The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
The current mainstream visual language model (VLM) is mainly based on the large language model (LLM) for further fine-tuning. Therefore, it is necessary to map the image to the embedding space of LLM in various ways, and then use autoregressive methods to predict the answer based on the image token. In this process, modal alignment is implicitly implemented through text tokens. How to align this step well is very critical. In response to this problem, researchers from Wuhan University, ByteDance Beanbao Large Model Team and the University of Chinese Academy of Sciences proposed a text token screening method (CAL) based on contrastive learning to screen out text Tokens that are highly related to the image are increased in weight of the loss function to achieve more accurate multi-modal alignment.
- Paper link: https://arxiv.org/pdf/2405.17871
- Code link: https://github.com/foundation-multimodal-models/CAL
CAL has the following highlights:
- can be directly nested into the training process without additional pre-training stage.
- has achieved significant improvements in OCR and Caption benchmarks. From the visualization, it can be found that CAL makes the image modal alignment better.
- CAL makes the training process more resistant to noisy data.
Currently, visual language models rely on the alignment of image modalities, and how to do alignment is very critical. The current mainstream method is to perform implicit alignment through text autoregression, but the contribution of each text token to image alignment is inconsistent. It is very necessary to distinguish these text tokens.
CAL proposed that in the existing visual language model (VLM) training data, text tokens can be divided into three categories:
- Text that is highly related to pictures: such as entities ( Such as people, animals, objects), quantity, color, text, etc. These tokens directly correspond to image information and are crucial for multi-modal alignment.
- Text with low correlation to the picture: Such as following words or content that can be inferred from the previous text. These tokens are actually mainly used to train the plain text capabilities of VLM.
- Text that contradicts the image content: These tokens are inconsistent with image information and may even provide misleading information, negatively affecting the multi-modal alignment process.
 标 Figure 1: The green mark is related to the high -related Token, the red is the contrary to the content, and the colorless is the neutral Token
标 Figure 1: The green mark is related to the high -related Token, the red is the contrary to the content, and the colorless is the neutral Token
During the training process, the latter two types of token are actually actually occupy a larger proportion, but because they are not strongly dependent on the image, they have little effect on the modal alignment of the image. Therefore, in order to achieve better alignment, it is necessary to increase the weight of the first type of text tokens, that is, the tokens that are highly related to the image. How to find this part of the token has become the key to solving this problem. Method
Finding tokens that are highly related to the image This problem can be solved by condition contrastive.
For each image-text pair in the training data, without image input, the logit on each text token represents LLM’s estimate of the occurrence of this situation based on context and existing knowledge. value.
- If you add image input in front, it is equivalent to providing additional contextual information. In this case, the logit of each text token will be adjusted based on the new situation. The logit changes in these two cases represent the impact of the new condition of the picture on each text token.
Specifically, during the training process, CAL inputs the image and text sequences and individual text sequences into the large language model (LLM) respectively to obtain the logit of each text token. By calculating the logit difference between these two cases, we can measure the impact of the image on each token. The larger the logit difference, the greater the impact of the image on the token, so the token is more relevant to the image. The figure below shows the flow chart of the logit diff and CAL methods for text tokens.对 Figure 2: The left picture is the visualization of the token logit diff in the two situations. The picture on the right is the visualization of the CAL method process
