


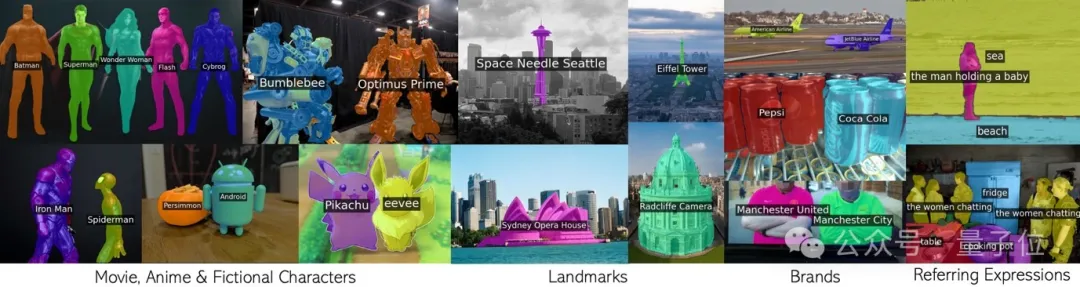
Call CLIP in a loop to effectively segment countless concepts without additional training.
Any phrase including movie characters, landmarks, brands, and general categories.
This new result of the joint team of Oxford University and Google Research has been accepted by CVPR 2024 and the code has been open sourced.

The team proposed a new technology called CLIP as RNN (CaR for short), which solves several key problems in the field of open vocabulary image segmentation:
To understand the principle of CaR, you need to first review the recurrent neural network RNN.
RNN introduces the concept of hidden state, which is like a "memory" that stores information from past time steps. And each time step shares the same set of weights, which can model sequence data well.
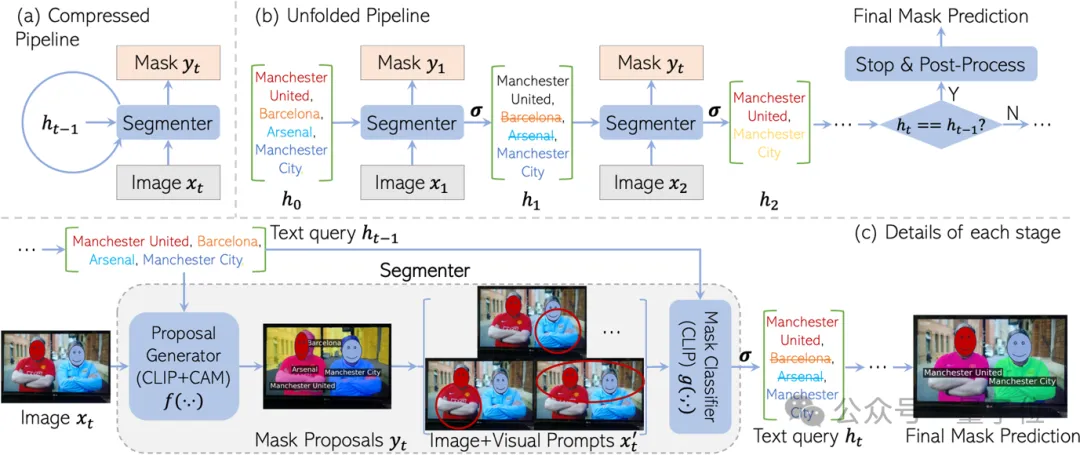
Inspired by RNN, CaR is also designed as a cyclic framework, consisting of two parts:
If iteration continues like this, the text query will become more and more accurate, and the quality of the mask will become higher and higher.
Finally, when the query set no longer changes, the final segmentation result can be output.

The reason why this recursive framework is designed is to retain the "knowledge" of CLIP pre-training to the greatest extent.
There are a huge number of concepts seen in CLIP pre-training, covering everything from celebrities, landmarks to anime characters. If you fine-tune on a split data set, the vocabulary is bound to shrink significantly.
For example, the "divide everything" SAM model can only recognize a bottle of Coca-Cola, but not even a bottle of Pepsi-Cola.

