Human education methods are also suitable for large models.
When raising children, people throughout the ages have talked about an important method: leading by example. That is to say, let yourself be an example for children to imitate and learn from, rather than simply telling them what to do. When training a large language model (LLM), we may also be able to use this method - demonstrate to the model.
Recently, Yang Diyi's team at Stanford University proposed a new framework DITTO that can align LLM with specific settings through a small number of demonstrations (examples of desired behavior provided by users). These examples can be obtained from the user's existing interaction logs, or by directly editing the output of LLM. This allows the model to efficiently understand and align user preferences for different users and tasks. 
- Paper title: Show, Don't Tell: Aligning Language Models with Demonstrated Feedback
- Paper address: https://arxiv.org/pdf/2406.00888
DITTO can be based on A small number of demos (fewer than 10) automatically creates a data set containing a large number of preference comparisons (a process called scaffolding) by tacitly recognizing that users prefer the LLM over the output of the original LLM and earlier iterations. Demo. Then, the demonstration and model output are combined into data pairs to obtain an enhanced data set. The language model can then be updated using alignment algorithms such as DPO. Additionally, the team also discovered that DITTO can be viewed as an online imitation learning algorithm, where data sampled from LLM is used to distinguish expert behavior. From this perspective, the team demonstrated that DITTO can achieve expert-superior performance through extrapolation. The team also verified the effect of DITTO through experiments. To align LLM, previous methods often require the use of thousands of pairs of comparison data, while DITTO can modify the behavior of the model with only a few demonstrations. This low-cost, rapid adaptation was made possible primarily by the team’s core insight: Online comparison data is easily available via demonstrations.
The language model can be viewed as a policy π(y|x), which results in a distribution of prompt x and completion result y. The goal of RLHF is to train an LLM to maximize a reward function r (x, y) that evaluates the quality of the prompt-completion result pair (x, y). Typically, a KL divergence is also added to prevent the updated model from deviating too far from the base language model (π_ref). Overall, the optimization goals of the RLHF method are:
This is to maximize the expected reward on the prompt distribution p, which is affected by the KL constraint regulated by α. Typically, the optimization goal uses a comparison data set of the form {(x, y^w, y^l )}, where the "winning" completion result y^w is better than the "losing" completion result y ^l, recorded as y^w ⪰ y^l. In addition, here we mark the small expert demonstration data set as D_E, and assume that these demonstrations are generated by the expert policy π_E, which can maximize the prediction reward. DITTO can directly use language model output and expert demonstrations to generate comparison data. That is, unlike generative paradigms for synthetic data, DITTO does not require a model that already performs well on a given task. DITTO’s key insight is that the language model itself, coupled with expert demonstrations, can lead to a comparative data set for alignment, which eliminates the need to collect large amounts of pairwise preference data. This results in a contrast-like target where expert demonstrations are positive examples. Generate comparison. Suppose we sample a completion result y^E ∼ π_E (・|x) from the expert policy. Then it can be considered that the rewards corresponding to samples sampled from other policies π are lower than or equal to the rewards of samples sampled from π_E. Based on this observation, the team constructed comparative data (x, y^E, y^π ), where y^E ⪰ y^π. Although such comparative data are derived from strategies rather than individual samples, previous research has demonstrated the effectiveness of this approach. A natural approach for DITTO is to use this data set and a readily available RLHF algorithm to optimize (1). Doing so improves the probability of expert responses while reducing the probability of the current model sample, unlike standard fine-tuning methods which only do the former. The key is that by using samples from π, an unbounded preference data set can be constructed with a small number of demonstrations. However, the team found that it could be done even better by taking into account the temporal aspects of the learning process. From comparison to ranking. Using only comparative data from experts and a single policy π may not be sufficient