


Wenn die Testfragen zu einfach sind, können sowohl Spitzenschüler als auch schlechte Schüler 90 Punkte erreichen, und es wird keine Lücke geben...
Mit der Veröffentlichung stärkerer Modelle wie Claude 3, Llama 3 und noch später GPT- 5, die Industrie braucht dringend ein schwierigeres Modell, differenziertere Benchmark-Tests.
LMSYS, die Organisation hinter der großen Model-Arena, hat den Benchmark Arena-Hard der nächsten Generation auf den Markt gebracht, der große Aufmerksamkeit erregte.
Die neueste Referenz ist auch für die Stärke der beiden in der Anleitung optimierten Versionen von Llama 3 verfügbar.
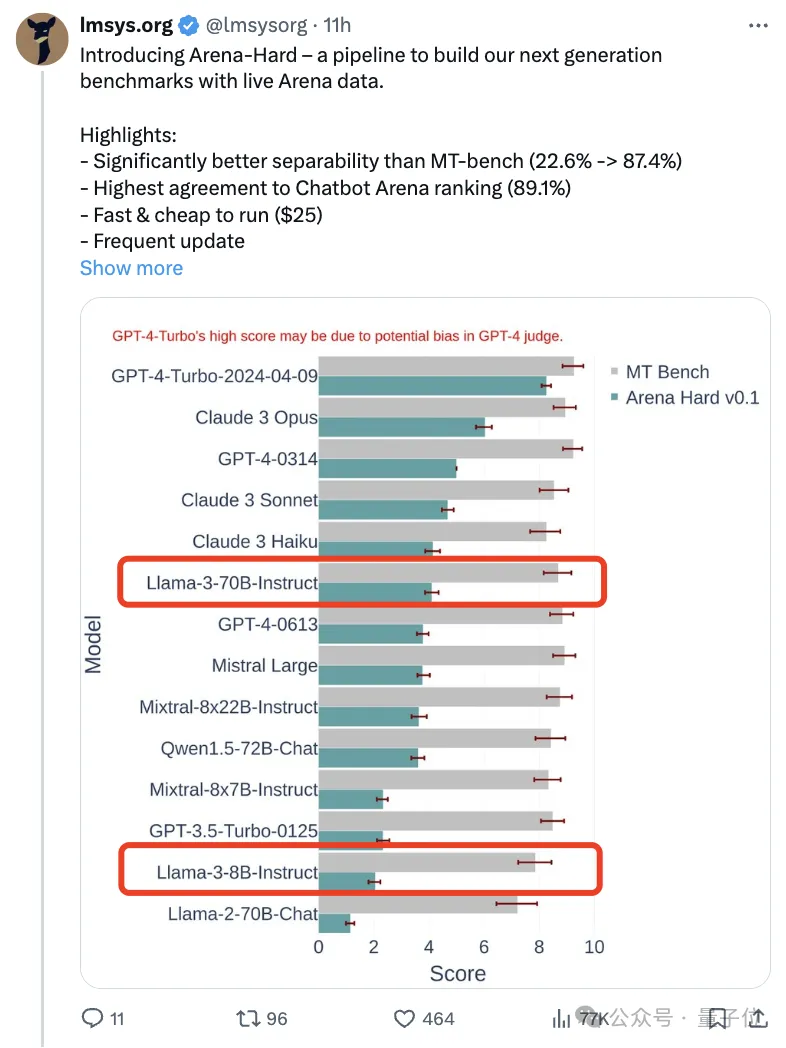
Verglichen mit der vorherigen MT-Bench, die ähnliche Ergebnisse erzielte, stieg die Arena-Hard-Diskriminierung von 22,6 % auf 87,4 %, was auf den ersten Blick klar ist.
