



Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Die effiziente und qualitativ hochwertige Rekonstruktion dynamischer dreidimensionaler physikalischer Phänomene wie Rauch ist ein wichtiges Thema in der entsprechenden wissenschaftlichen Forschung. Sie bietet breite Anwendungsaussichten in der aerodynamischen Designüberprüfung, der meteorologischen dreidimensionalen Beobachtung und anderen Bereichen. Durch die gemeinsame Rekonstruktion dreidimensionaler Dichtesequenzen, die sich im Laufe der Zeit ändern, können Wissenschaftler verschiedene komplexe physikalische Phänomene in der realen Welt besser verstehen und überprüfen.

Abbildung 1 zeigt die Bedeutung der Beobachtung dynamischer dreidimensionaler physikalischer Phänomene für die wissenschaftliche Forschung. Das Bild zeigt den weltweit größten Windkanal NFAC, der aerodynamische Experimente an Nutzfahrzeugen durchführt.
Allerdings ist es ziemlich schwierig, in der realen Welt schnell dynamische 3D-Dichtefelder mit hoher Qualität zu erfassen und zu rekonstruieren. Erstens ist es schwierig, dreidimensionale Informationen direkt mit herkömmlichen zweidimensionalen Bildsensoren (z. B. Kameras) zu messen. Darüber hinaus stellen sich mit hoher Geschwindigkeit ändernde dynamische Phänomene hohe Anforderungen an die physikalischen Erfassungsmöglichkeiten: Eine vollständige Abtastung eines einzelnen dreidimensionalen Dichtefeldes muss in sehr kurzer Zeit erfasst werden, da sich sonst das dreidimensionale Dichtefeld selbst ändert. Die grundlegende Herausforderung besteht darin, die Informationslücke zwischen der Messprobe selbst und den Ergebnissen der dynamischen dreidimensionalen Dichtefeldrekonstruktion zu schließen.
Aktuelle Mainstream-Forschungsarbeiten nutzen Vorwissen, um den Mangel an Informationen in Messproben auszugleichen. Der Berechnungsaufwand ist hoch und die Rekonstruktionsqualität ist schlecht, wenn die Vorbedingungen nicht erfüllt sind. Anders als die gängigen Forschungsideen glaubt das Forschungsteam des National Key Laboratory of Computer-Aided Design and Graphics Systems der Zhejiang-Universität, dass der Schlüssel zur Lösung des Problems in der Erhöhung des Informationsgehalts der Einheitsmessstichprobe liegt.
Das Forschungsteam nutzt KI nicht nur zur Optimierung des Rekonstruktionsalgorithmus, sondern nutzt KI auch, um bei der Entwicklung physischer Erfassungsmethoden zu helfen, um eine vollautomatische gemeinsame Optimierung von Software und Hardware zu erreichen, die dasselbe Ziel verfolgt und im Wesentlichen die Menge an Informationen über das Zielobjekt erhöht in der Einheitsmessprobe. Durch die Simulation physikalischer optischer Phänomene in der realen Welt kann künstliche Intelligenz entscheiden, wie strukturiertes Licht projiziert, entsprechende Bilder gesammelt und aus dem Musterbuch ein dynamisches dreidimensionales Dichtefeld rekonstruiert wird. Am Ende verwendete das Forschungsteam nur einen leichten Hardware-Prototyp mit einem einzelnen Projektor und einer kleinen Anzahl von Kameras (1 oder 3), um die Anzahl strukturierter Lichtmuster zu reduzieren und ein einzelnes dreidimensionales Dichtefeld (räumliche Auflösung 128 x 128 x 128) zu modellieren. bis 6, wodurch ein effizienter Erfassungssatz von 40 dreidimensionalen Dichtefeldern pro Sekunde erreicht wird.
Das Team schlug innovativ einen leichten eindimensionalen Decoder im Rekonstruktionsalgorithmus vor, der lokales Eingangslicht als Teil der Decoder-Eingabe und gemeinsame Decoder-Parameter unter verschiedenen, von verschiedenen Kameras erfassten Materialien verwendet, wodurch die Komplexität des Netzwerks erheblich reduziert wird Verbessern Sie die Berechnungsgeschwindigkeit. Um die Dekodierungsergebnisse verschiedener Kameras zu fusionieren, wird ein 3D-U-Net-Fusionsnetzwerk mit einfacher Struktur entworfen. Die endgültige Rekonstruktion eines einzelnen dreidimensionalen Dichtefeldes dauert nur 9,2 Millisekunden. Im Vergleich zur SOTA-Forschungsarbeit wird die Rekonstruktionsgeschwindigkeit um 2-3 Größenordnungen erhöht, wodurch eine hochwertige Rekonstruktion des dreidimensionalen Dichtefeldes in Echtzeit erreicht wird . Das zugehörige Forschungspapier „Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination“ wurde von CVPR 2024, der führenden internationalen akademischen Konferenz im Bereich Computer Vision, angenommen.

