


Da die autonome Fahrtechnologie ausgereifter wird und die Nachfrage nach Wahrnehmungsaufgaben für autonomes Fahren steigt, hoffen Industrie und Wissenschaft derzeit sehr auf ein ideales Wahrnehmungsalgorithmusmodell, das gleichzeitig abgeschlossen werden kann dreidimensionale Zielerkennung und semantische Segmentierungsaufgaben basierend auf dem BEV-Raum. Ein autonom fahrendes Fahrzeug ist in der Regel mit Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellen-Radarsensoren ausgestattet, um Daten in verschiedenen Modalitäten zu sammeln. Auf diese Weise können die komplementären Vorteile zwischen verschiedenen Modalitäten vollständig genutzt werden, sodass die komplementären Vorteile von Daten zwischen verschiedenen Modalitäten erzielt werden können. Beispielsweise können 3D-Punktwolkendaten Informationen für 3D-Zielerkennungsaufgaben liefern, während Farbbilddaten kann mehr Informationen für semantische Segmentierungsaufgaben liefern. Angesichts der komplementären Vorteile zwischen verschiedenen Modaldaten wird durch die Konvertierung der effektiven Informationen verschiedener Modaldaten in dasselbe Koordinatensystem die anschließende gemeinsame Verarbeitung und Entscheidungsfindung erleichtert. Beispielsweise können 3D-Punktwolkendaten in Punktwolkendaten basierend auf dem BEV-Raum umgewandelt werden, und Bilddaten von Rundumsichtkameras können durch die Kalibrierung interner und externer Parameter der Kamera in den 3D-Raum projiziert werden, wodurch eine einheitliche Verarbeitung erreicht wird verschiedene modale Daten. Durch die Nutzung unterschiedlicher Modaldaten können genauere Wahrnehmungsergebnisse erzielt werden als bei einzelnen Modaldaten. Jetzt können wir das multimodale Wahrnehmungsalgorithmusmodell bereits im Auto einsetzen, um robustere und genauere räumliche Wahrnehmungsergebnisse zu erzielen. Durch genaue räumliche Wahrnehmungsergebnisse können wir eine zuverlässigere und sicherere Garantie für die Realisierung autonomer Fahrfunktionen bieten.
Obwohl in Wissenschaft und Industrie kürzlich viele 3D-Wahrnehmungsalgorithmen für die multisensorische und multimodale Datenfusion basierend auf dem Transformer-Netzwerk-Framework vorgeschlagen wurden, nutzen sie alle den Kreuzaufmerksamkeitsmechanismus in Transformer, um eine multimodale Datenintegration zu erreichen. Fusion zwischen ihnen, um ideale 3D-Zielerkennungsergebnisse zu erzielen. Diese Art der multimodalen Merkmalsfusionsmethode ist jedoch nicht vollständig für semantische Segmentierungsaufgaben basierend auf dem BEV-Raum geeignet. Darüber hinaus verwenden viele Algorithmen nicht nur den Kreuzaufmerksamkeitsmechanismus, um die Informationsfusion zwischen verschiedenen Modalitäten abzuschließen, sondern verwenden auch die Vorwärtsvektorkonvertierung in LSA, um fusionierte Merkmale zu konstruieren. Es gibt jedoch auch einige Probleme wie folgt: (Begrenzte Wortanzahl, detaillierte Beschreibung folgt ).
