


Wird das Sprachmodell zukünftige Token vorsehen? Dieses Papier gibt Ihnen die Antwort.
„Lass Yann LeCun es nicht sehen.“
Yann LeCun sagte, es sei zu spät, er habe es bereits gesehen. Die Frage, die in dem Artikel „LeCun Must Read“ diskutiert wird, den ich heute vorstellen werde, lautet: Ist Transformer ein durchdachtes Sprachmodell? Wenn es an einem bestimmten Standort Rückschlüsse zieht, antizipiert es dann nachfolgende Standorte?
Das Fazit dieser Studie lautet: Transformer hat die Fähigkeit dazu, tut dies aber in der Praxis nicht.
Wir alle wissen, dass Menschen denken, bevor sie sprechen. Zehn Jahre Sprachforschung zeigen, dass Menschen, wenn sie Sprache verwenden, die bevorstehende Spracheingabe, Wörter oder Sätze, mental vorhersagen.
Im Gegensatz zum Menschen weisen aktuelle Sprachmodelle beim „Sprechen“ jedem Token einen festen Rechenaufwand zu. Wir kommen also nicht umhin zu fragen: Werden Sprachmodelle im Voraus denken wie Menschen?
Jüngsten Untersuchungen zufolge konnte gezeigt werden, dass der nächste Token durch die Untersuchung des verborgenen Zustands des Sprachmodells vorhergesagt werden kann. Interessanterweise kann durch die Verwendung linearer Sonden für die verborgenen Zustände des Modells die Ausgabe des Modells auf zukünftige Token bis zu einem gewissen Grad vorhergesagt werden, und zukünftige Ausgaben können vorhersehbar geändert werden. Einige neuere Untersuchungen haben gezeigt, dass es möglich ist, das nächste Token vorherzusagen, indem die verborgenen Zustände eines Sprachmodells untersucht werden. Interessanterweise kann durch die Verwendung linearer Sonden für die verborgenen Zustände des Modells die Ausgabe des Modells auf zukünftige Token bis zu einem gewissen Grad vorhergesagt werden, und zukünftige Ausgaben können vorhersehbar geändert werden.
Diese Ergebnisse legen nahe, dass die Modellaktivierung zu einem bestimmten Zeitpunkt zumindest teilweise eine Prognose für die zukünftige Ausgabe darstellt.
Allerdings wissen wir noch nicht, warum: Ist dies nur eine zufällige Eigenschaft der Daten oder liegt es daran, dass das Modell absichtlich Informationen für zukünftige Zeitschritte aufbereitet (dies wirkt sich jedoch auf die Leistung des Modells am aktuellen Standort aus)?
Um diese Frage zu beantworten, haben drei Forscher der University of Colorado Boulder und der Cornell University kürzlich einen Artikel mit dem Titel „Werden Sprachmodelle zukünftige Token planen?“ veröffentlicht. "These.

Titel des Papiers: Planen Sprachmodelle zukünftige Token? Optimieren Sie nicht nur das Gewicht für den Verlust der aktuellen Token-Position, sondern optimieren Sie auch die Token später in der Sequenz. Sie fragten weiter: In welchem Verhältnis wird das aktuelle Transformatorgewicht dem aktuellen Token und zukünftigen Token Ressourcen zuweisen?
Sie haben zwei Möglichkeiten in Betracht gezogen: die Pre-Caching-Hypothese und die Breadcrumbs-Hypothese.
Die Pre-Cache-Hypothese bedeutet, dass der Transformator im Zeitschritt t Merkmale berechnet, die für die Inferenzaufgabe des aktuellen Zeitschritts nicht relevant sind, aber für zukünftige Zeitschritte t + τ nützlich sein können, während die Breadcrumb-Hypothese bedeutet, dass die Merkmale, die für den Zeitschritt t am relevantesten sind, bereits den Merkmalen entsprechen, die im Zeitschritt t + τ am nützlichsten sind. Um zu bewerten, welche Hypothese richtig ist, schlug das Team ein kurzsichtiges Trainingsschema vor, das den Verlustgradienten an der aktuellen Position nicht auf den verborgenen Zustand an der vorherigen Position überträgt. Die mathematische Definition und theoretische Beschreibung der oben genannten Annahmen und Lösungen finden Sie im Originalpapier.

