


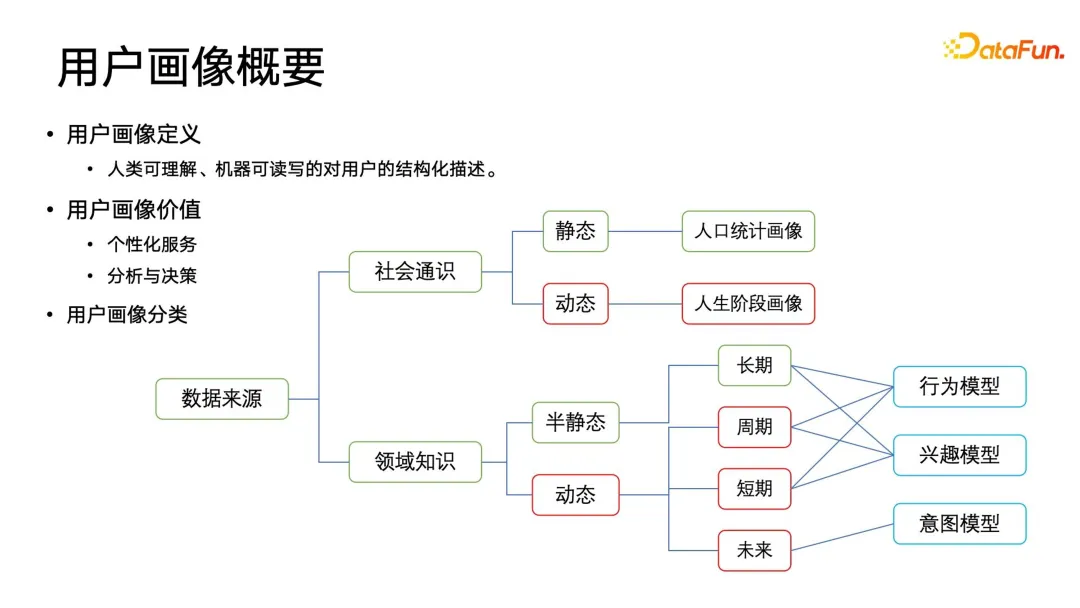
Ein Porträt ist eine strukturierte Beschreibung des Benutzers, die für Menschen verständlich, maschinenlesbar und beschreibbar ist. Es bietet nicht nur personalisierte Dienstleistungen, sondern spielt auch eine wichtige Rolle bei der strategischen Entscheidungsfindung und Geschäftsanalyse des Unternehmens.
Je nach Datenquelle ist es in die Kategorie „Social General Knowledge“ und „Domain Knowledge“ unterteilt. Allgemeine Sozialporträts können nach der Zeitdimension in statische und dynamische Kategorien unterteilt werden. Die häufigsten statischen allgemeinen Sozialporträts umfassen demografische Merkmale wie Geschlecht, Haushaltsregistrierung, Abschlussschule usw. Diese Inhalte werden über einen relativ langen Zeitraum angezeigt Die Fenster sind relativ statisch und werden nicht nur in Bildern verwendet, sondern auch häufig in der Demografie, Demografie, Soziologie usw. Wichtiger sind dynamische soziale Gesamtporträts, die auch als Lebensabschnittsporträts bezeichnet werden. Beispielsweise wird sich das Einkommen der Menschen mit der beruflichen Entwicklung weiter ändern, und auch ihre Einkaufstendenzen werden sich ändern. Daher sind diese Lebensabschnittsporträts von großer praktischer Bedeutung Wert.
Zusätzlich zu den oben genannten allgemeinen Porträts können Unternehmen weitere Domänenwissensporträts erstellen. Domänenwissensporträts können aus der Zeitdimension in semistatische und dynamische Attributporträts unterteilt werden und können weiter in langfristige, zyklische, kurzfristige und zukünftige Attributporträts unterteilt werden. Diese Zeitdimensionsporträts sind mit konzeptuellen Feldern verknüpft, zu denen Verhaltensmodelle, Interessenmodelle und Absichtsmodelle gehören.
Das Verhaltensmodell verfolgt hauptsächlich das zyklische Verhalten der Benutzer, z. B. was Benutzer jeden Morgen beim Pendeln tun, was sie abends nach der Arbeit tun, was sie unter der Woche tun, was sie am Wochenende tun usw andere zyklische Verhaltensweisen. Das Interessenmodell führt eine bestimmte gemeinsame Modellierung und Sortierung von Tags innerhalb des Domänenwissens durch. Beispielsweise können Benutzer nach der Interaktion mit Plattformprodukten wie APPs korreliert und analysiert werden, um einige strukturierte und gekennzeichnete Daten zu extrahieren Sie können in Kategorien eingeteilt, mit einem bestimmten Gewicht versehen und schließlich nach einem bestimmten Interessenprofil sortiert werden. Es ist zu beachten, dass das Absichtsmodell eher eine Zukunftsform hat und eine Vorhersage der zukünftigen Absichten des Benutzers darstellt. Aber wie kann man die möglichen Absichten neuer Benutzer vorhersagen, bevor sie interagieren? Dieses Problem ist stärker auf Echtzeit- und zukünftige Porträts ausgerichtet und stellt auch höhere Anforderungen an die gesamte Infrastrukturstruktur der Porträtdaten.
Nachdem wir das Konzept und die allgemeine Klassifizierung von Bildern verstanden haben, stellen wir kurz das grundlegende Anwendungsgerüst von Benutzerporträts vor. Das gesamte Framework kann in vier Ebenen unterteilt werden: Die erste ist die Datenerfassung, die zweite ist die Datenvorverarbeitung, die dritte ist die Erstellung und Aktualisierung von Porträts basierend auf diesen verarbeiteten Daten und schließlich wird in der Anwendungsebene ein Nutzungsprotokoll definiert Anwendungsschicht, damit nachgeschaltete Benutzer Bilder bequemer, schneller und effizienter für verschiedene Anwendungen verwenden können.
Anhand dieses Frameworks können wir feststellen, dass Benutzerprofilierungsanwendungen und Benutzerprofilierungsalgorithmen eine sehr breite und komplexe Konnotation verstehen müssen, da es sich nicht nur um einfache, beschriftete, textbasierte Daten handelt. Es gibt auch verschiedene Multi- Modale Daten, bei denen es sich um Audio-, Video- oder Grafikdaten handeln kann, sind erforderlich, um qualitativ hochwertige Daten zu erhalten und anschließend ein sichereres Porträt zu erstellen. Dies umfasst verschiedene Aspekte wie Data Mining, maschinelles Lernen, Wissensgraphen und statistisches Lernen. Der Unterschied zwischen Benutzerporträts und herkömmlichen Suchempfehlungsalgorithmen besteht darin, dass wir eng mit Domänenexperten zusammenarbeiten müssen, um in Iterationen und Zyklen kontinuierlich qualitativ hochwertigere Porträts zu erstellen.

