Insgesamt10000 bezogener Inhalt gefunden

So verwenden Sie den PHP-Bloom-Filter für die URL-Deduplizierung und das Website-Crawling-Management
Artikeleinführung:Überblick über die Verwendung des PHP-Bloom-Filters für die URL-Deduplizierung und Website-Crawling-Verwaltung: Beim Crawlen einer Website besteht eine wichtige Aufgabe darin, doppelte URLs zu entfernen, um zu vermeiden, dass dieselbe Seite wiederholt gecrawlt wird, was Ressourcen und Zeit verschwendet. Der Bloom-Filter ist eine effiziente Datenstruktur, mit der schnell ermittelt werden kann, ob ein Element in einer großen Menge vorhanden ist. In diesem Artikel wird erläutert, wie Sie den PHP-Bloom-Filter für die URL-Deduplizierung und das Website-Crawling-Management verwenden. Installieren der Bloom Filter-Erweiterung Zuerst müssen wir die Bloom Filter-Erweiterung für PHP installieren. kann passieren
2023-07-09
Kommentar 0
1285

PHP und phpSpider: Wie gehe ich mit Daten-Crawling-Fehlern um, die durch Website-Änderungen verursacht werden?
Artikeleinführung:PHP und phpSpider: Wie gehe ich mit Daten-Crawling-Fehlern um, die durch Website-Änderungen verursacht werden? Einleitung: Ein Webcrawler ist ein automatisiertes Programm, mit dem Daten von Websites abgerufen und verarbeitet werden. PHP ist eine weit verbreitete Programmiersprache und phpSpider ist ein Open-Source-Webcrawler-Framework, das auf PHP basiert. Allerdings können Crawler, die ansonsten normal funktionieren würden, aufgrund ständiger Änderungen an der Website ausfallen. In diesem Artikel wird erläutert, wie mit Fehlern beim Daten-Crawling umgegangen werden kann, die durch Website-Änderungen in PHP und phpSpider verursacht werden
2023-07-22
Kommentar 0
1178

PHP und phpSpider: Wie gehe ich mit der JS-Herausforderung des Website-Anti-Crawlings um?
Artikeleinführung:PHP und phpSpider: Wie gehe ich mit der JS-Herausforderung des Website-Anti-Crawlings um? Mit der Entwicklung der Internettechnologie werden die Abwehrmechanismen von Websites gegen Crawler-Skripte immer leistungsfähiger. Websites verwenden häufig Javascript-Technologie zum Anti-Crawling, da Javascript Seiteninhalte dynamisch generieren kann, was es für einfache Crawler-Skripte schwierig macht, vollständige Daten zu erhalten. In diesem Artikel wird erläutert, wie Sie PHP und phpSpider verwenden, um die JS-Herausforderung des Website-Anti-Crawlings zu bewältigen. phpSpider ist PH-basiert
2023-07-21
Kommentar 0
1598

PHP-Web-Crawling-Grundlagen-Tutorial: Verwendung der cURL-Bibliothek für den Zugriff auf Websites
Artikeleinführung:Mit der Entwicklung des Internets und der zunehmenden Datenmenge sind Webcrawler zu einer der wichtigsten Möglichkeiten geworden, an Internetinformationen zu gelangen. Ein Webcrawler ist ein automatisiertes Programm, das über Netzwerkanfragen auf eine Website zugreift, Informationen auf der Website crawlt, verarbeitet und analysiert. In diesem Fall stellen wir vor, wie man einen einfachen Webcrawler in PHP schreibt, die cURL-Bibliothek verwendet, um auf die Website zuzugreifen, die gecrawlt werden muss, und wie man die erhaltenen Informationen verarbeitet. Installation der cURL-Bibliothek Die cURL-Bibliothek ist ein sehr leistungsfähiges Tool zum Arbeiten mit URLs über die Befehlszeile
2023-06-13
Kommentar 0
1799
网页抓取:PHP实现网页爬虫方式小结,抓取爬虫_PHP教程
Artikeleinführung:网页抓取:PHP实现网页爬虫方式小结,抓取爬虫。网页抓取:PHP实现网页爬虫方式小结,抓取爬虫 来源:http://www.ido321.com/1158.html 抓取某一个网页中的内容,需要对DOM树进行解析,找到指定
2016-07-13
Kommentar 0
1328

Wie verwende ich PHP und phpSpider, um bestimmte Website-Inhalte genau zu crawlen?
Artikeleinführung:Wie verwende ich PHP und phpSpider, um bestimmte Website-Inhalte genau zu crawlen? Einführung: Mit der Entwicklung des Internets nimmt die Datenmenge auf der Website zu und es ist ineffizient, die erforderlichen Informationen durch manuelle Vorgänge zu erhalten. Daher müssen wir häufig automatisierte Crawling-Tools verwenden, um den Inhalt bestimmter Websites abzurufen. Die PHP-Sprache und die phpSpider-Bibliothek sind eines der sehr praktischen Tools. In diesem Artikel wird erläutert, wie Sie mit PHP und phpSpider bestimmte Website-Inhalte genau crawlen, und es werden Codebeispiele bereitgestellt. 1. Installation
2023-07-22
Kommentar 0
1407
PHP抓取采集类snoopy介绍_PHP教程
Artikeleinführung:PHP抓取采集类snoopy介绍。snoopy是一个php类,用来模仿web浏览器的功能,它能完成获取网页内容和发送表单的任务。官方网站 http://snoopy.sourceforge.net/ Snoopy的一些功能
2016-07-13
Kommentar 0
670