Um zu verstehen, ob es für Sprachmodelle möglich ist, Precaching direkt zu implementieren, haben sie ein synthetisches Szenario entworfen, in dem die Aufgabe nur durch explizites Precaching erfüllt werden kann. Sie konfigurierten eine Aufgabe, bei der das Modell Informationen für den nächsten Token vorab berechnen musste, da es sonst nicht in der Lage wäre, die richtige Antwort in einem einzigen Durchgang genau zu berechnen.的 Definition synthetischer Datensätze, die vom Team erstellt wurden.
In dieser synthetischen Szene fand das Team klare Beweise dafür, dass Transformatoren lernen können, vorab zwischenzuspeichern. Transformatorbasierte Sequenzmodelle tun dies, wenn sie Informationen vorab berechnen müssen, um Verluste zu minimieren. Dann untersuchten sie, ob Modelle natürlicher Sprache (vorab trainierte GPT-2-Varianten) die Breadcrumb-Hypothese oder die Precaching-Hypothese aufweisen würden. Ihre Experimente mit kurzsichtigen Trainingsschemata zeigen, dass Precaching in dieser Umgebung viel seltener auftritt, sodass die Ergebnisse stärker in Richtung der Breadcrumb-Hypothese tendieren.
2-Modell basierend auf der Token-Position und dem kurzsichtigen GPT-2-Modell.原 GPT-2 Überprüfung des Kreuzentropieverlusts, der durch primitives und kurzes Training erzielt wird.
Das Team behauptet also: Auf realen Sprachdaten bereiten Sprachmodelle zukünftige Informationen nicht in nennenswertem Umfang vor. Stattdessen handelt es sich um Rechenfunktionen, die für die Vorhersage des nächsten Tokens nützlich sind – was sich auch für zukünftige Schritte als nützlich erweisen wird. 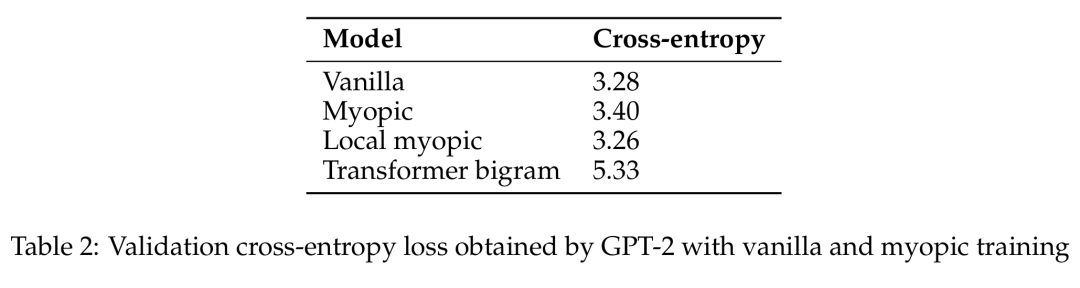
Das Team sagte: „In den Sprachdaten stellen wir fest, dass es keinen signifikanten Kompromiss zwischen der gierigen Optimierung für den nächsten Token-Verlust und der Sicherstellung der zukünftigen Vorhersageleistung gibt Wir können also wahrscheinlich sehen, dass es herauskommt.“ Die Frage, ob der Transformer vorausschauend sein kann, scheint im Wesentlichen eine Datenfrage zu sein.
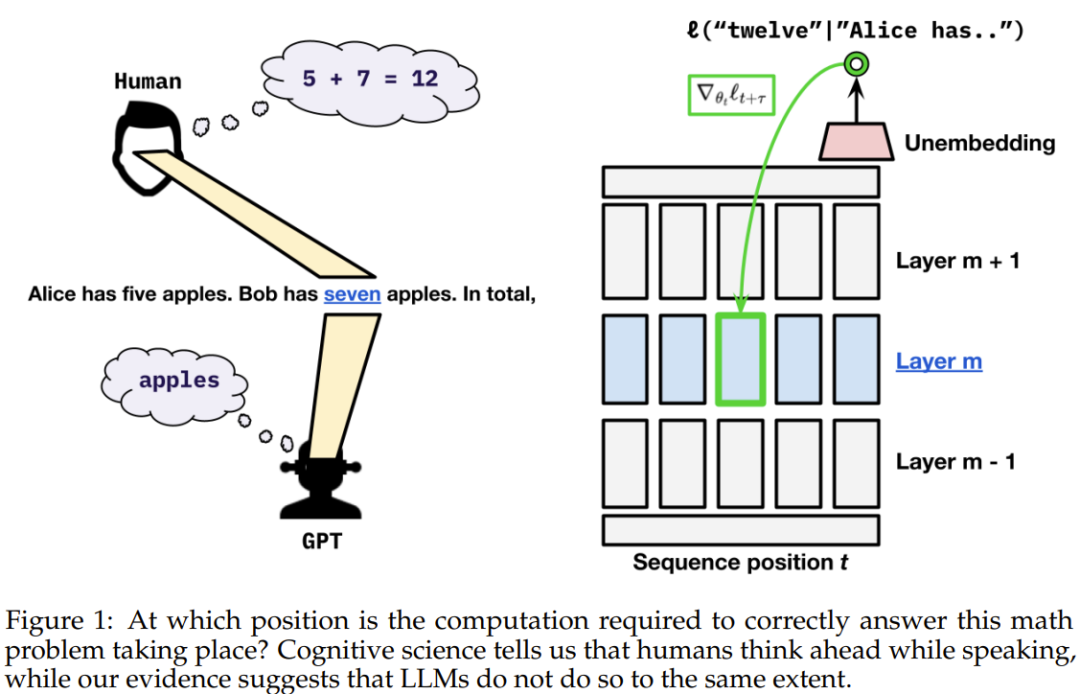 Es ist denkbar, dass wir vielleicht in Zukunft durch geeignete Datenverarbeitungsmethoden Sprachmodellen die Fähigkeit geben können, wie Menschen vorauszudenken.
Es ist denkbar, dass wir vielleicht in Zukunft durch geeignete Datenverarbeitungsmethoden Sprachmodellen die Fähigkeit geben können, wie Menschen vorauszudenken.
Das obige ist der detaillierte Inhalt vonTransformer könnte nachdenklich sein, tut es aber einfach nicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Konfigurieren Sie die Java-Laufzeitumgebung
Konfigurieren Sie die Java-Laufzeitumgebung
 So installieren Sie den Pycharm-Interpreter
So installieren Sie den Pycharm-Interpreter
 So überprüfen Sie die CPU-Auslastung unter Linux
So überprüfen Sie die CPU-Auslastung unter Linux
 Die Rolle von Linux-Terminalbefehlen
Die Rolle von Linux-Terminalbefehlen
 So stellen Sie eine Verbindung zum LAN her
So stellen Sie eine Verbindung zum LAN her
 Verwendung der isnumber-Funktion
Verwendung der isnumber-Funktion
 So verwenden Sie Google Voice
So verwenden Sie Google Voice
 So reparieren Sie das Win7-System, wenn es beschädigt ist und nicht gestartet werden kann
So reparieren Sie das Win7-System, wenn es beschädigt ist und nicht gestartet werden kann








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