Papierlink: https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
Forschungshomepage: https://svbrdf.github.io/publications/realtimedynamic/project. html
Verwandte Arbeiten können in die folgenden zwei Kategorien unterteilt werden, je nachdem, ob die Beleuchtung während des Sammelvorgangs gesteuert wird.
Die erste Art von Arbeit, die auf nicht steuerbarer Beleuchtung basiert, erfordert keine spezielle Lichtquelle und steuert die Beleuchtung während des Sammelvorgangs nicht, daher sind die Anforderungen an die Sammelbedingungen lockerer [2,3]. Da eine Einzelbildkamera eine zweidimensionale Projektion einer dreidimensionalen Struktur erfasst, ist es schwierig, verschiedene dreidimensionale Strukturen mit hoher Qualität zu unterscheiden. In diesem Zusammenhang besteht eine Idee darin, die Anzahl der gesammelten Blickwinkelproben zu erhöhen, beispielsweise durch die Verwendung dichter Kameraarrays oder Lichtfeldkameras, was zu hohen Hardwarekosten führen wird. Eine andere Idee besteht immer noch darin, den Perspektivbereich nur spärlich abzutasten und die Informationslücke durch verschiedene Arten von Vorinformationen zu schließen, wie z. B. heuristische Priors, physikalische Regeln oder aus vorhandenen Daten erlerntes Vorwissen. Sobald die a priori-Bedingungen in der Praxis nicht erfüllt sind, verschlechtert sich die Qualität der Rekonstruktionsergebnisse dieser Art von Verfahren. Darüber hinaus ist der Rechenaufwand zu hoch, um eine Echtzeitrekonstruktion zu unterstützen.
Die zweite Arbeitsart nutzt steuerbare Beleuchtung, um die Lichtverhältnisse während des Sammelvorgangs aktiv zu steuern [4,5]. Solche Arbeiten kodieren die Beleuchtung, um die physische Welt aktiver zu erforschen, und verlassen sich auch weniger auf Priors, was zu einer höheren Rekonstruktionsqualität führt. Abhängig davon, ob eine einzelne Lampe oder mehrere Lampen gleichzeitig verwendet werden, können die damit verbundenen Arbeiten weiter in Scanverfahren und Beleuchtungsmultiplexverfahren unterteilt werden. Bei dynamischen physischen Objekten müssen erstere durch den Einsatz teurer Hardware hohe Scangeschwindigkeiten erreichen oder die Integrität der Ergebnisse opfern, um den Erfassungsaufwand zu reduzieren. Letzteres verbessert die Sammeleffizienz erheblich, indem mehrere Lichtquellen gleichzeitig programmiert werden. Für hochwertige schnelle Echtzeit-Dichtefelder ist die Abtasteffizienz bestehender Methoden jedoch immer noch unzureichend [5].
Die Arbeit des Teams der Zhejiang-Universität gehört zur zweiten Kategorie. Anders als die meisten bestehenden Arbeiten nutzt diese Forschungsarbeit künstliche Intelligenz, um die physikalische Erfassung (d. h. neuronales strukturiertes Licht) und die rechnerische Rekonstruktion gemeinsam zu optimieren und so eine effiziente und qualitativ hochwertige dynamische dreidimensionale Dichtefeldmodellierung zu erreichen.
Hardware-Prototyp
Das Forschungsteam baute einen einzelnen kommerziellen Projektor (BenQ (dargestellt in Abbildung 3). Sechs vortrainierte strukturierte Lichtmuster werden zyklisch durch den Projektor projiziert, drei Kameras nehmen gleichzeitig auf und eine dynamische dreidimensionale Dichtefeldrekonstruktion wird auf der Grundlage der von den Kameras gesammelten Bilder durchgeführt. Die Winkel der vier Geräte relativ zum Sammelobjekt sind die optimalen Anordnungen, die nach Simulationen aus verschiedenen Simulationsexperimenten ausgewählt wurden.