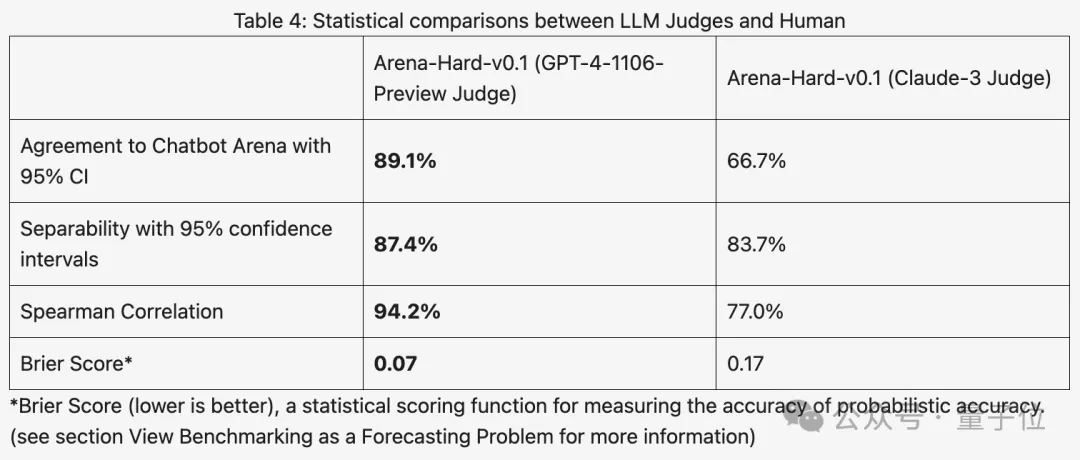
Arena-Hard basiert auf menschlichen Echtzeitdaten aus der Arena und die Übereinstimmungsrate mit menschlichen Vorlieben liegt bei bis zu 89,1 %.
Zusätzlich zu den beiden oben genannten Indikatoren, die SOTA erreichen, gibt es einen zusätzlichen Vorteil:
Die in Echtzeit aktualisierten Testdaten enthalten Aufforderungswörter, die von Menschen neu erfunden und von der KI während der Trainingsphase noch nie gesehen wurden, wodurch potenzielle Daten nachgeben .
Nach der Veröffentlichung eines neuen Modells müssen Sie nicht mehr etwa eine Woche warten, bis menschliche Benutzer abstimmen. Geben Sie einfach 25 US-Dollar aus, um die Testpipeline schnell auszuführen und die Ergebnisse zu erhalten.
Einige Internetnutzer bemerkten, dass es wirklich wichtig sei, für Tests echte Benutzeraufforderungswörter anstelle von High-School-Prüfungen zu verwenden.

Vereinfacht ausgedrückt werden aus 200.000 Benutzeranfragen im großen Modellbereich 500 hochwertige Aufforderungswörter als Testsatz ausgewählt.
Stellen Sie zunächst sicher, dass der Auswahlprozess vielfältig ist, d. h. das Testset sollte ein breites Spektrum realer Themen abdecken.
Um dies sicherzustellen, übernimmt das Team die Themenmodellierungspipeline in BERTopic und konvertiert zunächst jeden Tipp mithilfe des Einbettungsmodells von OpenAI (text-embedding-3-small), reduziert die Dimensionalität mithilfe von UMAP und gruppiert mithilfe eines hierarchiebasierten Modellalgorithmus ( HDBSCAN), um Cluster zu identifizieren und schließlich GPT-4-turbo für die Aggregation zu verwenden.
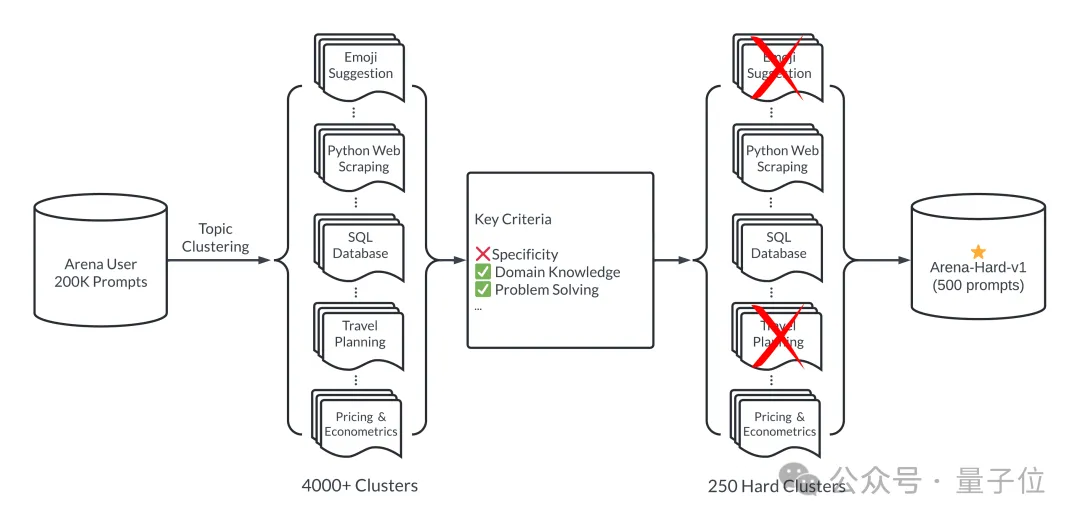
Stellen Sie außerdem sicher, dass die ausgewählten Aufforderungswörter von hoher Qualität sind, was anhand von sieben Schlüsselindikatoren gemessen wird:

Verwenden Sie GPT-3.5-Turbo und GPT-4-Turbo, um jeden Tipp von 0 bis 7 zu kommentieren, um zu bestimmen, wie viele Bedingungen erfüllt sind. Jeder Cluster wird dann basierend auf der durchschnittlichen Punktzahl der Hinweise bewertet.
