


Wenn KI mathematische Probleme löst, ist das eigentliche Denken tatsächlich heimlich „Kopfrechnen“?
Neue Untersuchungen des Teams der New York University haben ergeben, dass die Leistung der KI bei einigen komplexen Aufgaben erheblich verbessert werden kann, selbst wenn sie keine Schritte schreiben darf und durch bedeutungsloses „…“ ersetzt wird!
Der Erstautor Jacab Pfau sagte: Solange Sie Rechenleistung aufwenden, um zusätzliche Token zu generieren, können Sie Vorteile bringen. Es spielt keine Rolle, welchen Token Sie wählen.
 Bilder
Bilder
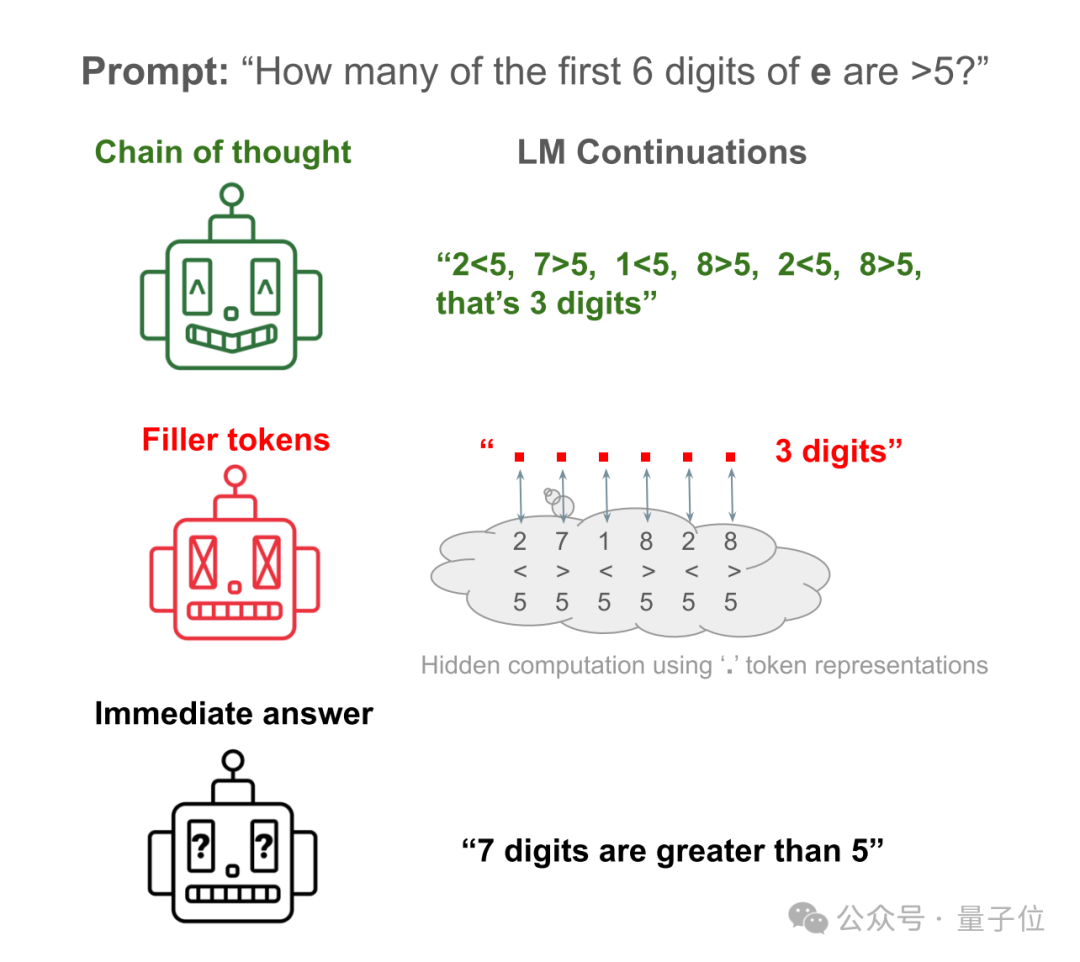
Lassen Sie Lama 34M zum Beispiel eine einfache Frage beantworten: Wie viele der ersten 6 Ziffern der Naturkonstanten e sind größer als 5?
Die direkte Antwort der KI ist fast so, als würde sie ein Chaos anrichten. Sie zählt nur die ersten 6 Ziffern und tatsächlich 7.
Lassen Sie die KI die Schritte zur Überprüfung jeder Zahl aufschreiben, und Sie erhalten die richtige Antwort.
Lassen Sie die KI die Schritte ausblenden und durch viele „…“ ersetzen, und Sie erhalten immer noch die richtige Antwort!
