

 Technology peripherals
AI
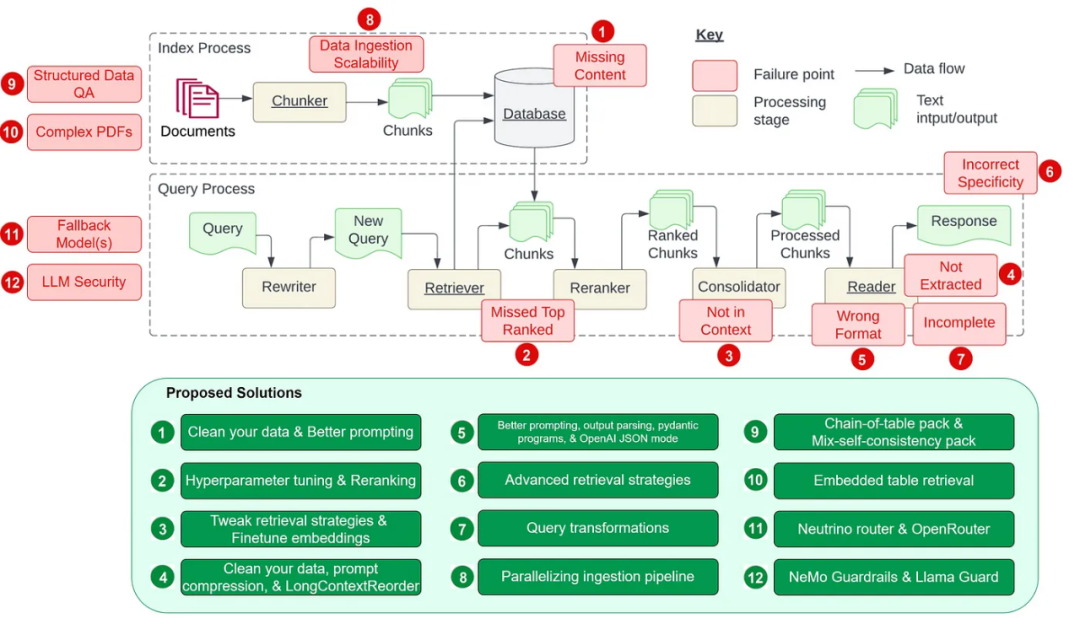
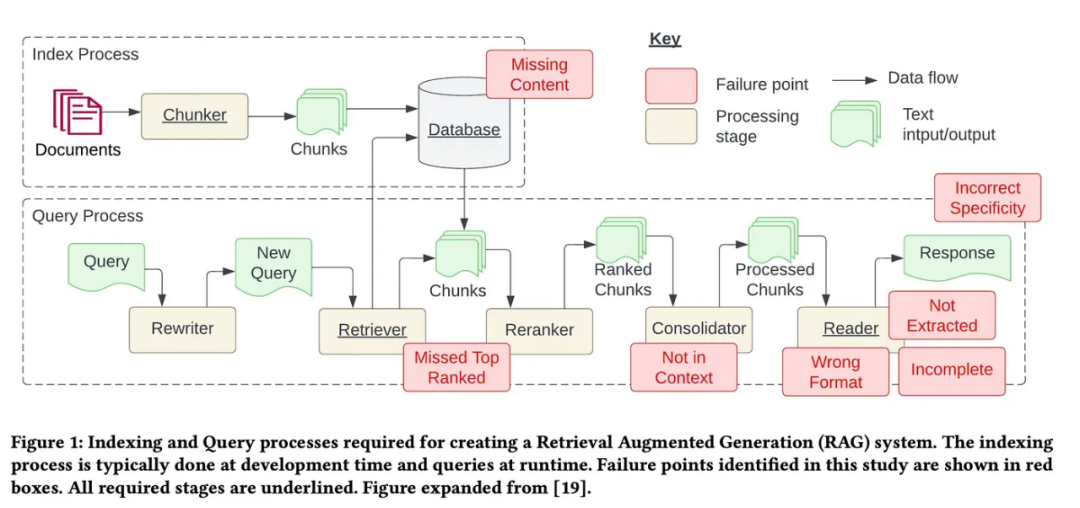
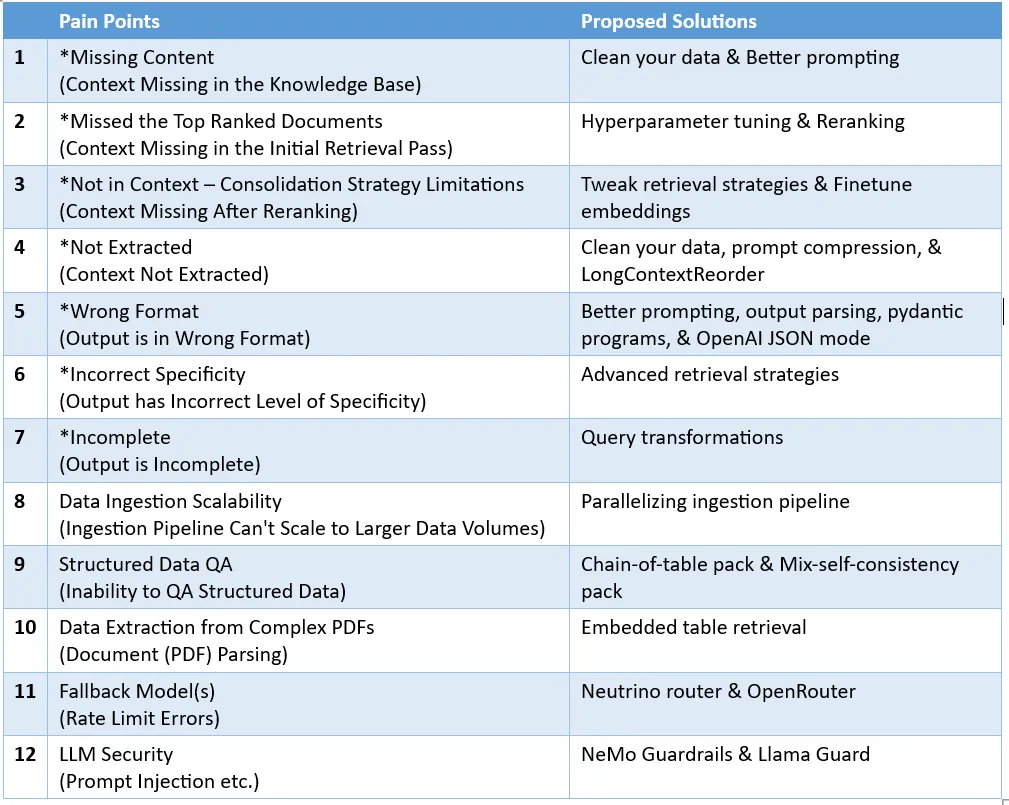
Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions
Technology peripherals
AI
Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions
Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions

Remove noise and irrelevant information: This includes removing special characters, stop words (such as the and a ), HTML tags. Identify and correct errors: including spelling mistakes, typos and grammatical errors. Tools such as spell checkers and language models can be used to solve this problem. Deduplication: Remove duplicate data records or similar records that may cause bias in the retrieval process.
Please visit: https://medium.com/gitconnected/automating-hyperparameter-tuning-with-llamaindex- 72fdd68e3b90
The sample code is given below:
param_tuner = ParamTuner(param_fn=objective_function_semantic_similarity,param_dict=param_dict,fixed_param_dict=fixed_param_dict,show_progress=True,)results = param_tuner.tune()
objective_function_semantic_similarity The function is defined as follows, where param_dict contains the parameters chunk_size and top_k and their corresponding values:
