


Vor kurzem hat das Diffusionsmodell erhebliche Fortschritte im Bereich der Bildgenerierung gemacht und beispiellose Entwicklungsmöglichkeiten für Bildgenerierungs- und Videogenerierungsaufgaben eröffnet. Trotz der beeindruckenden Ergebnisse führen die mehrstufigen iterativen Entrauschungseigenschaften, die dem Inferenzprozess von Diffusionsmodellen innewohnen, zu hohen Rechenkosten. Kürzlich wurde eine Reihe von Diffusionsmodell-Destillationsalgorithmen entwickelt, um den Inferenzprozess von Diffusionsmodellen zu beschleunigen. Diese Methoden lassen sich grob in zwei Kategorien einteilen: i) bahnerhaltende Destillation; ii) bahnenerhaltende Destillation. Diese beiden Arten von Methoden werden jedoch durch die begrenzte Effektobergrenze oder Änderungen im Ausgabebereich eingeschränkt.
Um diese Probleme zu lösen, schlug das technische Team von ByteDance ein Konsistenzmodell für die Trajektoriensegmentierung namens Hyper-SD vor. Die Open Source von Hyper-SD wurde auch von Clem Delangue, CEO von Huggingface, gewürdigt.
Bei diesem Modell handelt es sich um ein neuartiges Diffusionsmodell-Destillationsframework, das die Vorteile der Trajektorien-erhaltenden Destillation und der Trajektorien-Rekonstruktionsdestillation kombiniert, um die Anzahl der Entrauschungsschritte zu komprimieren und gleichzeitig eine nahezu verlustfreie Leistung aufrechtzuerhalten. Im Vergleich zu bestehenden Diffusionsmodell-Beschleunigungsalgorithmen erzielt diese Methode hervorragende Beschleunigungsergebnisse. Nach umfangreichen Experimenten und Benutzerbewertungen kann Hyper-SD+ sowohl auf SDXL- als auch auf SD1.5-Architekturen eine Bildgenerierungsleistung auf SOTA-Niveau in 1 bis 8 Schritten erreichen.

Projekthomepage: https://hyper-sd.github.io/
Papierlink: https://arxiv.org/abs/2404.13686
Huggingface-Link: https:/ // /huggingface.co/ByteDance/Hyper-SD
Demo-Link zur Einzelschrittgenerierung: https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
Echtzeitzeichnen Board-Demo-Link: https://huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble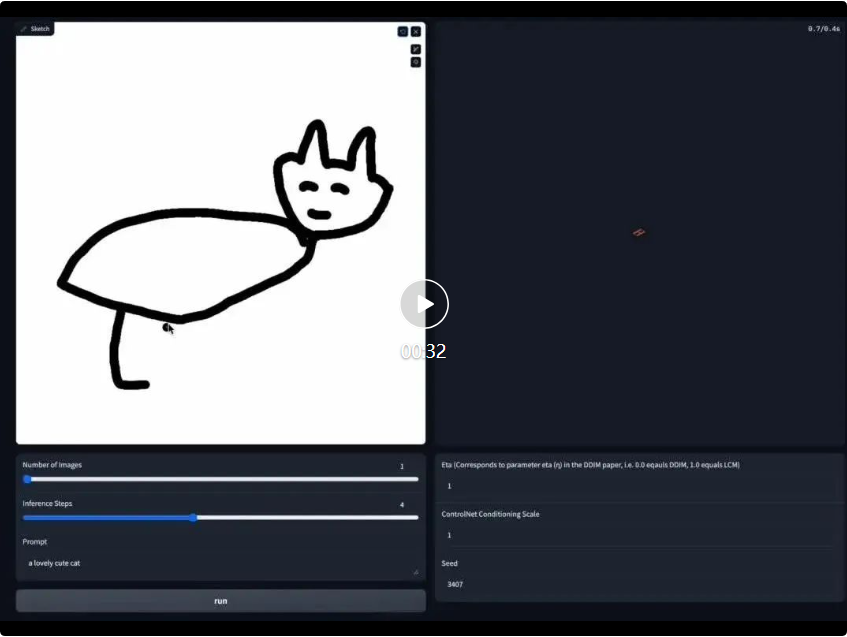
Bestehende Destillationsmethoden zur Diffusionsmodellbeschleunigung können grob in zwei Kategorien unterteilt werden: Flugbahnerhaltende Destillation und Flugbahnrekonstruktionsdestillation. Die bahnerhaltende Destillationstechnik zielt darauf ab, die ursprüngliche Bahn der gewöhnlichen Differentialgleichung (ODE) entsprechend der Diffusion beizubehalten. Das Prinzip besteht darin, Inferenzschritte zu reduzieren, indem das destillierte Modell und das Originalmodell gezwungen werden, ähnliche Ergebnisse zu erzeugen. Es ist jedoch zu beachten, dass zwar eine Beschleunigung erreicht werden kann, solche Methoden jedoch aufgrund der begrenzten Modellkapazität und unvermeidlicher Fehler beim Training und Anpassen zu einer Verschlechterung der Generierungsqualität führen können. Im Gegensatz dazu verwenden Trajektorienrekonstruktionsmethoden direkt die Endpunkte auf der Trajektorie oder reale Bilder als Hauptquelle der Überwachung und ignorieren die Zwischenschritte der Trajektorie. Sie können die Anzahl der Inferenzschritte reduzieren, indem sie effektivere Trajektorien rekonstruieren und diese innerhalb einer begrenzten Zeitspanne durchführen Erkunden Sie innerhalb von Schritten das Potenzial Ihres Modells und befreien Sie es von den Einschränkungen der ursprünglichen Flugbahn. Dies führt jedoch häufig dazu, dass der Ausgabebereich des beschleunigten Modells nicht mit dem Originalmodell übereinstimmt, was zu suboptimalen Ergebnissen führt.