Benutzerporträt ist ein Konzept, das durch eine eingehende Analyse von Benutzerverhaltensdaten und -informationen erstellt wurde. Indem wir die Interessen, Vorlieben und Verhaltensmuster der Nutzer verstehen, können wir den Nutzern personalisierte Dienste und Erlebnisse besser bieten.
In den Anfängen stützten sich Benutzerporträts hauptsächlich auf Wissensgraphen, die aus dem Konzept der Ontologie stammen. Die Ontologie hingegen gehört zur Kategorie der Philosophie. Erstens ist die Definition der Ontologie der Definition des Porträts sehr ähnlich. Es handelt sich um ein konzeptionelles System, das für Menschen verständlich und für Maschinen lesbar und beschreibbar ist. Natürlich kann die Komplexität dieses Begriffssystems selbst sehr hoch sein. Es besteht aus Entitäten, Attributen, Beziehungen und Axiomen. Der Vorteil von auf Ontologie basierenden Benutzerporträts besteht darin, dass Benutzer und Inhalte einfach zu klassifizieren sind und es bequem ist, Datenberichte zu erstellen, die für Menschen intuitiv verständlich sind, und dann Entscheidungen auf der Grundlage der relevanten Schlussfolgerungen der Berichte zu treffen Warum wird diese Methode im Nicht-Deep-Learning-Zeitalter gewählt? Eine technische Form.
Als nächstes werden wir einige grundlegende Konzepte der Ontologie vorstellen. Um eine Ontologie zu erstellen, müssen Sie zunächst Domänenwissen konzeptualisieren, also Entitäten, Attribute, Beziehungen und Axiome konstruieren und diese in maschinenlesbare Formate wie RDF und OWL verarbeiten. Natürlich können Sie auch einige einfachere Datenformate verwenden oder die Ontologie sogar in eine relationale Datenbank oder Diagrammdatenbank umwandeln, die speichern, lesen, schreiben und analysieren kann. Der Weg, ein solches Porträt zu erhalten, besteht normalerweise darin, es durch Fachexperten zu erstellen oder es auf der Grundlage einiger bestehender Industriestandards zu bereichern und zu verfeinern. Beispielsweise stützt sich das von Taobao eingeführte Produktkennzeichnungssystem tatsächlich auf die öffentlichen Standards des Landes für verschiedene verarbeitende Rohstoffindustrien und erweitert und iteriert diese Grundlage.

Das Bild unten ist ein sehr einfaches Ontologiebeispiel, das 3 Knoten enthält. Die Entität im Bild ist jeweils ein Interessen-Tag im Unterhaltungsbereich Filme haben eindeutige IDs und jeder Film hat seine eigenen Attribute, wie z. B. Titel und Hauptrolle. Diese Entität gehört ebenfalls zur Krimiserie, und die Krimiserie gehört zur Unterkategorie der Actionfilme. Wir schreiben das RDF-Textdokument auf der rechten Seite der Abbildung unten basierend auf diesem visuellen Diagramm. In diesem Dokument werden zusätzlich zu den Entitätsattributbeziehungen, die wir intuitiv verstehen können, auch einige Axiome definiert, wie zum Beispiel die Einschränkung, die „hat“. „Titel“ kann nur auf den grundlegenden konzeptionellen Bereich von Filmen wirken, wenn es andere konzeptionelle Bereiche gibt, wie z. B. die Verwendung des Regisseurs des Films als Einheit, um ihn in die Ontologie einzubauen, kann der Filmregisseur nicht über das Attribut „hat Titel“ verfügen. . Das Obige ist eine kurze Einführung in die Ontologie.

In den Anfängen der auf Ontologie basierenden Benutzerprofilierung wurde eine TF-IDF-ähnliche Methode verwendet, um das Gewicht der erstellten strukturierten Tags zu berechnen. TF-IDF wurde in der Vergangenheit hauptsächlich im Suchfeld oder Text-Betrefffeld verwendet. Es berechnete hauptsächlich die Gewichtung eines bestimmten Suchbegriffs oder Betreffworts. Bei der Anwendung auf Benutzerporträts muss es nur leicht eingeschränkt und verformt werden, z Im vorherigen Beispiel zählt TF die Anzahl der Filme oder kurzen Videos, die Benutzer unter dieser Tag-Kategorie ansehen. IDF zählt zunächst die Anzahl der Filme oder kurzen Videos, die Benutzer unter jeder Tag-Kategorie ansehen alle historischen Ansichten und berechnen Sie sie dann gemäß der Formel in der Abbildung. Die Berechnungsmethode von TF-IDF ist sehr einfach und stabil, außerdem ist sie interpretierbar und einfach zu verwenden.
Aber seine Mängel liegen auch auf der Hand: TF-IDF reagiert sehr empfindlich auf die Tag-Granularität, ist jedoch unempfindlich gegenüber der Ontologiestruktur selbst. Es kann unpopuläre Interessen überbetonen und zu trivialen Lösungen führen, wie z. B. Benutzer Video unter einem bestimmten Tag wird der TF sehr klein und der IDF extrem groß sein. Der TF-IDF wird möglicherweise einen Wert erreichen, der seinem populären Interesse nahe kommt. Noch wichtiger ist, dass wir die Benutzerporträts im Laufe der Zeit aktualisieren und anpassen müssen und die herkömmliche TF-IDF-Methode für diese Situation nicht geeignet ist. Daher haben Forscher eine neue Methode zur direkten Erstellung gewichteter Benutzerporträts basierend auf dem strukturierten Ausdruck der Ontologie vorgeschlagen, um den Anforderungen dynamischer Aktualisierungen gerecht zu werden.