Angesichts der vielen oben genannten Probleme im multimodalen Fusionsprozess, die sich auf die Wahrnehmungsfähigkeit des endgültigen Modells auswirken können, und angesichts der leistungsstarken Leistung, die das generative Modell kürzlich gezeigt hat, haben wir das generative Modell anhand seiner Verwendung untersucht um multimodale Fusions- und Rauschunterdrückungsaufgaben zwischen mehreren Sensoren zu erreichen. Darauf aufbauend schlagen wir einen generativen Modellwahrnehmungsalgorithmus DifFUSER vor, der auf bedingter Diffusion basiert, um multimodale Wahrnehmungsaufgaben zu implementieren. Wie aus der folgenden Abbildung ersichtlich ist, kann der von uns vorgeschlagene multimodale Datenfusionsalgorithmus DifFUSER einen effektiveren multimodalen Fusionsprozess erreichen.  Der multimodale Datenfusionsalgorithmus von DifFUSER kann einen effektiveren multimodalen Fusionsprozess erreichen. Die Methode umfasst hauptsächlich zwei Stufen. Zunächst verwenden wir generative Modelle, um die Eingabedaten zu entrauschen und zu verbessern und so saubere und reichhaltige multimodale Daten zu generieren. Anschließend werden die vom generativen Modell generierten Daten für die multimodale Fusion verwendet, um bessere Wahrnehmungseffekte zu erzielen. Die experimentellen Ergebnisse des DifFUSER-Algorithmus zeigen, dass der von uns vorgeschlagene multimodale Datenfusionsalgorithmus einen effektiveren multimodalen Fusionsprozess erreichen kann. Bei der Implementierung multimodaler Wahrnehmungsaufgaben kann dieser Algorithmus einen effektiveren multimodalen Fusionsprozess erreichen und die Wahrnehmungsfähigkeiten des Modells verbessern. Darüber hinaus kann der multimodale Datenfusionsalgorithmus des Algorithmus einen effizienteren multimodalen Fusionsprozess erreichen. Alles in allem
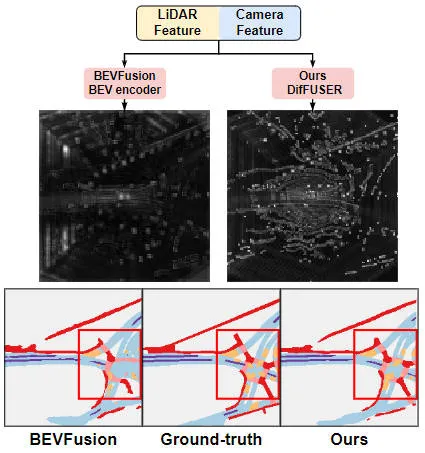
Visuelle Vergleichstabelle der Ergebnisse des vorgeschlagenen Algorithmusmodells und anderer Algorithmusmodelle
Papierlink: https://arxiv.org/pdf/2404.04629.pdf
„Moduldetails des DifFUSER-Algorithmus, Multitask-Wahrnehmungsalgorithmus basierend auf dem bedingten Diffusionsmodell“ ist ein Algorithmus zur Lösung von Aufgabenwahrnehmungsproblemen. Die folgende Abbildung zeigt die gesamte Netzwerkstruktur unseres vorgeschlagenen DifFUSER-Algorithmus. In diesem Modul schlagen wir einen Multitasking-Wahrnehmungsalgorithmus vor, der auf dem bedingten Diffusionsmodell basiert, um das Problem der Aufgabenwahrnehmung zu lösen. Das Ziel dieses Algorithmus besteht darin, die Leistung des Multitask-Lernens durch die Verbreitung und Aggregation aufgabenspezifischer Informationen im Netzwerk zu verbessern. Integration des DifFUSER-Algorithmus
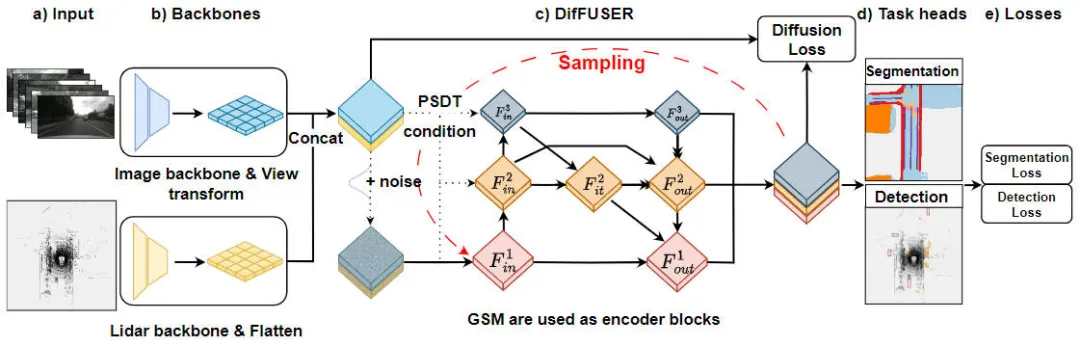 Vorgeschlagenes Netzwerkstrukturdiagramm des DifFUSER-Wahrnehmungsalgorithmusmodells
Vorgeschlagenes Netzwerkstrukturdiagramm des DifFUSER-Wahrnehmungsalgorithmusmodells
Wie aus der obigen Abbildung ersichtlich ist, umfasst die von uns vorgeschlagene DifFUSER-Netzwerkstruktur hauptsächlich drei Teilnetzwerke, nämlich den Backbone-Netzwerkteil, den multimodalen Datenfusionsteil von DifFUSER und der letzte BEV-Kopfteil der semantischen Segmentierungsaufgabe. Kopfteil der Wahrnehmungsaufgabe zur 3D-Objekterkennung. Im Backbone-Netzwerkteil nutzen wir vorhandene Deep-Learning-Netzwerkarchitekturen wie ResNet oder VGG, um High-Level-Merkmale der Eingabedaten zu extrahieren. Der multimodale Datenfusionsteil von DifFUSER verwendet mehrere parallele Zweige, wobei jeder Zweig zur Verarbeitung verschiedener Sensordatentypen (wie Bilder, Lidar und Radar usw.) verwendet wird. Jeder Zweig verfügt über einen eigenen Backbone-Netzwerkteil
Als nächstes werden wir die Implementierungsdetails jedes Hauptunterteils des Modells sorgfältig vorstellen.