Hochwertige Fragen beziehen sich in der Regel auf herausfordernde Themen oder Aufgaben, wie z. B. Spieleentwicklung oder mathematische Beweise.
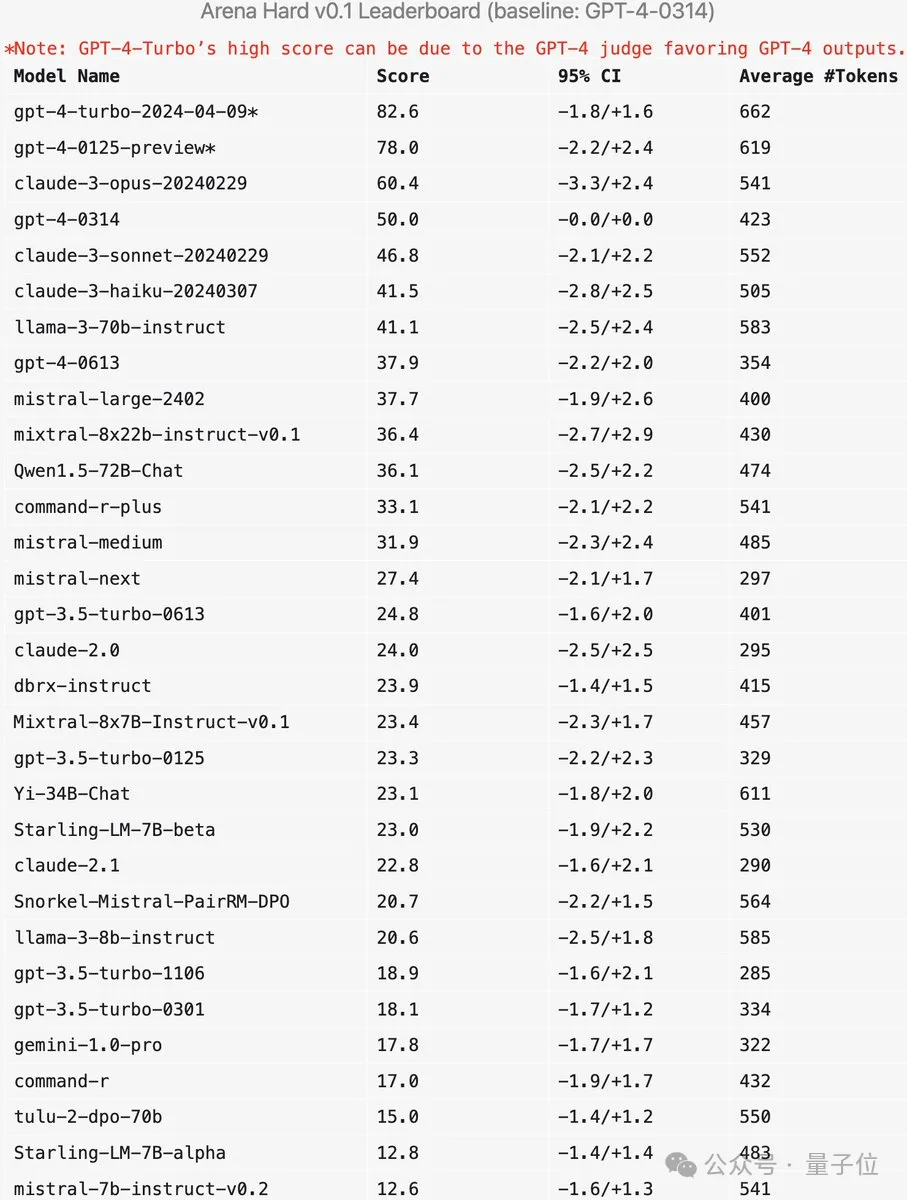
Arena-Hard hat derzeit eine Schwäche: Die Verwendung von GPT-4 als Schiedsrichter bevorzugt die eigene Ausgabe. Beamte gaben auch entsprechende Hinweise.
