


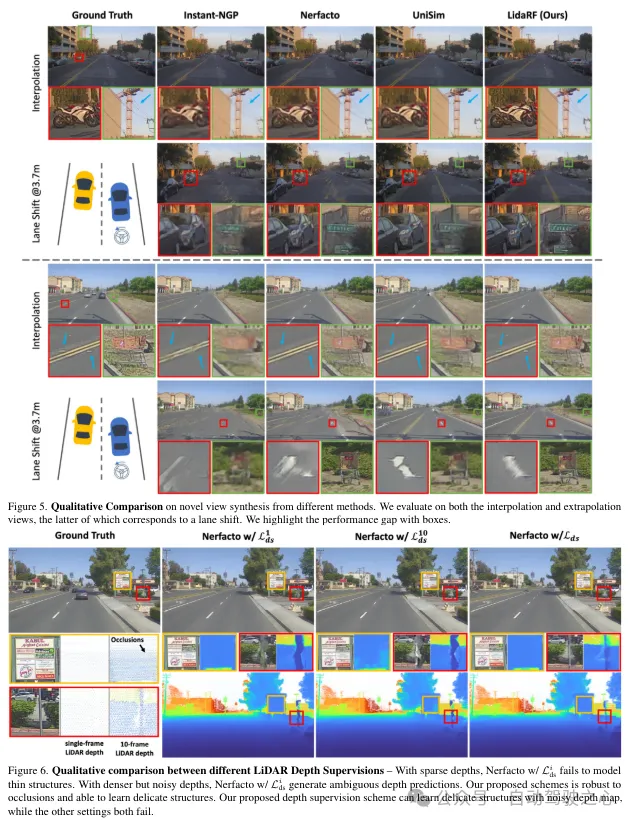
Lichtrealistische Simulation spielt eine Schlüsselrolle in Anwendungen wie dem autonomen Fahren, wo Fortschritte bei Strahlungsfeldern neuronaler Netze (NeRFs) eine bessere Skalierbarkeit durch die automatische Erstellung digitaler 3D-Assets ermöglichen können. Allerdings leidet die Rekonstruktionsqualität von Straßenszenen aufgrund der hohen Kollinearität der Kamerabewegung auf den Straßen und der spärlichen Abtastung bei hohen Geschwindigkeiten. Andererseits erfordert die Anwendung häufig ein Rendern aus einer Kameraperspektive, die von der Eingabeperspektive abweicht, um Verhaltensweisen wie Spurwechsel genau zu simulieren. LidaRF präsentiert mehrere Erkenntnisse, die eine bessere Nutzung von LIDAR-Daten ermöglichen, um die Qualität von NeRF in Straßenansichten zu verbessern. Erstens lernt das Framework geometrische Szenendarstellungen aus LiDAR-Daten, die mit einem impliziten netzbasierten Decoder kombiniert werden, um stärkere geometrische Informationen bereitzustellen, die von der angezeigten Punktwolke bereitgestellt werden. Zweitens wird eine robuste okklusionsbewusste, tiefenüberwachte Trainingsstrategie vorgeschlagen, die es ermöglicht, die NeRF-Rekonstruktionsqualität in Straßenszenen durch die Sammlung starker Informationen mithilfe dichter LiDAR-Punktwolken zu verbessern. Drittens werden verbesserte Trainingsansichten basierend auf der Intensität von LIDAR-Punkten generiert, um die signifikanten Verbesserungen, die bei der Synthese neuer Ansichten unter realen Fahrszenarien erzielt wurden, weiter zu verbessern. Auf diese Weise kann das Verfahren mit einer genaueren geometrischen Szenendarstellung, die das Framework aus LIDAR-Daten erlernt, in einem Schritt verbessert werden und bessere signifikante Verbesserungen in realen Fahrszenarien erzielt werden. Der Beitrag von
LidaRF spiegelt sich hauptsächlich in drei Aspekten wider:
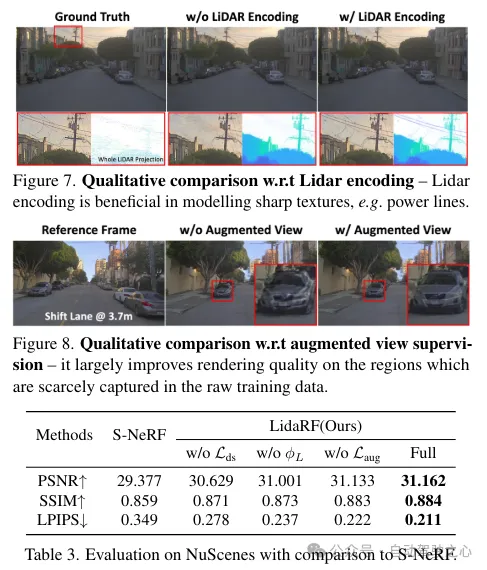
(i) Kombination von Lidar-Kodierung und Rasterfunktionen zur Verbesserung der Szenendarstellung. Während Lidar als natürliche Tiefenüberwachungsquelle verwendet wurde, bietet die Einbindung von Lidar in NeRF-Eingaben großes Potenzial für geometrische Induktion, ist jedoch nicht einfach zu implementieren. Zu diesem Zweck wird eine gitterbasierte Darstellung ausgeliehen, aber aus Punktwolken gelernte Merkmale werden in das Gitter integriert, um die Vorteile expliziter Punktwolkendarstellungen zu übernehmen. Durch die erfolgreiche Einführung des 3D-Wahrnehmungsrahmens werden spärliche 3D-Faltungsnetzwerke als effektive und effiziente Struktur genutzt, um geometrische Merkmale aus dem lokalen und globalen Kontext von Lidar-Punktwolken zu extrahieren.