In diesem Artikel wird ein Trajektoriensegmentierungskonsistenzmodell (kurz Hyper-SD) vorgeschlagen, das die Vorteile von Trajektorienerhaltungs- und Rekonstruktionsstrategien kombiniert. Konkret führt der Algorithmus zunächst die Konsistenzdestillation der Trajektoriensegmentierung ein, um die Konsistenz innerhalb jedes Segments zu erzwingen, und reduziert schrittweise die Anzahl der Segmente, um eine Vollzeitkonsistenz zu erreichen. Diese Strategie löst das Problem der suboptimalen Leistung konsistenter Modelle aufgrund unzureichender Modellanpassungsfähigkeiten und der Anhäufung von Inferenzfehlern. Anschließend verwendet der Algorithmus menschliches Feedback-Lernen (RLHF), um den Modellgenerierungseffekt zu verbessern, um den Verlust des Modellgenerierungseffekts während des Beschleunigungsprozesses auszugleichen und ihn besser an Low-Step-Argumentation anzupassen. Schließlich verwendet der Algorithmus eine fraktionierte Destillation, um die Leistung der einstufigen Erzeugung zu verbessern, und erreicht durch einheitliches LORA ein idealisiertes, konsistentes Vollzeitschritt-Diffusionsmodell, wodurch hervorragende Ergebnisse bei den Erzeugungseffekten erzielt werden.
Methode
1. Trajektoriensegmentierung, Konsistenzdestillation
Consistent Distillation (CD) [24] und Consistent Trajectory Model (CTM) [4] zielen beide darauf ab, das Diffusionsmodell durch One-Shot-Destillation in ein konsistentes Modell für den gesamten Zeitschrittbereich [0, T] umzuwandeln. Diese Destillationsmodelle erreichen jedoch häufig nicht die optimale Leistung, da die Möglichkeiten zur Modellanpassung eingeschränkt sind. Inspiriert durch das in CTM eingeführte Ziel der weichen Konsistenz verfeinern wir den Trainingsprozess, indem wir den gesamten Zeitschrittbereich [0, T] in k Segmente unterteilen und Schritt für Schritt eine stückweise konsistente Modelldestillation durchführen.
In der ersten Stufe setzen wir k=8 und verwenden das ursprüngliche Diffusionsmodell, um 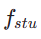 und
und 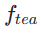 zu initialisieren. Der Startzeitschritt
zu initialisieren. Der Startzeitschritt 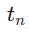 wird einheitlich zufällig aus
wird einheitlich zufällig aus  ausgewählt. Dann proben wir den Endzeitschritt
ausgewählt. Dann proben wir den Endzeitschritt 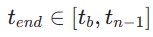 , wobei
, wobei 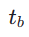 wie folgt berechnet wird:
wie folgt berechnet wird:
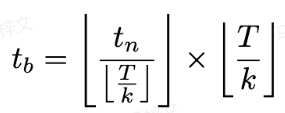
Der Trainingsverlust wird wie folgt berechnet:
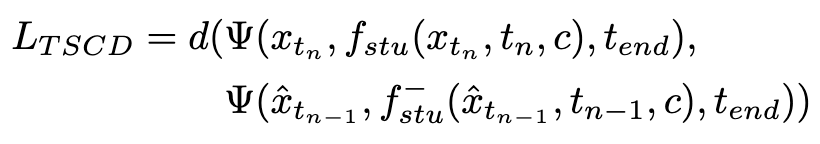
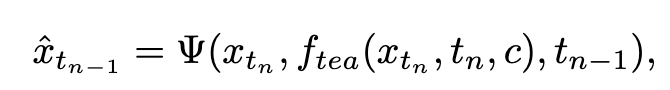
wobei 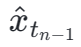 durch Gleichung 3 berechnet wird und
durch Gleichung 3 berechnet wird und 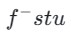 die Exponentialfunktion darstellt gleitender Durchschnitt des Studentenmodells (EMA).
die Exponentialfunktion darstellt gleitender Durchschnitt des Studentenmodells (EMA).
