


Unlocking the Power of Apache Lucene: A Comprehensive Guide
Ever wondered about the engine behind top search applications like Elasticsearch and Solr? Apache Lucene, a high-performance Java search library, is the answer. This guide provides a foundational understanding of Lucene, even for those new to search engineering.
Learning Objectives:
(This article is part of the Data Science Blogathon.)
Table of Contents:
What is Apache Lucene?
Lucene's power lies in several key concepts. Let's examine them using a product catalog example:
{
"product_id": "1",
"title": "Wireless Noise Cancelling Headphones",
"brand": "Bose",
"category": ["Electronics", "Audio", "Headphones"],
"price": 300
}
{
"product_id": "2",
"title": "Bluetooth Mouse",
"brand": "Jelly Comb",
"category": ["Electronics", "Computer Accessories", "Mouse"],
"price": 30
}
{
"product_id": "3",
"title": "Wireless Keyboard",
"brand": "iClever",
"category": ["Electronics", "Computer Accessories", "Keyboard"],
"price": 40
}Document: The fundamental unit in Lucene. Each product entry is a document, uniquely identified by a document ID.
Field: Each attribute within a document (e.g., product_id, title, brand).
Term: A unit of search. Lucene preprocesses text to create terms (e.g., "wireless," "headphones").
| Document ID | Terms |
|---|---|
| 1 | title: wireless, noise, cancelling, headphones; brand: bose; category: electronics, audio, headphones |
| 2 | title: bluetooth, mouse; brand: jelly, comb; category: electronics, computer, accessories |
| 3 | title: wireless, keyboard; brand: iclever; category: electronics, computer, accessories |

Segment: An index can be divided into multiple segments, each acting as a self-contained index. Searches across segments are typically sequential.
Scoring: Lucene ranks document relevance using methods like TF-IDF (and others like BM25).
Term Frequency (TF): How often a term appears in a document.




Lucene Search Application Components
Lucene comprises two main parts:
IndexWriter): Indexes documents, performing text processing (tokenization, etc.) and creating the inverted index.
IndexSearcher): Executes searches using query objects.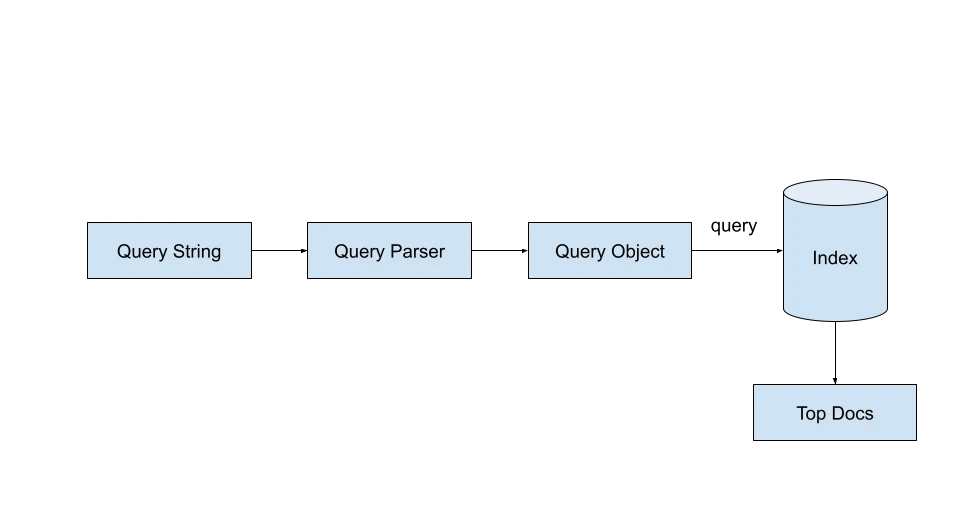
Supported Lucene Query Types
Lucene offers various query types:
Term Query: Matches documents containing a specific term. new TermQuery(new Term("brand", "jelly"))
Boolean Query: Combines other queries using Boolean logic.
Range Query: Matches documents with field values within a specified range.
Phrase Query: Matches documents containing a specific sequence of terms.
Function Query: Scores documents based on a field's value.
Building a Simple Lucene Search Application
The following Java code demonstrates a simple Lucene application:
(Code examples for indexer and searcher remain the same as in the original input)
Conclusion
Apache Lucene is a powerful tool for building high-performance search applications. This guide has covered the fundamentals, enabling you to create more advanced search solutions.
Key Takeaways:
IndexWriter and IndexSearcher are crucial for indexing and searching.Frequently Asked Questions
Q1. Does Lucene support Python? A. Yes, via PyLucene.
Q2. What open-source search engines are available? A. Solr, OpenSearch, Meilisearch, etc.
Q3. Does Lucene support semantic and vector search? A. Yes, with limitations on vector dimensions (currently 1024).
Q4. What relevance scoring algorithms does Lucene use? A. TF-IDF, BM25, etc.
Q5. What are some examples of complex Lucene queries? A. Fuzzy queries, span queries, etc.
(Note: Images are retained in their original format and position.)
The above is the detailed content of Introduction to Apache Lucene. For more information, please follow other related articles on the PHP Chinese website!
 attributeusage
attributeusage
 Website domain name valuation tool
Website domain name valuation tool
 What are the cloud servers?
What are the cloud servers?
 How to solve the problem of missing steam_api.dll
How to solve the problem of missing steam_api.dll
 Ethereum browser query digital currency
Ethereum browser query digital currency
 The main components that make up the CPU
The main components that make up the CPU
 What are the java file transfer methods?
What are the java file transfer methods?
 How to set the computer to automatically connect to WiFi
How to set the computer to automatically connect to WiFi
 Is Bitcoin trading allowed in China?
Is Bitcoin trading allowed in China?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