 Bilder
Bilder
Dieses Papier löste gleich nach seiner Veröffentlichung viele Diskussionen aus und wurde als „das metaphysischste KI-Papier, das ich je gesehen habe“ bewertet.
 Bilder
Bilder
Junge Leute sagen also gerne bedeutungslosere Wörter wie „ähm…“, „wie…“, kann das auch ihre Denkfähigkeit stärken?
 Bilder
Bilder
Tatsächlich begann die Forschung des Teams der New York University mit der Chain-of-Thought (CoT).
Das ist die berühmte Aufforderung „Lass uns Schritt für Schritt denken“.
 Bilder
Bilder
In der Vergangenheit wurde festgestellt, dass die Verwendung von CoT-Inferenz die Leistung großer Modelle bei verschiedenen Benchmarks erheblich verbessern kann.
Unklar ist, ob diese Leistungsverbesserung darauf zurückzuführen ist, dass Menschen nachgeahmt werden, um Aufgaben in einfacher zu lösende Schritte zu unterteilen, oder ob sie ein Nebenprodukt zusätzlicher Berechnungen ist.
Um dieses Problem zu verifizieren, hat das Team zwei spezielle Aufgaben und entsprechende synthetische Datensätze entworfen: 3SUM und 2SUM-Transformation.
3SUM erfordert das Finden von drei Zahlen aus einer bestimmten Menge von Zahlenfolgen, sodass die Summe dieser drei Zahlen bestimmte Bedingungen erfüllt, z. B. Division durch 10 und Belassen eines Rests von 0.
 Bild
Bild
Die Rechenkomplexität dieser Aufgabe beträgt O (n3), und der Standardtransformator kann nur eine quadratische Abhängigkeit zwischen der Eingabe der oberen Schicht und der Aktivierung der nächsten Schicht erzeugen.
Das heißt, wenn n groß genug und die Sequenz lang genug ist, übersteigt die 3SUM-Aufgabe die Ausdrucksfähigkeit von Transformer.
Im Trainingsdatensatz wird zwischen den Fragen und Antworten „…“ mit der gleichen Länge wie menschliche Denkschritte eingefügt. Das heißt, die KI hat nicht gesehen, wie Menschen das Problem während des Trainings zerlegen.
 Bilder
Bilder
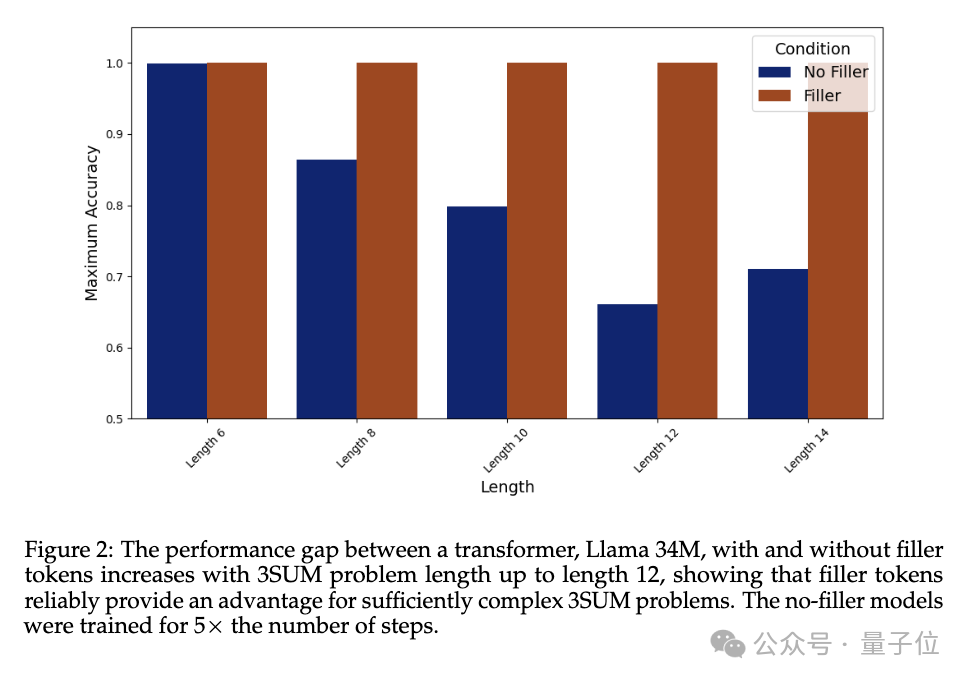
Im Experiment nimmt die Leistung von Llama 34M, das das Fülltoken „…“ nicht ausgibt, mit zunehmender Sequenzlänge ab, aber wenn das Fülltoken ausgegeben wird, bis die Länge 14, 100 beträgt % Genauigkeit kann garantiert werden.
