


With the development of the Internet, there are more and more data in all aspects, which can be seen from the growing call for big data in the past two years.
Although the project we are doing is not a big one, due to the volume of business, there is quite a lot of data.
When there is too much data, it is easy to have performance problems, and in order to solve this problem we usually easily think of clustering, sharding, etc.
But at some point, it is not necessary to use clustering or sharding, and data partitioning can also be used appropriately.
What is partition?
When MySQL does not enable the partition function, the contents of a single table of the database are stored on the file system in the form of a single file. When the partitioning function is enabled, MySQL will divide the contents of a single table into several files and store them on the file system according to user-specified rules. Partitioning is divided into horizontal partitioning and vertical partitioning. Horizontal partitioning divides table data into different data files by rows, while vertical partitioning divides table data into different data files by columns. Sharding must follow the principles of completeness, reconfigurability and disjointness. Completeness means that all data must be mapped to a fragment. Reconfigurability means that all sharded data must be able to be reconstructed into global data. Disjointness means that there is no duplication of data on different shards (unless you deliberately make it redundant).
Probably due to various considerations, the table we used uses range partitioning. The database is managed by others, but because this table is used, I took the time to do it. Simple learning.
As far as I know, if you want to use partitioning, you must use the statement to create a partition when creating the table structure, and it cannot be changed later.
For example, I create a simple emp table with three fields: id, name, and age, and then partition it based on id. The correct table creation statement is basically as follows:
CREATE TABLE emp( id INT NOT NULL, NAME VARCHAR(20), age INT) PARTITION BY RANGE(ID)( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION pmax VALUES LESS THAN maxvalue );
Here I set the data of the entire table to be divided into three areas. The area with id less than 6 is one area, and the area name is p0; the area with id between 6 and 11 belongs to One area, area name p1; then all areas with ID greater than 11, area name pmax.
Organize a syntax, basically as follows:
create table tablename( 字段名 数据类型...) partition by range(分区依赖的字段名)( partition 分取名 values less than (分区条件的值),...)
What needs to be noted here is that the last line in the example, partition pmax values less than maxvalue, in this sentence, only pmax, which represents the partition name, can be obtained arbitrarily. The rest The words below cannot be changed, and maxvalue represents the maximum value of the upper partition condition.
This will ensure that all data can be stored in the database normally. Otherwise, if there is no such sentence, data with ID greater than or equal to 11 will not be stored in the database, and an error will be reported.
After the table structure was created, in order to test whether the partitioning was successful, I inserted some data into the table. The statement is as follows:
INSERT INTO emp VALUES(1,'test1',22);INSERT INTO emp VALUES(2,'test2',25);INSERT INTO emp VALUES(3,'test3',27); INSERT INTO emp VALUES(4,'test4',20);INSERT INTO emp VALUES(5,'test5',22);INSERT INTO emp VALUES(6,'test6',25); INSERT INTO emp VALUES(7,'test7',27);INSERT INTO emp VALUES(8,'test8',20);INSERT INTO emp VALUES(9,'test9',22); INSERT INTO emp VALUES(10,'test10',25);INSERT INTO emp VALUES(11,'test11',27);INSERT INTO emp VALUES(12,'test12',20); INSERT INTO emp VALUES(13,'test13',22);INSERT INTO emp VALUES(14,'test14',25);INSERT INTO emp VALUES(15,'test15',27); INSERT INTO emp VALUES(16,'test16',20);INSERT INTO emp VALUES(17,'test17',30);INSERT INTO emp VALUES(18,'test18',40); INSERT INTO emp VALUES(19,'test19',20);
After the data insertion is completed, it is necessary to verify whether the data corresponding to the id is saved. In the corresponding partition, you can use the command to query the partition, as follows:
SELECT partition_name,partition_expression,partition_description,table_rows FROM information_schema.PARTITIONS WHERE table_schema = SCHEMA() AND table_name='emp'
The query result is as shown in the figure: 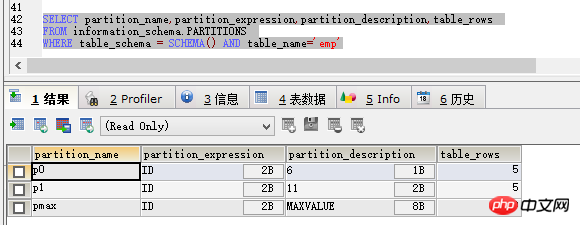
It can be seen that partition_name is the partition name, and partition_expression is the partition dependency. field, partition_description can be understood as the conditions of the partition, and table_rows represents the amount of data currently in the partition.
It can be seen from the above data that the partitioning is successful, but although the above partitioning can avoid the problem of being unable to be inserted, a new problem has arisen.
