The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
This article was completed by HMI Lab. HMI LabRelying on the two major platforms of Peking University’s National Engineering Research Center for Video and Visual Technology and the National Key Laboratory of Multimedia Information Processing, it has long been engaged in research in the direction of machine learning, multi-modal learning and embodied intelligence. The first author of this work is Dr. Liu Jiaming, whose research direction is multi-modal embodied large models and continuous learning technology for the open world. The second author of this work is Liu Mengzhen, whose research direction is vision basic model and robot manipulation. The instructor is Chen Shanghang, a researcher at the School of Computer Science at Peking University, a doctoral supervisor, and a young liberal scholar. Engaged in research on multi-modal large models and embodied intelligence, he has achieved a series of important research results. He has published more than 80 papers in top artificial intelligence journals and conferences, and has been cited by Google more than 9,700 times. Won the Best Paper Award from AAAI, the world's top artificial intelligence conference, and ranked first in Trending Research, the world's largest academic source code repository. In order to give the robot end-to-end reasoning and manipulation capabilities, this article innovatively integrates the visual encoder with an efficient state space language model to build a new RoboMamba multi-modal large model, making it capable of visual common sense tasks and robots reasoning capabilities on related tasks, and have achieved advanced performance. At the same time, this article found that when RoboMamba has strong reasoning capabilities, we can enable RoboMamba to master multiple manipulation posture prediction capabilities through extremely low training costs.

Paper: RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Paper link: https://arxiv.org/abs/2406.04339
Project homepage: https:// sites.google.com/view/robomamba-web
Github: https://github.com/lmzpai/roboMamba

Figure 1. Robot-related capabilities of RoboMamba, including tasks Planning, prompt mission planning, long-range mission planning, maneuverability judgment, maneuverability generation, future and past prediction, end effector pose prediction, etc. A basic goal of robot manipulation is to enable the model to understand the visual scene and perform actions. Although existing multimodal large models of robots (MLLM) can handle a series of basic tasks, they still face challenges in two aspects: 1) Insufficient reasoning ability to handle complex tasks; 2) The computational cost of MLLM fine-tuning and inference is relatively high high. A recently proposed state space model (SSM), namely Mamba, possesses linear inference complexity while demonstrating promising capabilities in sequence modeling. Inspired by this, we launched an end-to-end robot MLLM—RoboMamba, which uses the Mamba model to provide robot reasoning and action capabilities while maintaining efficient fine-tuning and reasoning capabilities. Specifically, we first integrate the visual encoder with Mamba to align visual data with language embeddings through joint training, giving our model visual common sense and robot-related reasoning capabilities. To further enhance RoboMamba's manipulation pose prediction capabilities, we explore an efficient fine-tuning strategy using only a simple Policy Head. We found that once RoboMamba has sufficient reasoning capabilities, it can master multiple operational skills with very few fine-tuning parameters (0.1% of the model) and fine-tuning time (20 minutes). In experiments, RoboMamba demonstrated excellent reasoning capabilities on general and robotic evaluation benchmarks, as shown in Figure 2. At the same time, our model demonstrates impressive manipulation pose prediction capabilities in simulations and real-world experiments, with inference speeds up to 7 times faster than existing robotic MLLMs. 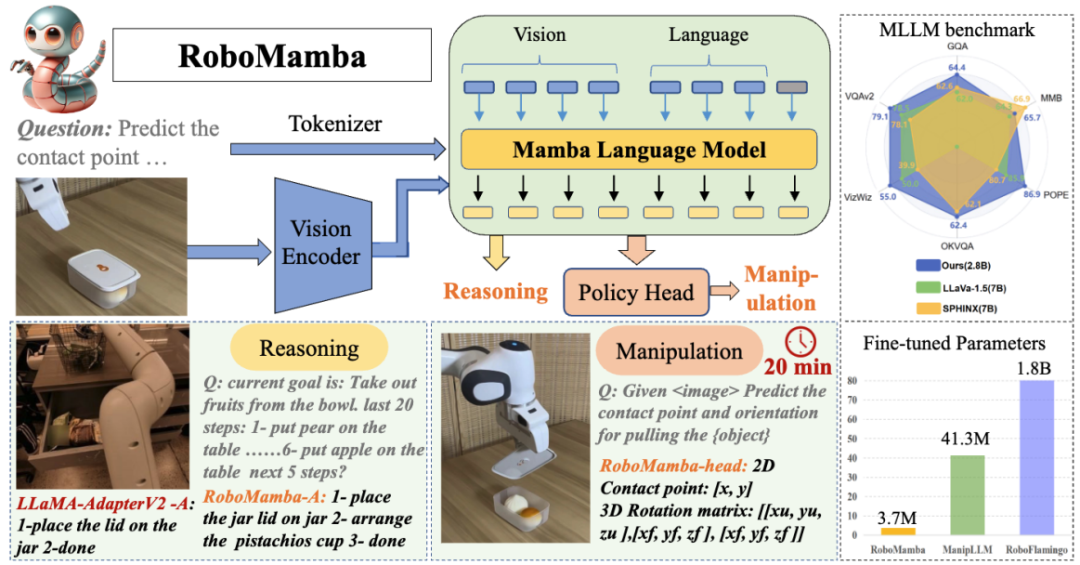