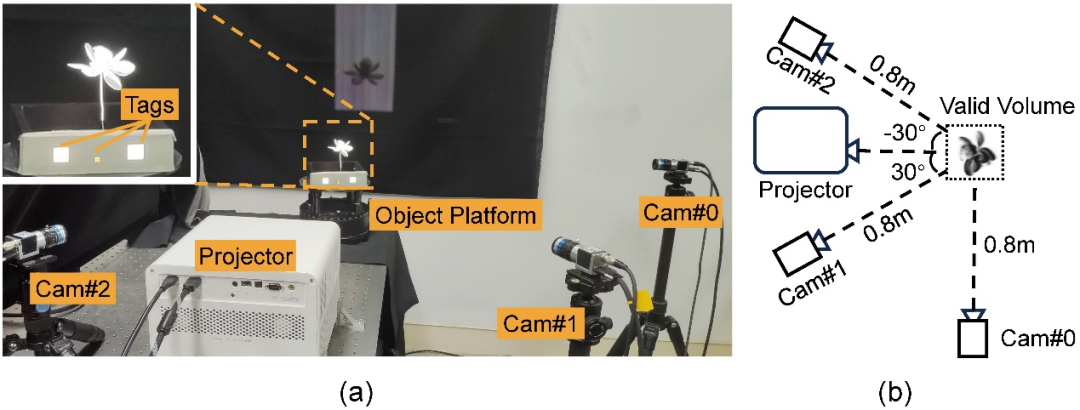
Abbildung 3: Hardware-Prototyp der Sammlung. (a) Echte Aufnahme des Hardware-Prototyps mit drei weißen Tags auf der Bühne, die zur Synchronisierung von Kamera und Projektor verwendet werden. (b) Schematische Darstellung der geometrischen Beziehung zwischen Kamera, Projektor und Motiv (Draufsicht).
Softwareverarbeitung
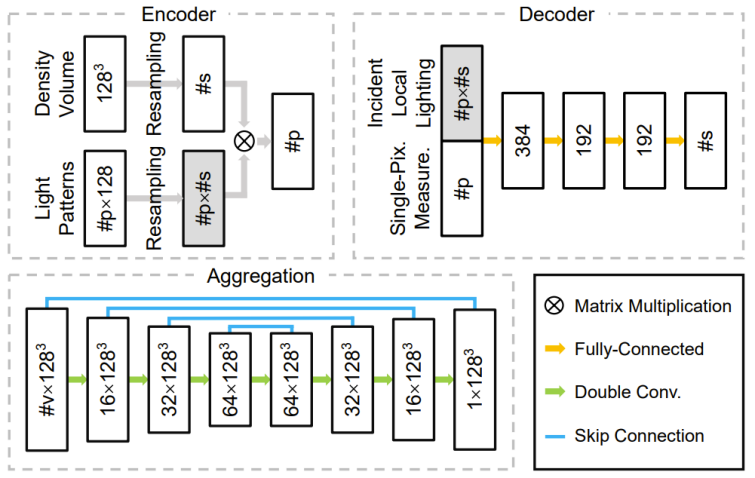
Das Forschungs- und Entwicklungsteam entwirft ein tiefes neuronales Netzwerk, das aus Encodern, Decodern und Aggregationsmodulen besteht. Die Gewichte in seinem Encoder entsprechen direkt der Intensitätsverteilung des strukturierten Lichts während der Erfassung. Der Decoder nimmt eine an einem einzelnen Pixel gemessene Probe als Eingabe, sagt eine eindimensionale Dichteverteilung voraus und interpoliert sie in ein dreidimensionales Dichtefeld. Das Aggregationsmodul kombiniert die mehreren dreidimensionalen Dichtefelder, die vom Decoder für jede Kamera vorhergesagt werden, zum Endergebnis. Durch die Verwendung von trainierbarem strukturiertem Licht und einem leichten eindimensionalen Decoder kann diese Studie die wesentliche Beziehung zwischen strukturierten Lichtmustern, zweidimensionalen Fotos und dreidimensionalen Dichtefeldern leichter erlernen, wodurch eine Überanpassung an die Trainingsdaten weniger wahrscheinlich ist . Abbildung 4 unten zeigt die gesamte Pipeline und Abbildung 5 zeigt die relevante Netzwerkstruktur.

