


JavaScript is case-sensitive:
Keywords, variables, function names, and all identifiers must be in consistent upper and lower case (generally we write them in lower case), which is very different from the multi-style writing method when I first learned C#.
For example: (Here we take the variables str and Str as examples)
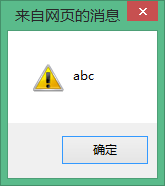
If str and Str are the same variable, then alert(str);, the output result should be ABC instead of abc as shown above. This just shows: JavaScript is case-sensitive.
Unicode escape sequence
The emergence of the Unicode character set is to make up for the limitation that ASCII codes can only represent 128 characters. If we want to display Chinese characters and Japanese in daily life, ASCII is obviously impossible. So Unicode is a superset of ASCII and Latin-1. First of all, JavaScript programs are written using the Unicode character set. However, in some computer hardware and software, it is impossible to display or input the complete set of Unicode characters (such as: é). In order to solve this phenomenon, JavaScript defines a special Sequence, this sequence uses 6 ASCII characters to represent any 16-bit Unicode internal code. This special sequence is collectively called the Unicode escape sequence. It is prefixed with u, followed by 4 hexadecimal digits
For example:
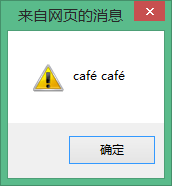
But we should note that Unicode allows multiple methods to encode the same character, as illustrated by the above é escape example:
é:
1. Unicode character u00E9 can be used to represent
2. You can also use eu0301 (intonation character) to represent
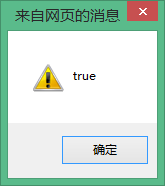
Although the results displayed on the text editor are the same, their binary encoding representations are fundamentally different. The programming language will eventually be converted into the computer mechanical code (binary encoding) of the local platform, and the computer can only process the binary The result can only be known by comparing the codes, so the final result of their comparison can only be false
So this is the best explanation for "Unicode allows multiple methods to encode the same character", because the Unicode standard defines a preferred encoding format for all characters to convert text into a uniform Unicode format. Sense sequence for appropriate comparison
Using é as an example again:
Are the é in face and café the same?
The é in face and café are both converted to u00E9 or both are converted to eu0301, so that the é in face and café can be compared





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



