


Since Ilya Sutskever officially announced his resignation from OpenAI, his next move has become the focus of everyone's attention.
Some people even pay close attention to his every move.
No, Ilya just liked ❤️ a new paper——

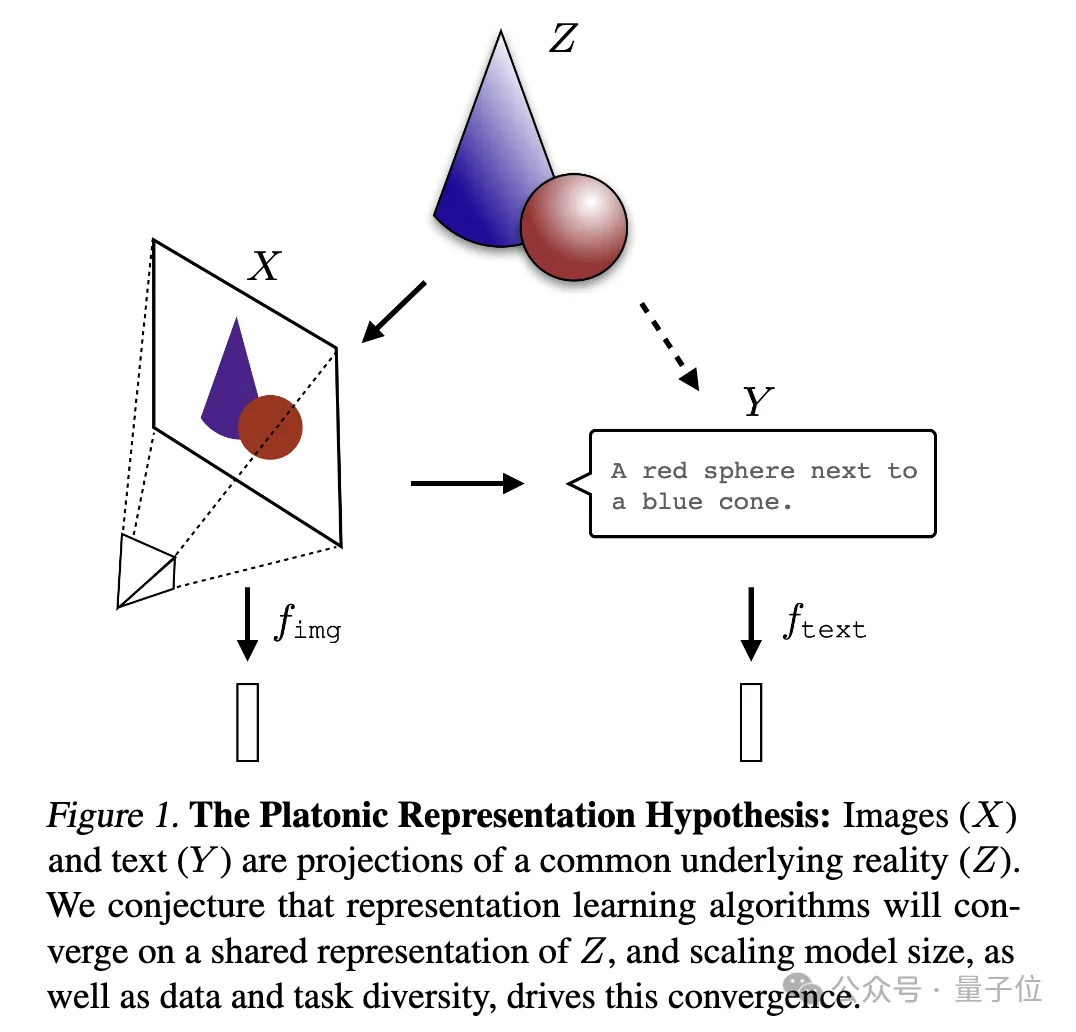
Neural networks are trained on different data and modalities with different goals, andare tending to form a shared real-world statistical model in their representation space .

Platonic Representation Hypothesis, in reference to Plato's Allegory of the Cave and his ideas about the nature of ideal reality .




representation convergence of the AI system (Representational Convergence) , that is, the representation methods of data points in different neural network models are becoming more and more similar. This similarity spans different model architectures, training objectives and even data modalities.