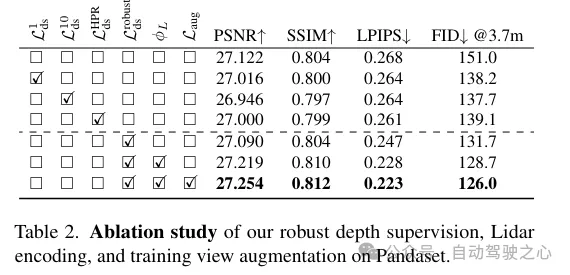
(ii) Robuste okklusionsbewusste Tiefenüberwachung. Ähnlich wie bei bestehenden Arbeiten wird auch hier Lidar als Quelle der Tiefenüberwachung eingesetzt, allerdings in größerer Tiefe. Da die geringe Dichte von LIDAR-Punkten ihre Wirksamkeit einschränkt, insbesondere in Bereichen mit geringer Textur, werden dichtere Tiefenkarten durch die Aggregation von LIDAR-Punkten über benachbarte Frames hinweg generiert. Die so erhaltene Tiefenkarte berücksichtigt jedoch keine Verdeckungen, was zu einer fehlerhaften Tiefenüberwachung führt. Daher wird ein robustes Tiefenüberwachungsschema vorgeschlagen, das sich an der Methode des Klassenlernens orientiert und die Tiefe schrittweise vom Nahfeld zum Fernfeld überwacht und während des NeRF-Trainingsprozesses schrittweise die falsche Tiefe herausfiltert, um die Tiefe effektiver zu extrahieren Tiefe aus dem Lidar lernen.
(iii) LiDAR-basierte Ansichtsverbesserung. Darüber hinaus wird angesichts der spärlichen Sicht und der begrenzten Abdeckung in Fahrszenarien Lidar verwendet, um die Trainingsansichten zu verdichten. Das heißt, die gesammelten LIDAR-Punkte werden in neue Trainingsansichten projiziert. Beachten Sie, dass diese Ansichten etwas von der Fahrbahn abweichen können. Diese aus LIDAR projizierten Ansichten werden dem Trainingsdatensatz hinzugefügt und berücksichtigen keine Okklusionsprobleme. Wir wenden jedoch das zuvor erwähnte Überwachungsschema an, um das Okklusionsproblem zu lösen und so die Leistung zu verbessern. Obwohl unsere Methode auch auf allgemeine Szenen anwendbar ist, konzentrieren wir uns in dieser Arbeit mehr auf die Bewertung von Straßenszenen und erzielen sowohl quantitativ als auch qualitativ deutliche Verbesserungen im Vergleich zu bestehenden Techniken.
LidaRF hat auch bei interessanten Anwendungen, die eine größere Abweichung von der Eingabeansicht erfordern, Vorteile gezeigt und die Qualität von NeRF bei anspruchsvollen Straßenszenenanwendungen erheblich verbessert.
LidaRF ist eine Methode zur Eingabe und Ausgabe entsprechender Dichten und Farben. Sie verwendet UNet, um Huff-Codierung und Lidar-Codierung zu kombinieren. Darüber hinaus werden über Lidar-Projektionen verbesserte Trainingsdaten generiert, um geometrische Vorhersagen mithilfe des vorgeschlagenen robusten Deep-Supervision-Schemas zu trainieren.