Anschließend stellen wir die Modellgewichte aus der vorherigen Stufe wieder her und trainieren weiter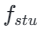 , wobei wir k schrittweise auf [4,2,1] reduzieren. Es ist erwähnenswert, dass k=1 dem Standard-CTM-Trainingsschema entspricht. Für die Distanzmetrik d verwenden wir eine Mischung aus kontradiktorischem Verlust und mittlerem quadratischem Fehler (MSE). In Experimenten haben wir beobachtet, dass der MSE-Verlust effektiver ist, wenn der vorhergesagte Wert und der Zielwert nahe beieinander liegen (z. B. für k = 8, 4), während der gegnerische Verlust mit zunehmender Differenz zwischen dem vorhergesagten Wert und dem Zielwert zunimmt . wird präziser (zum Beispiel für k=2, 1). Daher erhöhen wir während der gesamten Trainingsphase dynamisch das Gewicht des gegnerischen Verlusts und verringern das Gewicht des MSE-Verlusts. Darüber hinaus integrieren wir einen Geräuschstörungsmechanismus, um die Trainingsstabilität zu verbessern. Nehmen Sie als Beispiel den zweistufigen Trajectory Segment Consensus Distillation (TSCD)-Prozess. Wie in der Abbildung unten gezeigt, führt unsere erste Stufe eine unabhängige Konsistenzdestillation in den Zeiträumen
, wobei wir k schrittweise auf [4,2,1] reduzieren. Es ist erwähnenswert, dass k=1 dem Standard-CTM-Trainingsschema entspricht. Für die Distanzmetrik d verwenden wir eine Mischung aus kontradiktorischem Verlust und mittlerem quadratischem Fehler (MSE). In Experimenten haben wir beobachtet, dass der MSE-Verlust effektiver ist, wenn der vorhergesagte Wert und der Zielwert nahe beieinander liegen (z. B. für k = 8, 4), während der gegnerische Verlust mit zunehmender Differenz zwischen dem vorhergesagten Wert und dem Zielwert zunimmt . wird präziser (zum Beispiel für k=2, 1). Daher erhöhen wir während der gesamten Trainingsphase dynamisch das Gewicht des gegnerischen Verlusts und verringern das Gewicht des MSE-Verlusts. Darüber hinaus integrieren wir einen Geräuschstörungsmechanismus, um die Trainingsstabilität zu verbessern. Nehmen Sie als Beispiel den zweistufigen Trajectory Segment Consensus Distillation (TSCD)-Prozess. Wie in der Abbildung unten gezeigt, führt unsere erste Stufe eine unabhängige Konsistenzdestillation in den Zeiträumen 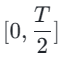 und
und 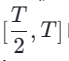 durch und führt dann eine globale Konsistenzverlaufsdestillation basierend auf den Ergebnissen der Konsistenzdestillation der beiden vorherigen Perioden durch.
durch und führt dann eine globale Konsistenzverlaufsdestillation basierend auf den Ergebnissen der Konsistenzdestillation der beiden vorherigen Perioden durch.