Für die Wahrnehmungsaufgaben im autonomen Fahrsystem ist es entscheidend, dass das Algorithmusmodell die aktuelle äußere Umgebung in Echtzeit wahrnehmen kann, also ist es so sehr wichtig, um die Leistung und Effizienz des Diffusionsmoduls sicherzustellen. Daher lassen wir uns vom bidirektionalen Feature-Pyramiden-Netzwerk inspirieren und führen eine BiFPN-Diffusionsarchitektur mit ähnlichen Bedingungen ein, die wir Conditional-Mini-BiFPN nennen. Die spezifische Netzwerkstruktur ist in der obigen Abbildung dargestellt.


Für ein autonomes Fahrzeug ist die Leistung des autonomen Fahrerfassungssensors von entscheidender Bedeutung. Während der täglichen Fahrt des autonomen Fahrzeugs ist es sehr wahrscheinlich, dass die Der Kamerasensor oder Lidar-Sensor wird blockiert oder weist eine Fehlfunktion auf, was sich auf die Sicherheit und Betriebseffizienz des endgültigen autonomen Fahrsystems auswirkt. Basierend auf dieser Überlegung haben wir ein progressives Sensor-Dropout-Trainingsparadigma vorgeschlagen, um die Robustheit und Anpassungsfähigkeit des vorgeschlagenen Algorithmusmodells in Situationen zu verbessern, in denen der Sensor möglicherweise blockiert ist.
Durch unser vorgeschlagenes progressives Sensor-Dropout-Trainingsparadigma kann das Algorithmusmodell fehlende Merkmale rekonstruieren, indem es die Verteilung zweier modaler Daten nutzt, die von Kamerasensoren und Lidar-Sensoren erfasst werden, und so eine hervorragende Anpassung an Leistung und Robustheit unter rauen Bedingungen erreichen. Insbesondere nutzen wir Merkmale aus Bilddaten und Lidar-Punktwolkendaten auf drei verschiedene Arten: als Trainingsziele, als Rauscheingabe in das Diffusionsmodul und zur Simulation von Bedingungen, unter denen ein Sensor verloren geht oder eine Fehlfunktion aufweist. Während des Trainings erhöhen wir schrittweise die Verlustrate des Kamerasensor- oder Lidar-Sensoreingangs von 0 auf einen vordefinierten Maximalwert a = 25. Der gesamte Prozess kann durch die folgende Formel ausgedrückt werden:
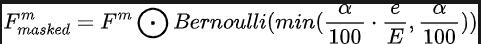
Stellt unter anderem die Anzahl der Trainingsrunden dar, in denen sich das aktuelle Modell befindet, und definiert die Ausfallwahrscheinlichkeit, um die Wahrscheinlichkeit darzustellen, dass jedes Feature gelöscht wird. Durch diesen progressiven Trainingsprozess wird das Modell nicht nur darauf trainiert, das Rauschen effektiv zu entstören und ausdrucksstärkere Merkmale zu erzeugen, sondern minimiert auch seine Abhängigkeit von einem einzelnen Sensor und verbessert so die Handhabung unvollständiger Sensoren mit größerer Belastbarkeit.