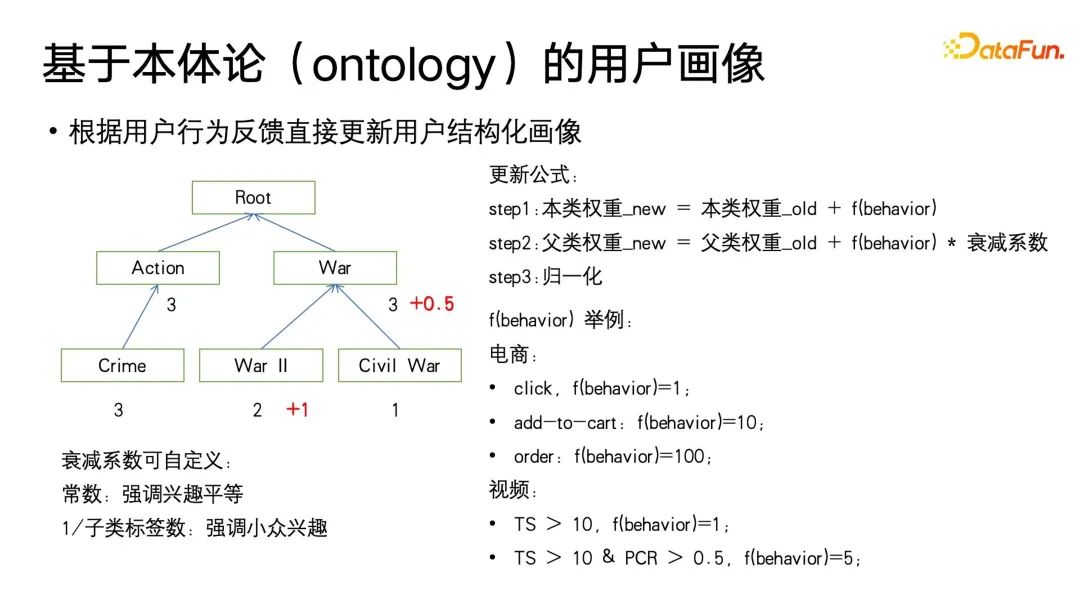
Dieser Algorithmus beginnt in der Blattkategorie der Ontologie und verwendet das Medienkonsumverhalten des Benutzers unter dem entsprechenden Tag, um das Gewicht zu aktualisieren. Das Gewicht wird auf 0 initialisiert und dann entsprechend der durch das Verhalten des Benutzers definierten fbehavior -Funktion aktualisiert . Die fbehavior -Funktion gibt unterschiedliche implizite Feedbacksignale basierend auf den unterschiedlichen Ebenen des Benutzerkonsums, wie z. B. Klicks, zusätzliche Käufe und Bestellungen im E-Commerce-Bereich oder Wiedergabe und Abschluss im Videobereich. Gleichzeitig werden wir auch unterschiedlich starke Rückmeldungen zu unterschiedlichem Nutzerverhalten geben, zum Beispiel beim E-Commerce-Konsumverhalten, Bestellen > Kaufen > Klicks, beim Videokonsum, höherer Wiedergabeabschluss, höherer Wiedergabedauer usw. A Außerdem wird ein stärkerer Wert für das Verhalten festgelegt.
Nachdem das Zielsignaturgewicht der Blattklasse aktualisiert wurde, muss das Gewicht der übergeordneten Klasse aktualisiert werden. Es ist zu beachten, dass beim Aktualisieren der übergeordneten Klasse ein Zerfallskoeffizient von weniger als 1 definiert werden muss. Denn wie in der Abbildung gezeigt, interessieren sich Benutzer möglicherweise für die Unterkategorie „Zweiter Weltkrieg“ in „Krieg“, aber möglicherweise nicht für andere Kriegsthemen. Dieser Dämpfungskoeffizient kann als Hyperparameter angepasst werden. Diese Definition betont die Gleichheit des Beitrags der einzelnen Unterkategorien zur übergeordneten Kategorie. Der Kehrwert der Anzahl der Unterkategoriebezeichnungen kann auch als Dämpfungskoeffizient verwendet werden, sodass mehr Wert darauf gelegt wird Bei Nischeninteressen enthalten beispielsweise einige große Hauptkategorie-Knoten weit gefasste und nicht eng miteinander verbundene Themen. Normalerweise ist die Anzahl solcher Werke sehr, sehr groß. und die Abklinggeschwindigkeit kann entsprechend schneller eingestellt werden, und die kleineren Unterkategoriebezeichnungen sind möglicherweise von Nischeninteresse und es gibt nicht viele Werke. Die Beziehung zwischen den Unterkategoriethemen und der Abschwächungsgeschwindigkeit ist relativ eng kann entsprechend kleiner eingestellt werden. Kurz gesagt, wir können den Dämpfungskoeffizienten basierend auf diesen in der Ontologie definierten Domänenwissensattributen festlegen.
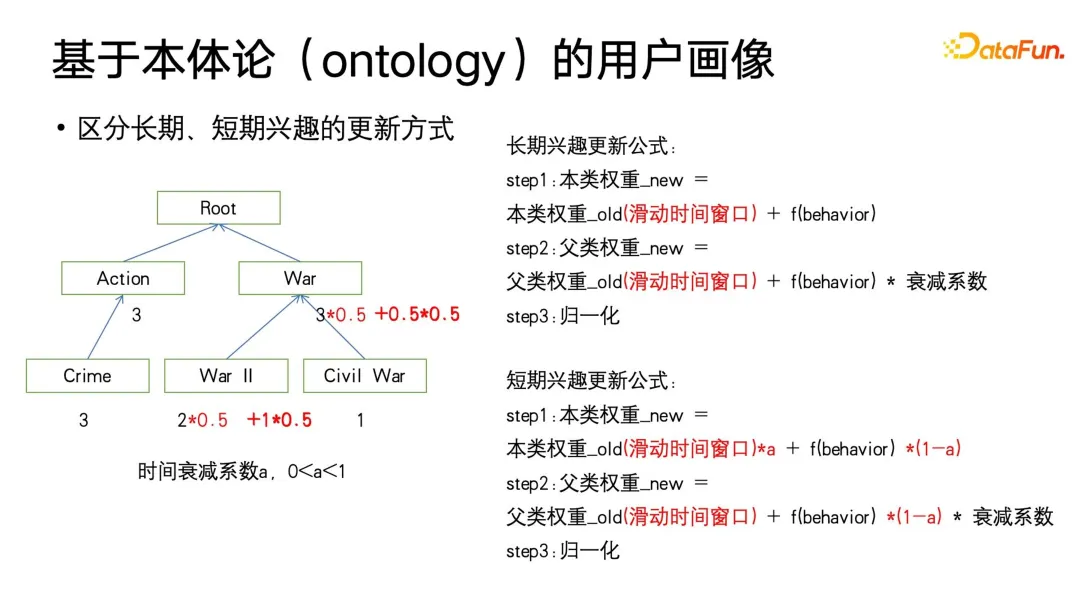
Wir dachten zunächst, dass wir die Aktualisierung des Gewichts selbst noch weiter anpassen könnten. Wenn Sie langfristige und kurzfristige Benutzerporträts unterscheiden müssen, können Sie der Gewichtung ein Schiebefenster hinzufügen und einen Zeitabfallkoeffizienten a (zwischen 0 und 1) definieren. Die Funktion des Schiebefensters besteht darin, sich nur auf den Benutzer zu konzentrieren Der Grund dafür ist, dass sich die langfristigen Interessen des Benutzers mit der Änderung der Lebensphase auch langsam ändern Ich schaue mir den Film ein oder zwei Jahre lang an und mag ihn dann nicht mehr.