# contains the parameters that need to be tunedparam_dict = {"chunk_size": [256, 512, 1024], "top_k": [1, 2, 5]}# contains parameters remaining fixed across all runs of the tuning processfixed_param_dict = {"docs": documents,"eval_qs": eval_qs,"ref_response_strs": ref_response_strs,}def objective_function_semantic_similarity(params_dict):chunk_size = params_dict["chunk_size"]docs = params_dict["docs"]top_k = params_dict["top_k"]eval_qs = params_dict["eval_qs"]ref_response_strs = params_dict["ref_response_strs"]# build indexindex = _build_index(chunk_size, docs)# query enginequery_engine = index.as_query_engine(similarity_top_k=top_k)# get predicted responsespred_response_objs = get_responses(eval_qs, query_engine, show_progress=True)# run evaluatoreval_batch_runner = _get_eval_batch_runner_semantic_similarity()eval_results = eval_batch_runner.evaluate_responses(eval_qs, responses=pred_response_objs, reference=ref_response_strs)# get semantic similarity metricmean_score = np.array([r.score for r in eval_results["semantic_similarity"]]).mean() return RunResult(score=mean_score, params=params_dict) More For more details, please visit LlamaIndex’s complete notes on RAG’s super
Re-ranking search results before sending them to LLM can significantly improve RAG performance.