Figure 2. Overview: Robomamba is an efficient multi-modal large model of robots with powerful reasoning and operation capabilities. RoboMamba-2.8B achieves competitive inference performance with other 7B MLLMs on general-purpose MLLM benchmarks while demonstrating long-range inference capabilities in robotic tasks. Subsequently, we introduced an extremely efficient fine-tuning strategy to give RoboMamba the ability to predict manipulation poses, and it only takes 20 minutes to fine-tune a simple strategy head. The main contributions of this article are summarized as follows:
- We innovatively integrate the visual encoder with the efficient Mamba language model to build a new end-to-end multi-modal large model of robot, RoboMamba , which has visual common sense and comprehensive reasoning capabilities related to robots.
- In order to equip RoboMamba with end-effector manipulation pose prediction capabilities, we explored an efficient fine-tuning strategy using a simple Policy Head. We found that once RoboMamba reaches sufficient reasoning capabilities, it can master manipulation pose prediction skills at very low cost.
- In our extensive experiments, RoboMamba performs well on general and robotic inference evaluation benchmarks, and demonstrates impressive pose prediction results in simulators and real-world experiments.
Data scaling up has significantly promoted the development of large language models (LLMs) research, demonstrating significant reasoning and generalization capabilities in natural language processing (NLP) progress. In order to understand multimodal information, multimodal large language models (MLLMs) emerged, giving LLMs the ability to follow visual instructions and understand scenes. Inspired by the powerful capabilities of MLLMs in general-purpose environments, recent research aims to apply MLLMs to the field of robot operation. Some research efforts enable robots to understand natural language and visual scenes and automatically generate mission plans. Other research works exploit the inherent capabilities of MLLMs to enable them to predict operating poses. Robot operation involves interacting with objects in a dynamic environment, requiring human-like reasoning capabilities to understand the semantic information of the scene, as well as powerful manipulation pose prediction capabilities. Although existing robot-based MLLMs can handle a range of basic tasks, they still face challenges in two aspects. 1) First, the reasoning ability of pre-trained MLLMs in robotics scenarios was found to be insufficient. As shown in Figure 2, this shortcoming creates challenges when fine-tuned robotic MLLMs encounter complex reasoning tasks. 2) Secondly, due to the high computational complexity of existing MLLM attention mechanisms, fine-tuning MLLMs and using them to generate robot operating actions will incur higher computational costs. In order to balance reasoning ability and efficiency, several studies have emerged in the field of NLP. In particular, Mamba introduces the innovative Selective State Space Model (SSM), which facilitates context-aware reasoning while maintaining linear complexity. Inspired by this, we asked a question: "Can we develop an efficient robotic MLLM that not only has strong reasoning capabilities, but also acquires robotic operation skills in a very economical way?"
