

前言:
在之前的讲解中,我们已经完成了网络基本原理的介绍。整个过程围绕TCP/IP四层协议展开,详细讲述了应用层、传输层、网络层以及数据链路层的相关内容。至于一些小主题,比如ARP欺骗、HTTP协议的工作机制、cookie与session等细节,我们将在后续进行补充说明。
从本文开始,我们将重点转向IO相关的问题。通过了解不同的IO模型,逐步引出多路复用的核心概念,并深入讲解select、poll和epoll的实现方式,最终还会单独介绍Reactor模式。至此,关于网络的基本知识也将告一段落。
话不多说,我们直接进入对五种IO模型的解析。
提到IO这个话题,其实它贯穿了我们学习编程的各个阶段。从C语言中的printf和scanf函数,到文件操作中的read和write,再到Linux系统中的文件描述符概念,甚至在网络通信中也频繁使用文件描述符,这些都体现了IO在编程中的重要地位。
那么问题来了,虽然我们一直将IO理解为输入输出,但其背后的过程远不止如此。以scanf为例,当程序运行到该函数时会处于阻塞状态,直到用户输入数据为止。这说明IO过程中存在一个“等待”的环节。
实际上,完整的IO操作包含两个核心部分:等待和拷贝。也就是说,只有当数据准备就绪(例如用户输入),系统才会将其从内核缓冲区复制到应用程序的缓冲区中。