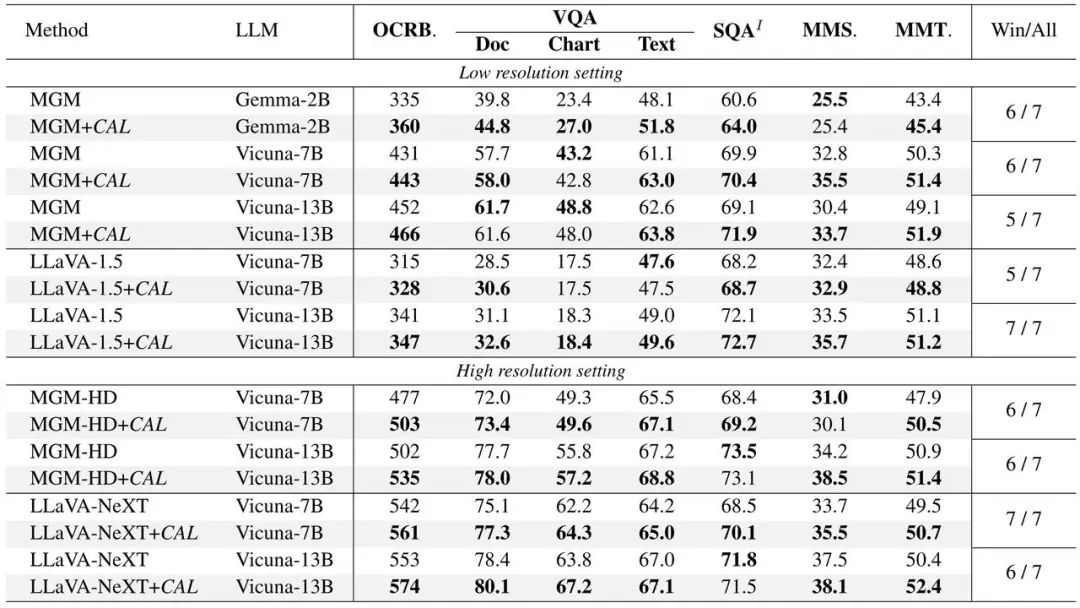
 Cal in Llava Experimental verification was conducted on two mainstream models: MGM and MGM, and performance improvements were achieved in models of different sizes. Contains the following four parts of verification:
Cal in Llava Experimental verification was conducted on two mainstream models: MGM and MGM, and performance improvements were achieved in models of different sizes. Contains the following four parts of verification: (1) Models using CAL perform better on various benchmark indicators.
(2) Create a batch of noise data (image-text mismatch) by randomly exchanging the text in the two image-text pairs in proportion and use it for model training. CAL makes the training process Has stronger data anti-noise performance.度 Figure 3: In the case of noise training at different intensity, the performance of CAL and the baseline
(3) calculates the attention scores of the picture token in the answer part of QA Case, And plotting it on the original image, the CAL-trained model has a clearer attention distribution map.
C Figure 4: The baseline and CAL's Attention Map can be visualized. The right side of each pair is CAL
(4) to the text token to the text token in its most similar LLM vocabulary. Drawing it onto the original image, the CAL-trained model mapping content is closer to the image content. A Figure 5: Imam into the Image Token as the most similar vocabulary, and correspond to the original picture. The model team was established in 2023 and is committed to developing the industry's most advanced AI large model technology, becoming a world-class research team, and contributing to technological and social development.
 The Doubao Big Model team has long-term vision and determination in the field of AI. Its research directions cover NLP, CV, speech, etc., and it has laboratories and research positions in China, Singapore, the United States and other places. Relying on the platform's sufficient data, computing and other resources, the team continues to invest in related fields. It has launched a self-developed general large model to provide multi-modal capabilities. The downstream supports 50+ businesses such as Doubao, Buttons, and Jimeng, and is open to the volcano engine. Corporate customers. At present, Doubao APP has become the AIGC application with the largest number of users in the Chinese market. Welcome to join the ByteDance Beanbao model team.
The Doubao Big Model team has long-term vision and determination in the field of AI. Its research directions cover NLP, CV, speech, etc., and it has laboratories and research positions in China, Singapore, the United States and other places. Relying on the platform's sufficient data, computing and other resources, the team continues to invest in related fields. It has launched a self-developed general large model to provide multi-modal capabilities. The downstream supports 50+ businesses such as Doubao, Buttons, and Jimeng, and is open to the volcano engine. Corporate customers. At present, Doubao APP has become the AIGC application with the largest number of users in the Chinese market. Welcome to join the ByteDance Beanbao model team. The above is the detailed content of Bytedance Doubao and Wuhan University proposed CAL: enhancing multi-modal alignment effects through visually related tokens. For more information, please follow other related articles on the PHP Chinese website!





 What does it mean when a message has been sent but rejected by the other party?
What does it mean when a message has been sent but rejected by the other party?
 Usage of fopen function in Matlab
Usage of fopen function in Matlab
 The difference between get request and post request
The difference between get request and post request
 css font color
css font color
 What's going on when the ip address is unavailable?
What's going on when the ip address is unavailable?
 psrpc.dll not found solution
psrpc.dll not found solution
 How to insert audio into ppt
How to insert audio into ppt
 Recommended computer hardware testing software rankings
Recommended computer hardware testing software rankings





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