 Pictures
Pictures
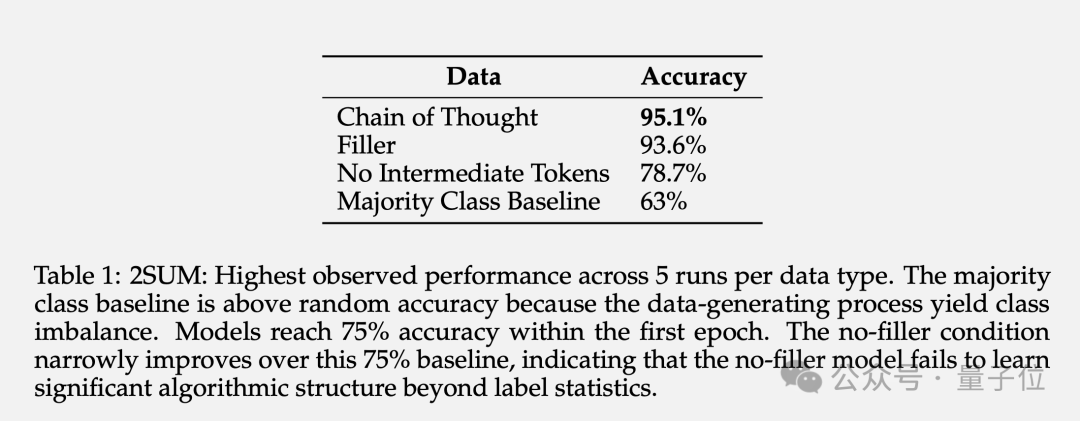
2SUM-Transform muss lediglich bestimmen, ob die Summe zweier Zahlen die Anforderungen erfüllt, was innerhalb der Ausdrucksfähigkeiten von Transformer liegt.
Am Ende der Frage wird jedoch ein Schritt hinzugefügt: „Permutieren Sie jede Zahl der Eingabesequenz zufällig“, um zu verhindern, dass das Modell direkt auf dem Eingabetoken berechnet.
Die Ergebnisse zeigen, dass der Einsatz von Padding-Tokens die Genauigkeit von 78,7 % auf 93,6 % steigern kann.
 Bilder
Bilder
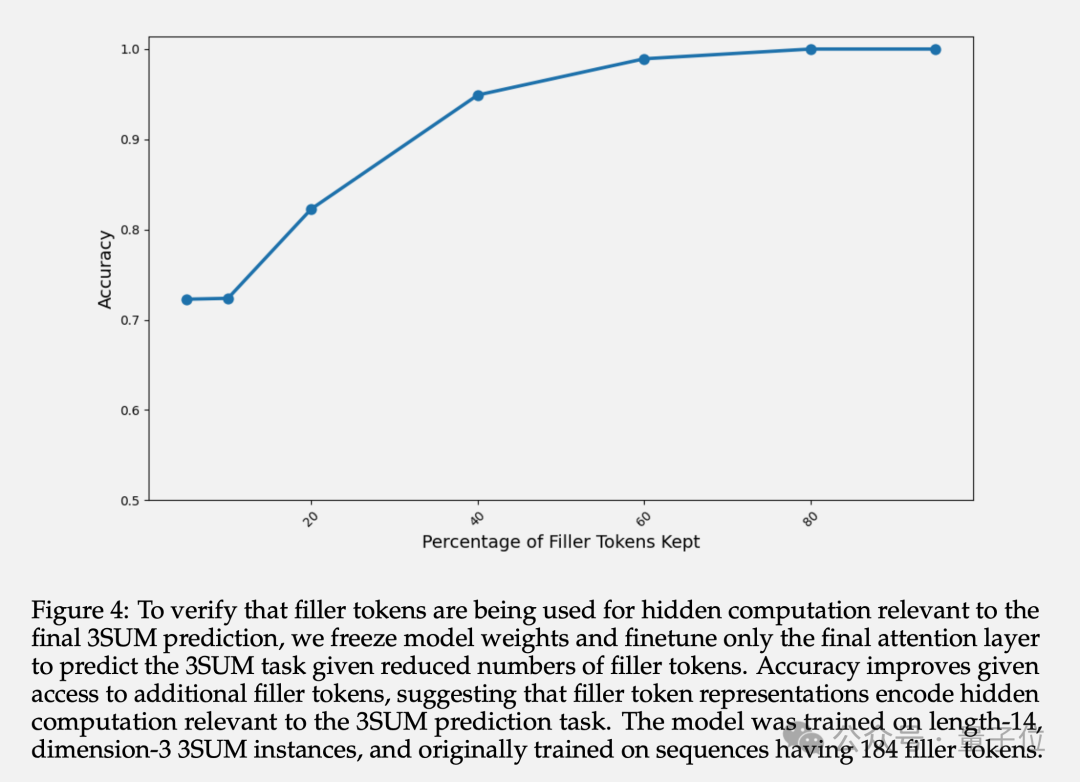
Zusätzlich zur endgültigen Genauigkeit untersuchte der Autor auch die Darstellung der verborgenen Schicht gefüllter Token. Experimente zeigen, dass durch das Einfrieren der Parameter der vorherigen Schichten und die Feinabstimmung nur der letzten Aufmerksamkeitsschicht die Vorhersagegenauigkeit mit zunehmender Anzahl verfügbarer Fülltoken zunimmt.