to obtain good performance. Doing so will only reduce the likelihood of a particular π, leading to the overfitting problem - which also plagues SFT with little data. The team proposes that it is also possible to consider data generated by all policies learned over time during RLHF, similar to replay in reinforcement learning. Let the initial strategy in the first round of iteration be π_0. A data set D_0 is obtained by sampling this strategy. A comparison data set for RLHF can then be generated based on this, which can be denoted as D_E ⪰ D_0. Using these derived comparison data, π_0 can be updated to get π_1. By definition, also holds. After that, continue using π_1 to generate comparison data, and D_E ⪰ D_1. Continue this process, continually generating increasingly diverse comparison data using all of the previous strategies. The team calls these comparisons "replay comparisons." Although this method makes sense in theory, overfitting may occur if D_E is small. However, comparisons between policies can also be considered during training if it is assumed that the policy will improve after each iteration. Unlike comparison with experts, we cannot guarantee that the strategy will be better after each iteration, but the team found that the overall model is still improving after each iteration. This may be because both reward modeling and (1) It's convex. In this way, the comparison data can be sampled according to the following ranking:
By adding these "inter-model" and "replay" comparison data, the effect obtained is that the likelihood of early samples (such as the samples in D_1) will be higher than Later ones (as in D_t) press lower, thus smoothing the implicit reward picture. In practical implementation, the team's approach is to not only use comparison data with experts, but also aggregate some comparison data between these models. A practical algorithm. In practice, the DITTO algorithm is an iterative process consisting of three simple components, as shown in Algorithm 1.
First, run supervised fine-tuning on the expert demo set, performing a limited number of gradient steps. Let this be the initial policy π_0. Second step, sample comparison data: during training, for each of the N demonstrations in D_E, a new dataset D_t is constructed by sampling M completion results from π_t, They are then added to the ranking according to strategy (2). When sampling comparison data from equation (2), each batch B consists of 70% "online" comparison data D_E ⪰ D_t and 20% "replay" comparison data D_E ⪰ D_{i
where σ is the logistic function from the Bradley-Terry preference model. During each update, the reference model from the SFT strategy is not updated to avoid deviating too far from the initialization. Derivating DITTO into Online Imitation Learning DITTO can be derived from an online imitation learning perspective, where a combination of expert demonstrations and online data are used to learn the reward function and policy simultaneously. Specifically, the strategy player maximizes the expected reward? (π, r), while the reward player minimizes the loss min_r L (D^π, r) on the online data set D^π. More specifically, the The team’s approach is to use the policy objective in (1) and the standard reward modeling loss to instantiate the optimization problem:
Derivating DITTO, the first step in simplifying (3) is to solve its internal policy maximum issues. Fortunately, the team found based on previous research that the policy objective ?_KL has a closed-form solution of the form where Z (x) is the partition function of the normalized distribution. Notably, this creates a bijective relationship between the policy and the reward function, which can be used to eliminate internal optimizations. By rearranging this solution, the reward function can be written as: In addition, previous research has shown that this reparameterization can represent arbitrary reward functions. Therefore, by substituting into equation (3), the variable r can be changed into π, thereby obtaining the DITTO objective: Please note that similar to DPO, the reward function is estimated implicitly here. The difference from DPO is that DITTO relies on an online preference data set D^π. Why is DITTO better than just using SFT? One reason why DITTO performs better is that it uses much more data than SFT by generating comparison data. Another reason is that in some cases online imitation learning methods outperform presenters, whereas SFT can only imitate demonstrations. The team also conducted empirical research to prove the effectiveness of DITTO. Please refer to the original paper for the specific settings of the experiment. We only focus on the experimental results here. Research results based on static benchmarks The evaluation of static benchmarks used GPT-4, and the results are shown in Table 1.