Darüber hinaus können Sie auch feststellen, dass diese Formel der Adam-Gradientenaktualisierungsmethode mit Impuls ähnelt. Wir passen die Größe von a an, damit sich die Gewichtsaktualisierung bis zu einem gewissen Grad stärker auf die Geschichte oder die Gegenwart konzentriert. Insbesondere wird bei einem kleineren a der Schwerpunkt stärker auf die Gegenwart gelegt, und die historische Anhäufung wird dann stärker abgeschwächt.
Die einfachste Methode besteht darin, das Porträt durch kollaborative Filterung zu vervollständigen. Angenommen, es gibt eine Beschriftungsmatrix. Die horizontale Achse ist der Benutzer und die vertikale Achse ist die Elemente in dieser sehr großen Matrix sind die Reaktion des Benutzers auf dieses Label. Diese Elemente können 0 oder 1 oder Zinsgewichte sein. Selbstverständlich lässt sich diese Matrix auch so umwandeln, dass sie sich an das demografische Profil anpasst. Beispielsweise kann die Bezeichnung so ausgedrückt werden, ob es sich um einen Studenten handelt, ob es sich um einen Berufstätigen handelt oder um welche Art von Beruf es sich handelt usw. Sie können auch Folgendes verwenden Eine Codierungsmethode zum Erstellen dieser Matrix. Sie können auch eine Matrixzerlegung anwenden, um die Matrixzerlegung zu erhalten, und dann die fehlenden Eigenwerte vervollständigen. Zu diesem Zeitpunkt ist das Optimierungsziel wie in der folgenden Abbildung dargestellt.
Wie Sie dieser Formel entnehmen können, ist die ursprüngliche Matrix M, die Vervollständigungsmatrix ist eine Matrix mit niedrigem Rang, da wir davon ausgehen, dass die Interessen einer großen Anzahl von Benutzern ähnlich sind Für ähnliche Benutzer muss die Etikettenmatrix einen niedrigen Rang haben. Schließlich wird eine Regularisierung dieser Matrix durchgeführt, um das Ziel einer nicht-negativen Matrixzerlegung zu erreichen. Diese Methode kann tatsächlich mit der uns am besten vertrauten Methode des stochastischen Gradientenabstiegs gelöst werden.
Natürlich können neben dem Rückschluss auf fehlende Attribute oder Interessen durch Matrixzerlegung auch traditionelle Methoden des maschinellen Lernens eingesetzt werden. Es wird immer noch davon ausgegangen, dass ähnliche Benutzer ähnliche Interessen haben. Zu diesem Zeitpunkt kann die KNN-Klassifizierung oder Regression verwendet werden, um die Interessen des Benutzers abzuleiten und dann die Tags oder Tags mit den größten hinzuzufügen Anzahl der Nachbarn unter den k nächsten Nachbarn des Benutzers. Der gewichtete Mittelwert wird den fehlenden Attributen des Benutzers zugewiesen. Das Nachbarschaftsbeziehungsdiagramm kann von Ihnen selbst erstellt werden oder es kann sich um eine vorgefertigte Nachbarschaftsdiagrammstruktur handeln, z. B. das Benutzerporträt eines sozialen Netzwerks oder das Geschäftsporträt der B-Seite – die Unternehmenskarte. Das Obige ist eine Einführung in die Konstruktion traditioneller Porträts durch die Ontologie. Der Wert des traditionellen Porträtkonstruktionsalgorithmus besteht darin, dass er sehr einfach, direkt, leicht verständlich und leicht zu implementieren ist. Gleichzeitig ist seine Wirkung gut, sodass er insbesondere nicht vollständig durch Algorithmen höherer Ordnung ersetzt werden kann Wenn wir das Porträt debuggen müssen, ist eine Klasse traditioneller Algorithmen praktischer.
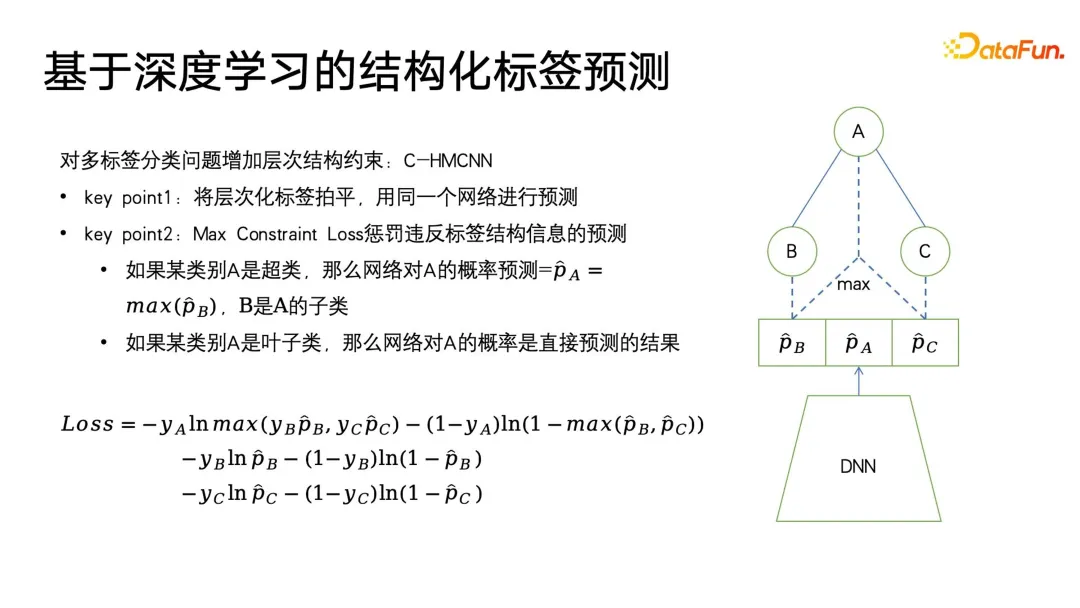
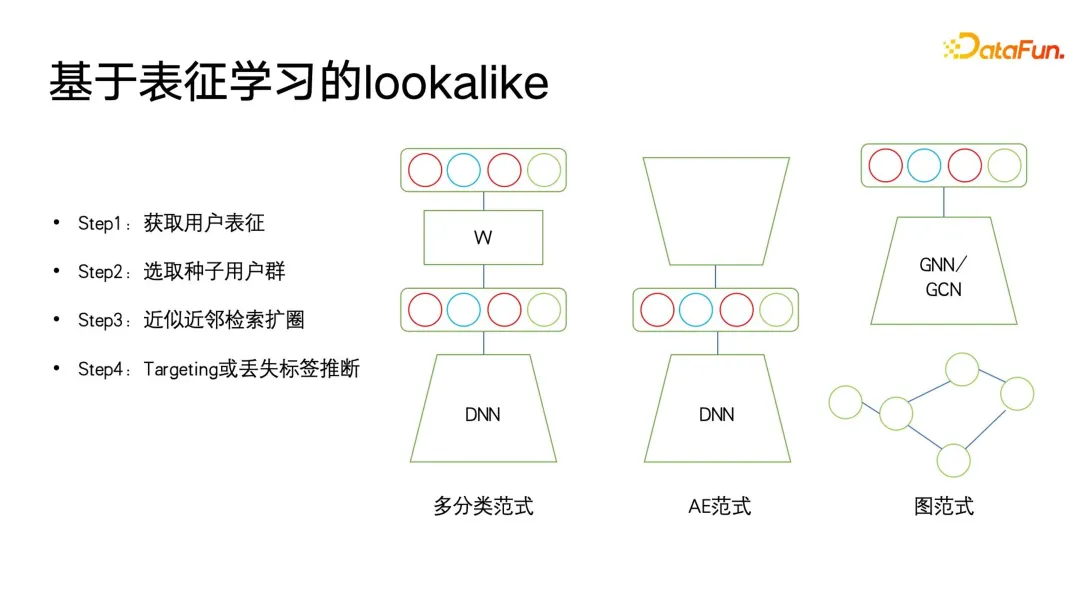
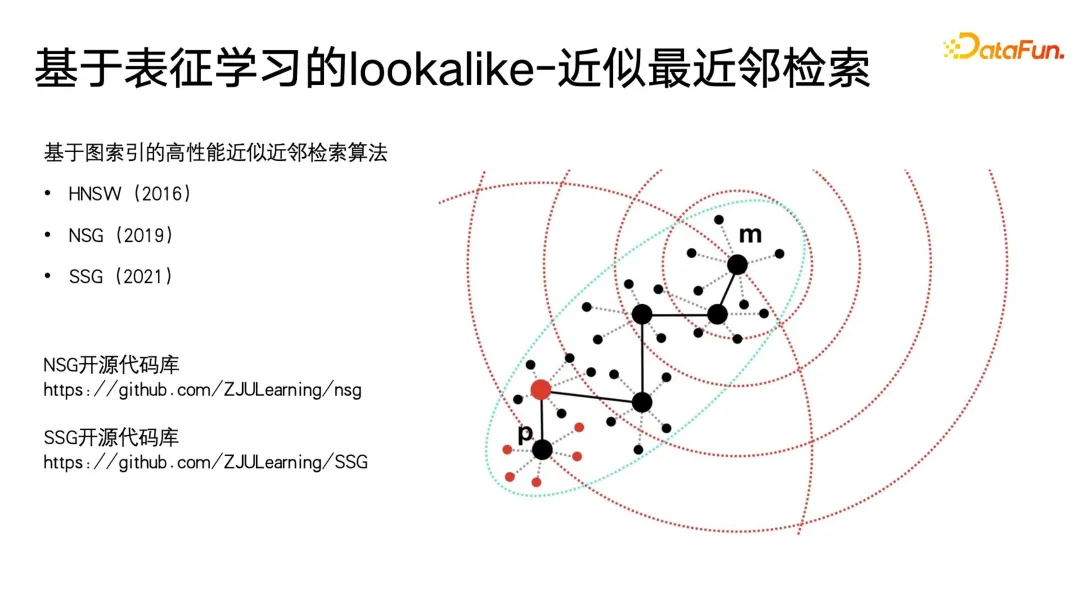
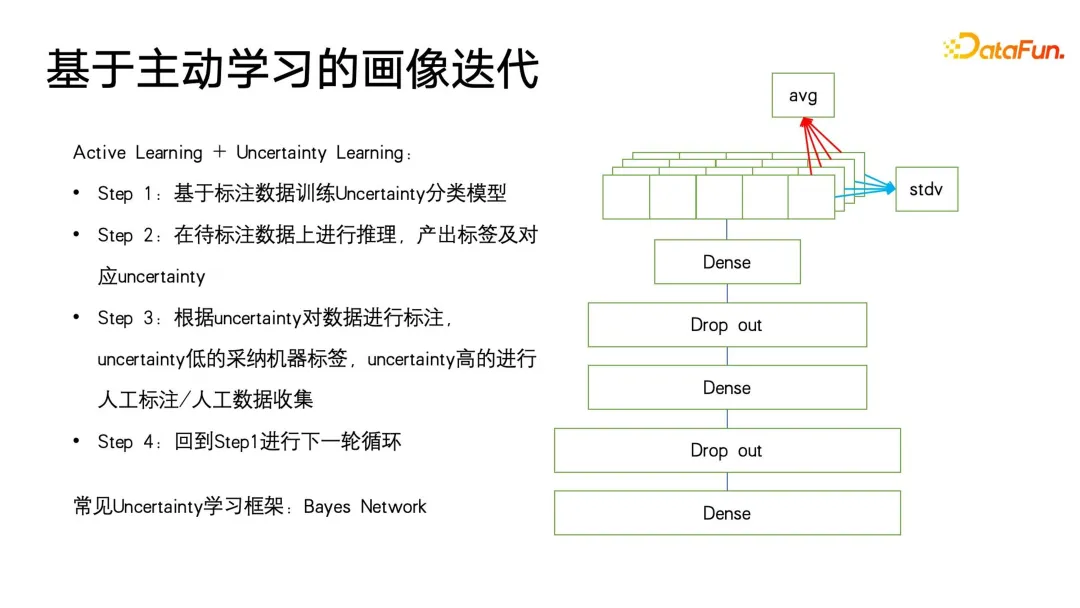
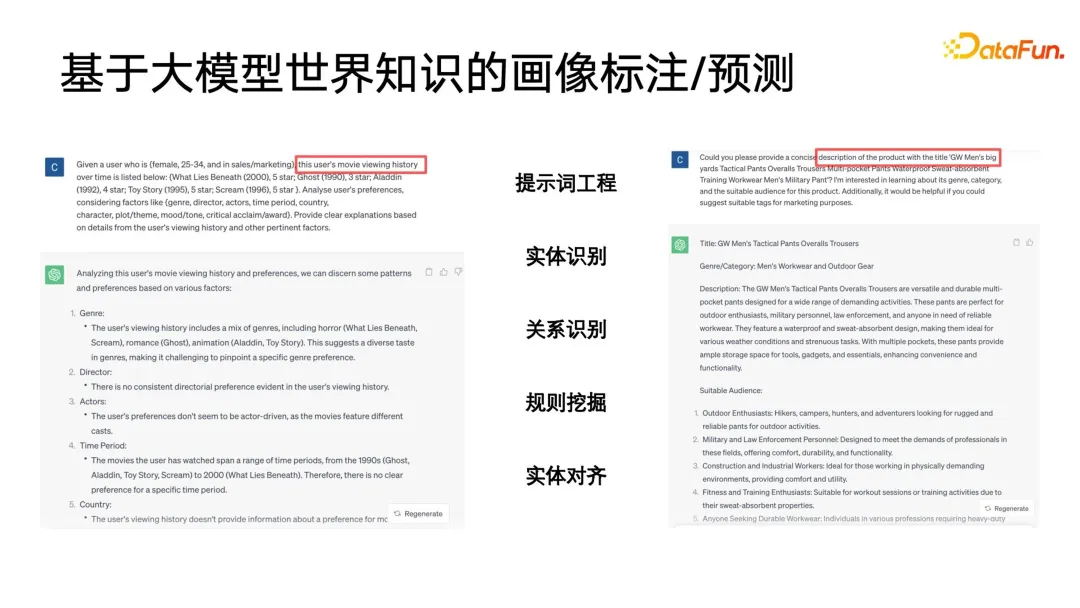