目前我们所接触到的基本上都是阻塞IO,当然也存在其他类型的IO模型,我们将在下文中逐一介绍。值得一提的是,在MySQL索引优化中提到的“减少IO次数”就是为了提升效率,而高效的IO正是通过降低“等待”在整个IO过程中的占比来实现的。
为了帮助理解,我们可以借助钓鱼的场景来类比五种IO模型:
接下来我们就具体来看每种模型的实际含义。
这是我们最熟悉的IO方式。像
read()
recvfrom()
scanf()
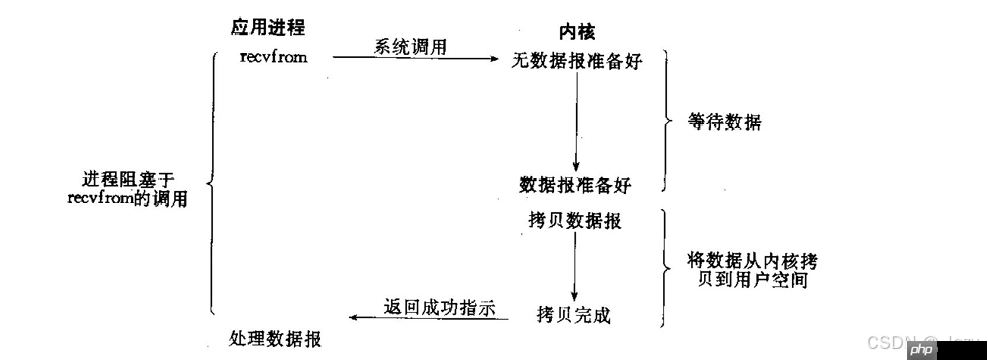
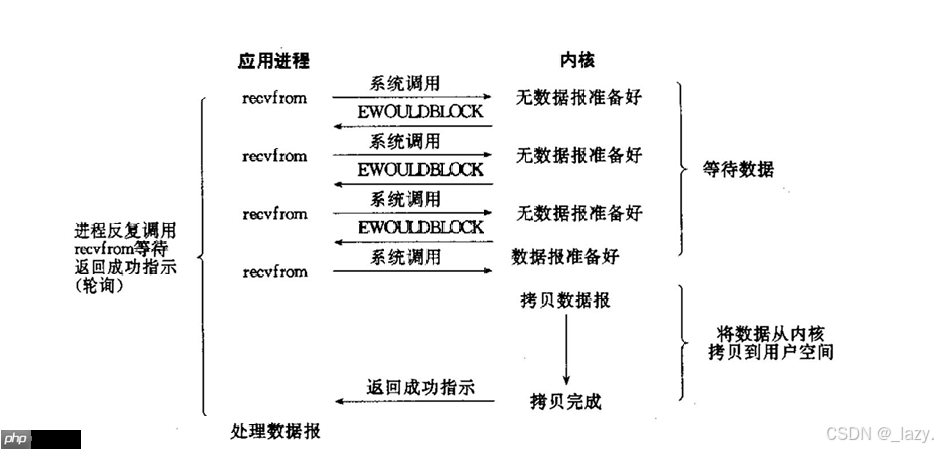
顾名思义,这种模型不会让进程长时间挂起。但它需要不断尝试读写操作(即轮询),因此可能会浪费大量CPU资源。适用于特定高并发场景。
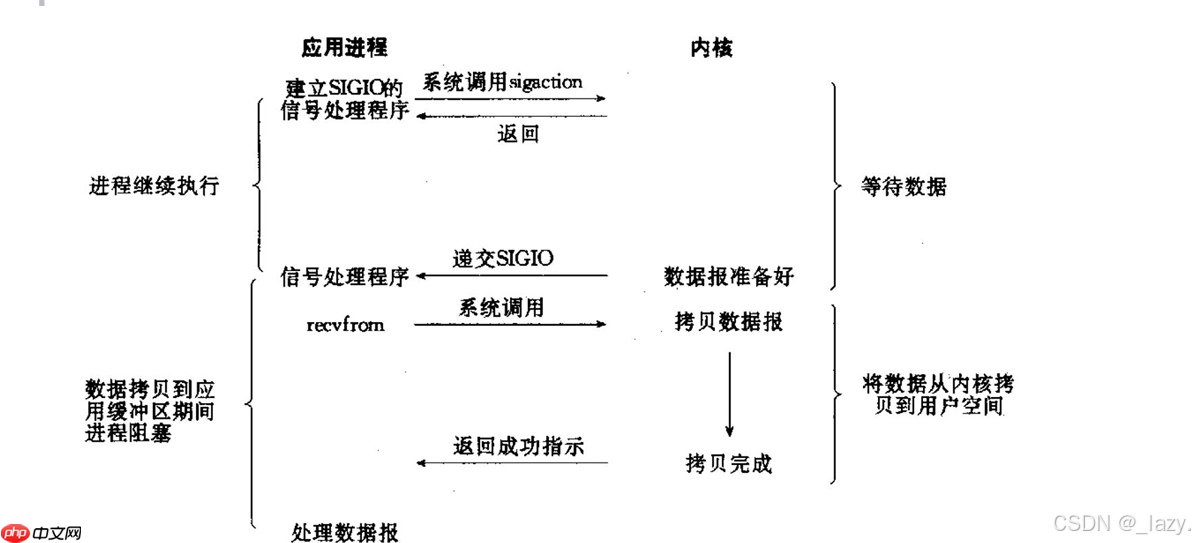
通过注册信号处理函数(如SIGIO),当数据就绪时由内核主动通知应用程序。这种方式避免了持续轮询,但仍属于同步IO范畴。
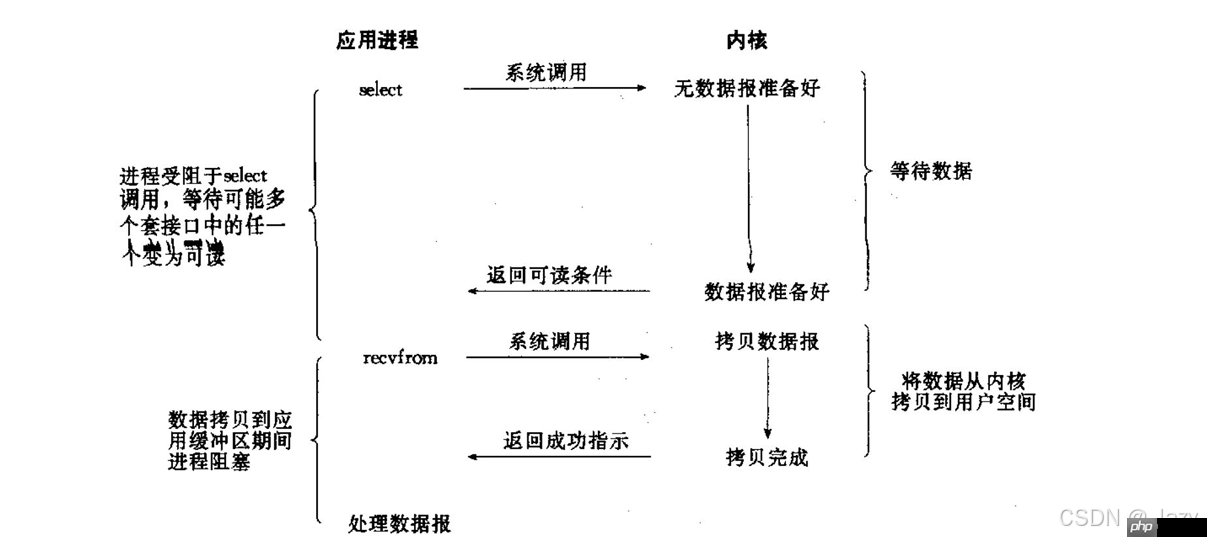
本质上是阻塞IO的一种扩展形式,允许单个线程同时监听多个文件描述符。典型的实现包括
select()
poll()
epoll()
真正意义上的非阻塞IO。应用程序发起请求后立即返回,之后由操作系统完成数据准备和复制工作,并通过信号或回调通知应用程序。由于全程不阻塞主线程,因此称为异步。