Secara purata, DITTO mengatasi semua kaedah lain: 71.67% kadar kemenangan purata pada CMCC, 82.50% kadar kemenangan purata pada CCAT50; 77.09% kadar kemenangan purata keseluruhan. Pada CCAT50, untuk semua pengarang, DITTO tidak mencapai kemenangan keseluruhan dalam hanya satu daripada mereka. Pada CMCC, untuk semua pengarang, DITTO mengatasi separuh daripada penanda aras di seluruh papan, diikuti dengan beberapa pukulan yang mendorong kemenangan sebanyak 30%. Walaupun SFT menunjukkan prestasi yang baik, DITTO meningkatkan purata kadar kemenangannya sebanyak 11.7% berbanding dengannya. Kajian pengguna: Menguji keupayaan untuk membuat generalisasi kepada tugasan semula jadiSecara keseluruhan, hasil kajian pengguna adalah konsisten dengan keputusan pada penanda aras statik. DITTO mengatasi kaedah yang berbeza dari segi keutamaan untuk demo sejajar, seperti yang ditunjukkan dalam Jadual 2: di mana DITTO (kadar kemenangan 72.1%) > SFT (60.1%) > beberapa pukulan (48.1%) > segera kendiri (44.2%) > pukulan sifar (25.0%).
Sebelum menggunakan DITTO, pengguna mesti mempertimbangkan beberapa prasyarat, daripada berapa banyak demo yang mereka ada kepada berapa banyak contoh negatif mesti diambil sampel daripada model bahasa. Pasukan itu meneroka kesan keputusan ini dan memberi tumpuan kepada CMCC kerana ia merangkumi lebih banyak misi daripada CCAT. Selain itu, mereka menganalisis kecekapan sampel demonstrasi berbanding maklum balas berpasangan. Pasukan menjalankan kajian ablasi ke atas komponen DITTO. Seperti yang ditunjukkan dalam Rajah 2 (kiri), meningkatkan bilangan lelaran DITTO biasanya boleh meningkatkan prestasi.
Dapat dilihat apabila bilangan lelaran dinaikkan daripada 1 kepada 4, kadar kemenangan yang dinilai oleh GPT-4 akan meningkat sebanyak 31.5%. Peningkatan ini tidak monotonik - pada lelaran 2, prestasi menurun sedikit (-3.4%). Ini kerana lelaran awal mungkin berakhir dengan sampel yang lebih bising, sekali gus mengurangkan prestasi. Sebaliknya, seperti yang ditunjukkan dalam Rajah 2 (tengah), meningkatkan bilangan contoh negatif secara monotonik meningkatkan prestasi DITTO. Tambahan pula, apabila lebih banyak contoh negatif dijadikan sampel, varians prestasi DITTO berkurangan.
Selain itu, seperti yang ditunjukkan dalam Jadual 3, kajian ablasi pada DITTO mendapati bahawa mengalih keluar mana-mana komponennya mengakibatkan kemerosotan prestasi. Sebagai contoh, jika anda melepaskan pensampelan berulang dalam talian, berbanding menggunakan DITTO, kadar kemenangan akan turun daripada 70.1% kepada 57.3%. Dan jika π_ref dikemas kini secara berterusan semasa proses dalam talian, ia akan menyebabkan penurunan prestasi yang ketara: daripada 70.1% kepada 45.8%. Pasukan itu membuat spekulasi bahawa sebabnya ialah pengemaskinian π_ref boleh menyebabkan overfitting. Akhir sekali, kita juga boleh melihat dalam Jadual 3 kepentingan data perbandingan ulang dan antara strategi. Salah satu kelebihan utama DITTO ialah kecekapan sampelnya. Pasukan menilai ini dan keputusan ditunjukkan dalam Rajah 2 (kanan sekali lagi, kadar kemenangan