Nach dem Eintritt in die Ära des Deep Learning hofft jeder, ihn weiter zu verbessern durch die Kombination von Deep-Learning-Algorithmen Die Wirkung des Profiling-Algorithmus. Welchen Wert hat Deep Learning für Profiling-Algorithmen? Zuallererst muss es leistungsfähigere Benutzerdarstellungsfunktionen geben. Im Bereich Deep Learning und maschinelles Lernen gibt es eine spezielle Kategorie – Repräsentationslernen oder metrisches Lernen. Diese Lernmethode kann uns beim Aufbau einer sehr leistungsstarken Methode helfen Benutzervertretung. Der zweite ist ein einfacherer Modellierungsprozess. Wir können den End-to-End-Ansatz des Deep Learning verwenden, um den Modellierungsprozess zu vereinfachen. In vielen Fällen müssen wir nur Features konstruieren, einige Feature-Engineering durchführen und dann das neuronale Netzwerk behandeln Eine Blackbox ist eine Eingabe, und am Ausgang werden Beschriftungen oder andere Überwachungsinformationen definiert, ohne auf die Details zu achten. Basierend auf den leistungsstarken Ausdrucksfähigkeiten von Deep Learning haben wir bei vielen Aufgaben auch eine höhere Genauigkeit erreicht. Dann kann Deep Learning auch multimodale Daten einheitlich modellieren. Im Zeitalter traditioneller Algorithmen müssen wir viel Energie in die Datenvorverarbeitung investieren. Beispielsweise erfordert die oben erwähnte Extraktion von Videotyp-Tags eine sehr komplexe Vorverarbeitung. Schneiden Sie zuerst das Video ab, extrahieren Sie dann das Thema und identifizieren Sie es Fügen Sie die Gesichter nacheinander hinzu und erstellen Sie schließlich das Porträt. Wenn Sie mit Deep Learning einen einheitlichen Benutzer- oder Elementausdruck wünschen, können Sie multimodale Daten direkt durchgängig verarbeiten. Abschließend hoffen wir, die Kosten während der Iterationen so weit wie möglich zu senken. Wie im vorherigen Artikel erwähnt, besteht der Unterschied zwischen der Iteration von Profilierungsalgorithmen und anderen Kategorien von Algorithmusiterationen wie der Suchförderung darin, dass viel manuelle Teilnahme erforderlich ist. Manchmal sind die zuverlässigsten Daten die Daten, die von Menschen kommentiert oder durch Fragebögen und andere Methoden gesammelt werden. Die Kosten für die Beschaffung dieser Daten sind recht hoch. Wie kann man also Daten mit höherem Anmerkungswert zu geringeren Kosten erhalten? Auch für dieses Problem gibt es im Zeitalter des Deep Learning mehr Ideen und Lösungen. C-HMCNN ist eine klassische Deep-Learning-Methode zur Vorhersage strukturierter Ontologie-Labels, sondern eine geeignete Definition eines Algorithmus-Frameworks für Etiketten, insbesondere für die Klassifizierung oder Vorhersage strukturierter Etiketten. Der Kern besteht darin, hierarchisch strukturierte Tags abzuflachen und sie dann vorherzusagen. Wie auf der rechten Seite der Abbildung unten gezeigt, gibt das Netzwerk direkt die Vorhersagewahrscheinlichkeit der drei ABC-Tags an, ohne die Ebene und Tiefe der Struktur zu berücksichtigen. Das Design der Verlustformel kann auch Ergebnisse bestrafen, die strukturierte Tags so weit wie möglich verletzen. Die Formel verwendet zunächst den klassischen Kreuzentropieverlust für die Blattkategorien B und C und max(yBpB für die übergeordneten Kategorien , y CpC), um die Strukturinformationen einzuschränken und die übergeordnete Kategorie A nur dann vorherzusagen, wenn vorhergesagt wird, dass die Unterkategorie wahr ist, unter Verwendung von 1-max(pB, pC) Zum Ausdrücken, wenn die Wenn die Zielbezeichnung der übergeordneten Klasse falsch ist, wird die Vorhersage der Kategorie der Unterklasse erzwungen, so nahe wie möglich bei 0 zu liegen, wodurch Einschränkungen für strukturierte Bezeichnungen erreicht werden. Der Vorteil dieser Modellierung besteht darin, dass die Berechnung des Verlusts sehr einfach ist. Sie prognostiziert alle Etiketten gleichermaßen und kann die Tiefeninformationen des Etikettenbaums nahezu ignorieren. Das letzte, was zu erwähnen ist, ist, dass diese Methode erfordert, dass jedes Label 0 oder 1 ist. Beispielsweise stellt PB nur die Vorlieben oder Abneigungen des Benutzers dar und kann nicht auf eine Mehrfachkategorie festgelegt werden, da die LOSS-Einschränkungen von Bei der