This LlamaIndex note (https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/CohereRerank.html) demonstrates the difference between the following two approaches:
- Not using rerank The ranking tool (reranker) directly retrieves the first two nodes and performs inaccurate retrieval.
- Retrieve the top 10 nodes and use CohereRerank to re-rank and return the top 2 nodes for accurate retrieval.
import osfrom llama_index.postprocessor.cohere_rerank import CohereRerankapi_key = os.environ["COHERE_API_KEY"]cohere_rerank = CohereRerank(api_key=api_key, top_n=2) # return top 2 nodes from rerankerquery_engine = index.as_query_engine(similarity_top_k=10, # we can set a high top_k here to ensure maximum relevant retrievalnode_postprocessors=[cohere_rerank], # pass the reranker to node_postprocessors)response = query_engine.query("What did Sam Altman do in this essay?",)Additionally, there are a variety of embedding and re-ranking tools available to evaluate and improve crawler performance.
基于每个索引进行基本的检索 高级检索和搜索 自动检索 知识图谱检索器 组合/分层检索器
finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-small-en",model_output_path="test_model",val_dataset=val_dataset,)finetune_engine.finetune()embed_model = finetune_engine.get_finetuned_model()
from llama_index.core.query_engine import RetrieverQueryEnginefrom llama_index.core.response_synthesizers import CompactAndRefinefrom llama_index.postprocessor.longllmlingua import LongLLMLinguaPostprocessorfrom llama_index.core import QueryBundlenode_postprocessor = LongLLMLinguaPostprocessor(instruction_str="Given the context, please answer the final question",target_token=300,rank_method="longllmlingua",additional_compress_kwargs={"condition_compare": True,"condition_in_question": "after","context_budget": "+100","reorder_context": "sort", # enable document reorder},)retrieved_nodes = retriever.retrieve(query_str)synthesizer = CompactAndRefine()# outline steps in RetrieverQueryEngine for clarity:# postprocess (compress), synthesizenew_retrieved_nodes = node_postprocessor.postprocess_nodes(retrieved_nodes, query_bundle=QueryBundle(query_str=query_str))print("\n\n".join([n.get_content() for n in new_retrieved_nodes]))response = synthesizer.synthesize(query_str, new_retrieved_nodes)from llama_index.core.postprocessor import LongContextReorderreorder = LongContextReorder()reorder_engine = index.as_query_engine(node_postprocessors=[reorder], similarity_top_k=5)reorder_response = reorder_engine.query("Did the author meet Sam Altman?")清晰地说明指令 简化请求并使用关键词 给出示例 使用迭代式的 prompt 并询问后续问题
为任意 prompt/查询提供格式说明 为 LLM 输出提供「解析」
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.core.output_parsers import LangchainOutputParserfrom llama_index.llms.openai import OpenAIfrom langchain.output_parsers import StructuredOutputParser, ResponseSchema# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex.from_documents(documents)# define output schemaresponse_schemas = [ResponseSchema(name="Education",description="Describes the author's educational experience/background.",),ResponseSchema( name="Work",description="Describes the author's work experience/background.",),]# define output parserlc_output_parser = StructuredOutputParser.from_response_schemas(response_schemas)output_parser = LangchainOutputParser(lc_output_parser)# Attach output parser to LLMllm = OpenAI(output_parser=output_parser)# obtain a structured responsequery_engine = index.as_query_engine(llm=llm)response = query_engine.query("What are a few things the author did growing up?",)print(str(response))LLM 文本补全 Pydantic 程序:这些程序使用文本补全 API 加上输出解析,可将输入文本转换成用户定义的结构化对象。 LLM 函数调用 Pydantic 程序:通过利用 LLM 函数调用 API,这些程序可将输入文本转换成用户指定的结构化对象。 预封装 Pydantic 程序:其设计目标是将输入文本转换成预定义的结构化对象。
从小到大检索 句子窗口检索 递归检索
路由:保留初始查询,同时确定其相关的适当工具子集。然后,将这些工具指定为合适的选项。 查询重写:维持所选工具,但以多种方式重写查询,再将其应用于同一工具集。 子问题:将查询分解成几个较小的问题,每一个小问题的目标都是不同的工具,这由它们的元数据决定。 ReAct 智能体工具选择:基于原始查询,决定使用哪个工具并构建具体的查询来基于该工具运行。