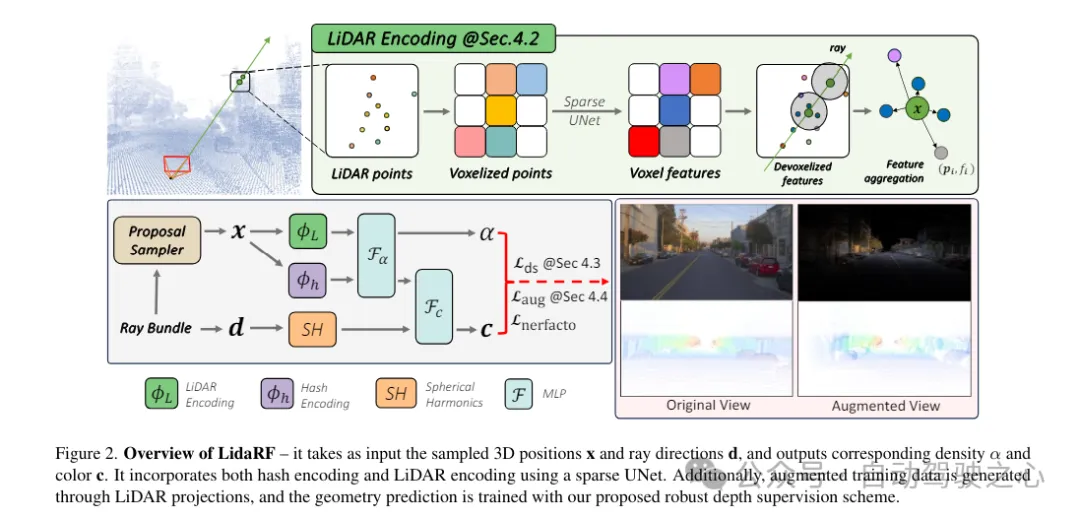
Lidar-Punktwolken haben ein starkes geometrisches Führungspotenzial, was für NeRF (Neural Rendering Field) äußerst wertvoll ist. Wenn man sich bei der Szenendarstellung jedoch ausschließlich auf LIDAR-Funktionen verlässt, führt dies aufgrund der spärlichen Beschaffenheit von LIDAR-Punkten (trotz zeitlicher Akkumulation) zu einer Darstellung mit niedriger Auflösung. Da LIDAR außerdem über ein begrenztes Sichtfeld verfügt und beispielsweise Gebäudeoberflächen ab einer bestimmten Höhe nicht erfassen kann, kommt es in diesen Bereichen zu leeren Renderings. Im Gegensatz dazu verschmilzt unser Framework Lidar-Funktionen und hochauflösende räumliche Rasterfunktionen, um die Vorteile beider zu nutzen und gemeinsam zu lernen, um eine qualitativ hochwertige und vollständige Szenenwiedergabe zu erreichen.
Lidar-Feature-Extraktion. Der Extraktionsprozess für geometrische Merkmale für jeden LIDAR-Punkt wird hier ausführlich beschrieben. In Abbildung 2 werden zunächst die LIDAR-Punktwolken aller Frames der gesamten Sequenz aggregiert, um eine dichtere Punktwolkensammlung zu erstellen. Die Punktwolke wird dann in ein Voxelgitter voxelisiert, wobei die räumlichen Positionen der Punkte innerhalb jeder Voxeleinheit gemittelt werden, um ein 3D-Merkmal für jede Voxeleinheit zu erzeugen. Inspiriert durch den weit verbreiteten Erfolg von 3D-Wahrnehmungsframeworks werden Szenengeometriemerkmale mithilfe von 3D-Sparse-UNet auf einem Voxelgitter codiert, was das Lernen aus dem globalen Kontext der Szenengeometrie ermöglicht. 3D-sparse UNet verwendet ein Voxelgitter und seine dreidimensionalen Merkmale als Eingabe und gibt neuronale volumetrische Merkmale aus. Jedes besetzte Voxel besteht aus n-dimensionalen Merkmalen.