For robot visual reasoning, our Robo Mamba generates language based on images 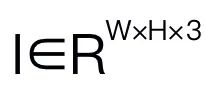 and language questions
and language questions 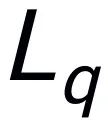 The answer is
The answer is 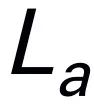 , expressed as
, expressed as 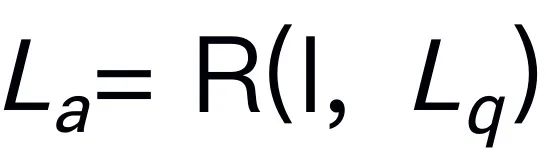 .Reasoning answers often contain separate subtasks
.Reasoning answers often contain separate subtasks  for a question
for a question  . For example, when faced with a planning problem such as "How to clear the table?" responses typically include steps such as "Step 1: Pick up the object" and "Step 2: Put the object into the box." For action prediction, we utilize an efficient and simple policy head π to predict actions
. For example, when faced with a planning problem such as "How to clear the table?" responses typically include steps such as "Step 1: Pick up the object" and "Step 2: Put the object into the box." For action prediction, we utilize an efficient and simple policy head π to predict actions  . Following previous work, we use 6-DoF to express the end-effector pose of the Franka Emika Panda robotic arm. The 6 degrees of freedom include the end effector position
. Following previous work, we use 6-DoF to express the end-effector pose of the Franka Emika Panda robotic arm. The 6 degrees of freedom include the end effector position 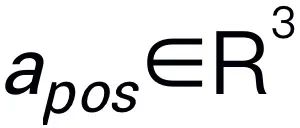 representing the three-dimensional coordinates and the direction
representing the three-dimensional coordinates and the direction  representing the rotation matrix. If training on a grasping task, we add the gripper state to the pose prediction, enabling 7-DoF control.
This article chooses Mamba as the large language model. Mamba is composed of many Mamba blocks, the most critical component is SSM. SSM is designed based on a continuous system that projects a 1D input sequence
representing the rotation matrix. If training on a grasping task, we add the gripper state to the pose prediction, enabling 7-DoF control.
This article chooses Mamba as the large language model. Mamba is composed of many Mamba blocks, the most critical component is SSM. SSM is designed based on a continuous system that projects a 1D input sequence 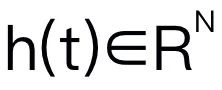 to a 1D output sequence
to a 1D output sequence 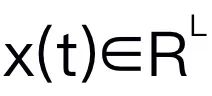 through hidden states
through hidden states  . SSM consists of three key parameters: state matrix
. SSM consists of three key parameters: state matrix  , input matrix
, input matrix  , and output matrix
, and output matrix  . The SSM can be expressed as:
. The SSM can be expressed as: 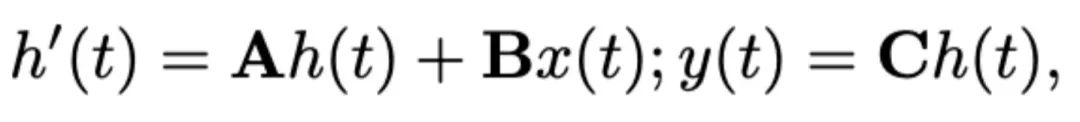
Recent SSMs (e.g., Mamba) are constructed as discrete continuous systems using the time scale parameter Δ. This parameter converts the continuous parameters A and B into discrete parameters  and
and  . The discretization adopts the zero-order preserving method, which is defined as follows:
. The discretization adopts the zero-order preserving method, which is defined as follows: 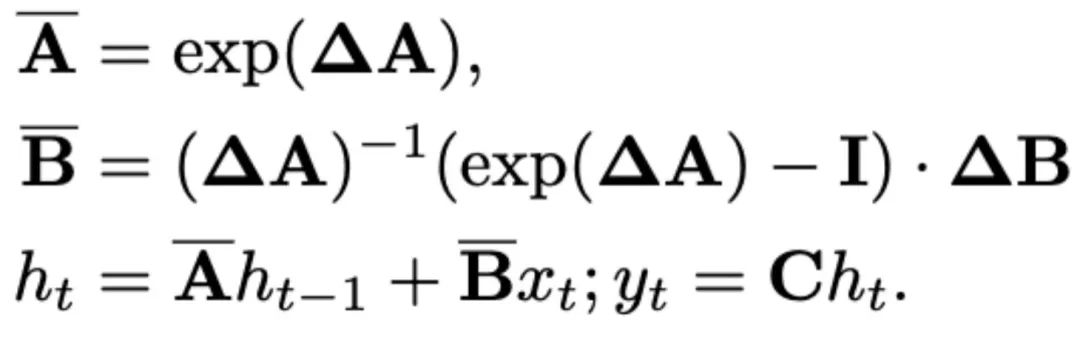