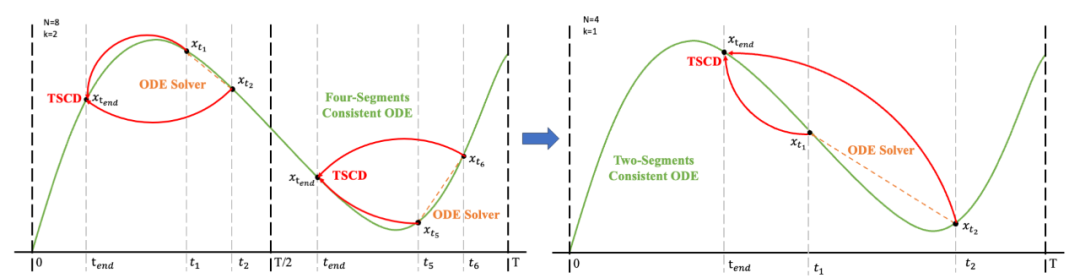
Der vollständige Algorithmusprozess ist wie folgt:

2. Menschliches Feedback-Lernen
Zusätzlich zur Destillation kombinieren wir Feedback-Lernen, um die Leistung des beschleunigten Diffusionsmodells zu verbessern. Insbesondere verbessern wir die Generierungsqualität beschleunigter Modelle, indem wir das Feedback menschlicher ästhetischer Vorlieben und bestehender visueller Wahrnehmungsmodelle nutzen. Für ästhetisches Feedback nutzen wir den LAION-Ästhetikprädiktor und das in ImageReward bereitgestellte Belohnungsmodell für ästhetische Präferenzen, um das Modell bei der Generierung ästhetischerer Bilder anzuleiten, wie unten gezeigt:
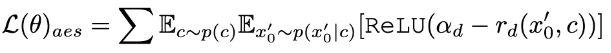
wobei 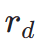 das ästhetische Belohnungsmodell ist, einschließlich des ästhetischen Prädiktors des LAION-Datensatzes und des ImageReward-Modells, c die Textaufforderung ist und
das ästhetische Belohnungsmodell ist, einschließlich des ästhetischen Prädiktors des LAION-Datensatzes und des ImageReward-Modells, c die Textaufforderung ist und 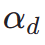 zusammen mit der ReLU-Funktion als Scharnierverlust verwendet wird. Zusätzlich zum Feedback aus ästhetischen Präferenzen stellen wir fest, dass auch bestehende visuelle Wahrnehmungsmodelle, die umfangreiches Vorwissen über Bilder einbetten, als gute Feedbackgeber dienen können. Empirisch stellen wir fest, dass Instanzsegmentierungsmodelle das Modell dabei unterstützen können, gut strukturierte Objekte zu generieren. Konkret diffundieren wir zunächst das Rauschen auf dem Bild
zusammen mit der ReLU-Funktion als Scharnierverlust verwendet wird. Zusätzlich zum Feedback aus ästhetischen Präferenzen stellen wir fest, dass auch bestehende visuelle Wahrnehmungsmodelle, die umfangreiches Vorwissen über Bilder einbetten, als gute Feedbackgeber dienen können. Empirisch stellen wir fest, dass Instanzsegmentierungsmodelle das Modell dabei unterstützen können, gut strukturierte Objekte zu generieren. Konkret diffundieren wir zunächst das Rauschen auf dem Bild 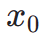 bis
bis 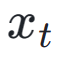 im latenten Raum. Anschließend führen wir, ähnlich wie bei ImageReward, eine iterative Rauschunterdrückung bis zu einem bestimmten Zeitschritt
im latenten Raum. Anschließend führen wir, ähnlich wie bei ImageReward, eine iterative Rauschunterdrückung bis zu einem bestimmten Zeitschritt 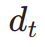 durch und sagen direkt voraus
durch und sagen direkt voraus 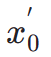 . Anschließend nutzen wir das perzeptive Instanzsegmentierungsmodell, um die Leistung der Strukturgenerierung zu bewerten, indem wir den Unterschied zwischen Instanzsegmentierungsanmerkungen für reale Bilder und Instanzsegmentierungsvorhersagen für entrauschte Bilder wie folgt untersuchen:
. Anschließend nutzen wir das perzeptive Instanzsegmentierungsmodell, um die Leistung der Strukturgenerierung zu bewerten, indem wir den Unterschied zwischen Instanzsegmentierungsanmerkungen für reale Bilder und Instanzsegmentierungsvorhersagen für entrauschte Bilder wie folgt untersuchen:
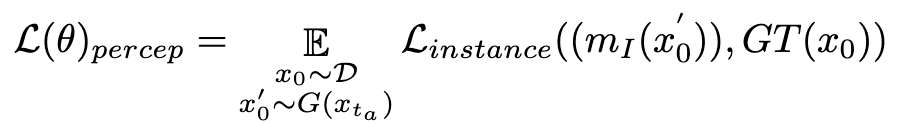