Dies bestätigt, dass die Darstellung der verborgenen Ebene des bestückten Tokens implizite Berechnungen im Zusammenhang mit nachgelagerten Aufgaben enthält.
 Bilder
Bilder
Einige Internetnutzer bezweifeln, dass in diesem Papier behauptet wird, dass die „Denkketten“-Methode tatsächlich eine Fälschung ist? Das Prompt-Word-Projekt, das ich so lange studiert habe, war vergebens.
 Bild
Bild
Das Team gab an, dass die Rolle des Füllens von Token theoretisch auf den Umfang von TC0-Komplexitätsproblemen beschränkt ist.
TC0 ist ein Rechenproblem, das durch eine Schaltung mit fester Tiefe gelöst werden kann. Jede Schicht der Schaltung kann parallel verarbeitet werden und kann durch einige Schichten von Logikgattern (z. B. UND-, ODER- und NICHT-Gatter) schnell gelöst werden. Es ist auch die Aufgabe des Transformers, die Obergrenze der Rechenkomplexität allein bei dieser Vorwärtsausbreitung zu bewältigen.
Und eine ausreichend lange Denkkette kann die Ausdrucksfähigkeit von Transformer über TC0 hinaus erweitern.
Und es ist für große Modelle nicht einfach, den Umgang mit Fülltokens zu erlernen, und es bedarf einer besonderen intensiven Betreuung, um sich anzunähern.
Allerdings ist es unwahrscheinlich, dass bestehende große Modelle direkt von der Padding-Token-Methode profitieren.
Dies ist jedoch keine inhärente Einschränkung aktueller Architekturen. Sie sollten in der Lage sein, ähnliche Vorteile durch das Auffüllen von Symbolen zu erzielen, wenn in den Trainingsdaten genügend Demonstrationen vorhanden sind.
Diese Forschung wirft auch ein besorgniserregendes Problem auf: Große Modelle können geheime Berechnungen durchführen, die nicht überwacht werden können, was die Erklärbarkeit und Kontrollierbarkeit der KI vor neue Herausforderungen stellt.
Mit anderen Worten: KI kann selbstständig in einer für Menschen unsichtbaren Form argumentieren, ohne sich auf menschliche Erfahrung zu verlassen.
Es ist aufregend und beängstigend zugleich.
 Bilder
Bilder
Schließlich schlugen einige Internetnutzer scherzhaft vor, dass Lama 3 zunächst 1 Billiarde Punkte erzeugen sollte, damit das Gewicht von AGI (Hundekopf) ermittelt werden kann.
 Bilder
Bilder
Papier: //m.sbmmt.com/link/36157dc9be261fec78aeee1a94158c26
Referenzlink:
[1]//m.sbmmt.com/link/e3 50113047 e82ceecb455c33c21ef32a [ 2]//m.sbmmt.com/link/872de53a900f3250ae5649ea19e5c381
Das obige ist der detaillierte Inhalt vonKI lernt, ihr Denken und ihre Vernunft heimlich zu verbergen! Komplexe Aufgaben zu lösen, ohne sich auf menschliche Erfahrung zu verlassen, ist eher eine Blackbox. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Proxy-Switchysharp
Proxy-Switchysharp
 Was ist die Tastenkombination für die Pinselgröße?
Was ist die Tastenkombination für die Pinselgröße?
 So beheben Sie einen Skriptfehler
So beheben Sie einen Skriptfehler
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Wie man mit Blockchain Geld verdient
Wie man mit Blockchain Geld verdient
 Detaillierter Prozess zum Upgrade des Win7-Systems auf das Win10-System
Detaillierter Prozess zum Upgrade des Win7-Systems auf das Win10-System
 Der Unterschied zwischen Windows-Ruhezustand und Ruhezustand
Der Unterschied zwischen Windows-Ruhezustand und Ruhezustand
 Können Programmdateien gelöscht werden?
Können Programmdateien gelöscht werden?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