Abbildung 4: Globale Erfassungs- und Rekonstruktionspipeline (a) und die Neuverarbeitung vom strukturierten Lichtmuster zum eindimensionalen lokalen einfallenden Licht (b) und von der vorhergesagten eindimensionalen Dichteverteilung zurück zur dreidimensionalen Dimensionsdichtefeld (c) Probenahmeprozess. Die Studie beginnt mit einem simulierten/realen dreidimensionalen Dichtefeld, auf das zunächst voroptimierte strukturierte Lichtmuster (d. h. Gewichte im Encoder) projiziert werden. Für jedes gültige Pixel in jeder Kameraansicht werden alle seine Messungen und das neu abgetastete lokale einfallende Licht dem Decoder zugeführt, um die eindimensionale Dichteverteilung auf dem entsprechenden Kamerastrahl vorherzusagen. Anschließend werden alle Dichteverteilungen einer Kamera gesammelt und in einem einzigen dreidimensionalen Dichtefeld neu abgetastet. Im Fall mehrerer Kameras führt diese Studie die vorhergesagten Dichtefelder jeder Kamera zusammen, um das Endergebnis zu erhalten. Abbildung 5: Architektur der drei Hauptkomponenten des Netzwerks: Encoder, Decoder und Aggregationsmodul.
 Ergebnisanzeige
Ergebnisanzeige
Abbildung 6 zeigt die teilweisen Rekonstruktionsergebnisse dieser Methode für vier verschiedene dynamische Szenen. Um dynamischen Wassernebel zu erzeugen, fügten die Forscher Flaschen mit flüssigem Wasser Trockeneis hinzu, um Wassernebel zu erzeugen, und steuerten den Fluss durch Ventile und leiteten ihn mithilfe von Gummischläuchen weiter zum Auffanggerät. Abbildung 6: Rekonstruktionsergebnisse verschiedener dynamischer Szenen. Jede Zeile ist das Visualisierungsergebnis eines ausgewählten Teils des rekonstruierten Rahmens in einer bestimmten Wassernebelsequenz. Die Anzahl der Wassernebelquellen in der Szene beträgt von oben nach unten: 1, 1, 3 bzw. 2. Wie in der orangefarbenen Markierung oben links gezeigt, entsprechen A, B und C jeweils den von den drei Eingabekameras gesammelten Bildern, und D ist ein real aufgenommenes Referenzbild, das der Renderperspektive des Rekonstruktionsergebnisses ähnelt. Der Zeitstempel wird in der unteren linken Ecke angezeigt. Detaillierte Ergebnisse der dynamischen Rekonstruktion finden Sie im Papiervideo. Um die Richtigkeit und Qualität dieser Forschung zu überprüfen, verglich das Forschungsteam diese Methode mit verwandten SOTA-Methoden an realen statischen Objekten (wie in Abbildung 7 dargestellt). Abbildung 7 vergleicht auch die Rekonstruktionsqualität unter verschiedenen Kamerazahlen. Alle Rekonstruktionsergebnisse werden unter derselben neuen, nicht erworbenen Perspektive dargestellt und anhand von drei Bewertungsmetriken quantitativ bewertet. Wie aus Abbildung 7 ersichtlich ist, ist die Rekonstruktionsqualität dieser Methode dank der Optimierung der Erfassungseffizienz besser als die der SOTA-Methode. Abbildung 7: Vergleich verschiedener Techniken an realen statischen Objekten. Von links nach rechts ist die optische Schichtschneidemethode [4], diese Methode (drei Kameras), diese Methode (Doppelkamera), diese Methode (einzelne Kamera), die Verwendung manuell entworfenen strukturierten Lichts unter einer einzelnen Kamera [5], SOTAs PINF Visualisierung der Rekonstruktionsergebnisse der Methoden [3] und GlobalTrans [2]. Wenn wir die Ergebnisse der optischen Schnitte als Maßstab nehmen und für alle anderen Ergebnisse deren quantitative Fehler in der unteren rechten Ecke der entsprechenden Bilder aufgelistet sind, bewertet mit drei Metriken SSIM/PSNR/RMSE (×0,01). Alle rekonstruierten Dichtefelder werden unter