

 System Tutorial
Windows Series
Real-time computing framework that can travel through time and space--Flink's processing of time
System Tutorial
Windows Series
Real-time computing framework that can travel through time and space--Flink's processing of time
Real-time computing framework that can travel through time and space--Flink's processing of time

In the Streaming-The Future of Big Data we know that the two most important things for streaming processing are correctness and time reasoning tools. Flink has very good support for both.
Flink guarantees correctnessFor continuous event streaming data, since there may be events that have not yet arrived when we process them, the correctness of the data may be affected. The common practice of using high-latency offline computing is now guaranteed, but it also sacrifices low latency.
The correctness of Flink is reflected in the definition of the calculation window in line with the natural laws of data generation. For example, click stream event tracks the access status of 3 users A, B, and C. We see that there may be gaps in the data, which is the session window.
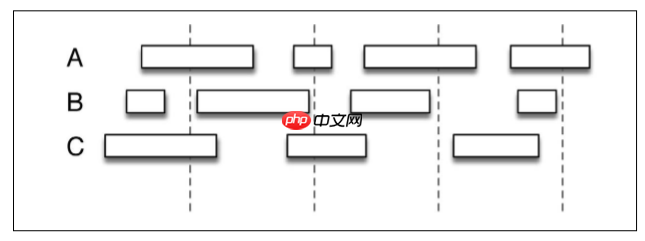
Using SparkStreaming's microbatch method (dashed lines are calculation windows, and solid lines are session windows), it is difficult to match the calculation windows and session windows. Using Flink's stream processing API, you can flexibly define the calculation window. For example, you can set a value, if it exceeds this value, the activity will be considered to be over.
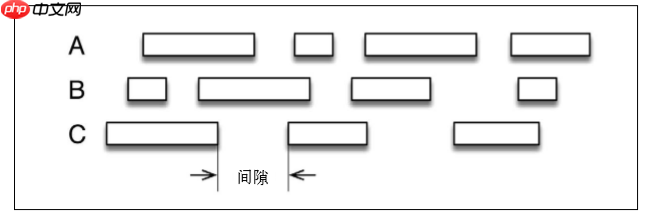
Unlike general stream processing, Flink can adopt event time, which is very useful for correctness.
For the correctness of failure, the calculation state must be tracked. Most of the time, the state guarantee is completed by developers, but continuous stream processing calculations have no end. Flink uses checkpoint-checkpoint technology to solve this problem. At each checkpoint, the system records the intermediate calculation status, which is accurate to reset when a fault occurs. This method allows the system to have fault tolerance in a low overhead manner - when everything is normal, the checkpoint mechanism has a very small impact on the system.
The interface provided by Flink includes tracking computing tasks and using the same technology to implement stream processing and batch processing, simplifying operation and maintenance development work, which is also a guarantee of correctness.
Flink's time processingThe biggest difference between using stream processing and batch processing is the processing of time.
Using batch processing architectureIn this architecture, we can store data every once in a while, for example, in HDFS, and execute it regularly by the scheduler to output the results.
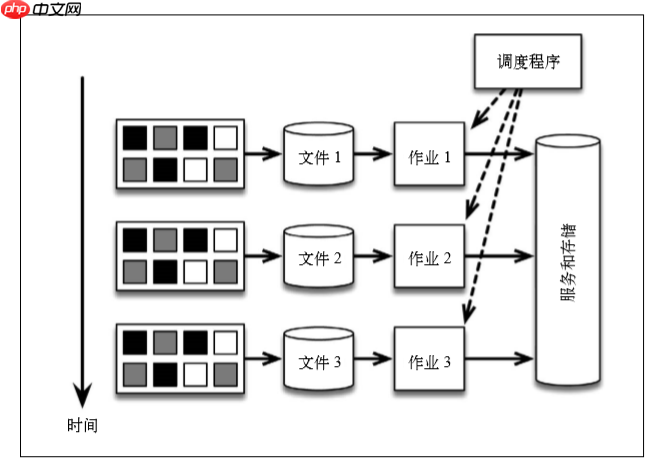
This architecture is feasible but there are several problems:
Too many separate parts. To calculate the number of events in the data, this architecture uses too many systems. Every system has learning costs and management costs, and there may be bugs. The method of handling time is unclear. Assume that it needs to be counted every 30 minutes instead. This change involves workflow scheduling logic (rather than application code logic), confusing DevOps problems with business requirements. Early warning. Assume that in addition to counting once an hour, you also need to receive a count warning as early as possible (such as when the number of events exceeds 10). To do this, Storm can be introduced to collect message flows in addition to periodically running batch jobs. Storm provides approximate counts in real time, and batch jobs provide accurate counts per hour. But this way, a system is added to the architecture, and a new programming model related to it. The above architecture is called the Lambda architecture.