Modellierung dieses Modells entspricht dies der Reduzierung aller Beschriftungen und der anschließenden Vorhersage von 0 und 1. Ein Problem, das durch die Abflachung verursacht werden kann, besteht darin, dass, wenn das übergeordnete Etikett in der Etikettenbaumstruktur eine große Anzahl von Unteretiketten aufweist, ein sehr großes Klassifizierungsproblem mit mehreren Etiketten auftritt Wenn Sie bestimmte Mittel verwenden, um die Interessen-Tags im Voraus herauszufiltern, ist sich der Benutzer möglicherweise nicht bewusst. Bei der Anwendung von Benutzerporträts wird häufig die Idee des Lookalike verwendet. In Porträt-Downstream-Anwendungen kann Lookalike verwendet werden, um potenzielle Benutzergruppen für Werbung anzusprechen. Lookalike kann auch verwendet werden, um einige Benutzer zu finden, denen Zielattribute basierend auf Seed-Benutzern fehlen, und dann können die entsprechenden fehlenden Attribute dieser Benutzer ersetzt oder ausgedrückt werden mit Seed-Nutzern. Was die Anwendung von Lookalike am meisten benötigt, ist ein leistungsstarker Repräsentationslerner. Wie in der Abbildung unten gezeigt, gibt es drei Arten von Repräsentationsmodellierungsmethoden, die am häufigsten verwendet werden. Die erste ist eine Mehrfachklassifizierungsmethode. Wenn wir über mehrere Klassifizierungsetikettenporträtdaten verfügen, können wir gezieltere Darstellungen für einen bestimmten Etikettentyp lernen, den wir vorhersagen möchten wertvoll für gezielte Vorhersagen fehlender Etiketten. Das zweite Modell ist das AE-Modell (Auto-Encoder). Es ist nicht erforderlich, auf Überwachungsinformationen zu achten Benutzer, und dann in der Mitte der dünnen Taille Dieses Paradigma der Komprimierung von Informationen und des Erhaltens einer Darstellung ist zuverlässiger, wenn nicht genügend Überwachungsdaten vorhanden sind. Das dritte ist das Graphenparadigma. Derzeit werden Graphennetzwerke wie GNN und GCN in immer mehr Bereichen verwendet, auch in Porträts. Darüber hinaus kann GNN auf der Grundlage der Maximum-Likelihood-Methode unbeaufsichtigt trainiert werden Überwachtes Training mit Etiketteninformationen und übertrifft Multiklassifizierungsparadigmen. Denn die Diagrammstruktur kann nicht nur Beschriftungsinformationen ausdrücken, sondern auch weitere Diagrammstrukturinformationen einbetten. Wenn keine Diagrammstruktur angezeigt wird, gibt es viele Möglichkeiten, ein Diagramm zu erstellen. Swing i2i, ein bekannter Empfehlungsalgorithmus im E-Commerce-Bereich, erstellt beispielsweise ein zweiteiliges Diagramm basierend auf den gemeinsamen Einkäufen oder gemeinsamen Anzeigedatensätzen der Benutzer . Solche Diagrammstrukturen sind auch sehr umfangreich. Die semantischen Informationen können uns helfen, bessere Benutzerdarstellungen zu lernen. Nachdem wir umfassende Darstellungen haben, können wir einige Startbenutzer auswählen, um mithilfe der Suche nach nächsten Nachbarn den Kreis zu erweitern, und dann die erweiterten Benutzer verwenden, um auf die fehlenden Tags oder das Ziel zu schließen. Es ist sehr einfach, den Abruf des nächsten Nachbarn bei kleinen Anwendungen durchzuführen, aber bei extrem großen Datenmengen, wie z. B. großen Plattformen mit Hunderten Millionen monatlich aktiven Benutzern, ist die Durchführung von KNN ein Problem Der Abruf für diese Benutzer ist sehr zeitaufwändig, daher ist die derzeit am häufigsten verwendete Methode der ungefähre Abruf des nächsten Nachbarn, der sich durch den Austausch von Genauigkeit gegen Effizienz auszeichnet. Er gewährleistet eine Genauigkeit von nahezu 99 % und komprimiert gleichzeitig die Abrufzeit auf 1/. 