Im Einzelnen ist die Netzwerkstruktur des Gated Self-Conditioned Modulation Diffusion Module in der folgenden Abbildung dargestellt
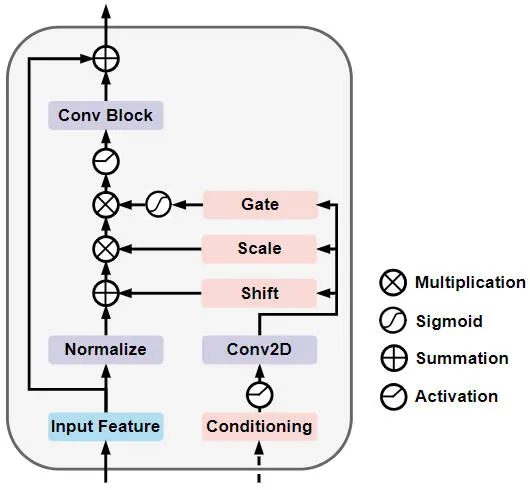
Gated Self-Conditioned Modulationsdiffusion Schematische Darstellung der Modulnetzwerkstruktur

Um die Wahrnehmungsergebnisse unseres vorgeschlagenen Algorithmusmodells DifFUSER für mehrere Aufgaben zu überprüfen, haben wir hauptsächlich durchgeführt Basierend auf dem nuScenes-Datensatz werden 3D-Zielerkennungs- und semantische Segmentierungsexperimente basierend auf dem BEV-Raum durchgeführt.
Zuerst haben wir die Leistung des vorgeschlagenen Algorithmusmodells DifFUSER mit anderen multimodalen Fusionsalgorithmen für semantische Segmentierungsaufgaben verglichen. Die spezifischen experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt:
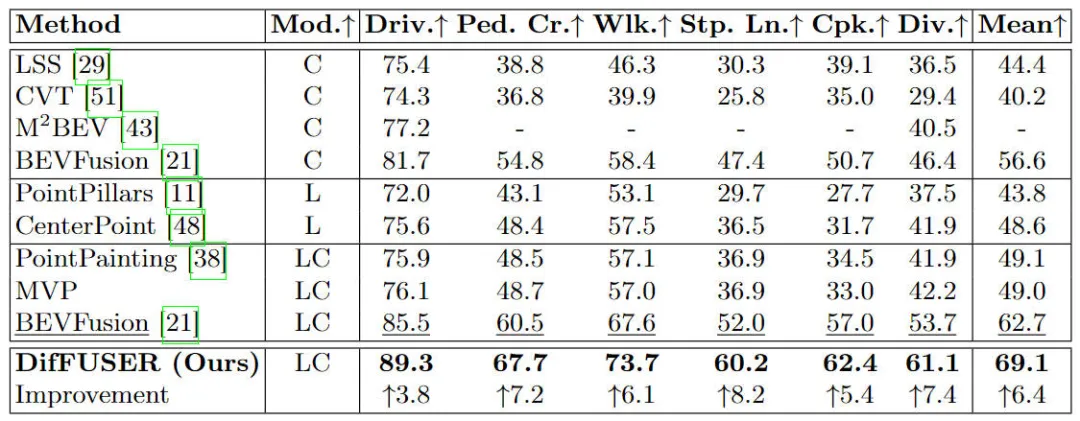 Vergleich verschiedener Algorithmusmodelle im nuScenes-Datensatz Experimentelle Ergebnisse semantischer Segmentierungsaufgaben basierend auf dem BEV-Raum
Vergleich verschiedener Algorithmusmodelle im nuScenes-Datensatz Experimentelle Ergebnisse semantischer Segmentierungsaufgaben basierend auf dem BEV-Raum
Aus den experimentellen Ergebnissen ist ersichtlich, dass das von uns vorgeschlagene Algorithmusmodell im Vergleich zum Basismodell eine deutlich verbesserte Leistung aufweist. Insbesondere beträgt der mIoU-Wert des BEVFusion-Modells nur 62,7 %, während das von uns vorgeschlagene Algorithmusmodell 69,1 % erreicht hat, was einer Verbesserung von 6,4 % entspricht, was zeigt, dass der von uns vorgeschlagene Algorithmus in verschiedenen Kategorien mehr Vorteile bietet. Darüber hinaus veranschaulicht die folgende Abbildung auch intuitiver die Vorteile des von uns vorgeschlagenen Algorithmusmodells. Insbesondere liefert der BEVFusion-Algorithmus schlechte Segmentierungsergebnisse, insbesondere in Szenarien über große Entfernungen, in denen eine Fehlausrichtung des Sensors offensichtlicher ist. Im Vergleich dazu liefert unser Algorithmusmodell genauere Segmentierungsergebnisse mit offensichtlicheren Details und weniger Rauschen.