wobei 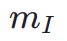 das Instanzsegmentierungsmodell ist (z. B. SOLO). Instanzsegmentierungsmodelle können die strukturellen Mängel generierter Bilder genauer erfassen und gezieltere Rückmeldungssignale liefern. Es ist erwähnenswert, dass neben Instanzsegmentierungsmodellen auch andere Wahrnehmungsmodelle anwendbar sind. Diese Wahrnehmungsmodelle können als ergänzendes Feedback zur subjektiven Ästhetik dienen und sich stärker auf die objektive generative Qualität konzentrieren. Daher kann unser optimiertes Diffusionsmodell mit Rückkopplungssignalen wie folgt definiert werden:
das Instanzsegmentierungsmodell ist (z. B. SOLO). Instanzsegmentierungsmodelle können die strukturellen Mängel generierter Bilder genauer erfassen und gezieltere Rückmeldungssignale liefern. Es ist erwähnenswert, dass neben Instanzsegmentierungsmodellen auch andere Wahrnehmungsmodelle anwendbar sind. Diese Wahrnehmungsmodelle können als ergänzendes Feedback zur subjektiven Ästhetik dienen und sich stärker auf die objektive generative Qualität konzentrieren. Daher kann unser optimiertes Diffusionsmodell mit Rückkopplungssignalen wie folgt definiert werden:
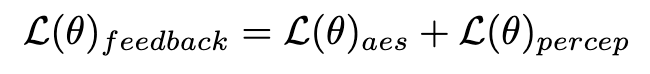
3. Verbesserung der einstufigen Generierung
Aufgrund der inhärenten Einschränkungen des Konsistenzverlusts ist eine einstufige Generierung innerhalb des Konsistenzmodellrahmens nicht möglich Ideal. Wie in CM analysiert, zeigt das konsistente Destillationsmodell eine hervorragende Genauigkeit bei der Führung des Trajektorienendpunkts  an der Position
an der Position  . Daher ist die fraktionierte Destillation eine geeignete und effektive Methode, um den einstufigen Erzeugungseffekt unseres TSCD-Modells weiter zu verbessern. Insbesondere treiben wir die weitere Erzeugung durch eine optimierte DMD-Technik (Distribution Matching Destillation) voran. DMD verbessert die Ausgabe des Modells, indem es zwei verschiedene Bewertungsfunktionen nutzt: die Verteilung
. Daher ist die fraktionierte Destillation eine geeignete und effektive Methode, um den einstufigen Erzeugungseffekt unseres TSCD-Modells weiter zu verbessern. Insbesondere treiben wir die weitere Erzeugung durch eine optimierte DMD-Technik (Distribution Matching Destillation) voran. DMD verbessert die Ausgabe des Modells, indem es zwei verschiedene Bewertungsfunktionen nutzt: die Verteilung 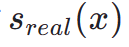 aus dem Lehrermodell und die
aus dem Lehrermodell und die 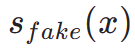 aus dem Fake-Modell. Wir kombinieren den Verlust des mittleren quadratischen Fehlers (MSE) mit einer punktebasierten Destillation, um die Trainingsstabilität zu verbessern. In diesem Prozess werden auch die oben genannten menschlichen Feedback-Lerntechniken integriert, um unser Modell so zu optimieren, dass Bilder mit hoher Wiedergabetreue effektiv generiert werden.
aus dem Fake-Modell. Wir kombinieren den Verlust des mittleren quadratischen Fehlers (MSE) mit einer punktebasierten Destillation, um die Trainingsstabilität zu verbessern. In diesem Prozess werden auch die oben genannten menschlichen Feedback-Lerntechniken integriert, um unser Modell so zu optimieren, dass Bilder mit hoher Wiedergabetreue effektiv generiert werden.
Durch die Integration dieser Strategien erzielt unsere Methode nicht nur hervorragende Low-Step-Inferenzergebnisse sowohl für SD1.5 als auch für SDXL (und erfordert keine Klassifikatorführung), sondern erreicht auch ein ideales globales Konsistenzmodell, ohne dass für jede eine bestimmte Zahl erforderlich ist Die Anzahl der Schritte wird verwendet, um UNet oder LoRA zu trainieren, um ein einheitliches Low-Step-Argumentationsmodell zu erreichen.