yang dinormalkan dilaporkan di sini); Pertama sekali, anda dapat melihat bahawa kadar kemenangan DITTO akan meningkat dengan cepat pada permulaannya. Apabila bilangan tunjuk cara berubah dari 1 hingga 3, prestasi yang dinormalisasi meningkat dengan ketara dengan setiap peningkatan (0% → 5% → 11.9%). Namun, apabila bilangan demo terus meningkat, peningkatan hasil berkurangan (11.9% → 15.39% apabila meningkat daripada 4 kepada 7), yang menunjukkan bahawa apabila bilangan demo meningkat, prestasi DITTO akan menjadi tepu. Di samping itu, pasukan membuat spekulasi bahawa bukan sahaja bilangan demonstrasi akan menjejaskan prestasi DITTO, tetapi juga kualiti demonstrasi, tetapi ini ditinggalkan untuk penyelidikan masa depan. Bagaimanakah keutamaan berpasangan berbanding demo? Satu andaian teras DITTO ialah kecekapan sampel datang daripada demonstrasi. Secara teori, jika pengguna mempunyai set demonstrasi yang sempurna dalam fikiran, kesan yang sama boleh dicapai dengan menganotasi banyak pasangan data keutamaan. Pasukan melakukan percubaan rapat, menggunakan sampel output daripada Compliance Mistral 7B, dan mempunyai 500 pasang data keutamaan yang turut dianotasi oleh salah seorang pengarang yang menyediakan demo kajian pengguna. Ringkasnya, mereka membina set data keutamaan berpasangan D_pref = {(x, y^i , y^j )}, dengan y^i ≻ y^j. Mereka kemudiannya mengira kadar kemenangan untuk 20 pasangan hasil sampel daripada dua model - satu dilatih pada 4 tunjuk cara menggunakan DITTO, dan satu lagi dilatih pada pasangan data pilihan {0...500} hanya menggunakan DPO .
Apabila mensampel data keutamaan berpasangan hanya daripada π_ref, dapat diperhatikan bahawa pasangan data yang dijana terletak di luar taburan yang ditunjukkan - keutamaan berpasangan tidak melibatkan tingkah laku yang ditunjukkan oleh pengguna (hasil untuk dasar Asas dalam Rajah 3, warna biru). Walaupun apabila mereka memperhalusi π_ref menggunakan demonstrasi pengguna, ia masih memerlukan lebih daripada 500 pasang data keutamaan untuk memadankan prestasi DITTO (hasil untuk dasar diperhalusi Demo dalam Rajah 3, oren). The above is the detailed content of It only takes a few demonstrations to align large models. The DITTO proposed by Yang Diyi's team is so efficient.. For more information, please follow other related articles on the PHP Chinese website!






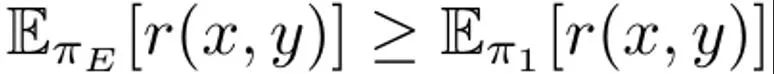 also holds. After that, continue using π_1 to generate comparison data, and D_E ⪰ D_1. Continue this process, continually generating increasingly diverse comparison data using all of the previous strategies. The team calls these comparisons "replay comparisons."
also holds. After that, continue using π_1 to generate comparison data, and D_E ⪰ D_1. Continue this process, continually generating increasingly diverse comparison data using all of the previous strategies. The team calls these comparisons "replay comparisons." 



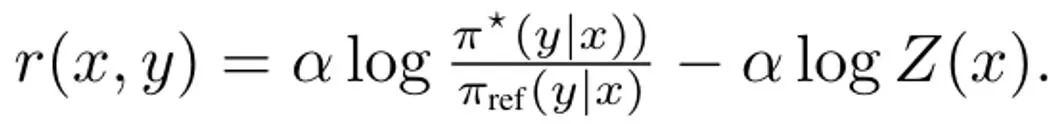
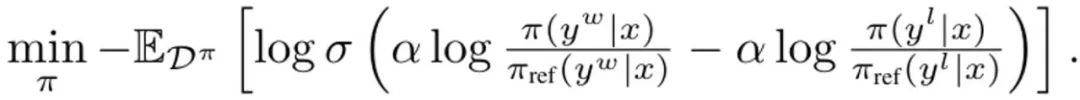





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