That is, the data in the last pmax area may be very large. As a result, the data is not average and disproportionate, which may cause performance problems when querying the data in the last area. Therefore, there are roughly three solutions:
First, when you can control the partition field data, such as the id here, if you can clearly know when and what value it will be, then you can Don't use this pmax at the beginning, but add partitions regularly. For example, if p0 and p1 exist here, you can add p2, p3 or even more when the id is about to reach 11. An example of a statement to add a partition is as follows:
ALTER TABLE emp ADD PARTITION(PARTITION p2 VALUES LESS THAN (16))
The syntax is:
alter table tablename add partition(partition 分区名 values lessthan (分区条件))
The above method can solve the problem of disproportionate data, but it also has hidden dangers, that is, if you forget to In order to increase the subsequent partitions, or the field values that the partitions depend on exceed expectations, it may cause the problem that the data cannot be stored in the database. In this way, there are two ways to solve it:
First, you can use mysql's transaction mechanism and stored procedures to do a mysql scheduled task, and then make the database system add partitions at a specific time. In this way, the problems mentioned in the first method will basically not occur, but this method requires a certain understanding of MySQL transactions and stored procedures, and it is difficult to operate.
I know this method, but I haven’t implemented it yet. I will give relevant examples after I learn more about transactions and stored procedures.
In addition to the above scheduled task method, there is another way to split the partition, that is, still use the table structure with pmax partition before, and then use the split partition statement to split it pmax. Examples are as follows:
ALTER TABLE emp REORGANIZE PARTITION pmax INTO( PARTITION p2 VALUES LESS THAN (16), PARTITION pmax VALUES LESS THAN maxvalue )
然后我们再用查询分区情况的语句查询,便可以看到结果变成这样: 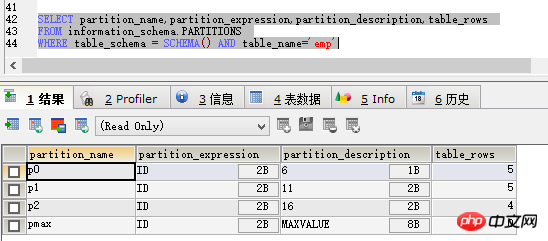
很显然,多出来了一个p2分区,拆分成功的同事不影响其他的功能。
那么这里分区拆分的语法整理如下:
alter table tablename reorganize partition 要拆分的分区名 into( partition 拆分后的分区名1 values less than (条件), partition 拆分后的分区名2 values lessthan (条件),...)
好了,到这里基本上算是完成了,但是我们知道数据库一般的操作都是增删改查,我们这里已经有了增改查,却自然也不能少了删。
按理说正常的生产环境的数据库应该是不能随意删除数据的,但是并不代表就不能删,反而有的时候还必须要删。
就比如我们项目中那个库,由于数据量太大,即便是分区了也依旧会在大量数据的情况下变慢。而与此同时,我们是按时间分区的,实际使用过程中只需要用到几天的数据,那么实际上很早以前的数据是可以删除不要的,或者说备份以后删除这个表的,这样就需要用到删除语句。
当然了,删除可以用delete,但是这样的话分区信息还在库中,实际上也是没必要要的,完全可以直接删除分区,因为删除分区的时候也同时会删除这个区内的所有数据。
示例之前我们先查一下之前插入的所有数据,如图: 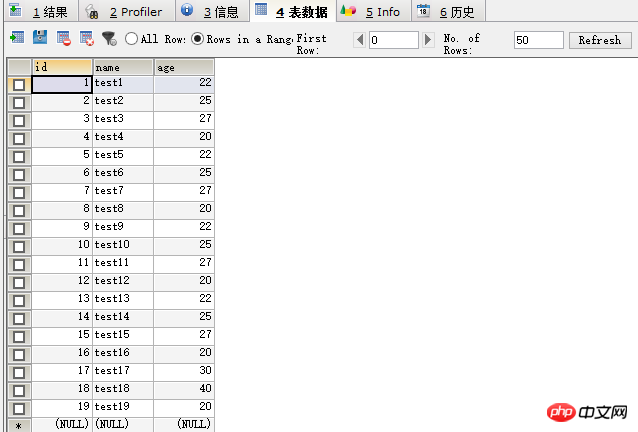
这里示例删除p0分区代码如下:
ALTER TABLE emp DROP PARTITION p0
然后先用查询分区的代码看一下,如图 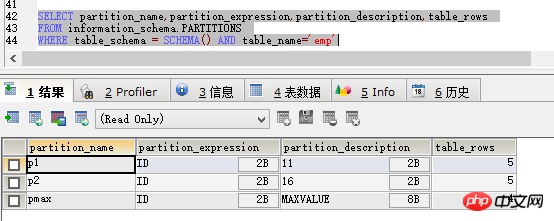
可以看到p0区不见了,在select * 一下,如图: 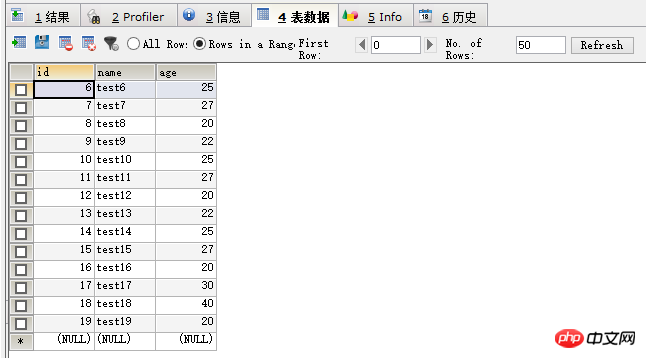
可以看到id小于6的数据已经没有了,数据删除成功。
以上就是mysql分区之range分区的详细介绍的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