Mamba introduces a selective scanning mechanism (S6) to form its SSM operation in each Mamba block. SSM parameters updated to  for better content-aware inference. The details of the Mamba block are shown in Figure 3 below. 2. RoboMamba model structure
for better content-aware inference. The details of the Mamba block are shown in Figure 3 below. 2. RoboMamba model structure 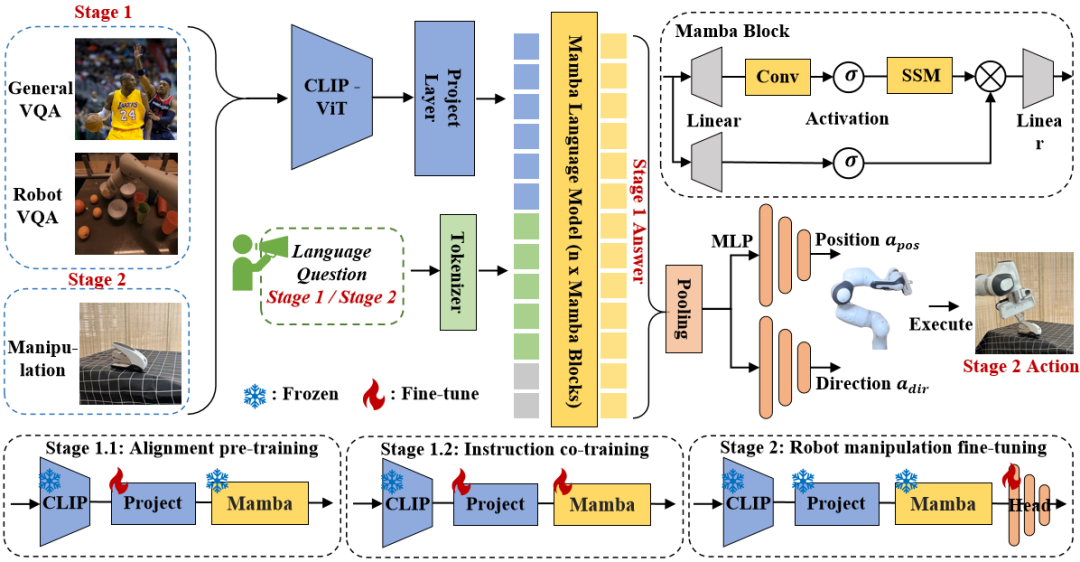
Figure 3. Robomamba overall framework. RoboMamba projects images into Mamba’s language embedding space through visual encoders and projection layers, which are then concatenated with text tokens and fed into the Mamba model. To predict the position and orientation of the end effector, we introduce a simple MLP policy head and use a pooling operation to generate global tokens from language output tokens as input. RoboMamba’s training strategy. For model training, we divide the training process into two stages. In Stage 1, we introduce aligned pre-training (Stage 1.1) and instruction co-training (Stage 1.2) to equip RoboMamba with common sense reasoning and robot-related reasoning capabilities. In Stage 2, we propose robot operation fine-tuning to efficiently empower RoboMamba with Low-Level operation skills. To equip RoboMamba with visual reasoning and operation capabilities, we built an efficient MLLM architecture starting from pre-trained large language models (LLMs) and vision models. As shown in Figure 3 above, we use the CLIP visual encoder to extract visual features 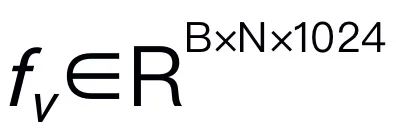 from the input image I, where B and N represent the batch size and the number of tokens respectively. Unlike recent MLLMs, we do not employ visual encoder ensemble techniques, which use multiple backbone networks (i.e., DINOv2, CLIP-ConvNeXt, CLIP-ViT) for image feature extraction. Integration introduces additional computational costs, severely affecting the practicality of robotic MLLM in the real world. Therefore, we demonstrate that simple and straightforward model design can also achieve powerful inference capabilities when high-quality data and appropriate training strategies are combined. To make the LLM understand visual features, we use a multilayer perceptron (MLP) to connect the visual encoder to the LLM. With this simple cross-modal connector, RoboMamba can transform visual information into a language embedding space
from the input image I, where B and N represent the batch size and the number of tokens respectively. Unlike recent MLLMs, we do not employ visual encoder ensemble techniques, which use multiple backbone networks (i.e., DINOv2, CLIP-ConvNeXt, CLIP-ViT) for image feature extraction. Integration introduces additional computational costs, severely affecting the practicality of robotic MLLM in the real world. Therefore, we demonstrate that simple and straightforward model design can also achieve powerful inference capabilities when high-quality data and appropriate training strategies are combined. To make the LLM understand visual features, we use a multilayer perceptron (MLP) to connect the visual encoder to the LLM. With this simple cross-modal connector, RoboMamba can transform visual information into a language embedding space 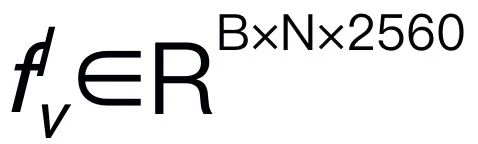 . Please note that model efficiency is crucial in the field of robotics, as robots need to respond quickly to human instructions. Therefore, we choose Mamba as our large language model due to its context-aware reasoning capabilities and linear computational complexity. Textual prompts are encoded into an embedding space