Verwendung von Nicht-Eingabeansichten gerendert, #v stellt die Anzahl der erfassten Ansichten dar und #p stellt die Anzahl der verwendeten strukturierten Lichtmuster dar. Das Forschungsteam verglich außerdem quantitativ die Rekonstruktionsqualität verschiedener Methoden anhand dynamischer Simulationsdaten. Abbildung 8 zeigt den Vergleich der Rekonstruktionsqualität simulierter Rauchsequenzen. Detaillierte Einzelbild-Rekonstruktionsergebnisse finden Sie im Papiervideo. Abbildung 8: Vergleich verschiedener Methoden an simulierten Rauchsequenzen. Von links nach rechts sind die tatsächlichen Werte, Rekonstruktionsergebnisse dieser Methode, PINF [3] und GlobalTrans [2] aufgeführt. Die Rendering-Ergebnisse der Eingabeansicht und der neuen Ansicht werden in der ersten bzw. zweiten Zeile angezeigt. Der quantitative Fehler SSIM/PSNR/RMSE (×0,01) wird in der unteren rechten Ecke des entsprechenden Bildes angezeigt. Den durchschnittlichen Fehler der gesamten rekonstruierten Sequenz entnehmen Sie bitte dem Zusatzmaterial der Arbeit. Darüber hinaus finden Sie im Papiervideo die Ergebnisse der dynamischen Rekonstruktion der gesamten Sequenz. Zukunftsausblick Das Forschungsteam plant, diese Methode auf fortschrittlichere Aufnahmegeräte (wie Lichtfeldprojektoren [6]) anzuwenden, um eine dynamische Aufnahmerekonstruktion durchzuführen. Das Team hofft außerdem, die Anzahl der für die Erfassung erforderlichen strukturierten Lichtmuster und Kameras durch die Erfassung umfangreicherer optischer Informationen (z. B. Polarisationszustand) weiter zu reduzieren. Darüber hinaus ist die Kombination dieser Methode mit neuronalen Ausdrücken (wie NeRF) auch eine der zukünftigen Entwicklungsrichtungen, an denen das Team interessiert ist. Schließlich könnte die Möglichkeit, dass die KI aktiver an der Gestaltung der physischen Erfassung und der rechnerischen Rekonstruktion beteiligt wird und sich nicht nur auf Nachbearbeitungssoftware beschränkt, neue Ideen für die weitere Verbesserung der physischen Wahrnehmungsfähigkeiten liefern und letztendlich eine effiziente und qualitativ hochwertige Modellierung verschiedener Modelle ermöglichen komplexe physikalische Phänomene. Referenzen: [1]. Im größten Windkanal der Welt https://youtu.be/ubyxYHFv2qw?si=KK994cXtARP3Atwn [2]. Taler , und Nils Thuerey. In CVPR, Seiten 1632–1642, 2021. [3]. Theobalt und Rhaleb Zayer. Physics informierte neuronale Felder für die Rauchrekonstruktion mit spärlichen Daten, 41 (4):1–14, 2022 Paul Debevec. Erfassung zeitveränderlicher teilnehmender Medien, 24 (3):812–815, 2005. [5]. . Belhumeur und Ravi Ramamoorthi. Komprimierendes strukturiertes Licht zur Wiederherstellung inhomogener teilnehmender Medien. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 (3): 1–1, 2013. Lin, Haoyang Zhou, Chong Zeng, Yaxin Yu, Kun Zhou und Hongzhi Wu. Ein einheitliches räumlich-winkeliges strukturiertes Licht zur Einzelansichtserfassung von Form und Reflexion, Seiten 206–215, 2023.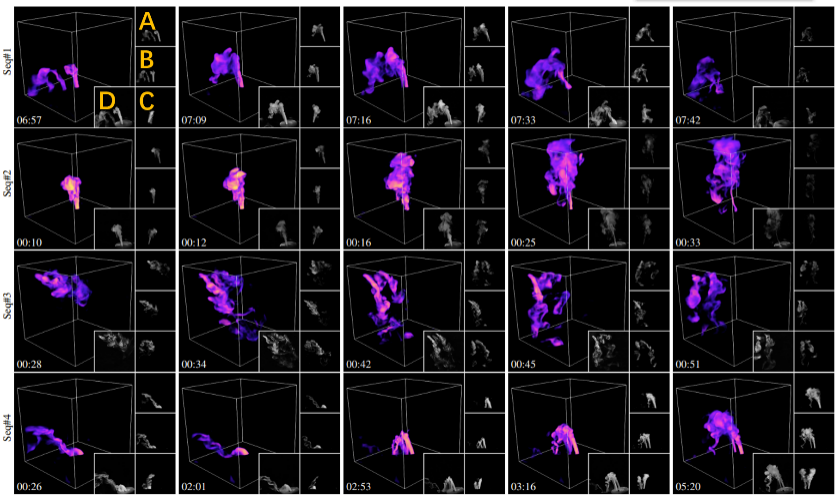


Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Mit Hilfe von neuronalem strukturiertem Licht gelingt der Zhejiang-Universität die Echtzeiterfassung und -rekonstruktion dynamischer dreidimensionaler Phänomene. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 U-Münzenpreis heute
U-Münzenpreis heute
 So schreiben Sie ein Batch-Skript bat
So schreiben Sie ein Batch-Skript bat
 Einführung in das xmpp-Protokoll
Einführung in das xmpp-Protokoll








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



