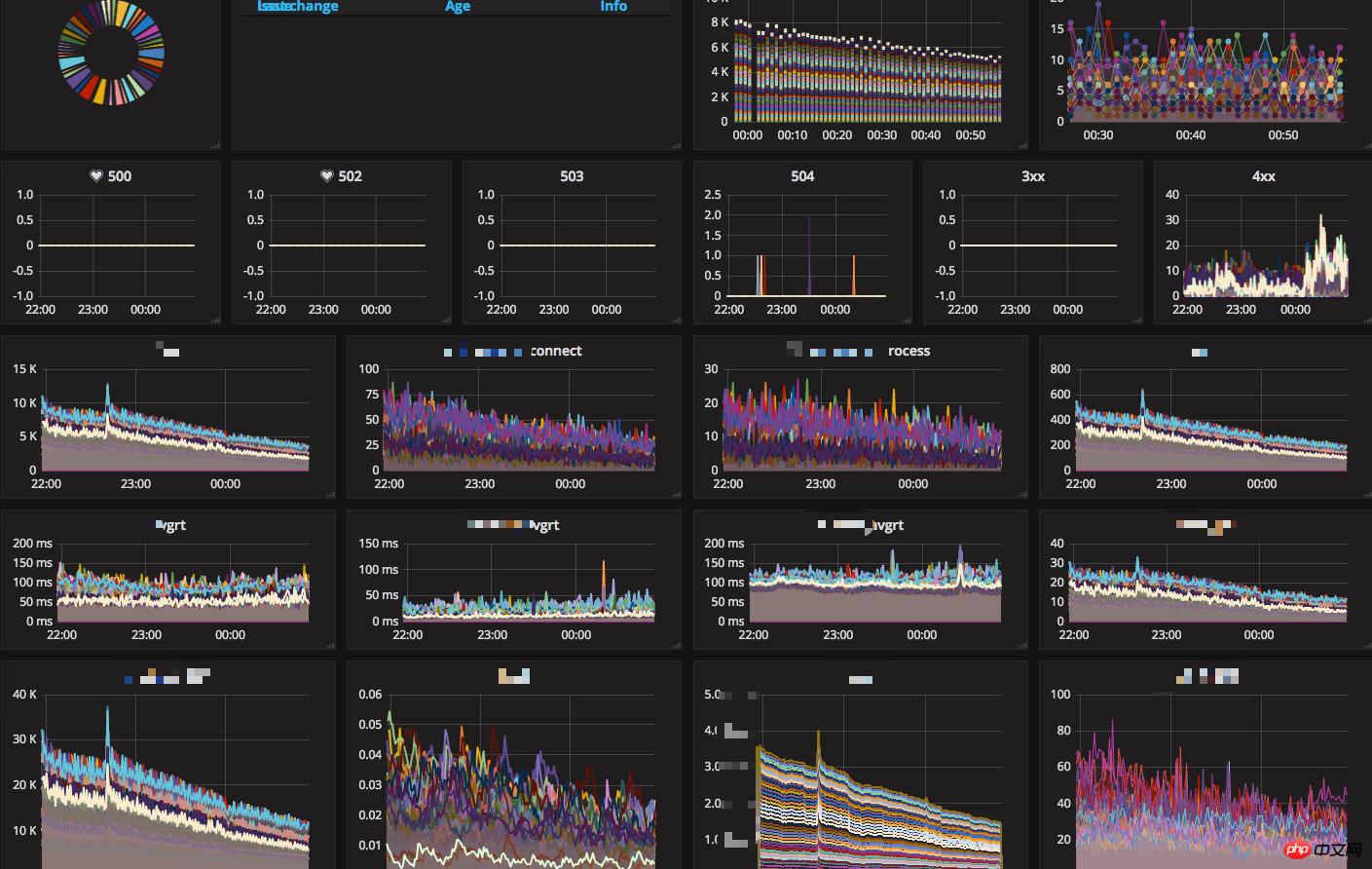 The road to growth of the back-end system architecture of News APP - Detailed graphic and text explanation of high-availability architecture design
The road to growth of the back-end system architecture of News APP - Detailed graphic and text explanation of high-availability architecture design
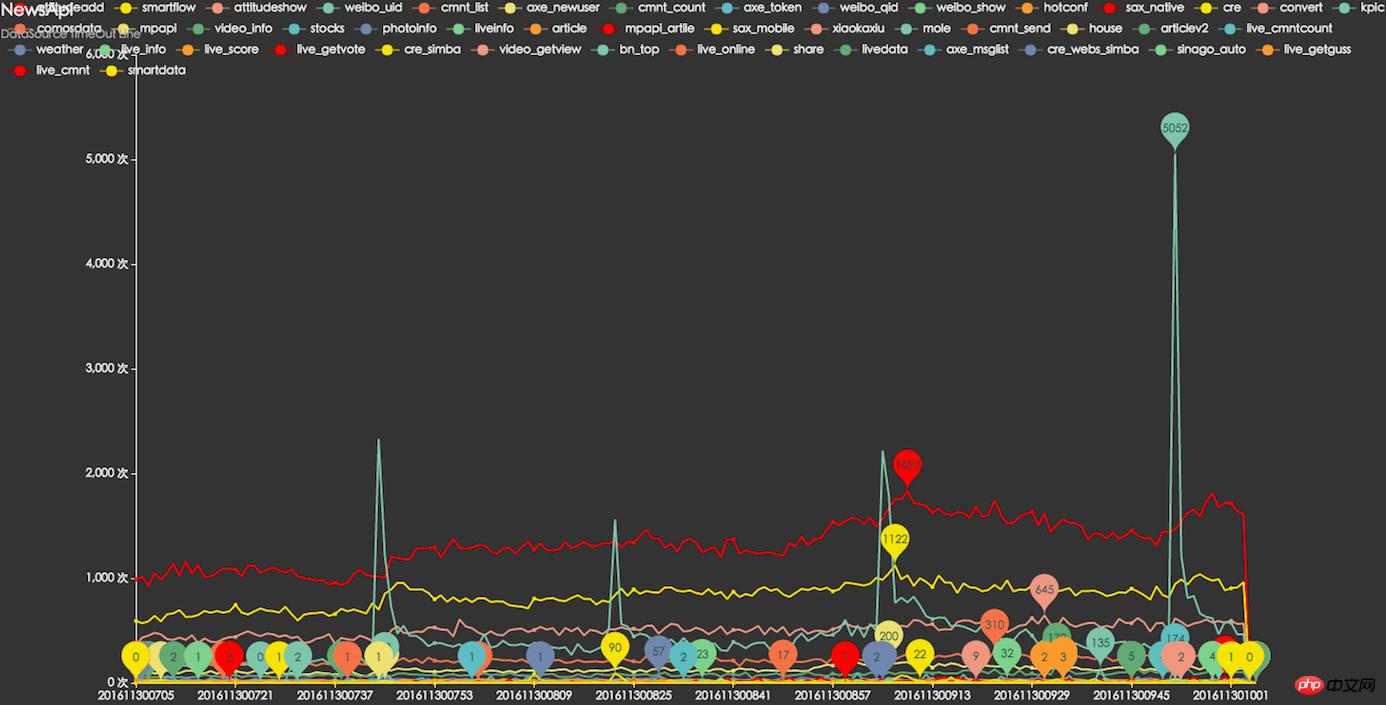 #Dependent resource timeout monitoring
#Dependent resource timeout monitoring
##Dependent resource average response time monitoring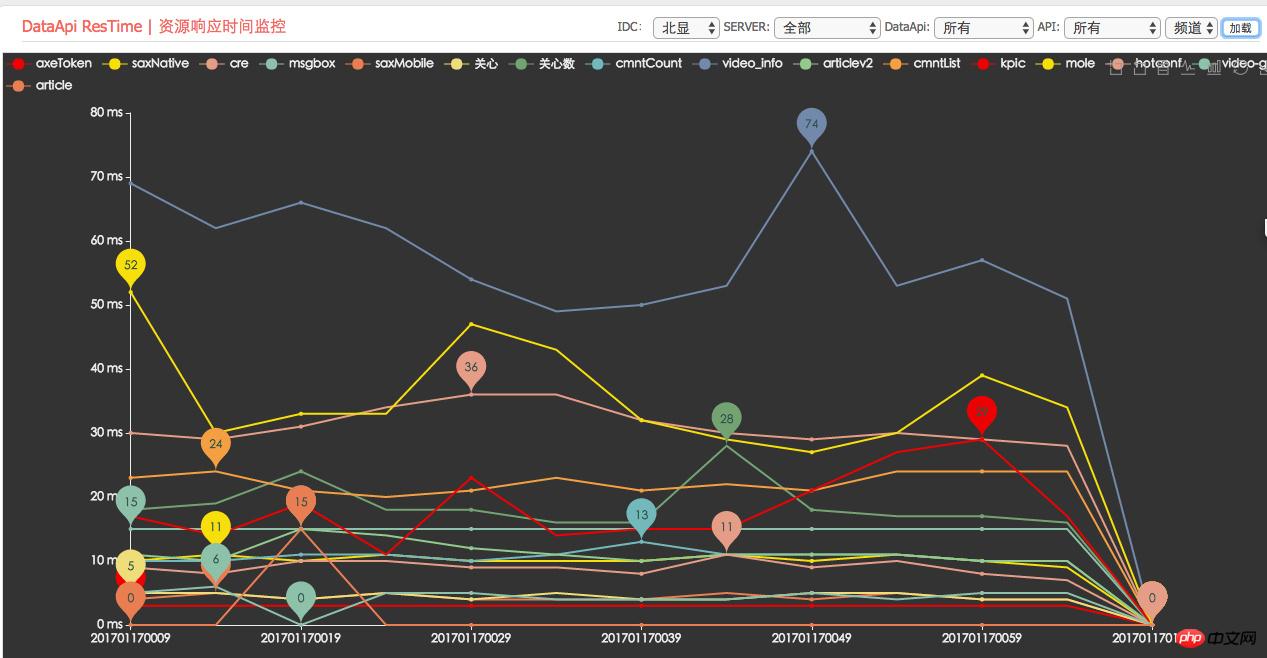
8. Soaring: high availability for the client
Recently, there have been a lot of articles talking about HTTPS in the Internet media. One of the reasons is that the bottom line of operators' evil behavior is getting lower and lower, and advertisements are inserted at every turn. A few days ago, several Internet companies jointly issued a joint statement on resisting illegal activities