. Please note that model efficiency is crucial in the field of robotics, as robots need to respond quickly to human instructions. Therefore, we choose Mamba as our large language model due to its context-aware reasoning capabilities and linear computational complexity. Textual prompts are encoded into an embedding space 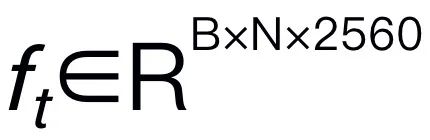 using a pretrained tokenizer, then concatenated (cat) with visual tokens and fed into Mamba. We leverage Mamba's powerful sequence modeling to understand multimodal information and use effective training strategies to develop visual reasoning capabilities (as described in the next section). The output token (
using a pretrained tokenizer, then concatenated (cat) with visual tokens and fed into Mamba. We leverage Mamba's powerful sequence modeling to understand multimodal information and use effective training strategies to develop visual reasoning capabilities (as described in the next section). The output token (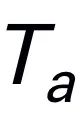 ) is then decoded (det) to generate a natural language response
) is then decoded (det) to generate a natural language response 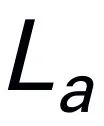 . The forward process of the model can be expressed as follows:
. The forward process of the model can be expressed as follows: 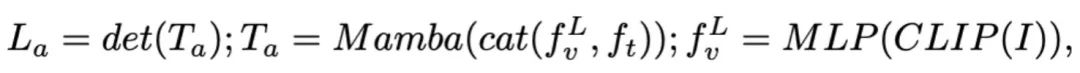
3.RoboMamba general vision and robot reasoning ability trainingAfter building the RoboMamba architecture, the next goal is to train our model to learn general visual reasoning and robot-related reasoning abilities. As shown in Figure 3, we divide the training of Stage 1 into two sub-steps: alignment pre-training (Stage 1.1) and instruction co-training (Stage 1.2). Specifically, unlike previous MLLM training methods, we aim to enable RoboMamba to understand general vision and robotics scenarios. Given that the field of robotics involves many complex and novel tasks, RoboMamba requires stronger generalization capabilities. Therefore, we adopted a co-training strategy in Stage 1.2 to combine high-level robot data (e.g., mission planning) with general instruction data. We find that co-training not only results in more generalizable robot policies, but also results in enhanced general-scenario reasoning capabilities due to complex reasoning tasks in robot data. The training details are as follows: - Stage 1.1: Alignment pre-training.
We adopt LLaVA filtered 558k image-text paired dataset for cross-modal alignment. As shown in Figure 3, we freeze the parameters of the CLIP encoder and Mamba language model and only update the projection layer. In this way, we can align image features with pre-trained Mamba word embeddings. - Stage 1.2: Command to train together.
