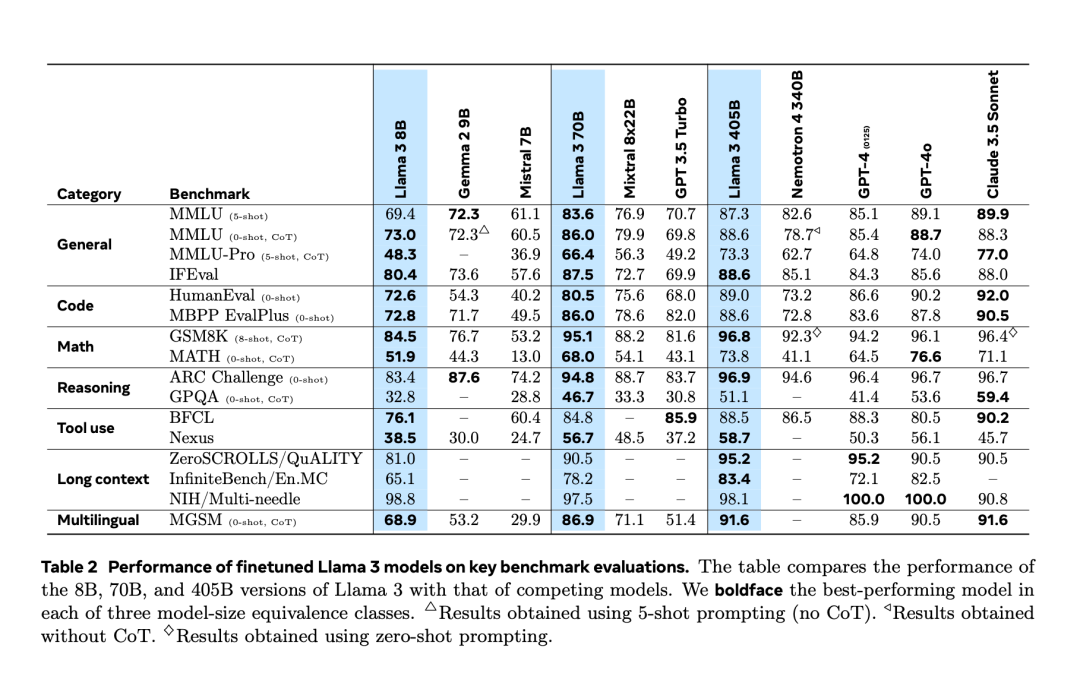
After experiencing an “accidental leak” two days in advance, Llama 3.1 was finally officially released last night. Llama 3.1 extends the context length to 128K and is available in 8B, 70B and 405B versions, once again single-handedly raising the bar for competition on large model tracks. For the AI community, the most important significance of Llama 3.1 405B is that it refreshes the upper limit of the capabilities of the open source basic model. Meta officials said that in a series of tasks, its performance is comparable to the best closed source model. The table below shows how the current Llama 3 Series models perform on key benchmarks. It can be seen that the performance of the 405B model is very close to GPT-4o.
At the same time, Meta published the paper "The Llama 3 Herd of Models", revealing the research details of the Llama 3 series models so far.

- to B is using 8K context length After pre-training, continuous training is performed with 128K context length, supporting multiple languages and tool usage.
Meta enhances the preprocessing of the Llama model and the Curation pipelines of pre-training data, as well as the quality assurance and filtering methods of post-training data.
Meta believes that there are three key levers for the development of high-quality underlying models: data, scale and complexity management.
-
- Data:
Meta has improved both quantity and quality of pre-training and post-training data compared to earlier Llama versions. Llama 3 is pre-trained on a corpus of approximately 15 trillion multilingual tokens, while Llama 2 only uses 1.8 trillion tokens.
Scale:
Trained models are much larger than previous Llama models: the flagship language model uses 3.8 x 10^25 floating-point operations (FLOPs) for pre-training, exceeding the largest version of Llama 2 by nearly 50 times. -
Complexity Management:
According to Scaling law, Meta’s flagship model has approximately calculated the optimal size, but the training time of smaller models has far exceeded the calculated optimal time. The results show that these smaller models outperform computationally optimal models for the same inference budget. In the post-training phase, Meta uses the 405B flagship model to further improve the quality of smaller models such as 70B and 8B. - Pre-training 405B on 15.6T tokens (3.8x10^25 FLOPs) was a major challenge, Meta optimized the entire training stack and used over 16K H100 GPUs.
As PyTorch founder and Meta Distinguished Engineer Soumith Chintala said, the Llama3 paper reveals a lot of cool details, one of which is the construction of the infrastructure.
- 1. During training, Meta improves the Chat model through multiple rounds of alignment, including supervised fine-tuning (SFT), rejection sampling, and direct preference optimization. Most SFT samples are generated from synthetic data.
- Die Forscher haben beim Design mehrere Entscheidungen getroffen, um die Skalierbarkeit des Modellentwicklungsprozesses zu maximieren. Beispielsweise wurde eine standardmäßige dichte Transformer-Modellarchitektur mit nur geringfügigen Anpassungen anstelle einer Expertenmischung gewählt, um die Trainingsstabilität zu maximieren. Ebenso wird ein relativ einfaches Post-Training-Verfahren angewendet, das auf überwachter Feinabstimmung (SFT), Ablehnungsstichprobe (RS) und direkter Präferenzoptimierung (DPO) basiert, und nicht auf komplexeren Reinforcement-Learning-Algorithmen, die tendenziell weniger stabil sind und schwierigere Erweiterung.
- Im Rahmen des Entwicklungsprozesses von Llama 3 entwickelte das Meta-Team auch multimodale Erweiterungen des Modells, die ihm Fähigkeiten in den Bereichen Bilderkennung, Videoerkennung und Sprachverständnis verleihen. Diese Modelle befinden sich noch in der aktiven Entwicklung und sind noch nicht zur Veröffentlichung bereit, aber der Artikel stellt die Ergebnisse vorläufiger Experimente mit diesen multimodalen Modellen vor.
- Meta hat seine Lizenz aktualisiert, um Entwicklern die Nutzung der Ausgabe von Llama-Modellen zur Verbesserung anderer Modelle zu ermöglichen.
- Am Ende dieses Artikels haben wir auch eine lange Liste von Mitwirkenden gesehen: fenye1 Diese Reihe von Faktoren hat heute schließlich die Llama 3-Serie hervorgebracht.
- Natürlich ist die Verwendung des Lama-Modells im Maßstab 405B für normale Entwickler eine Herausforderung und erfordert viel Rechenressourcen und Fachwissen.
- Nach dem Start ist das Ökosystem von Llama 3.1 bereit. Über 25 Partner bieten Dienste an, die mit dem neuesten Modell funktionieren, darunter Amazon Cloud Technologies, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, Snowflake und mehr.

Weitere technische Details finden Sie im Originalpapier.
The above is the detailed content of How to create an open source model that can defeat GPT-4o? Regarding Llama 3.1 405B, Meta is written in this paper. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