Es ist ersichtlich, dass die Ergebnisse der letzten beiden Versionen von GPT-4 viel höher sind als die von Claude 3 Opus, aber der Unterschied bei den menschlichen Abstimmungsergebnissen ist nicht so offensichtlich.
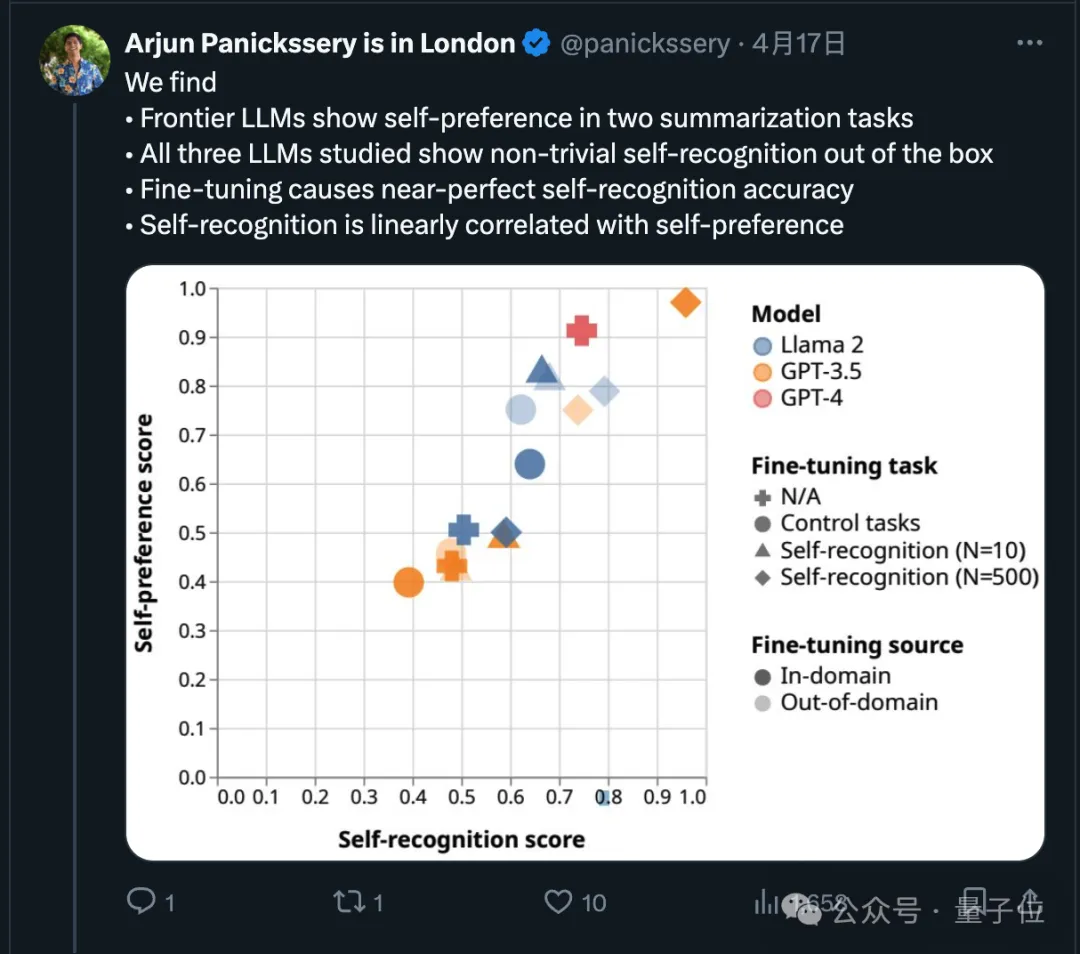
Tatsächlich haben aktuelle Untersuchungen in diesem Punkt gezeigt, dass Spitzenmodelle ihre eigene Ausgabe bevorzugen.