In this stage, we first follow previous MLLM work for general visual instruction data collection. We employ the 655K LLaVA Hybrid Instruction Dataset and the 400K LRV-Instruct Dataset for learning visual instruction following and mitigating hallucinations, respectively. It is important to note that mitigating hallucinations plays an important role in robotic scenarios because robotic MLLM needs to generate mission plans based on real scenarios rather than imagined ones. For example, existing MLLMs may formulaically answer "Open the microwave" by saying "Step 1: Find the handle," but many microwave ovens do not have handles. Next, we combine the 800K RoboVQA dataset to learn high-level robotic skills such as long-range mission planning, maneuverability judgment, maneuverability generation, future and past prediction, etc. During co-training, as shown in Figure 3, we freeze the parameters of the CLIP encoder and fine-tune the projection layer and Mamba on the 1.8m merged dataset. All outputs from the Mamba language model are supervised using a cross-entropy loss. 4. RoboMamba Manipulation Ability Fine-tuning Training Based on RoboMamba’s powerful reasoning capabilities, we introduce our robot operation fine-tuning strategy in this section, which is called training Stage 2 in Figure 3 . Existing MLLM-based robot operation methods require updating the projection layer and the entire LLM during the operation fine-tuning stage. Although this paradigm can give the model action pose prediction capabilities, it also destroys the inherent capabilities of MLLM and requires a large amount of training resources. To address these challenges, we propose an efficient fine-tuning strategy, as shown in Figure 3. We freeze all parameters of RoboMamba and introduce a simple Policy head to model Mamba’s output token. The policy head contains two MLPs that learn the end effector position and direction respectively, occupying a total of 0.1% of the entire model parameters. According to the previous work where2act, the loss formula of position and direction is as follows: 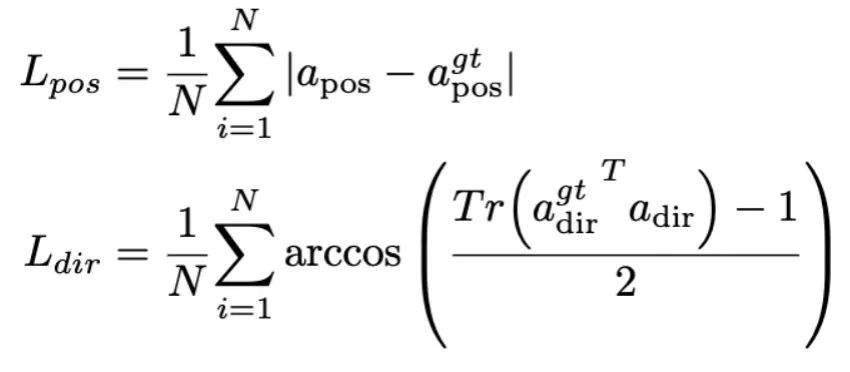 where, N represents the number of training samples, and Tr (A) represents the trace of matrix A. RoboMamba only predicts the 2D position (x, y) of the contact pixel in the image and then uses depth information to convert it into 3D space. To evaluate this fine-tuning strategy, we generated a dataset of 10,000 end-effector pose predictions using SAPIEN simulations. After operational fine-tuning, we found that once RoboMamba has sufficient reasoning capabilities, it can acquire pose prediction skills through extremely efficient fine-tuning. Due to the minimal number of fine-tuning parameters (7MB) and efficient model design, we can achieve new operational skill learning in just 20 minutes. This finding highlights the importance of reasoning ability in learning operational skills and proposes a new perspective: we can efficiently empower MLLMs with operational capabilities without affecting their inherent reasoning capabilities. Finally, RoboMamba can use language responses for common sense and robot-related reasoning, and a policy head for action pose prediction. 1. General Reasoning Ability Assessment (MLLM Benchmarks) To evaluate reasoning ability, we used several popular benchmarks, including VQAv2, OKVQA, GQA, OCRVQA, VizWiz, POPE, MME, MMBench and MM-Vet.In addition, we also directly evaluated RoboMamba's robot-related reasoning capabilities on RoboVQA's 18k verification data set, covering robot tasks such as task planning, prompted task planning, long-range task planning, maneuverability judgment, and maneuverability. Sexual generation, past description and future prediction, etc. Om Table 1. Comparison of Robomamba and the existing MLLMS on multiple benchmarks.