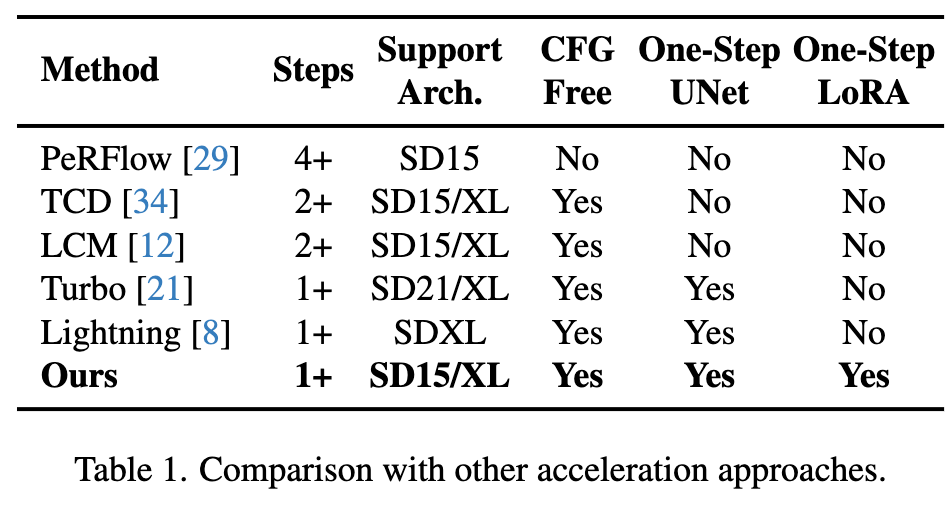
Experimente
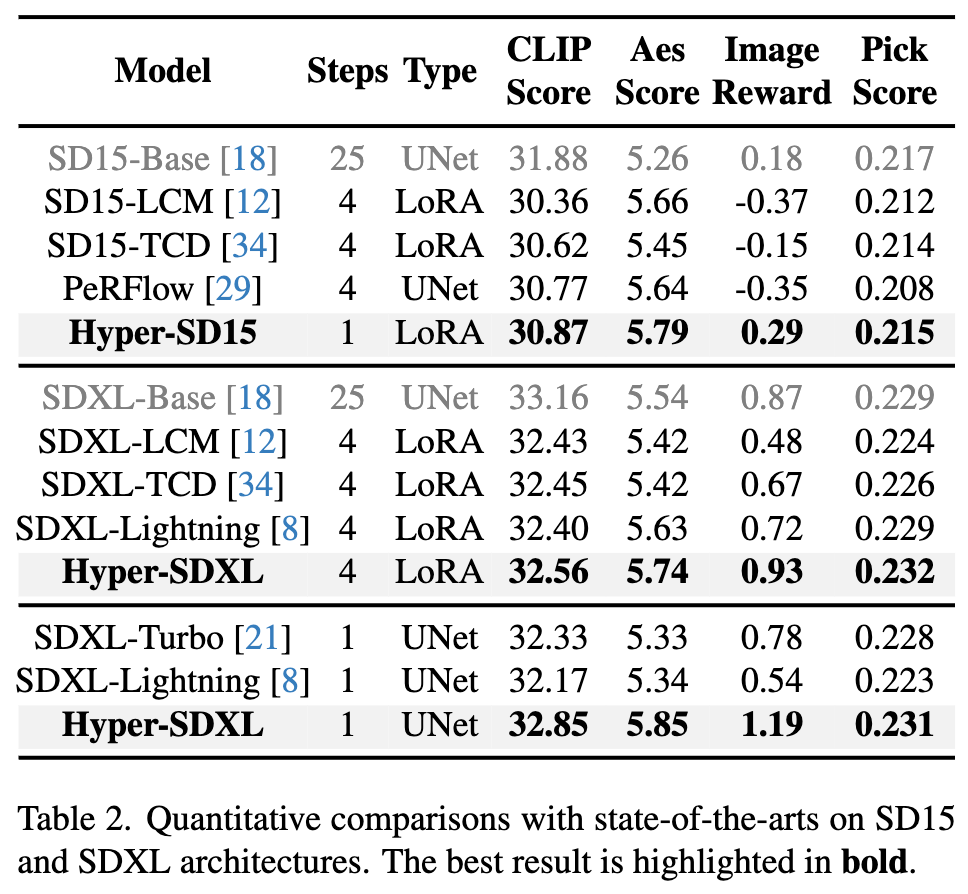
Quantitativer Vergleich verschiedener bestehender Beschleunigungsalgorithmen auf SD1.5 und SDXL zeigt, dass Hyper-SD deutlich besser ist als die aktuellen State-of-the-Art-Methoden
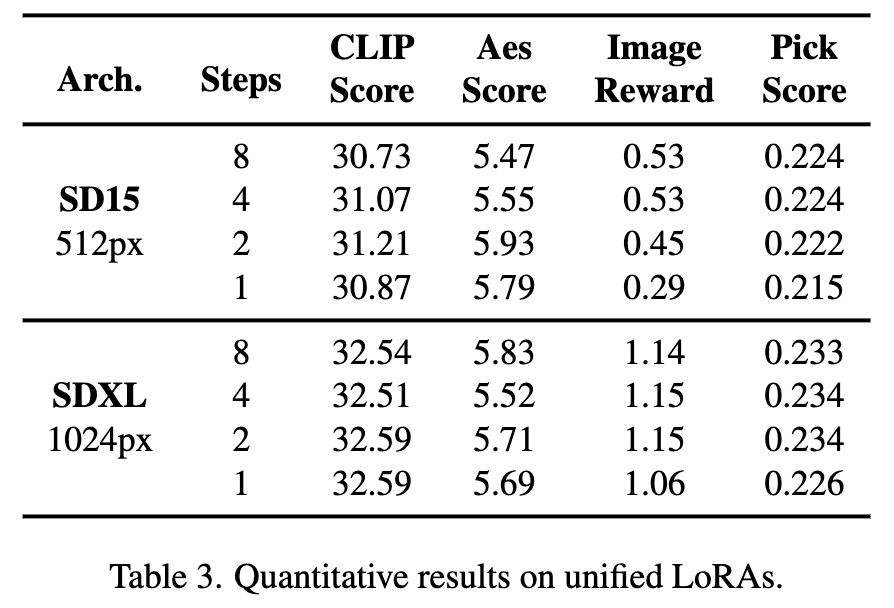
Darüber hinaus kann Hyper-SD ein Modell verwenden, um verschiedene Low-Step-Schlussfolgerungen zu erzielen. Die oben genannten quantitativen Indikatoren zeigen auch die Wirkung unserer Methode, wenn ein einheitliches Modell für die Schlussfolgerung verwendet wird.