Das Forschungsteam fand außerdem heraus, dass KI von Natur aus feststellen kann, ob ein Text von selbst geschrieben wurde. Nach der Feinabstimmung kann die Selbsterkennungsfähigkeit verbessert werden, und die Selbsterkennungsfähigkeit hängt linear mit der Selbsterkennung zusammen. Präferenz.
Wie wird sich die Verwendung von Claude 3 zur Wertung auf die Ergebnisse auswirken? LMSYS hat auch entsprechende Experimente durchgeführt.
Zuallererst werden die Punktzahlen der Claude-Reihe tatsächlich steigen.
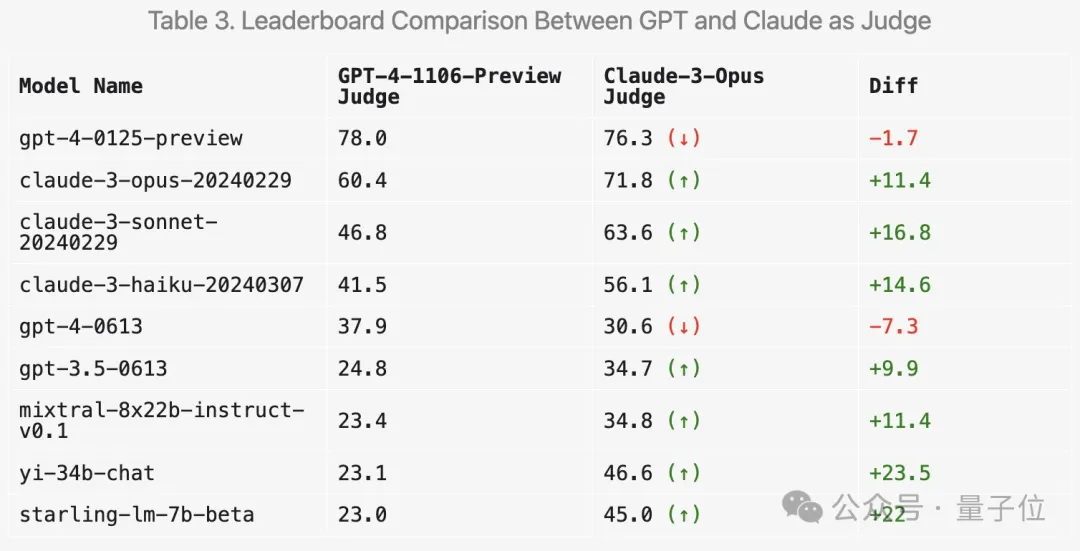
Aber überraschenderweise bevorzugt es mehrere offene Modelle wie Mixtral und Zero One Thousand Yi und schneidet bei GPT-3.5 sogar deutlich besser ab.
Insgesamt sind die Unterscheidungsfähigkeit und die Konsistenz mit menschlichen Ergebnissen, die mit Claude 3 erzielt wurden, nicht so gut wie mit GPT-4.
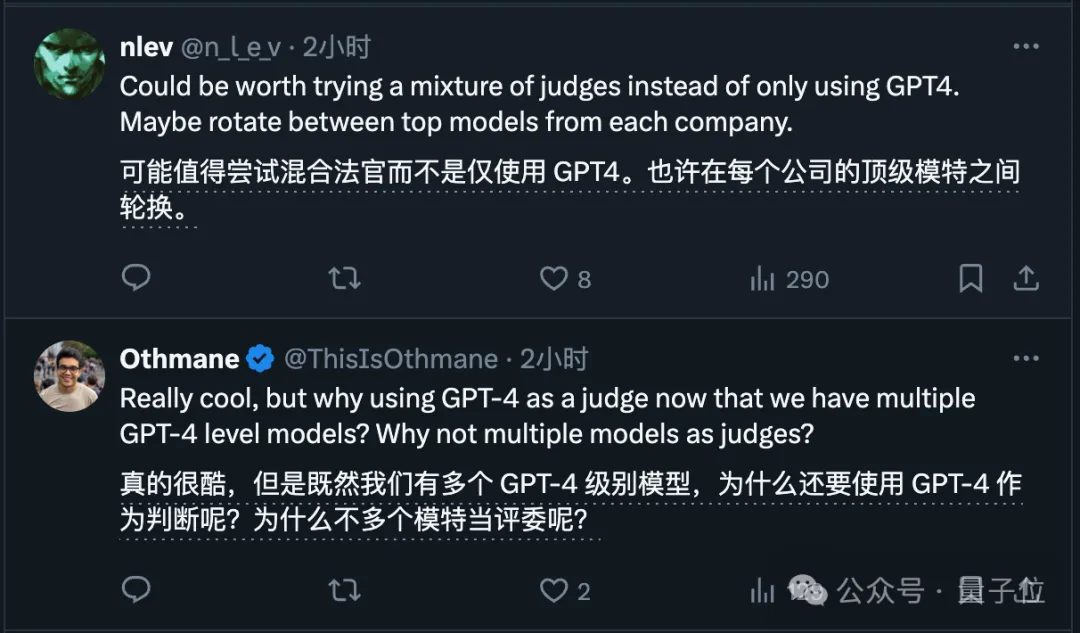
So viele Internetnutzer schlugen vor, mehrere große Modelle für eine umfassende Bewertung zu verwenden.