where, N represents the number of training samples, and Tr (A) represents the trace of matrix A. RoboMamba only predicts the 2D position (x, y) of the contact pixel in the image and then uses depth information to convert it into 3D space. To evaluate this fine-tuning strategy, we generated a dataset of 10,000 end-effector pose predictions using SAPIEN simulations. After operational fine-tuning, we found that once RoboMamba has sufficient reasoning capabilities, it can acquire pose prediction skills through extremely efficient fine-tuning. Due to the minimal number of fine-tuning parameters (7MB) and efficient model design, we can achieve new operational skill learning in just 20 minutes. This finding highlights the importance of reasoning ability in learning operational skills and proposes a new perspective: we can efficiently empower MLLMs with operational capabilities without affecting their inherent reasoning capabilities. Finally, RoboMamba can use language responses for common sense and robot-related reasoning, and a policy head for action pose prediction. 1. General Reasoning Ability Assessment (MLLM Benchmarks) To evaluate reasoning ability, we used several popular benchmarks, including VQAv2, OKVQA, GQA, OCRVQA, VizWiz, POPE, MME, MMBench and MM-Vet.In addition, we also directly evaluated RoboMamba's robot-related reasoning capabilities on RoboVQA's 18k verification data set, covering robot tasks such as task planning, prompted task planning, long-range task planning, maneuverability judgment, and maneuverability. Sexual generation, past description and future prediction, etc. Om Table 1. Comparison of Robomamba and the existing MLLMS on multiple benchmarks. 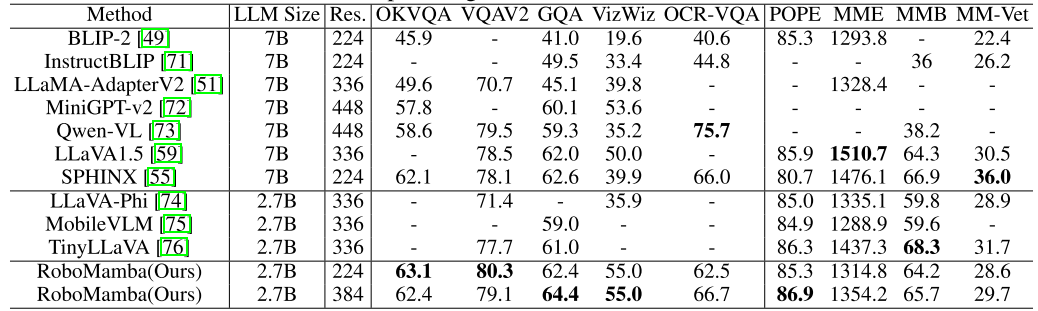 As shown in Table 1, we compare RoboMamba with previous state-of-the-art (SOTA) MLLM on common VQA and recent MLLM benchmarks. First, we find that RoboMamba achieves satisfactory results on all VQA benchmarks using only 2.7B language models. The results show that the simple structural design is effective. Aligned pre-training and instruction co-training significantly improve the inference capabilities of MLLM. For example, RoboMamba's spatial recognition performance on the GQA benchmark is improved due to the introduction of large amounts of robot data in the collaborative training phase. Meanwhile, we also tested our RoboMamba on the recently proposed MLLM benchmark. Compared with previous MLLMs, we observe that our model achieves competitive results on all benchmarks. Although some performance of RoboMamba is still lower than the state-of-the-art 7B MLLM (e.g., LLaVA1.5 and SPHINX), we prioritize the smaller and faster Mamba-2.7B to balance the efficiency of the robot model. In the future, we plan to develop RoboMamba-7B for resource-unconstrained scenarios.