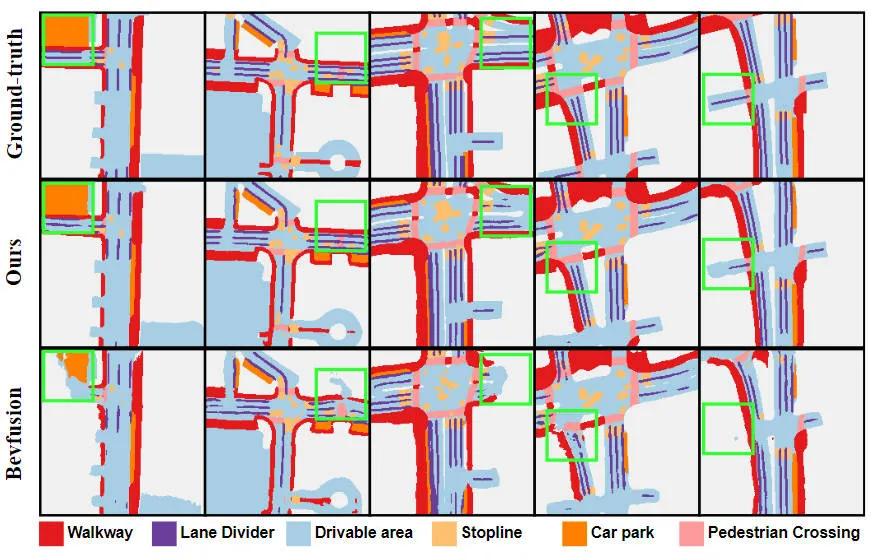
Vergleich der Segmentierungsvisualisierungsergebnisse des vorgeschlagenen Algorithmusmodells und des Basismodells
Darüber hinaus haben wir das vorgeschlagene Algorithmusmodell auch mit anderen 3D-Zielerkennungsalgorithmusmodellen verglichen. Die spezifischen experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt
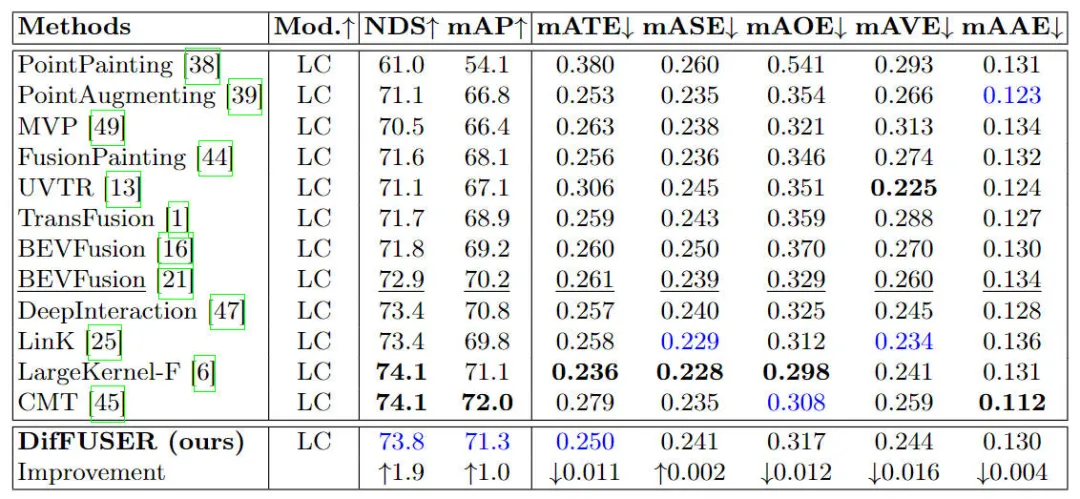
Vergleich der experimentellen Ergebnisse verschiedener Algorithmusmodelle zur 3D-Zielerkennungsaufgabe im nuScenes-Datensatz
Wie aus den in der Tabelle aufgeführten Ergebnissen ersichtlich ist, weist unser vorgeschlagenes Algorithmusmodell DifFUSER sowohl in NDS als auch in mAP eine bessere Leistung auf Im Vergleich zu den 72,9 % NDS und 70,2 % mAP des Basismodells BEVFusion ist unser Algorithmusmodell um 1,8 % bzw. 1,0 % höher. Die Verbesserung relevanter Indikatoren zeigt, dass das von uns vorgeschlagene multimodale Diffusionsfusionsmodul bei der Merkmalsreduzierung und Merkmalsverfeinerung wirksam ist.