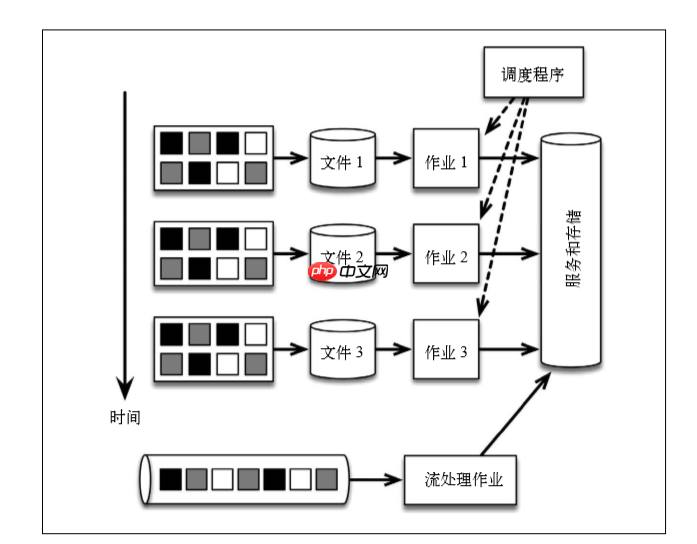
First, the message is written centrally to the message transmission system kafka, the event stream is provided by the message transmission system, and is processed only by a single Flink job.
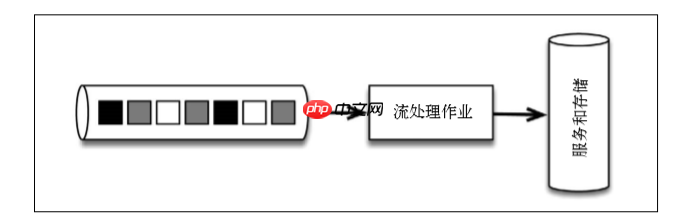
Split the event stream into batches of tasks in units of time, and this logic is completely embedded in the application logic of the Flink program. The warning is generated by the same program, and out-of-order events are handled by Flink themselves. To change from grouping with fixed time to grouping according to the time period in which the data is generated, just modify the definition of the window in the Flink program. Also, if the application's code has been changed, you can replay the application by simply replaying the Kafka theme. Using a streaming architecture can significantly reduce systems that need to learn, manage, and write code. Flink application code example:
Code language: javascript Number of code runs: 0 run copy <code class="javascript">DataStream<LogEvent> stream = env // 通过Kafka生成数据流.addSource(new FlinkKafkaConsumer(...)) // 分组.keyBy("country") // 将时间窗口设为60分钟.timeWindow(Time.minutes(60)) // 针对每个时间窗口进行操作.apply(new CountPerWindowFunction());</code>In stream processing, there are two main concepts of time:
Event time, that is, the time when the event actually occurs. More precisely, each event has a timestamp associated with it, and the timestamp is part of the data record.
Processing time, that is, the time when the event is processed. Processing time is actually the time measured by the machine that handles events.