Darüber hinaus führte das Team weitere Ablationsexperimente durch, um die Wirksamkeit des neuen Benchmark-Tests zu überprüfen.
Wenn Sie beispielsweise „Machen Sie die Antwort so detailliert wie möglich“ zum Aufforderungswort hinzufügen, ist die durchschnittliche Ausgabelänge höher und die Punktzahl verbessert sich tatsächlich.
Durch die Änderung des Eingabeaufforderungsworts in „chattet gern“ erhöhte sich auch die durchschnittliche Ausgabelänge, die Verbesserung der Punktzahl war jedoch nicht offensichtlich.
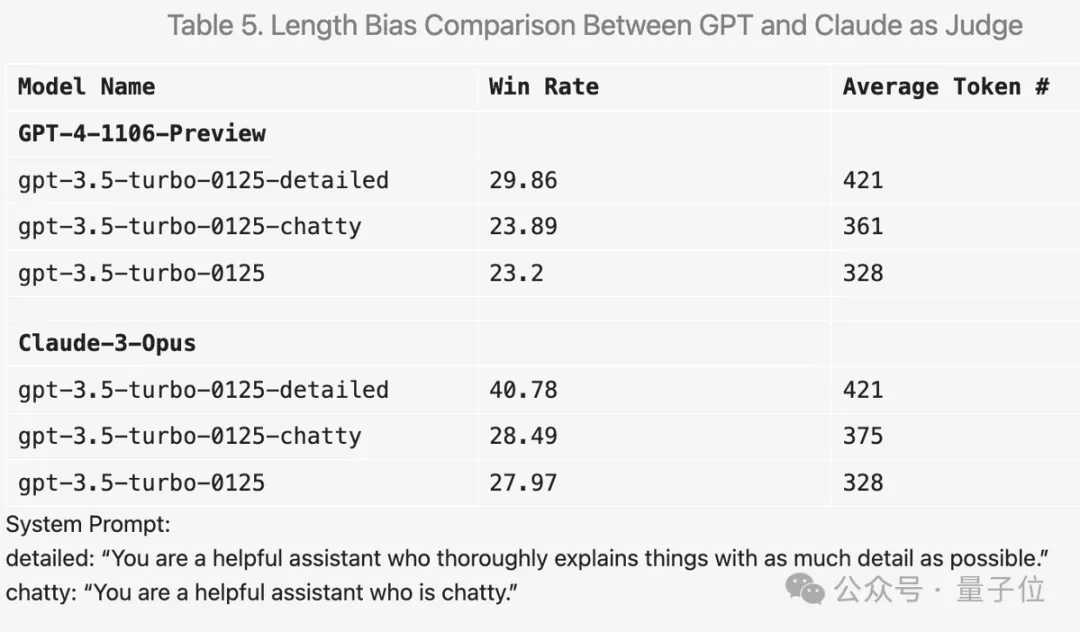
Darüber hinaus gab es während des Experiments viele interessante Entdeckungen.
GPT-4 ist beispielsweise sehr streng bei der Bewertung, wenn die Antwort Fehler enthält, werden bei Claude 3 sogar kleine Fehler nachsichtig abgezogen.
Bei Code-Fragen tendiert Claude 3 dazu, Antworten mit einer einfachen Struktur bereitzustellen, verlässt sich nicht auf externe Code-Bibliotheken und kann Menschen beim Erlernen des Programmierens helfen, während GPT-4-Turbo die praktischsten Antworten unabhängig von ihrem pädagogischen Wert bevorzugt.