Um die Wahrnehmungsrobustheit unseres vorgeschlagenen Algorithmusmodells im Falle eines Sensorausfalls oder einer Sensorokklusion zu zeigen, haben wir außerdem die Ergebnisse verwandter Segmentierungsaufgaben verglichen, wie in der folgenden Abbildung dargestellt.
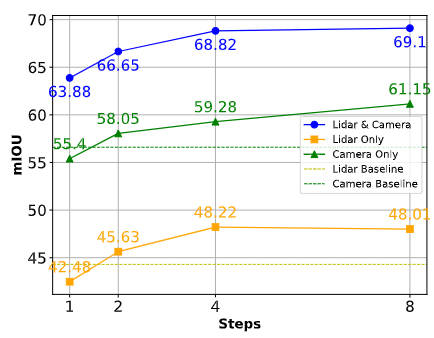
Vergleich der Algorithmusleistung in verschiedenen Situationen
Wie aus der obigen Abbildung ersichtlich ist, kann das von uns vorgeschlagene Algorithmusmodell bei ausreichender Abtastung fehlende Merkmale effektiv kompensieren und als Grundlage für die Sammlung fehlender Sensoren verwendet werden Informationen. Alternative Inhalte. Die Fähigkeit unseres vorgeschlagenen DifFUSER-Algorithmusmodells, synthetische Merkmale zu generieren und zu nutzen, verringert effektiv die Abhängigkeit von einer einzelnen Sensormodalität und stellt sicher, dass das Modell in verschiedenen und anspruchsvollen Umgebungen reibungslos funktionieren kann.
Die folgende Abbildung zeigt die Visualisierung der 3D-Zielerkennungs- und semantischen Segmentierungsergebnisse des BEV-Raums unseres vorgeschlagenen DifFUSER-Algorithmusmodells. Aus den Visualisierungsergebnissen ist ersichtlich, dass das von uns vorgeschlagene Algorithmusmodell gut ist Erkennung und Split-Effekt.

In diesem Artikel wird ein multimodales Wahrnehmungsalgorithmusmodell DifFUSER vorgeschlagen, das auf dem Diffusionsmodell basiert und die Fusionsarchitektur des Netzwerkmodells verbessert und die Rauschunterdrückungseigenschaften nutzt des Diffusionsmodells. Die experimentellen Ergebnisse des Nuscenes-Datensatzes zeigen, dass das von uns vorgeschlagene Algorithmusmodell eine SOTA-Segmentierungsleistung in der semantischen Segmentierungsaufgabe des BEV-Raums erreicht und eine ähnliche Erkennungsleistung wie das aktuelle SOTA-Algorithmusmodell in der 3D-Zielerkennungsaufgabe erreichen kann.
Das obige ist der detaillierte Inhalt vonJenseits von BEVFusion! DifFUSER: Das Diffusionsmodell tritt in die autonome Fahr-Multitask ein (BEV-Segmentierung + Erkennung Dual-SOTA). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was sind die Java-Texteditoren?
Was sind die Java-Texteditoren?
 So deduplizieren Sie eine Datenbank in MySQL
So deduplizieren Sie eine Datenbank in MySQL
 Der Unterschied zwischen injektiv und surjektiv
Der Unterschied zwischen injektiv und surjektiv
 Was ist die Interrupt-Priorität?
Was ist die Interrupt-Priorität?
 So legen Sie ein geplantes Herunterfahren in UOS fest
So legen Sie ein geplantes Herunterfahren in UOS fest
 vim-Befehl zum Speichern und Beenden
vim-Befehl zum Speichern und Beenden
 So überprüfen Sie tote Links auf Ihrer Website
So überprüfen Sie tote Links auf Ihrer Website
 Einführung in den Dateityp
Einführung in den Dateityp








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