Die Visualisierung des Beschleunigungseffekts auf SD1.5 und SDXL zeigt intuitiv die Überlegenheit von Hyper-SD bei der Beschleunigung der Diffusionsmodellinferenz.
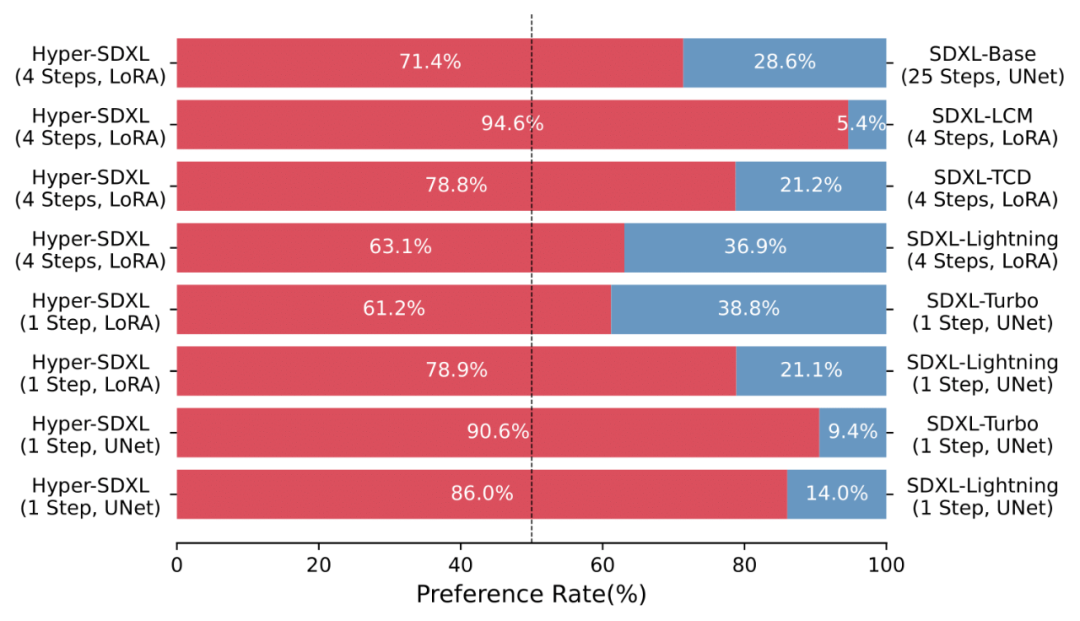
Eine Vielzahl von Anwenderstudien zeigt auch die Überlegenheit von Hyper-SD gegenüber verschiedenen bestehenden Beschleunigungsalgorithmen.

Das von Hyper-SD trainierte beschleunigte LoRA ist gut kompatibel mit verschiedenen Stilen von Vincent-Figurenbasismodellen.
