


Uploading a CSV file to Django REST (especially in an atomic setting) is a simple task, but kept me puzzled until I found out some tricks I would be sharing with you.
In this article, I will be using postman (in place of a frontend) and will also share what you need to set on postman for request sending via pictures.
What we desire
Method
pip install pandas
For the value cell, click the 'Select Files' button and upload the CSV. Check the screenshot below

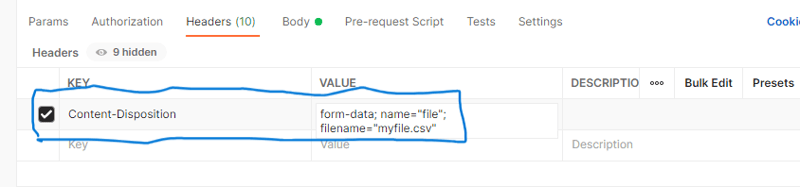
Under headers, set Content-Disposition and the value to form-data; name="file"; filename="your_file_name.csv". Replace your_file_name.csv with your actual file name. Check the screenshot below.
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
Explaining the code above:
The code begins with importing necessary packages, defining a class based view and setting a parser class (FileUploadParser). The first part of the post method in the class attempts to get the file from request.FILES and check its availability.
Then a minor validation checks that it is a CSV by checking the extension.
The next part loads it into a pandas dataframe (very much like a spreadsheet):
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
I will explain some of the arguments passed to the loading function:
skiprows
In reading the loaded csv file, it should be noted that the csv in this case is passed over a network, so some metadata like stuff is added to the beginning and end of the file. These things can be annoying and are not in comma separated value (csv) form so can actually raise errors in parsing. This explains why I used skiprows=3, to skip the first 3 rows containing metadata and header and land directly on the body of the csv. If you remove skiprowsor use a lesser number, perhaps you might get an error like: Error tokenizing data. C error or you might notice the data starting from the header.
dtype=str
Pandas likes to prove smart in trying to guess the datatype of certain columns. I wanted all values as string, so I used dtype=str
delimiter
Specifies how the cells are separated. Default is usually comma.
iloc[:-1]
I had to use iloc to slice the dataframe, removing the metadata at the end of the df.
Then, the next line df = df.where(pd.notnull(df), None) converts all NaNvalues to None. NaNis a stand-in value that pandas uses to rep None.
The next block is a bit tricky. We loop over every row in the dataframe, instantiate the row data with the BiodataModel, perform model-level validation (not serializer-level) with full_clean() method because bulk create bypasses Django validation, and then add our create operations to a list called bulk_data. Yeah , add not run yet ! Remember, we are trying to do an atomic operation (at batch level ) so we want all or None. Saving rows individually won’t give us all or none behaviour.
Then for the last significant part. Within a transaction.atomic() block (which provides all or none behaviour), we run BiodataModel.objects.bulk_create(bulk_data) to save all rows at once.
One more thing. Notice the index variable and the except block in the for loop. In the except block error message, I added 2 to the indexvariable derived from df.iterrows() because the value did not match exactly the row it was on, when looked at in an excel file. The except block catches any error and constructs an error message having the exact row number when opened in excel, so that the uploader can easily locate the line in the excel file!
Thanks for reading!!!
VERSIONS OF TOOLS USED
from rest_framework import status
from rest_framework.views import APIView
from rest_framework.parsers import FileUploadParser
from rest_framework.response import Response
from .models import BiodataModel
from django.db import transaction
import pandas as pd
class UploadCSVFile(APIView):
parser_classes = [FileUploadParser]
def post(self,request):
csv_file = request.FILES.get('file')
if not csv_file:
return Response({"error": "No file provided"}, status=status.HTTP_400_BAD_REQUEST)
# Validate file type
if not csv_file.name.endswith('.csv'):
return Response({"error": "File is not CSV type"}, status=status.HTTP_400_BAD_REQUEST)
df = pd.read_csv(csv_file, delimiter=',',skiprows=3,dtype=str).iloc[:-1]
df = df.where(pd.notnull(df), None)
bulk_data=[]
for index, row in df.iterrows():
try:
row_instance= BiodataModel(
name=row.get('name'),
age=row.get('age'),
address =row.get('address'))
row_instance.full_clean()
bulk_data.append(row_instance)
except Exception as e:
return Response({"error": f'Error at row {index + 2} -> {e}'}, status=status.HTTP_400_BAD_REQUEST)
try:
with transaction.atomic():
BiodataModel.objects.bulk_create(bulk_data)
except Exception as e:
return Response({"error": f'Bulk create error--{e}'}, status=status.HTTP_400_BAD_REQUEST)
return Response({"msg":"CSV file processed successfully"}, status=status.HTTP_201_CREATED)
The above is the detailed content of HOW TO UPLOAD A CSV FILE TO DJANGO REST. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