#But using CLIP directly for segmentation, the effect is not satisfactory.
This is because CLIP’s pre-training goal was not originally designed for dense prediction. Especially when certain text queries do not exist in the image, CLIP can easily generate some wrong masks.
CaR cleverly solves this problem through RNN-style iteration. By repeatedly evaluating and filtering queries while improving the mask, high-quality open vocabulary segmentation is finally achieved.
Finally, let’s follow the team’s interpretation and learn about the details of the CaR framework.
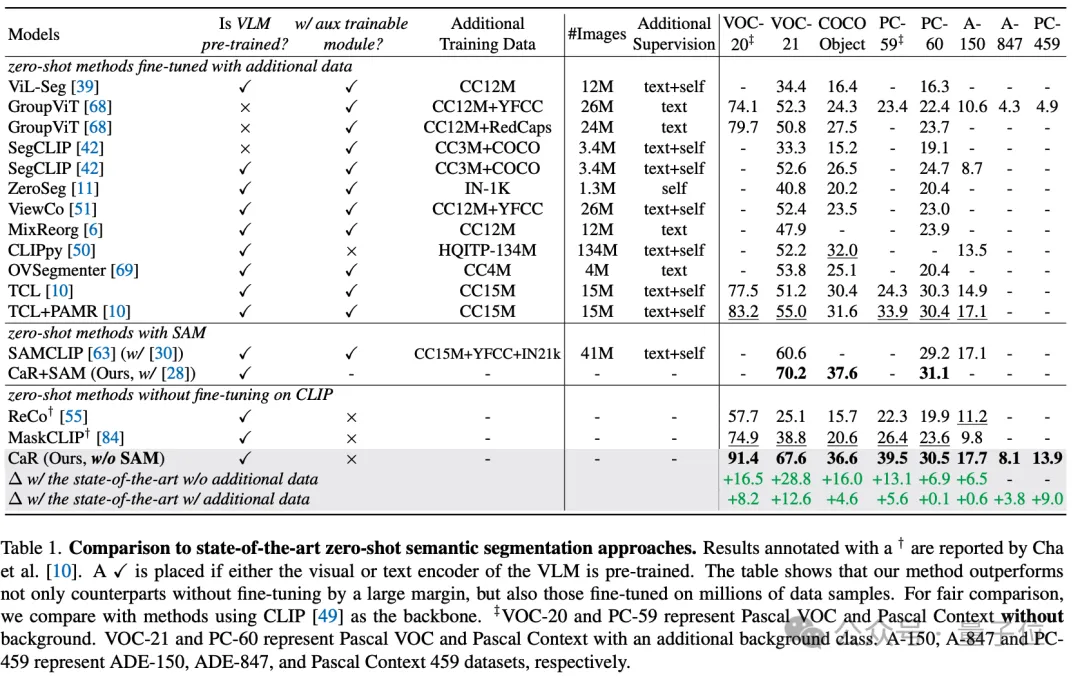
Through these technical means, CaR technology has achieved significant performance improvements on multiple standard data sets, surpassing traditional zero-shot learning methods, and working with models that have been fine-tuned on a large amount of data. It also showed competitiveness in comparison. As shown in the table below, although no additional training and fine-tuning is required, CaR shows stronger performance on eight different indicators of zero-shot semantic segmentation than previous methods fine-tuned on additional data.
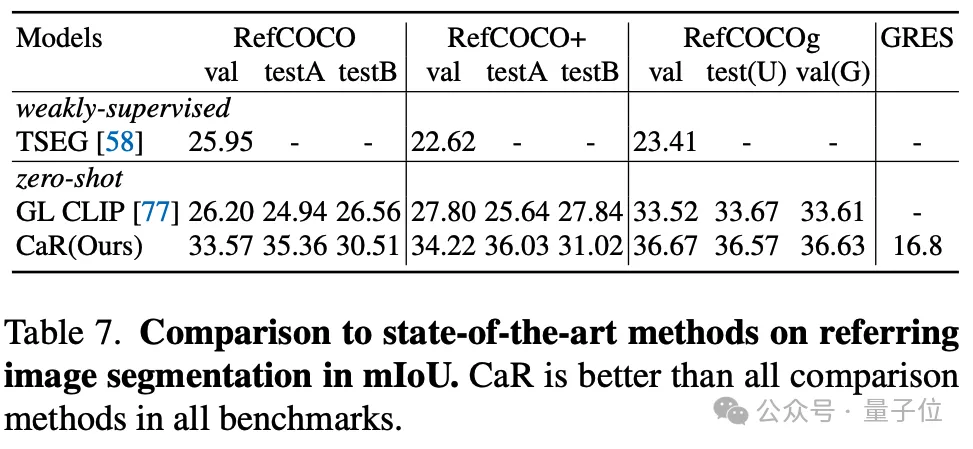
The author also tested the effect of CaR on zero-sample Referring segmentation. CaR also showed stronger performance than the previous zero-sample method.
To sum up, CaR (CLIP as RNN) is an innovative recurrent neural network framework that can effectively perform zero training without additional training data. Sample semantic and referent image segmentation tasks. It significantly improves segmentation quality by preserving the broad vocabulary space of pre-trained visual-language models and leveraging an iterative process to continuously optimize the alignment of text queries with mask proposals.
The advantages of CaR are its ability to handle complex text queries without fine-tuning and its scalability to the video field, which has brought breakthrough progress to the field of open vocabulary image segmentation.
Paper link: https://arxiv.org/abs/2312.07661.
Project homepage: https://torrvision.com/clip_as_rnn/.
The above is the detailed content of CLIP is selected as CVPR when used as RNN: it can segment countless concepts without training | Oxford University & Google Research. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