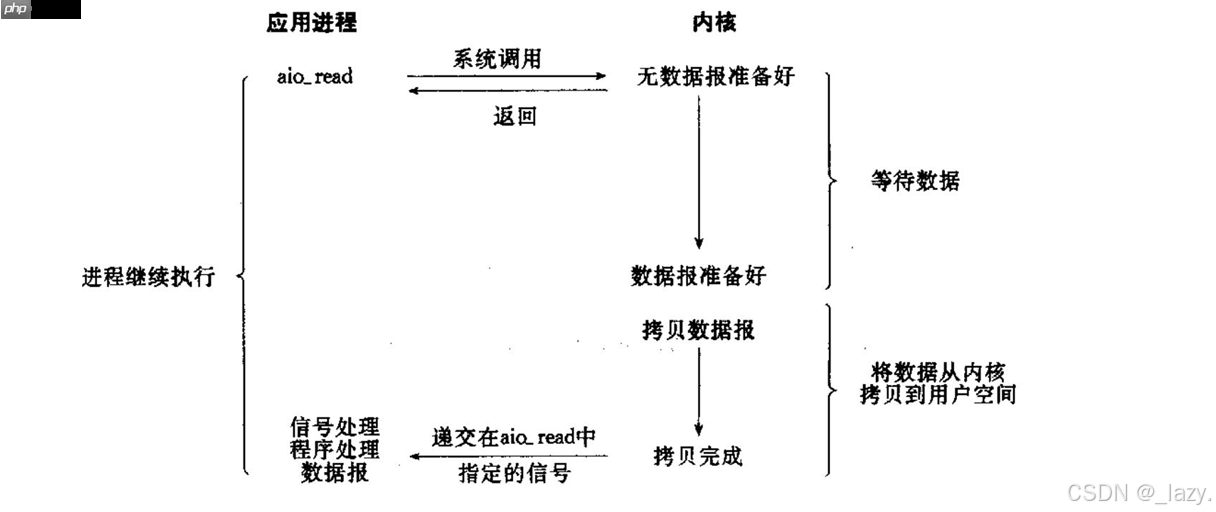
在这五种模型中,IO多路复用因其高效性被广泛采用,也是我们后续重点研究的方向。
如果我们希望将原本阻塞的IO操作改为非阻塞模式,可以使用
fcntl()
void SetNoBlock() {
int n = ::fcntl(0, F_GETFL);
if (n < 0) {
// 错误处理
}
n |= O_NONBLOCK;
fcntl(0, F_SETFL, n);
}此时再次调用
read()
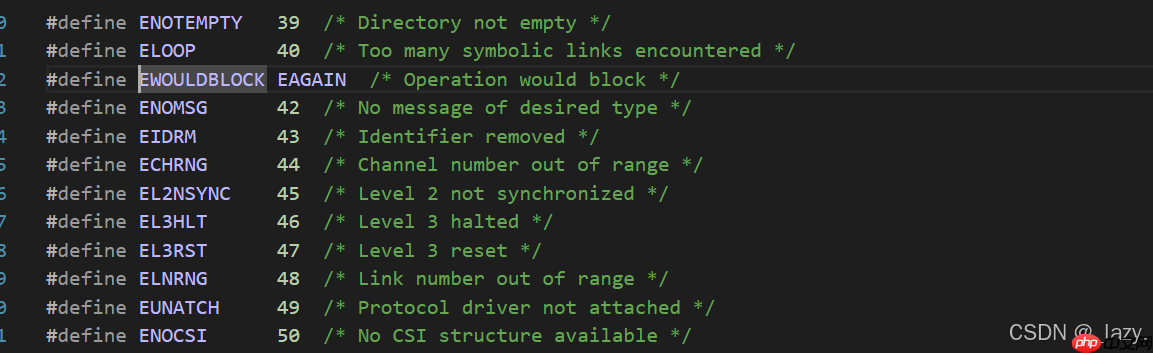
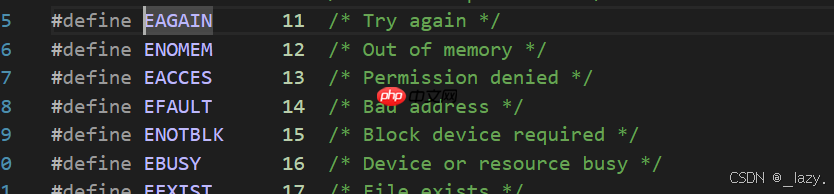
EWOULDBLOCK
EAGAIN

以上就是关于IO模型的基本概述,作为后续深入探讨的一个铺垫。
以上就是初识Linux · 五种IO模型和非阻塞IO的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 //m.sbmmt.com/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 719
719
