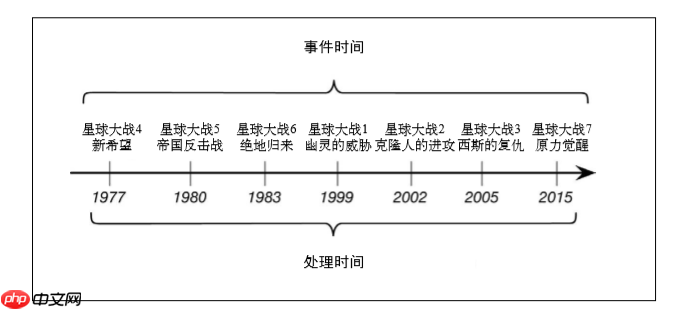
Take the Star Wars series as an example. The first 3 movies released are the 4th, 5th and 6th in the series (this is the time of the event), and their release years are 1977, 1980 and 1983 (this is the time of the process). The 1st, 2nd, 3rd and 7th series released by the event time were then the corresponding processing times were 1999, 2002, 2005 and 2015 respectively. It can be seen that the order of event flow may be messy (although the order of years is generally not messy)
There is usually the third concept of time, namely, intake time, also known as entry time. It refers to the time when an event enters the stream processing framework. Data that lacks the time of the real event will be timestamped by the stream processor, that is, when the stream processor first sees it (this operation is done by the source function, which is the first processing point of the program).
In the real world, many factors (such as temporary connection interruption, network delay caused by different reasons, clock out of synchronization in distributed systems, steep increase in data rates, physical reasons, or bad luck) cause event time and processing time to be biased (i.e. event time deviation). Event chronological order and processing chronological order are often inconsistent, which means that events arrive at the stream processor in out of order.
Flink allows users to choose to adopt event time, processing time, or ingestion time definition windows based on the required semantics and requirements for accuracy.
windowThe time window is the easiest and most useful one. It supports scrolling and sliding.
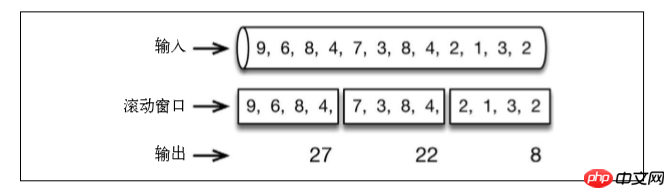
For example, a one-minute scrolling window collects the values of the last minute and outputs the sum at the end of one minute:
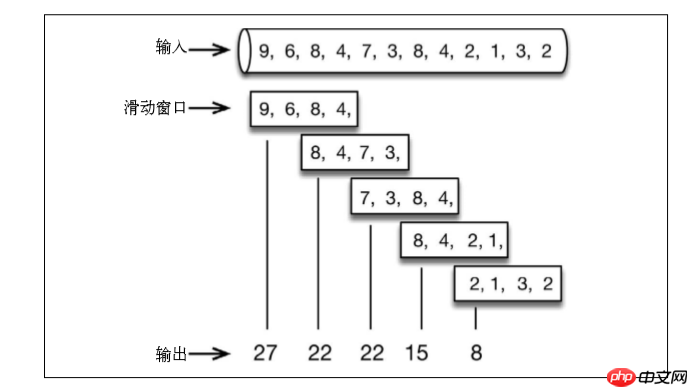
The one-minute sliding window calculates the sum of the values of the last minute, but slides every half minute and outputs the result:
In Flink, the one-minute scrolling window is defined as follows.
Code language: javascript Number of code runs: 0 run copy<code class="javascript">stream.timeWindow(Time.minutes(1))</code>
The one-minute sliding window that slides every half minute (i.e. 30 seconds) is shown below.
Code language: javascript Number of code runs: 0 run copy<code class="javascript">stream.timeWindow(Time.minutes(1), Time.seconds(30))</code>
Another common window supported by Flink is called the counting window. When using a count window, the grouping is no longer a timestamp, but the number of elements.
A sliding window can also be interpreted as a counting window consisting of 4 elements and slides once every two elements. The scrolling and sliding counting windows are defined as follows.