1000, 1/1 des ursprünglichen gewaltsamen Abrufs 10000 oder sogar 1/100000. Derzeit sind Vektorabrufalgorithmen, die auf Diagrammindizes basieren, die effektivsten Methoden zum Abrufen des nächsten Nachbarn. Diese Methoden haben in der aktuellen Ära großer Modelle ihren Höhepunkt erreicht, was bei einigen großen Modellen das beliebteste Konzept ist Vor einiger Zeit. -- RAG (Retrieval Enhancement Generation) ist die Vektorabfrage. Die am häufigsten verwendete Methode ist HNSW, NSG und SSG. Die beiden letztgenannten Der ursprüngliche Open-Source-Code und der Implementierungslink sind ebenfalls in der folgenden Abbildung platziert. Im Prozess der Porträtiteration gibt es immer noch einige blinde Flecken, die nicht abgedeckt werden können. Beispielsweise sind einige Benutzerporträts mit geringem Konsumverhalten immer noch nicht abgedeckt Sehr gut. Am Ende werden viele Methoden immer noch auf manuelle Erfassungsmethoden zurückgreifen. Wir haben jedoch so viele Benutzer mit geringer Aktivität, dass wir wertvollere Daten sammeln können. Deshalb haben wir eine kostengünstige Porträtiteration zum unsicheren Lernen eingeführt . Trainieren Sie zunächst basierend auf den vorhandenen annotierten Daten ein Klassifizierungsmodell mit Unsicherheitsvorhersage. Die verwendete Methode ist die klassische Methode im Bereich des probabilistischen Lernens – das Bayesianische Netzwerk. Das Merkmal des Bayes'schen Netzwerks besteht darin, dass es bei der Vorhersage nicht nur die Wahrscheinlichkeit angeben, sondern auch die Unsicherheit des Vorhersageergebnisses vorhersagen kann. Bayesianisches Netzwerk ist sehr einfach zu implementieren, wie auf der rechten Seite der Abbildung unten gezeigt. Fügen Sie einfach einige spezielle Ebenen in der Mitte dieser Netzwerke hinzu, um sie zufällig zu löschen Feedforward-Netzwerk einige Parameter. Das Bayes'sche Netzwerk enthält mehrere Subnetzwerke, von denen jedes genau die gleichen Netzwerkparameter aufweist. Aufgrund der Eigenschaften der Dropout-Schicht ist jedoch die Wahrscheinlichkeit, dass jeder Netzwerkparameter zufällig gelöscht wird, unterschiedlich Drop-out wird auch bei der Verwendung von Drop-out beibehalten, was sich von der Verwendung von Drop-out in anderen Bereichen unterscheidet. In anderen Bereichen wird der Ausfall nur während des Trainings durchgeführt und alle Parameter werden während der Inferenz angewendet. Erst wenn die Logit- und Wahrscheinlichkeitswerte endgültig berechnet werden, wird die durch den Ausfall verursachte Skalenverdoppelung wiederhergestellt. Der Unterschied zwischen Bayes'schen Netzwerken besteht darin, dass die gesamte Drop-Out-Zufälligkeit während der Feedforward-Inferenz beibehalten werden muss, sodass jedes Netzwerk eine andere Wahrscheinlichkeit für diese Bezeichnung angibt und dann diesen Satz von Wahrscheinlichkeiten berechnet. Der Mittelwert ist tatsächlich das Ergebnis von a Abstimmung und der Wahrscheinlichkeitswert, den wir vorhersagen möchten. Gleichzeitig wird eine Varianzberechnung für diesen Satz von Wahrscheinlichkeitswerten durchgeführt, um die Unsicherheit der Vorhersage auszudrücken. Wenn eine Stichprobe unterschiedliche Drop-Out-Parameterausdrücke durchläuft, ist der endgültige Wahrscheinlichkeitswert unterschiedlich. Je größer die Varianz des Wahrscheinlichkeitswerts ist, desto geringer ist die Wahrscheinlichkeitssicherheit im Lernprozess. Schließlich können Etikettenvorhersageproben mit hoher Unsicherheit manuell etikettiert werden, und für Etiketten mit hoher Sicherheit können die Ergebnisse der maschinellen Etikettierung direkt übernommen werden. Kehren Sie dann zum ersten Schritt des aktiven Lernrahmens zurück, um den Zyklus fortzusetzen. Das Obige ist der Grundrahmen des aktiven Lernens. 5. Porträtanmerkung/Vorhersage basierend auf dem Weltwissen großer Modelle Die folgende Abbildung zeigt zwei einfache Beispiele. Ein großes Modell wird zum Kommentieren von Benutzerporträts verwendet und der Anzeigeverlauf des Benutzers wird in einer bestimmten Reihenfolge organisiert, um eine Eingabeaufforderung zu bilden Analyse, z. B. welche Genres, Regisseure, Schauspieler usw. dem Benutzer gefallen könnten. Auf der rechten Seite ist ein großes Modell zu sehen, das den Titel eines Produkts analysiert und den Produkttitel angibt, damit das große Modell erraten kann, zu welcher Kategorie es gehört.