such as traffic hijacking and denounced some operator. On the other hand, it is also strongly promoted by Apple's ATS policy, forcing everyone to use HTTPS communication in all apps. There are many benefits to using HTTPS: protecting user data from leaks, preventing middlemen from tampering with data, and authenticating corporate information. Although HTTPS technology is used, some evil operators will block HTTPS and use DNS pollution technology to point domain names to their own servers to perform DNS hijacking.
If this problem is not solved, even HTTPS cannot fundamentally solve the problem, and many users will still have access problems. At least it may lead to distrust of the product, but at worst it may directly cause users to be unable to use the product, leading to user loss.
So according to third-party data, how serious is the abnormality in domain name resolution for Internet companies like Gouchang? Every day, Gouchang's distributed domain name resolution monitoring system continuously detects all key LocalDNS across the country. The number of daily resolution exceptions for Gouchang's domain names across the country has exceeded 800,000. This caused huge losses to the business.
Operators will do whatever they can to make money from advertising and save money on inter-network settlements. A common hijacking method they use is to provide fake DNS domain names through ISPs.
"In fact, we are also facing the same serious problem"
Through log monitoring and analysis on the news APP, it was found that 1%-2% of users have DNS resolution abnormalities and interface access problems.
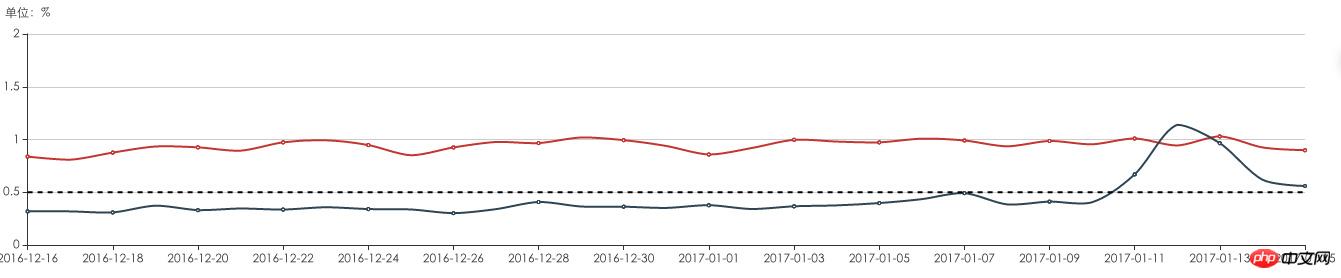
DNS exception and inability to access the interface
Invisibly causing a large number of user losses, especially during the period of rapid business development, it caused great damage to the business experience.