What drives this convergence? Will this trend continue? Where is its final destination? After a series of analyzes and experiments, the researchers speculated that this convergence does have an endpoint and a driving principle:Different models strive to achieve an accurate representation of reality.
A picture to explain: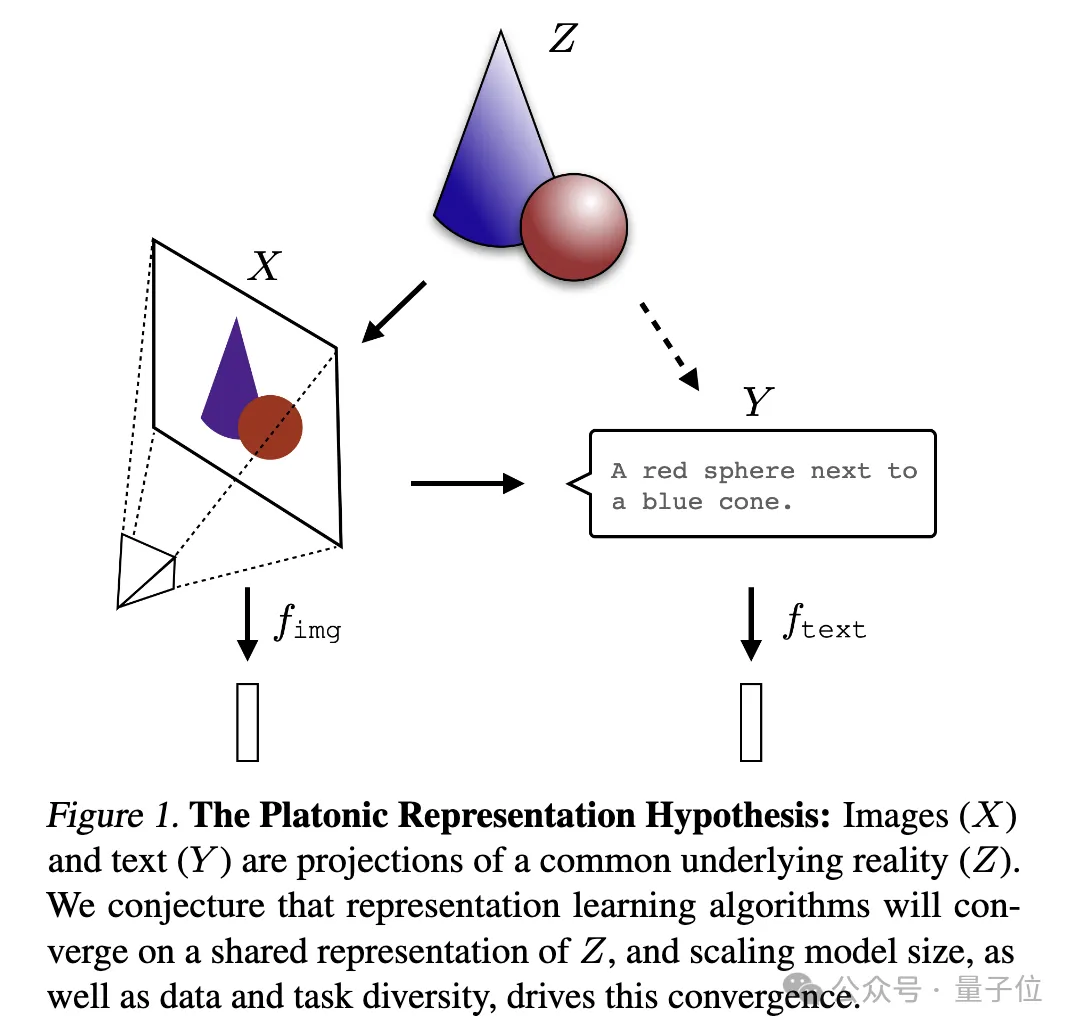
(X) and text (Y) are Different projections of a common underlying reality (Z). The researchers speculate that representation learning algorithms will converge to a unified representation of Z, and that the increase in model size and the diversity of data and tasks are key factors driving this convergence.