Code language: javascript Number of code runs: 0 run copy<code class="javascript">stream.countWindow(4) stream.countWindow(4, 2)</code>
Although the counting window is useful, its definition is not as rigorous as the time window, so it should be used with caution. Time does not stop, and the time window will always be "closed". But as far as counting windows are concerned, assuming that the number of elements defined is 100, and the corresponding elements of a key will never reach 100, the window will never close, and the memory occupied by the window will be wasted.
Another useful window supported by Flink is the session window. The session window is set by the timeout time, that is, how long does it take to wait before you think the session has ended. Examples are as follows:
Code language: javascript Number of code runs: 0 run copy<code class="javascript">stream.window(SessionWindows.withGap(Time.minutes(5))</code>trigger
In addition to windows, Flink also provides a trigger mechanism. The trigger controls the time when the result is generated, that is, when the window content is aggregated and the result is returned to the user. Each default window has a trigger. For example, a time window that takes event time will be triggered when a watermark is received. For users, in addition to generating complete and accurate results when receiving the watermark, custom triggers can also be implemented.
Time backtrackA core capability of stream processing architecture is the time backtracking mechanism. It means rewinding the data stream to a time in the past, restarting the handler until the current time is processed. Kafka supports this capability.
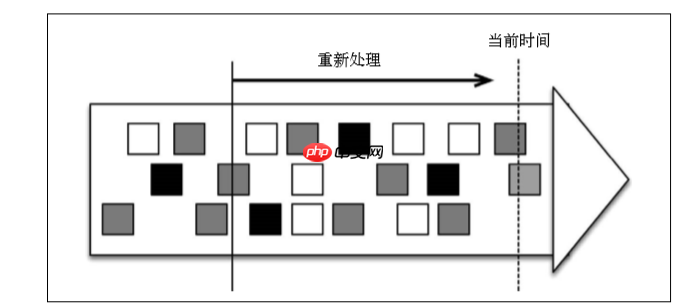
Real-time stream processing is always processing the most recent data (i.e., data of "current time" in the figure), while historical stream processing starts from the past and can be processed until the current time. Streaming processors support event time, which means "rewinding" the data stream and rerunning the same program with the same set of data will get the same result.
WatermarkFlink advances event time through watermarks. Watermark is a conventional record embedded in the stream. The calculation program uses the watermark to know that a certain time point has arrived. The window that receives the watermark will know that no more records earlier than that time will appear, because all events with timestamps less than or equal to that time have arrived. At this time, the window can safely calculate and give the result (sum). Watermark makes the event time completely independent of the processing time. Late watermarks ("late" is from the perspective of processing time) do not affect the correctness of the results, but only affect the speed of the results being received.
Watermarks are generated by application developers, which usually require a certain understanding of the corresponding fields. Perfect watermarks can never be wrong: Events whose timestamps are smaller than the watermark mark time will not appear again.
If the watermark is too late, the result may be received very slowly. The solution is to output an approximate result before the watermark arrives (Flink can do it). If the watermark arrives too early, you may receive an error result, but Flink's mechanism to process late data can solve this problem.
Related articles: Streaming-The Future of Big Data
The cornerstone of real-time computing big data processing - Google Dataflow
The Future of Data Architecture—A Brief Discussion on Streaming Processing Architecture
The above is the detailed content of Real-time computing framework that can travel through time and space--Flink's processing of time. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

ArtGPT
AI image generator for creative art from text prompts.

Stock Market GPT
AI powered investment research for smarter decisions

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 Is Xiaohongshu Qianfan APP easy to use? User experience and function evaluation of Xiaohongshu Qianfan APP
Sep 29, 2025 pm 12:03 PM
Is Xiaohongshu Qianfan APP easy to use? User experience and function evaluation of Xiaohongshu Qianfan APP
Sep 29, 2025 pm 12:03 PM
Xiaohongshu Qianfan APP provides functions such as product order management, customer service speech library, timed content release, automatic virtual product shipment and sub-account permission allocation, and supports efficient mobile operation; however, some users have reported performance problems such as lag in uploading pictures and delayed message sending. It is recommended to use and keep the APP updated in a Wi-Fi environment to improve the experience.