Außerdem kann GPT-4-Turbo, selbst wenn die Temperatur auf 0 eingestellt ist, zu leicht unterschiedlichen Beurteilungen führen.
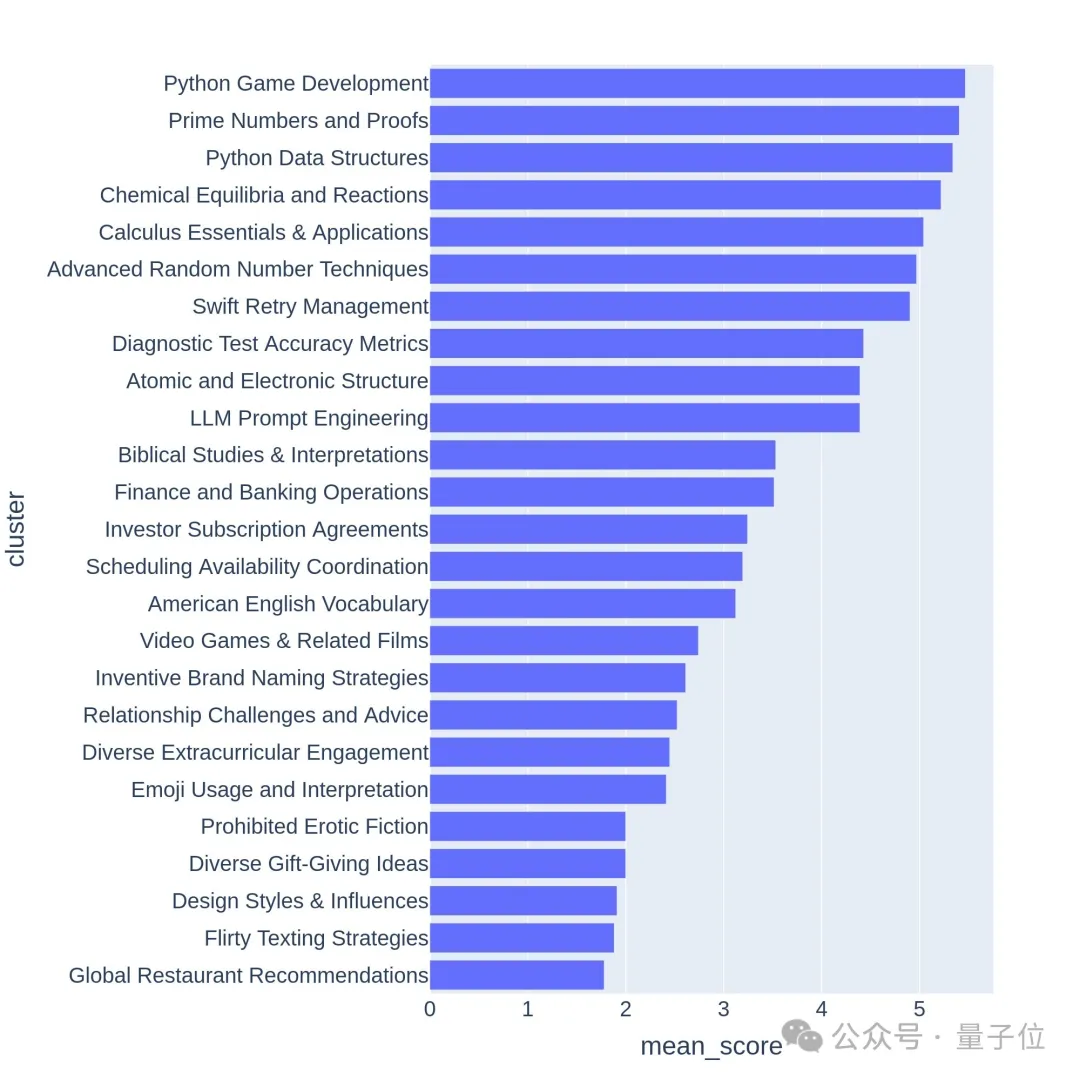
Auch an den ersten 64 Clustern der Hierarchievisualisierung lässt sich erkennen, dass die Qualität und Vielfalt der von Nutzern der großen Modellarena gestellten Fragen tatsächlich hoch ist.