# So is there a technical solution that can solve the root cause of domain name resolution anomalies, user access cross-network problems and DNS hijacking?
The industry has a solution to solve this kind of scenario, namely HTTP DNS.
HttpDNS sends a domain name resolution request to the DNS server based on the Http protocol, replacing the traditional method of initiating a resolution request to the operator's LocalDNS based on the DNS protocol. It can avoid domain name hijacking and cross-network access problems caused by LocalDNS, and solve the problem of abnormal domain name resolution in mobile Internet services. Come trouble.
HttpDNS mainly solves three types of problems: Solve DNS resolution anomalies in mobile Internet, LocalDNS domain name hijacking, average response time increases, and user connection failure rate remains high
1. DNS resolution exception and LocalDNS hijacking:
The current situation of mobile DNS: The operator's LocalDNS export performs NAT based on the authoritative DNS target IP address, or forwards the resolution request to other DNS servers, causing the authoritative DNS to be unable to correctly identify the operator's LocalDNS IP, causing domain name resolution errors and traffic crossing the network.
Consequences of domain name hijacking: website inaccessibility (unable to connect to the server), pop-up advertisements, access to phishing websites, etc.
The consequences of cross-domain, cross-province, cross-operator, and cross-country parsing results: website access is slow or even inaccessible.
Since HttpDNS directly requests http to obtain the server A record address through IP, there is no need to ask the local operator for the domain resolution process, so the hijacking problem is fundamentally avoided.
2. The average access response time increases: Since direct IP access saves a domain resolution process, the fastest node is found for access after sorting through intelligent algorithms.
3. Reduced user connection failure rate: Reduce the ranking of servers with excessive failure rates in the past through algorithms, improve server ranking through recently accessed data, and improve servers through historical access success records. Sort. If there is an access error to ip(a), the sorted records of ip(b) or ip(c) will be returned next time. (LocalDNS is likely to return records within a ttl (or multiple ttl)
HTTPS can prevent operators from hijacking traffic to the greatest extent, including content security from being tampered with.
HTTP-DNS can solve the problem of client DNS, ensuring that user requests are directed directly to the server with the fastest response.
The principle of HTTP DNS is very simple. It converts DNS, a protocol that is easily hijacked, into HTTP protocol requests
DomainIP mapping. After obtaining the correct IP, the Client assembles the HTTP protocol by itself to prevent the ISP from tampering with the data.
The client directly accesses the HTTPDNS interface to obtain the optimal IP of the domain name. (Based on disaster recovery considerations, the method of using the operator's LocalDNS to resolve domain names is reserved as an alternative.)
After the client obtains the business IP, it sends a business protocol request directly to this IP. Taking the HTTP request as an example, you can send a standard HTTP request to the IP returned by HTTPDNS by specifying the host field in the header.
If you want to achieve high availability on the client side, you must first solve this problem. We have started preparations together with APP development students and operation and maintenance students, striving to launch HTTPDNS as quickly as possible to achieve high availability for APP users and provide reliable guarantee for the rapid development of business!
After a year of hard work, the entire APP back-end system has basically gone from the barbaric era to the current state of perfection. I have also learned a lot of knowledge from a little bit of exploration, and I think I have also achieved great growth, but at the same time we are facing many, many Problem, with the rapid development of business, the requirements for back-end services are getting higher and higher. There are still many problems that need to be solved in the future. We will also hold ourselves to higher standards and prepare for the scale of hundreds of millions of users.# This is the road of growth in the back-end system architecture of the news APP-detailed explanation of high available architecture design graphics, more related content, please pay attention to PHP Chinese website ( m.sbmmt.com)!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