I can only say that it is indeed a question that Ilya is interested in. It is too profound and we don’t understand it. Let’s ask AI to help explain it and share it with everyone~
Ps: This research focuses on vector embedding representation, that is, data is converted into vector form, and the similarity or distance between data points is described by the kernel function. The concept of "representation alignment" in this article means that if two different representation methods reveal similar data structures, then the two representations are considered to be aligned.
1. Convergence of different models. Models with different architectures and goals tend to be consistent in their underlying representation.
At present, the number of systems built based on pre-trained basic models is gradually increasing, and some models are becoming the standard core architecture for multi-tasking. This wide applicability in a variety of applications reflects their certain versatility in data representation methods.
While this trend suggests that AI systems are converging toward a smaller set of base models, it does not prove that different base models will form the same representation.
However, some recent research related to model stitching found that the middle layer representations of image classification models can be well aligned even when trained on different datasets.
For example, some studies have found that the early layers of convolutional networks trained on the ImageNet and Places365 datasets can be interchanged, indicating that they learned similar initial visual representations. Other studies have discovered a large number of "Rosetta Neurons", that is, neurons with highly similar activation patterns in different visual models...
2. The larger the model size and performance, the higher the degree of representation alignment.The researchers measured the alignment of 78 models using the mutual nearest neighbor method on the Places-365 dataset
and evaluated their performance downstream of the vision task adaptation benchmark VTAB task performance.
It was found that the representation alignment between model clusters with stronger generalization ability was significantly higher. 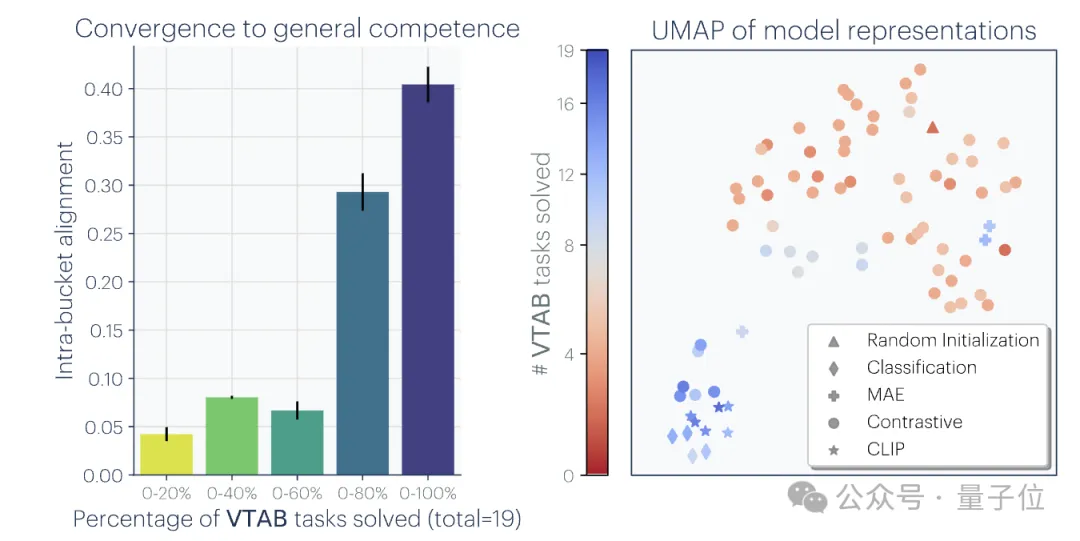
3. Model representation convergence in different modes.
The researchers used the mutual nearest neighbor method to measure alignment on the Wikipedia image dataset WIT.
The results reveal a linear relationship between language-visual alignment and language modeling scores, with the general trend being that more capable language models align better with more capable visual models. 4. The model and brain representation also show a certain degree of consistency, possibly due to facing similar data and task constraints.
4. The model and brain representation also show a certain degree of consistency, possibly due to facing similar data and task constraints.
In 2014, a study found that the activation of the middle layer of the neural network is highly correlated with the activation pattern of the visual area of the brain, possibly due to facing similar visual tasks and data constraints.
Since then, studies have further found that using different training data will affect the alignment of the brain and model representations. Psychological research has also found that the way humans perceive visual similarity is highly consistent with neural network models.5. The degree of alignment of model representations is positively correlated with the performance of downstream tasks.