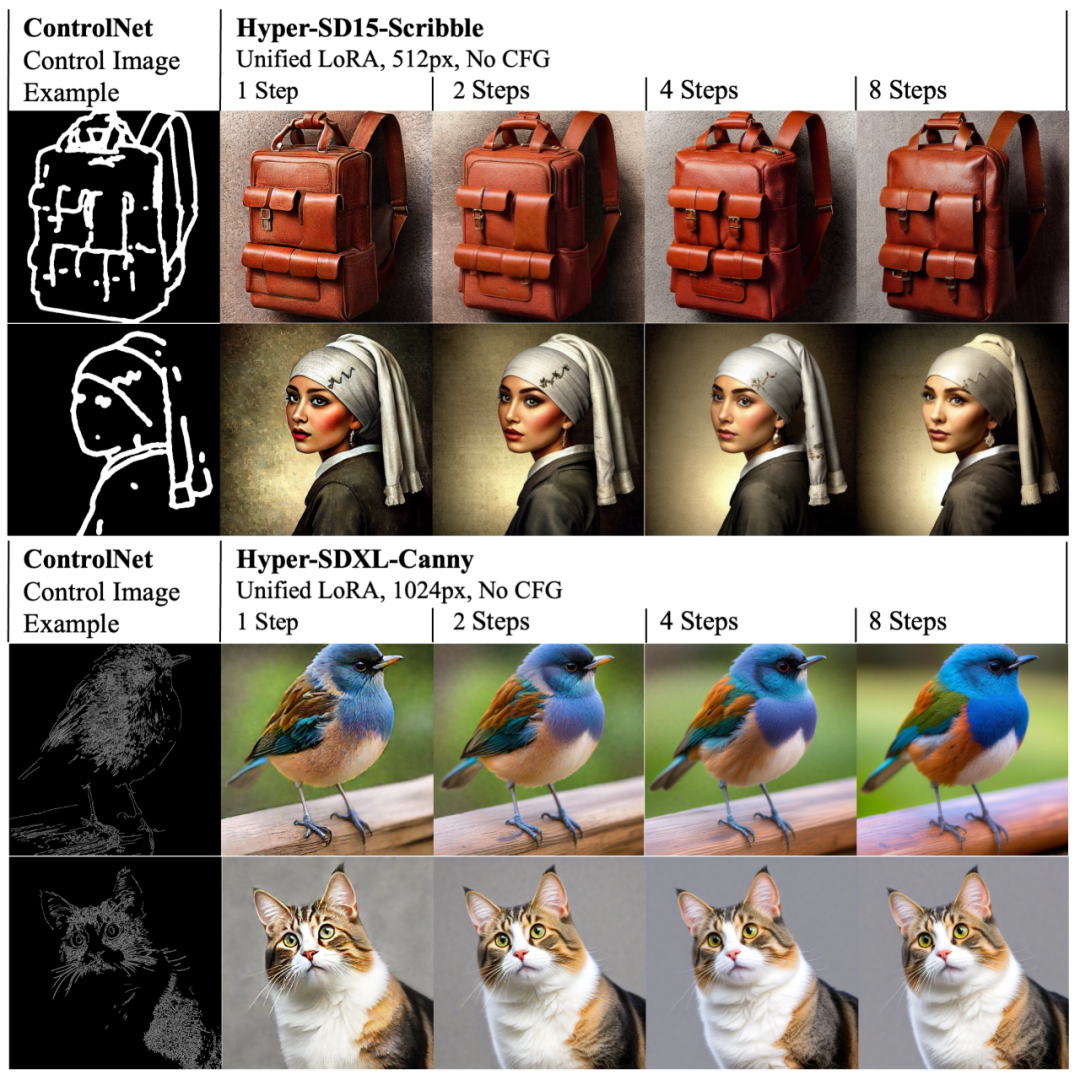
Gleichzeitig kann sich LoRA von Hyper-SD auch an das bestehende ControlNet anpassen, um eine qualitativ hochwertige, steuerbare Bilderzeugung mit einer geringen Anzahl von Schritten zu erreichen.
Zusammenfassung
Das Papier schlägt Hyper-SD vor, ein einheitliches Framework zur Beschleunigung von Diffusionsmodellen, das die Generierungsfähigkeit von Diffusionsmodellen in Low-Step-Situationen erheblich verbessern und eine neue SOTA-Leistung basierend auf SDXL und SD15 erreichen kann. Diese Methode nutzt die Trajektoriensegmentierungskonsistenzdestillation, um die Fähigkeit zur Trajektorienkonservierung während des Destillationsprozesses zu verbessern und einen Erzeugungseffekt zu erzielen, der dem ursprünglichen Modell nahe kommt. Anschließend wird das Potenzial des Modells bei extrem niedrigen Schrittzahlen durch die weitere Nutzung des menschlichen Feedback-Lernens und der Variationsfraktionellestillation verbessert, was zu einer optimierteren und effizienteren Modellgenerierung führt. Das Papier stellte auch das Lora-Plug-in für SDXL und SD15 mit 1- bis 8-stufiger Inferenz sowie ein spezielles einstufiges SDXL-Modell als Open-Source-Lösung zur Verfügung, um die Entwicklung der generativen KI-Community weiter voranzutreiben.
Das obige ist der detaillierte Inhalt vonBeschleunigen Sie das Diffusionsmodell und generieren Sie Bilder auf SOTA-Ebene im schnellsten Schritt. Byte Hyper-SD ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Historisches Bitcoin-Preisdiagramm
Historisches Bitcoin-Preisdiagramm
 Prinzip der bidirektionalen Datenbindung
Prinzip der bidirektionalen Datenbindung
 Einführung in die Bedeutung von Javascript
Einführung in die Bedeutung von Javascript








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