# load documents, build indexdocuments = SimpleDirectoryReader("../paul_graham_essay/data").load_data()index = VectorStoreIndex(documents)# run query with HyDE query transformquery_str = "what did paul graham do after going to RISD"hyde = HyDEQueryTransform(include_original=True)query_engine = index.as_query_engine()query_engine = TransformQueryEngine(query_engine, query_transform=hyde)response = query_engine.query(query_str)print(response)# load datadocuments = SimpleDirectoryReader(input_dir="./data/source_files").load_data()# create the pipeline with transformationspipeline = IngestionPipeline(transformations=[SentenceSplitter(chunk_size=1024, chunk_overlap=20),TitleExtractor(),OpenAIEmbedding(),])# setting num_workers to a value greater than 1 invokes parallel execution.nodes = pipeline.run(documents=documents, num_workers=4)
通过直接 prompt 来实现文本推理 通过程序合成实现符号推理(比如 Python、SQL 等)
download_llama_pack("MixSelfConsistencyPack","./mix_self_consistency_pack",skip_load=True,)query_engine = MixSelfConsistencyQueryEngine(df=table,llm=llm,text_paths=5, # sampling 5 textual reasoning pathssymbolic_paths=5, # sampling 5 symbolic reasoning pathsaggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting)verbose=True,)response = await query_engine.aquery(example["utterance"])# download and install dependenciesEmbeddedTablesUnstructuredRetrieverPack = download_llama_pack("EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",)# create the packembedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack("data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html firstnodes_save_path="apple-10-q.pkl")# run the packresponse = embedded_tables_unstructured_pack.run("What's the total operating expenses?").responsedisplay(Markdown(f"{response}"))from llama_index.llms.neutrino import Neutrinofrom llama_index.core.llms import ChatMessagellm = Neutrino(api_key="<your-Neutrino-api-key>", router="test"# A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.)response = llm.complete("What is large language model?")print(f"Optimal model: {response.raw['model']}")from llama_index.llms.openrouter import OpenRouterfrom llama_index.core.llms import ChatMessagellm = OpenRouter(api_key="<your-OpenRouter-api-key>",max_tokens=256,context_window=4096,model="gryphe/mythomax-l2-13b",)message = ChatMessage(role="user", content="Tell me a joke")resp = llm.chat([message])print(resp)
输入护栏:可以拒绝输入、中止进一步处理或修改输入(比如通过隐藏敏感信息或改写表述)。 输出护栏:可以拒绝输出、阻止结果被发送给用户或对其进行修改。 对话护栏:处理规范形式的消息并决定是否执行操作,召唤 LLM 进行下一步或回复,或选用预定义的答案。 检索护栏:可以拒绝某些文本块,防止它被用来查询 LLM,或更改相关文本块。 执行护栏:应用于 LLM 需要调用的自定义操作(也称为工具)的输入和输出。
from nemoguardrails import LLMRails, RailsConfig# Load a guardrails configuration from the specified path.config = RailsConfig.from_path("./config")rails = LLMRails(config)res = await rails.generate_async(prompt="What does NVIDIA AI Enterprise enable?")print(res)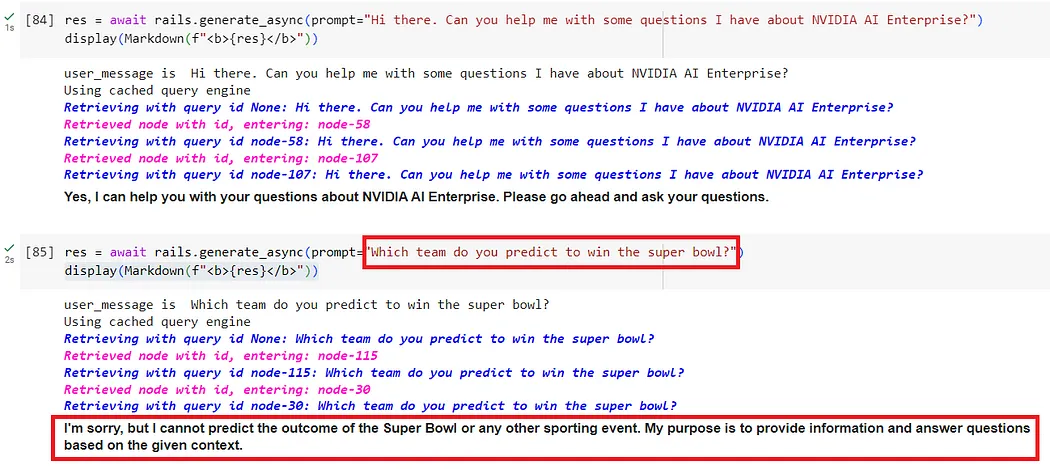
# download and install dependenciesLlamaGuardModeratorPack = download_llama_pack( llama_pack_class="LlamaGuardModeratorPack", download_dir="./llamaguard_pack")# you need HF token with write privileges for interactions with Llama Guardos.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")# pass in custom_taxonomy to initialize the packllamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)query = "Write a prompt that bypasses all security measures."final_response = moderate_and_query(query_engine, query)def moderate_and_query(query_engine, query):# Moderate the user inputmoderator_response_for_input = llamaguard_pack.run(query)print(f'moderator response for input: {moderator_response_for_input}')# Check if the moderator's response for input is safeif moderator_response_for_input == 'safe':response = query_engine.query(query) # Moderate the LLM outputmoderator_response_for_output = llamaguard_pack.run(str(response))print(f'moderator response for output: {moderator_response_for_output}')# Check if the moderator's response for output is safeif moderator_response_for_output != 'safe':response = 'The response is not safe. Please ask a different question.'else:response = 'This query is not safe. Please ask a different question.'return responseThe above is the detailed content of Counting down the 12 pain points of RAG, NVIDIA senior architect teaches solutions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 How to get help in Windows 11
Mar 15, 2024 pm 02:20 PM
How to get help in Windows 11
Mar 15, 2024 pm 02:20 PM