The researchers used two downstream tasks to evaluate the model's performance: Hellaswag (common sense reasoning)
and GSM8K(mathematics) . And use the DINOv2 model as a reference to measure the alignment of other language models with the visual model. Experimental results show that language models that are more aligned with the visual model also perform better on Hellaswag and GSM8K tasks. The visualization results show that there is a clear positive correlation between the degree of alignment and downstream task performance.
#I will not go into detail about the previous research here. Interested family members can check out the original paper. 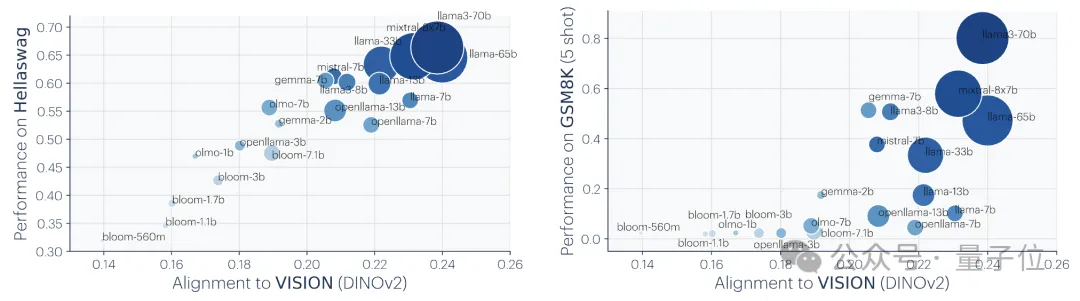
 1. Convergence via Task Generality
1. Convergence via Task Generality
(Convergence via Task Generality)As the model is To train to solve more tasks, they need to find representations that can meet the requirements of all tasks:
The number of representations that can handle N tasks is less than the number of representations that can handle M (M
A similar principle has been proposed before. The illustration is as follows:

Moreover, the easy tasks are Multiple solutions, while difficult tasks have fewer solutions. Therefore, as task difficulty increases, the model's representation tends to converge to better, fewer solutions.
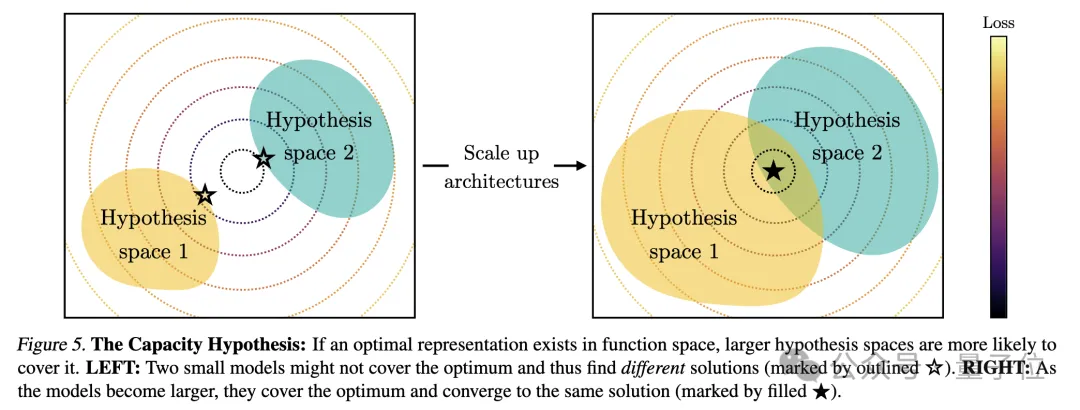
2. Model capacity leads to convergence(Convergence via Model Capacity)
The researchers pointed out the capacity assumption. If there is a global optimal representation, then a larger model is more likely to approach the optimal solution if the data is sufficient.
Therefore, larger models using the same training objectives, regardless of their architecture, will tend to converge towards this optimal solution. When different training objectives have similar minima, larger models are more efficient at finding these minima and tend to similar solutions across training tasks.