Scrapy-Framework-Praxis: Crawlen von Jianshu-Website-Daten
Artikeleinführung:Scrapy-Framework-Praxis: Crawlen von Jianshu-Website-Daten Scrapy ist ein Open-Source-Python-Crawler-Framework, mit dem Daten aus dem World Wide Web extrahiert werden können. In diesem Artikel stellen wir das Scrapy-Framework vor und verwenden es zum Crawlen von Daten von Jianshu-Websites. Scrapy installierenScrapy kann mit Paketmanagern wie pip oder conda installiert werden. Hier verwenden wir pip, um Scrapy zu installieren. Geben Sie den folgenden Befehl in die Befehlszeile ein: pipinstallscrapy Nachdem die Installation abgeschlossen ist
2023-06-22
Kommentar 0
1329
php结合curl实现多线程抓取,phpcurl多线程抓取_PHP教程
Artikeleinführung:php结合curl实现多线程抓取,phpcurl多线程抓取。php结合curl实现多线程抓取,phpcurl多线程抓取 php结合curl实现多线程抓取 php/*curl 多线程抓取*/ /** * curl 多线程 * * @param array $array 并行网址
2016-07-13
Kommentar 0
847

Gängige Anti-Crawling-Strategien für PHP-Webcrawler
Artikeleinführung:Ein Webcrawler ist ein Programm, das automatisch Internetinformationen crawlt und in kurzer Zeit große Datenmengen abrufen kann. Aufgrund der Skalierbarkeit und Effizienz von Webcrawlern befürchten jedoch viele Websites, dass sie von Crawlern angegriffen werden könnten, und haben daher verschiedene Anti-Crawling-Strategien eingeführt. Zu den gängigen Anti-Crawling-Strategien für PHP-Webcrawler gehören vor allem die folgenden: IP-Einschränkung IP-Einschränkung ist die häufigste Anti-Crawling-Technologie. Durch die Einschränkung des IP-Zugriffs können böswillige Crawler-Angriffe wirksam verhindert werden. Mit dieser Anti-Crawling-Strategie können PHP-Webcrawler umgehen
2023-06-14
Kommentar 0
1694
PHP单线程实现并行抓取网页_PHP教程
Artikeleinführung:PHP单线程实现并行抓取网页。PHP单线程实现并行抓取网页 本PHP教程将模拟并行抓取多个页面信息的过程,关键在于单线程的并行处理。 一般情况下,大家写抓取多个页
2016-07-13
Kommentar 0
1372

Was ist die GD-Bibliothek? Detaillierte Einführung zum Laden der GD-Bibliothek in PHP
Artikeleinführung:Zunächst müssen wir vorstellen, was die GD-Bibliothek ist: Die GD-Bibliothek ist eine Erweiterungsbibliothek für PHP zur Verarbeitung von Bildern. Sie können die GD-Bibliothek zum Verarbeiten von Bildern oder zum Generieren von Bildern verwenden Die GD-Bibliothek ist eine offene Funktionsbibliothek mit offenem Quellcode zum dynamischen Erstellen von Bildern, die von der offiziellen Website heruntergeladen werden kann. Derzeit unterstützt die GD-Bibliothek GIF, PNG, JPEG, WBMP und XBM sowie andere Bildformate für die Bildverarbeitung!
2017-04-24
Kommentar 0
4568
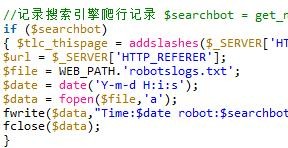
PHP implementiert die gemeinsame Nutzung von Suchmaschinen-Crawling-Code
Artikeleinführung:Dieser Artikel führt Sie hauptsächlich in den Implementierungscode der PHP-Aufzeichnung von Suchmaschinen-Crawling-Datensätzen ein und stellt Ihnen dann den Code für PHP zur Verfügung, mit dem Sie die Crawling-Datensätze jedes Such-Spiders erhalten können. Ich hoffe, er kann helfen Du.
2018-03-03
Kommentar 0
1676

So klonen Sie eine gesamte PHP-Website
Artikeleinführung:Sie können das Tool „curlMulti“ verwenden, das den Vorteil hat, verschiedene Ressourcen der komprimierten Dateien im HTML\Css\Js\RAR-Format zu crawlen, parallel zu crawlen und eine erstaunlich schnelle Crawling-Geschwindigkeit zu erzielen. Auch technisch nicht versierte Mitarbeiter können die gesamte Site schnell klonen.
2019-09-09
Kommentar 0
5865
PHP抓取网页、解析HTML常用的方法总结,php抓取_PHP教程
Artikeleinführung:PHP抓取网页、解析HTML常用的方法总结,php抓取。PHP抓取网页、解析HTML常用的方法总结,php抓取 概述 爬虫是我们在做程序时经常会遇到的一种功能。PHP有许多开源的爬虫工具,如snoopy,这
2016-07-13
Kommentar 0
962
php记录蜘蛛爬行历史的实现代码
Artikeleinführung: php记录蜘蛛爬行历史的实现代码
2016-07-25
Kommentar 0
1155
探讨:php抓取页面的几种方法
Artikeleinführung: 探讨:php抓取页面的几种方法
2016-07-25
Kommentar 0
1061