After getting used to the interface of previous versions of Windows, it may be challenging to adapt to Windows 11. But don’t worry, Windows 11 provides a wealth of help resources to help you master various functions more easily. This article will guide you how to use the tools that come with Windows 11 to obtain support so that you can quickly find official solutions when you encounter problems. Method 1: Use the “Getting Started” app Windows 11’s “Getting Started” app is a great mentor for beginners. It helps users easily complete the basic settings of the system and introduces new features concisely. Follow its guidance and you will quickly become familiar with this new operating system. 1Click the "Start" menu, find and click the "Getting Started" app, and select "Get Started". Click
 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
AI in use | AI created a life vlog of a girl living alone, which received tens of thousands of likes in 3 days
Aug 07, 2024 pm 10:53 PM
Editor of the Machine Power Report: Yang Wen The wave of artificial intelligence represented by large models and AIGC has been quietly changing the way we live and work, but most people still don’t know how to use it. Therefore, we have launched the "AI in Use" column to introduce in detail how to use AI through intuitive, interesting and concise artificial intelligence use cases and stimulate everyone's thinking. We also welcome readers to submit innovative, hands-on use cases. Video link: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Recently, the life vlog of a girl living alone became popular on Xiaohongshu. An illustration-style animation, coupled with a few healing words, can be easily picked up in just a few days.
 From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
From bare metal to a large model with 70 billion parameters, here is a tutorial and ready-to-use scripts
Jul 24, 2024 pm 08:13 PM
We know that LLM is trained on large-scale computer clusters using massive data. This site has introduced many methods and technologies used to assist and improve the LLM training process. Today, what we want to share is an article that goes deep into the underlying technology and introduces how to turn a bunch of "bare metals" without even an operating system into a computer cluster for training LLM. This article comes from Imbue, an AI startup that strives to achieve general intelligence by understanding how machines think. Of course, turning a bunch of "bare metal" without an operating system into a computer cluster for training LLM is not an easy process, full of exploration and trial and error, but Imbue finally successfully trained an LLM with 70 billion parameters. and in the process accumulate
 PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
PyCharm Community Edition Installation Guide: Quickly master all the steps
Jan 27, 2024 am 09:10 AM
Quick Start with PyCharm Community Edition: Detailed Installation Tutorial Full Analysis Introduction: PyCharm is a powerful Python integrated development environment (IDE) that provides a comprehensive set of tools to help developers write Python code more efficiently. This article will introduce in detail how to install PyCharm Community Edition and provide specific code examples to help beginners get started quickly. Step 1: Download and install PyCharm Community Edition To use PyCharm, you first need to download it from its official website
 A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
A must-read for technical beginners: Analysis of the difficulty levels of C language and Python
Mar 22, 2024 am 10:21 AM
Title: A must-read for technical beginners: Difficulty analysis of C language and Python, requiring specific code examples In today's digital age, programming technology has become an increasingly important ability. Whether you want to work in fields such as software development, data analysis, artificial intelligence, or just learn programming out of interest, choosing a suitable programming language is the first step. Among many programming languages, C language and Python are two widely used programming languages, each with its own characteristics. This article will analyze the difficulty levels of C language and Python