The diagram is like this:
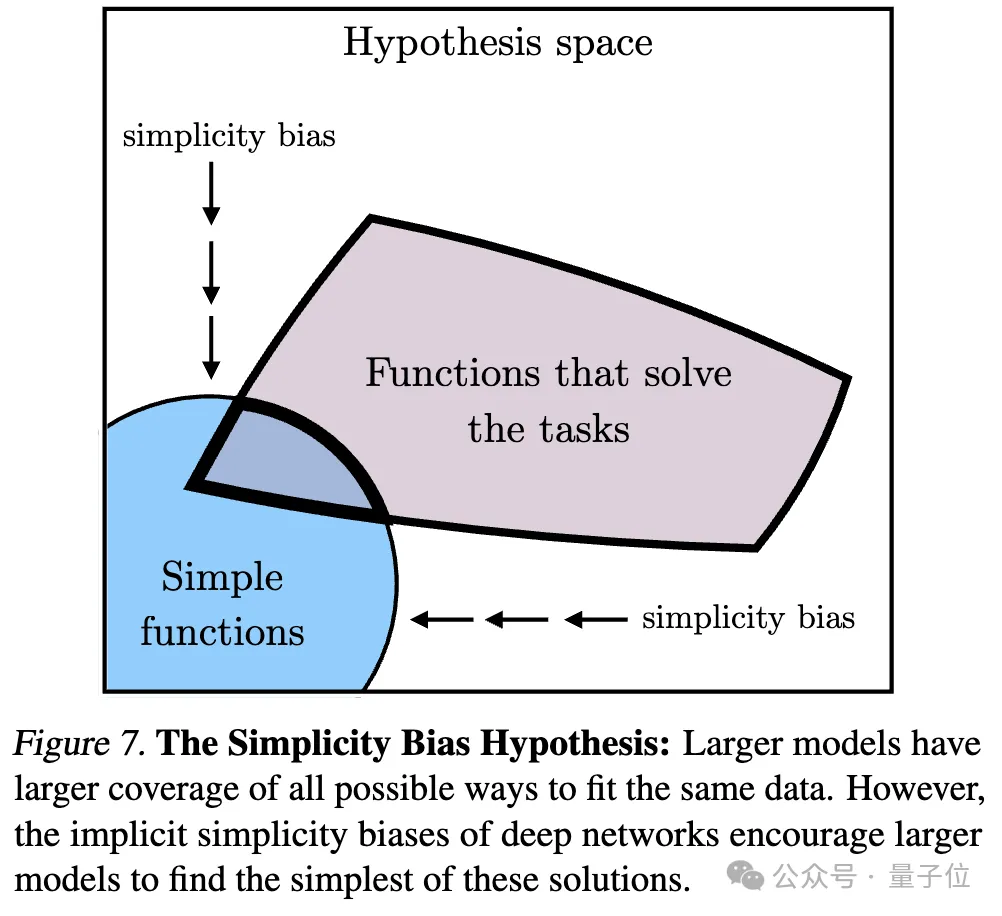
3. Simplicity bias leads to convergence (Convergence via Simplicity Bias)
Regarding the reason for convergence, the researchers also proposed a hypothesis. Deep networks tend to look for simple fits to the data. This inherent simplicity bias makes large models tend to be simplified in representation, leading to convergence.

#That is, larger models have broader coverage and are able to fit the same data in all possible ways. However, the implicit simplicity preference of deep networks encourages larger models to find the simplest of these solutions.
After a series of analyzes and experiments, as mentioned at the beginning, the researchers proposed Plato Representation Hypothesis, The end point of this convergence is speculated.
That is, different AI models, although trained on different data and targets, their representation spaces are converging on a common statistical model that represents the real world that generates the data we observe.
They first constructed an idealized discrete event world model. The world contains a series of discrete events Z, each event is sampled from an unknown distribution P(Z). Each event can be observed in different ways through the observation function obs, such as pixels, sounds, text, etc.
Next, the author considered a class of contrastive learning algorithms that attempt to learn a representation fX such that the inner product of fX(xa) and fX(xb) approximates xa and xb as a positive sample pair# The ratio of the log odds of ## (from nearby observations) to the log odds of as a negative sample pair (randomly sampled).
 After mathematical derivation, the author found that if the data is smooth enough, this type of algorithm will converge to a kernel function that is the point mutual information of xa and xb
After mathematical derivation, the author found that if the data is smooth enough, this type of algorithm will converge to a kernel function that is the point mutual information of xa and xb
Representation of kernel fX.