As shown in Table 1, we compare RoboMamba with previous state-of-the-art (SOTA) MLLM on common VQA and recent MLLM benchmarks. First, we find that RoboMamba achieves satisfactory results on all VQA benchmarks using only 2.7B language models. The results show that the simple structural design is effective. Aligned pre-training and instruction co-training significantly improve the inference capabilities of MLLM. For example, RoboMamba's spatial recognition performance on the GQA benchmark is improved due to the introduction of large amounts of robot data in the collaborative training phase. Meanwhile, we also tested our RoboMamba on the recently proposed MLLM benchmark. Compared with previous MLLMs, we observe that our model achieves competitive results on all benchmarks. Although some performance of RoboMamba is still lower than the state-of-the-art 7B MLLM (e.g., LLaVA1.5 and SPHINX), we prioritize the smaller and faster Mamba-2.7B to balance the efficiency of the robot model. In the future, we plan to develop RoboMamba-7B for resource-unconstrained scenarios. 2. Robot reasoning ability evaluation (RoboVQA Benchmark)
In addition, in order to comprehensively compare RoboMamba’s robot-related reasoning capabilities, we benchmarked it with LLaMA-AdapterV2 on the RoboVQA validation set. We choose LLaMA-AdapterV2 as the baseline because it is the base model for current SOTA robotic MLLM (ManipLLM). For a fair comparison, we loaded the LLaMA-AdapterV2 pre-trained parameters and fine-tuned them on the RoboVQA training set for two epochs using its official instruction fine-tuning method. As shown in Figure 4 a), RoboMamba achieves superior performance between BLEU-1 to BLEU-4. The results demonstrate that our model has advanced robot-related reasoning capabilities and confirm the effectiveness of our training strategy. In addition to higher accuracy, our model achieves inference speeds up to 7 times faster than LLaMA-AdapterV2 and ManipLLM, which can be attributed to the content-aware inference capabilities and efficiency of the Mamba language model. Figure 4. Comparison of robot-related reasoning on RoboVQA.  3. Robot Manipulation Ability Evaluation (SAPIEN)
3. Robot Manipulation Ability Evaluation (SAPIEN)
To evaluate the manipulation ability of RoboMamba, we compared our model with four baselines: UMPNet, Flowbot3D, RoboFlamingo and ManipLLM . Before comparison, we reproduce all baselines and train them on the dataset we collected. For UMPNet, we perform operations on predicted contact points, oriented perpendicular to the object surface. Flowbot3D predicts the direction of motion on the point cloud, selects the largest flow as the interaction point, and uses the flow direction to represent the direction of the end effector. RoboFlamingo and ManipLLM load OpenFlamingo and LLaMA-AdapterV2 pre-training parameters respectively, and follow their respective fine-tuning and model update strategies. As shown in Table 2, compared to the previous SOTA ManipLLM, our RoboMamba achieves 7.0% improvement on the visible category and 2.0% improvement on the invisible category. In terms of efficiency, RoboFlamingo updates 35.5% (1.8B) of model parameters, ManipLLM updates adapters in LLM (41.3M) containing 0.5% of model parameters, while our fine-tuned Policy head (3.7M) only accounts for model parameters 0.1%. RoboMamba updates 10x fewer parameters than previous MLLM-based methods while inferring 7x faster. The results show that our RoboMamba not only has strong reasoning capabilities, but also can obtain manipulation capabilities in a low-cost way. Table 2. Comparison of success rates between Robomamba and other baselines 
As shown in Figure 4, we visualize the inference results of RoboMamba in various robotic downstream tasks. In terms of task planning, compared to LLaMA-AdapterV2, RoboMamba has demonstrated more accurate and longer-term planning capabilities due to its powerful reasoning capabilities. For a fair comparison, we also fine-tune the baseline LLaMA-AdapterV2 on the RoboVQA dataset. For manipulation pose prediction, we used a Franka Emika robotic arm to interact with various household objects. We project the 3D pose predicted by RoboMamba onto a 2D image, using red points to represent contact points and end effectors to represent directions, as shown in the lower right corner of the figure. 


The above is the detailed content of Peking University launches new multi-modal robot model! Efficient reasoning and operations for general and robotic scenarios. For more information, please follow other related articles on the PHP Chinese website!




 . For example, when faced with a planning problem such as "How to clear the table?" responses typically include steps such as "Step 1: Pick up the object" and "Step 2: Put the object into the box." For action prediction, we utilize an efficient and simple policy head π to predict actions
. For example, when faced with a planning problem such as "How to clear the table?" responses typically include steps such as "Step 1: Pick up the object" and "Step 2: Put the object into the box." For action prediction, we utilize an efficient and simple policy head π to predict actions 















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



