


In this article, we will demonstrate a complete machine learning project workflow using Scikit-Learn. We will build a model to predict California housing prices based on various features, such as median income, house age, and average number of rooms. This project will guide you through each step of the process, including data loading, exploration, model training, evaluation, and visualization of results. Whether you're a beginner looking to understand the basics or an experienced practitioner seeking a refresher, this article will provide valuable insights into the practical application of machine learning techniques.
The California housing market is known for its unique characteristics and pricing dynamics. In this project, we aim to develop a machine learning model to predict house prices based on various features. We'll be using the California housing dataset, which includes various attributes such as median income, house age, average rooms, and more.
In this section, we will import the necessary libraries for data manipulation, visualization, and building our machine learning model.
import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error from sklearn.datasets import fetch_california_housing
We will load the California Housing dataset and create a DataFrame to organize the data. The target variable, which is the house price, will be added as a new column.
# Load the California Housing dataset california = fetch_california_housing() df = pd.DataFrame(california.data, columns=california.feature_names) df['PRICE'] = california.target
To keep the analysis manageable, we will randomly select 700 samples from the dataset for our study.
# Randomly Selecting 700 Samples df_sample = df.sample(n=700, random_state=42)
This section will provide an overview of the dataset, displaying the first five rows to understand the features and structure of our data.
# Overview of the data
print("First five rows of the dataset:")
print(df_sample.head())
First five rows of the dataset:
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
20046 1.6812 25.0 4.192201 1.022284 1392.0 3.877437 36.06
3024 2.5313 30.0 5.039384 1.193493 1565.0 2.679795 35.14
15663 3.4801 52.0 3.977155 1.185877 1310.0 1.360332 37.80
20484 5.7376 17.0 6.163636 1.020202 1705.0 3.444444 34.28
9814 3.7250 34.0 5.492991 1.028037 1063.0 2.483645 36.62
Longitude PRICE
20046 -119.01 0.47700
3024 -119.46 0.45800
15663 -122.44 5.00001
20484 -118.72 2.18600
9814 -121.93 2.78000
print(df_sample.info())
<class 'pandas.core.frame.DataFrame'> Index: 700 entries, 20046 to 5350 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 700 non-null float64 1 HouseAge 700 non-null float64 2 AveRooms 700 non-null float64 3 AveBedrms 700 non-null float64 4 Population 700 non-null float64 5 AveOccup 700 non-null float64 6 Latitude 700 non-null float64 7 Longitude 700 non-null float64 8 PRICE 700 non-null float64 dtypes: float64(9) memory usage: 54.7 KB
print(df_sample.describe())
MedInc HouseAge AveRooms AveBedrms Population \
count 700.000000 700.000000 700.000000 700.000000 700.000000
mean 3.937653 28.855714 5.404192 1.079266 1387.422857
std 2.085831 12.353313 1.848898 0.236318 1027.873659
min 0.852700 2.000000 2.096692 0.500000 8.000000
25% 2.576350 18.000000 4.397751 1.005934 781.000000
50% 3.480000 30.000000 5.145295 1.047086 1159.500000
75% 4.794625 37.000000 6.098061 1.098656 1666.500000
max 15.000100 52.000000 36.075472 5.273585 8652.000000
AveOccup Latitude Longitude PRICE
count 700.000000 700.000000 700.000000 700.000000
mean 2.939913 35.498243 -119.439729 2.082073
std 0.745525 2.123689 1.956998 1.157855
min 1.312994 32.590000 -124.150000 0.458000
25% 2.457560 33.930000 -121.497500 1.218500
50% 2.834524 34.190000 -118.420000 1.799000
75% 3.326869 37.592500 -118.007500 2.665500
max 7.200000 41.790000 -114.590000 5.000010
We will separate the dataset into features (X) and the target variable (y) and then split it into training and testing sets for model training and evaluation.
# Splitting the dataset into Train and Test sets
X = df_sample.drop('PRICE', axis=1) # Features
y = df_sample['PRICE'] # Target variable
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
In this section, we will create and train a Linear Regression model using the training data to learn the relationship between features and house prices.
# Creating and training the Linear Regression model lr = LinearRegression() lr.fit(X_train, y_train)
We will make predictions on the test set and calculate the Mean Squared Error (MSE) and R-squared values to evaluate the model's performance.
# Making predictions on the test set
y_pred = lr.predict(X_test)
# Calculating Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
print(f"\nLinear Regression Mean Squared Error: {mse}")
Linear Regression Mean Squared Error: 0.3699851092128846
Here, we will create a DataFrame to compare the actual house prices with the predicted prices generated by our model.
# Displaying Actual vs Predicted Values
results = pd.DataFrame({'Actual Prices': y_test.values, 'Predicted Prices': y_pred})
print("\nActual vs Predicted:")
print(results)
Actual vs Predicted:
Actual Prices Predicted Prices
0 0.87500 0.887202
1 1.19400 2.445412
2 5.00001 6.249122
3 2.78700 2.743305
4 1.99300 2.794774
.. ... ...
135 1.62100 2.246041
136 3.52500 2.626354
137 1.91700 1.899090
138 2.27900 2.731436
139 1.73400 2.017134
[140 rows x
2 columns]
In the final section, we will visualize the relationship between actual and predicted house prices using a scatter plot to assess the model's performance visually.
# Visualizing the Results
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue')
plt.xlabel('Actual Prices')
plt.ylabel('Predicted Prices')
plt.title('Actual vs Predicted House Prices')
# Draw the ideal line
plt.plot([0, 6], [0, 6], color='red', linestyle='--')
# Set limits to minimize empty space
plt.xlim(y_test.min() - 1, y_test.max() + 1)
plt.ylim(y_test.min() - 1, y_test.max() + 1)
plt.grid()
plt.show()
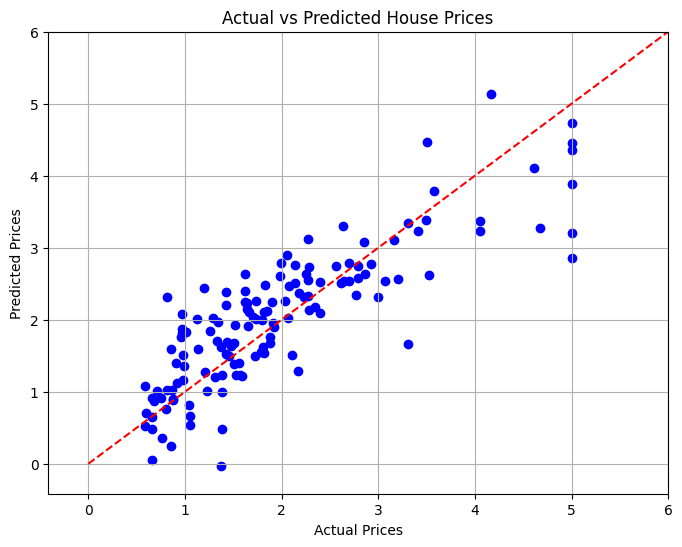
In this project, we developed a Linear Regression model to predict California housing prices based on various features. The Mean Squared Error was calculated to evaluate the model's performance, which provided a quantitative measure of prediction accuracy. Through visualization, we were able to see how well our model performed against actual values.
This project demonstrates the power of machine learning in real estate analytics and can serve as a foundation for more advanced predictive modeling techniques.
The above is the detailed content of Complete Machine Learning Workflow with Scikit-Learn: Predicting California Housing Prices. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