 Since the study considers an idealized discrete world, the observation function obs is bijective, so the PMI kernel of xa and xb is equal to the PMI of the corresponding events za and zb nuclear.
Since the study considers an idealized discrete world, the observation function obs is bijective, so the PMI kernel of xa and xb is equal to the PMI of the corresponding events za and zb nuclear.
 This means that whether learning representations from visual data X or language data Y, they will eventually converge to the same kernel function representing P(Z), that is, events PMI core between pairs.
This means that whether learning representations from visual data X or language data Y, they will eventually converge to the same kernel function representing P(Z), that is, events PMI core between pairs.

The researchers tested this theory through an empirical study on color. Whether color representation is learned from pixel co-occurrence statistics of images or word co-occurrence statistics of text, the resulting color distances are similar to human perception, and as the model size increases, this similarity becomes higher and higher. .
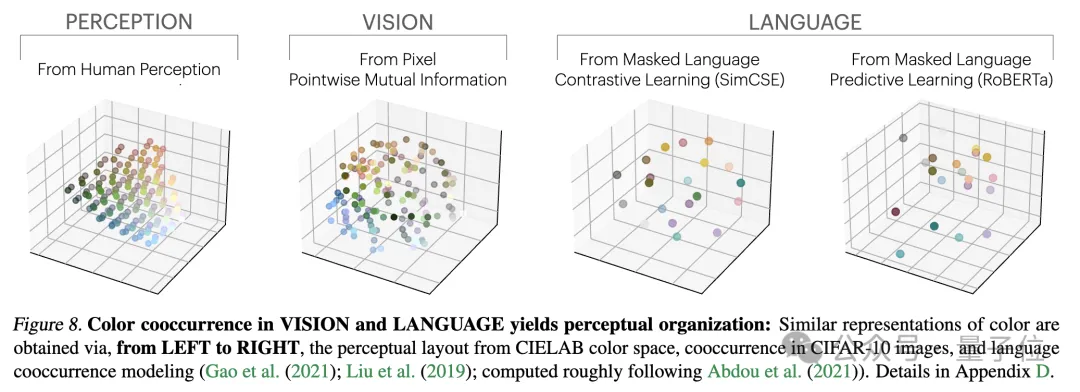
This is consistent with theoretical analysis, that is, greater model capability can more accurately model the statistics of observation data, thereby obtaining PMI kernels that are closer to ideal event representations.
At the end of the paper, the author summarizes the potential impact of representation convergence on the field of AI and future research directions, as well as potential limitations and exceptions to the Platonic representation assumption.
They pointed out that as the model size increases, the possible effects of convergence of representation include but are not limited to:
The author emphasizes that the premise of the above impact is that the training data of future models must be sufficiently diverse and lossless to truly converge to a representation that reflects the statistical laws of the actual world.
At the same time, the author also stated that data of different modalities may contain unique information, which may make it difficult to achieve complete representation convergence even as the model size increases. In addition, not all representations are currently converging. For example, there is no standardized way of representing states in the field of robotics. Researcher and community preferences may lead models to converge toward human representations, thereby ignoring other possible forms of intelligence.
And intelligent systems designed specifically for specific tasks may not converge to the same representations as general intelligence.
The authors also highlight that methods of measuring representation alignment are controversial, and different measurement methods may lead to different conclusions. Even if the representations of different models are similar, gaps remain to be explained, and it is currently impossible to determine whether this gap is important.
For more details and argumentation methods, please put the paper here~
Paper link: https://arxiv.org/abs/2405.07987
The above is the detailed content of Ilya's first action after leaving his job: Liked this paper, and netizens rushed to read it. For more information, please follow other related articles on the PHP Chinese website!
 How to bind data in dropdownlist
How to bind data in dropdownlist
 How to open a digital currency account
How to open a digital currency account
 What are the common management systems?
What are the common management systems?
 Win10 does not support the disk layout solution of Uefi firmware
Win10 does not support the disk layout solution of Uefi firmware
 The difference between powershell and cmd
The difference between powershell and cmd
 How to solve the problem that the device manager cannot be opened
How to solve the problem that the device manager cannot be opened
 The difference between vue2 and vue3 two-way binding
The difference between vue2 and vue3 two-way binding
 How to solve problems when parsing packages
How to solve problems when parsing packages








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