 Why don't I have Xiaohongshu Qianfan APP_Instructions on the permissions of Xiaohongshu Qianfan APP
Sep 29, 2025 pm 12:18 PM
Why don't I have Xiaohongshu Qianfan APP_Instructions on the permissions of Xiaohongshu Qianfan APP
Sep 29, 2025 pm 12:18 PM
You must first complete the enterprise or professional account certification and open a store to ensure that the account is not violated and complies with industry access, and then update the APP to the latest version to find the entrance.
 How to choose the background music for Douyin_Recommend and use of Douyin's popular BGMs
Sep 29, 2025 pm 12:06 PM
How to choose the background music for Douyin_Recommend and use of Douyin's popular BGMs
Sep 29, 2025 pm 12:06 PM
Priority is given to finding popular BGMs through the Douyin hot list, such as "The Moon of the Small Village" adapts to pastoral style, "Crying with the Wind" is used for inspirational themes of broken hearts, and combining video emotions to select music and collect common songs to improve efficiency.
 Which free novel app is better_Recommended popular novel reading software
Sep 29, 2025 pm 12:00 PM
Which free novel app is better_Recommended popular novel reading software
Sep 29, 2025 pm 12:00 PM
Answer: Tomato Free Novel, Qimao Free Novel, Shuqi Novel and Crazy Reading Novel are four free reading applications with rich resources and smooth experience. Tomato improves the sustainability of reading through personalized recommendations and incentive mechanisms; Qimao focuses on free websites and relies on advertising to support copyrighted content, suitable for readers who like urban cool articles and fantasy; Shuqi Novel relies on Alibaba's ecosystem to integrate novels, comics and videos, and supports account interoperability and social interaction; Crazy Reading Novel focuses on high-quality original works, and encourages users to participate in the construction of the content ecosystem. Each application provides functions such as classified browsing, personalized settings, offline caching, etc. Some also support listening to books, notes and excerpts and reading activities to meet diverse reading needs.
 How to change the number of steps in WeChat exercise steps_Modify and synchronize the number of steps in WeChat exercise steps
Sep 29, 2025 am 11:54 AM
How to change the number of steps in WeChat exercise steps_Modify and synchronize the number of steps in WeChat exercise steps
Sep 29, 2025 am 11:54 AM
The abnormal WeChat movement step problem can be solved by modifying system health data, using third-party simulation tools, checking permission settings and manually refreshing.
 How to set the timed turn off Kugou Music? Tutorial on Kugou Music's sleep mode
Sep 29, 2025 pm 12:09 PM
How to set the timed turn off Kugou Music? Tutorial on Kugou Music's sleep mode
Sep 29, 2025 pm 12:09 PM
1. Open the Kugou Music App, click the three horizontal icon in the upper right corner to enter the menu, select "Timed Off" and set the countdown time to automatically stop after the playback is finished, saving power.
 How to set up fans' visible notes_Xiaohongshu set up exclusive benefits for fans' visible notes
Sep 29, 2025 am 11:48 AM
How to set up fans' visible notes_Xiaohongshu set up exclusive benefits for fans' visible notes
Sep 29, 2025 am 11:48 AM
Currently, Xiaohongshu does not have the "visible only for fans", and can limit content reading by setting "visible only for yourself", using private favorites or registering a small account.
 Persistent memory programming
Sep 30, 2025 am 10:47 AM
Persistent memory programming
Sep 30, 2025 am 10:47 AM
Persistent Memory Programming June 2013 I wrote about future interfaces for nonvolatile memory (NVM). This describes the NVM programming model under development by SNIANVM Programmingtechnicalworkgroup (TWG). Over the past four years, specifications have been released, and as predicted, programming models have become the focus of a lot of follow-up efforts. This programming model, described in the specification as NVM.PM.FILE, can map PM to memory by the operating system as a file. This article introduces how the persistent memory programming model is implemented in the operating system, what work has been done, and what challenges we still face. Persistent memory background PM and storageclassme