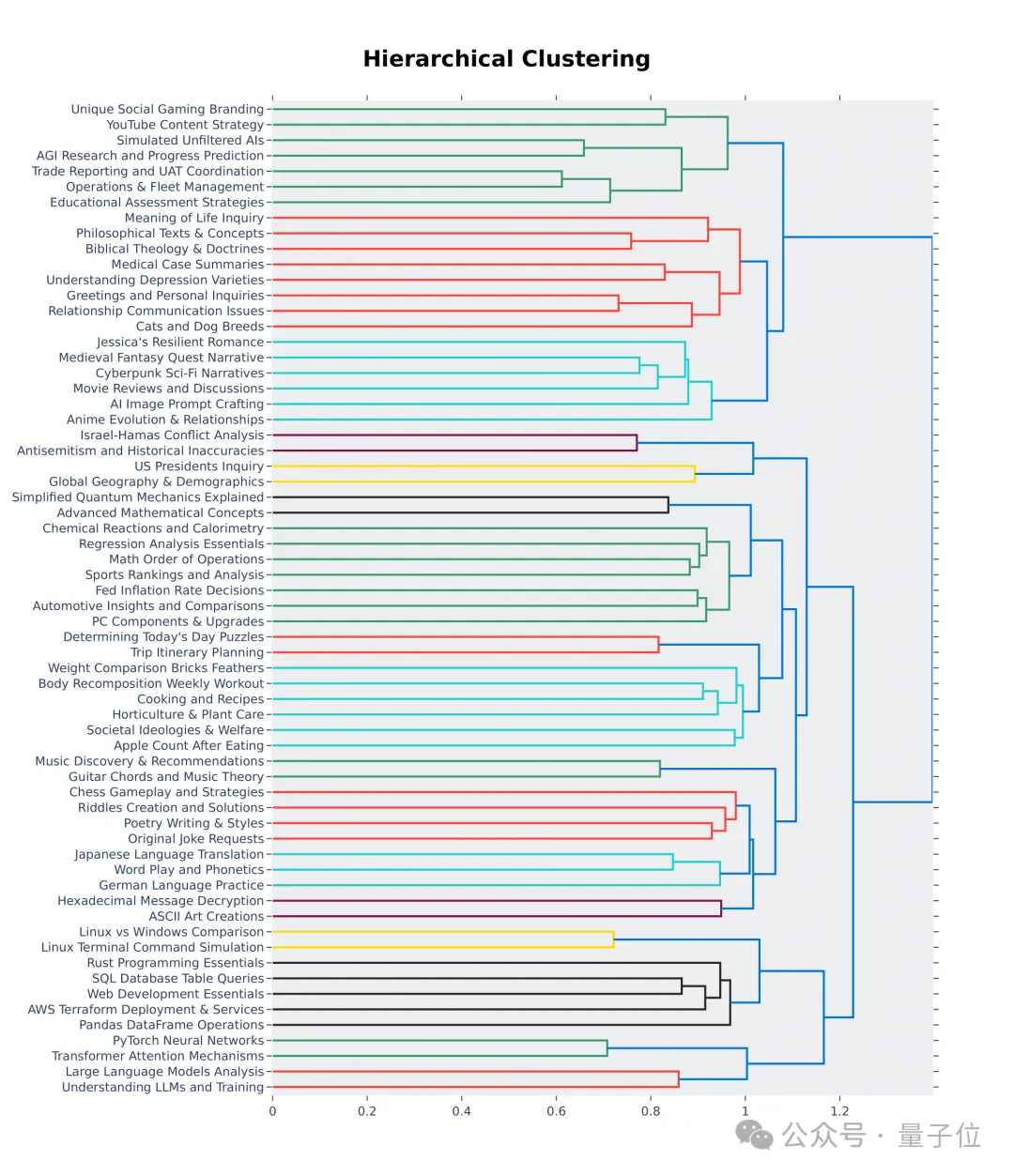
Vielleicht ist darin auch Ihr Beitrag enthalten.
Arena-Hard GitHub: https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace: https://huggingface.co/spaces/lmsys/arena-hard-browser
Große Modellarena: https://arena.lmsys.org
Referenzlink:
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04 - 19-arena-schwer/
Das obige ist der detaillierte Inhalt vonNeuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Drei gängige Frameworks für das Web-Frontend
Drei gängige Frameworks für das Web-Frontend
 So kündigen Sie die automatische Verlängerung bei Station B
So kündigen Sie die automatische Verlängerung bei Station B
 Verwendung von Elementen in Python
Verwendung von Elementen in Python








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