Lidar-Funktionsabfrage. Für jeden Beispielpunkt x entlang des zu rendernden Strahls werden seine LIDAR-Features abgefragt, wenn sich mindestens K nahegelegene LIDAR-Punkte innerhalb des Suchradius R befinden. Andernfalls werden seine LIDAR-Features auf Null (d. h. alle Nullen) gesetzt. Konkret wird die Methode „Fixed Radius Nearest Neighbor“ (FRNN) verwendet, um nach dem K nächstgelegenen LIDAR-Punktindexsatz in Bezug auf x zu suchen, der als bezeichnet wird. Anders als die Methode in [9], bei der die Strahlabtastpunkte vor Beginn des Trainingsprozesses vorbestimmt werden, erfolgt die FRNN-Suche bei unserer Methode in Echtzeit, da die Abtastpunktverteilung aus dem regionalen Netzwerk mit der Konvergenz des NeRF-Trainings dynamisch tendiert Konzentrieren Sie sich auf die Oberfläche. Unsere Methode folgt dem Point-NeRF-Ansatz und verwendet ein mehrschichtiges Perzeptron (MLP) F, um die Lidar-Merkmale jedes Punkts in einer neuronalen Szenenbeschreibung abzubilden. Für den i-ten Nachbarpunkt der inversen Distanzgewichtungsmethode zur Aggregation der neuronalen Szenenbeschreibung seiner K Nachbarpunkte
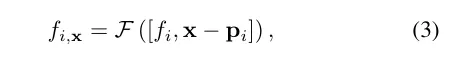
Merkmalsfusion für die Strahlungsdekodierung. Der Lidar-Code ϕL wird mit dem Hash-Code ϕh verkettet und ein mehrschichtiges Perzeptron Fα wird angewendet, um die Dichte α und die Dichteeinbettung h jeder Probe vorherzusagen. Schließlich wird durch ein weiteres mehrschichtiges Perzeptron Fc die entsprechende Farbe c basierend auf der sphärischen harmonischen Kodierung SH und der Dichteeinbettung h in der Betrachtungsrichtung d vorhergesagt.
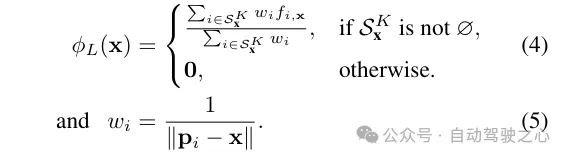
Zusätzlich zur Merkmalskodierung wird Tiefenüberwachung aus LIDAR-Punkten erhalten, indem diese auf die Bildebene projiziert werden. Aufgrund der spärlichen Anzahl an LIDAR-Punkten sind die daraus resultierenden Vorteile jedoch begrenzt und reichen nicht aus, um Bereiche mit geringer Textur wie Straßenbeläge zu rekonstruieren. Hier schlagen wir vor, benachbarte Lidar-Frames zu akkumulieren, um die Dichte zu erhöhen. Obwohl 3D-Punkte in der Lage sind, die Szenenstruktur genau zu erfassen, muss bei der Projektion auf die Bildebene zur Tiefenüberwachung die Verdeckung zwischen Punkten berücksichtigt werden. Verdeckungen resultieren aus einer erhöhten Verschiebung zwischen der Kamera und dem Lidar und seinen angrenzenden Bildern, was zu einer falschen Tiefenüberwachung führt, wie in Abbildung 3 dargestellt. Aufgrund der spärlichen Beschaffenheit von Lidar auch nach der Akkumulation ist die Bewältigung dieses Problems sehr schwierig, sodass grundlegende Grafiktechniken wie Z-Pufferung nicht anwendbar sind. In dieser Arbeit wird ein robustes Überwachungsschema vorgeschlagen, um falsche Tiefenüberwachung beim Training von NeRF automatisch herauszufiltern. 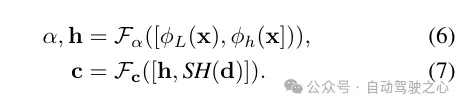
Denken Sie daran, dass aufgrund der Vorwärtsbewegung der Bordkamera die von ihr erzeugten Trainingsbilder spärlich sind und nur über eine begrenzte Sichtfeldabdeckung verfügen, was die NeRF-Rekonstruktion vor Herausforderungen stellt, insbesondere wenn die neuen Ansichten von der Fahrzeugbahn abweichen. Hier schlagen wir vor, LiDAR zu nutzen, um Trainingsdaten zu erweitern. Zuerst färben wir die Punktwolke jedes Lidar-Frames ein, indem wir sie auf die synchronisierte Kamera projizieren und die RGB-Werte interpolieren. Die farbige Punktwolke wird akkumuliert und auf eine Reihe synthetisch verbesserter Ansichten projiziert, wodurch das in Abbildung 2 dargestellte synthetische Bild und die Tiefenkarte entstehen.
 Experimentelle Vergleichsanalyse
Experimentelle Vergleichsanalyse

Das obige ist der detaillierte Inhalt vonLidaRF: Untersuchung von LiDAR-Daten für Street View Neural Radiation Fields (CVPR\'24). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 WLAN Passwort
WLAN Passwort
 So löschen Sie eine Datei unter Linux
So löschen Sie eine Datei unter Linux
 So summieren Sie dreidimensionale Arrays in PHP
So summieren Sie dreidimensionale Arrays in PHP
 Python führt zwei Listen zusammen
Python führt zwei Listen zusammen
 Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
 So lösen Sie das Problem, dass der Scanf-Rückgabewert ignoriert wird
So lösen Sie das Problem, dass der Scanf-Rückgabewert ignoriert wird
 So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie
So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