4. Zusammenfassung und Ausblick Lassen Sie uns abschließend kurz die aktuellen Einschränkungen von Benutzerporträts und die zukünftige Entwicklungsrichtung zusammenfassen. Die erste Frage ist, wie die Genauigkeit bestehender Bilder weiter verbessert werden kann. Zu den Faktoren, die die Verbesserung der Genauigkeit behindern, gehören die folgenden Aspekte: Der erste ist die Vereinheitlichung von der virtuellen ID zur natürlichen Person. In Wirklichkeit verfügt ein Benutzer über mehrere Geräte, um sich bei demselben Konto anzumelden, und kann auch über mehrere Ports und mehrere Kanäle verfügen Zum Anmelden. Beispielsweise meldet sich ein Benutzer bei verschiedenen APPs an, diese APPs gehören jedoch zur selben Gruppe. Können wir natürliche Personen innerhalb der Gruppe verbinden, alle virtuellen IDs derselben Person zuordnen und diese dann identifizieren? Das zweite ist die Frage der Personenidentifikation für gemeinsam genutzte Familienkonten. Dieses Problem tritt im Videobereich sehr häufig auf, insbesondere im Bereich langer Videos. Beispielsweise handelt es sich bei dem Benutzer offensichtlich um einen Erwachsenen, der etwa 40 Jahre alt ist Die Familie teilt ein Konto. Persönliche Interessen sind unterschiedlich. Können wir als Reaktion auf diese Situation Mittel einsetzen, um die aktuellen Zeit- und Verhaltensmuster zu identifizieren, um das Porträt schnell und in Echtzeit zu aktualisieren, dann zu bestimmen, wer das aktuelle Motiv ist, und dann gezielte personalisierte Dienste anzubieten? Das dritte ist die Echtzeit-Absichtsvorhersage der Verknüpfung mehrerer Szenarien. Wir haben festgestellt, dass die Such- und Werbebilder der Plattform immer noch relativ fragmentiert sind. Manchmal hat ein Benutzer beispielsweise gerade eine empfohlene Szene betreten und ist nun bereit, eine bessere Suche durchzuführen Wenn Sie gerade nach empfohlenen Wörtern suchen oder gerade nach etwas gesucht haben, können Sie diese Absicht verwenden, um einige andere Kategorien von Dingen zu verbreiten und vorherzusagen, die der Benutzer möglicherweise sehen möchte Machen Sie eine Absichtsvorhersage. Der Übergang von der geschlossenen Ontologie zur offenen Ontologie ist auch im Bereich der Bildgebung ein Problem, das dringend gelöst werden muss. Lange Zeit wurden einige relativ solide Industriestandards zur Definition der Ontologie verwendet, aber jetzt ist die Ontologie vieler Systeme völlig offen für inkrementelle Aktualisierungen, wie z. B. Kurzvideoplattformen, und die verschiedenen Tags von Kurzvideobenutzern und -plattformen selbst bleiben bestehen unter der gemeinsamen Schöpfung spontan zu wachsen und zu explodieren. Es gibt viele heiße Wörter und heiße Tags, die im Laufe der Zeit immer wieder auftauchen. Wie wir die Aktualität von Bildern in der offenen Ontologie verbessern, Rauschen entfernen und dann mehr erforschen und einige Methoden verwenden können, um die Genauigkeit von Bildern zu verbessern, ist ebenfalls eine Frage, die es wert ist, untersucht zu werden. Im Zeitalter des Deep Learning schließlich wird die Frage, wie die Interpretierbarkeit von Profilierungsalgorithmen verbessert werden kann, insbesondere von Profilierungsalgorithmen, die Deep Learning anwenden, und wie große Modelle besser in Profilierungsalgorithmen implementiert werden können, die Richtungen für zukünftige Forschung sein. Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Vielen Dank an alle! A1: Der Bewerbungslink für Porträts ist tatsächlich relativ lang. Wenn Ihr Porträt hauptsächlich Algorithmen bedient, besteht tatsächlich eine Lücke im Genauigkeitsverlust zwischen der Genauigkeit des Porträts und den nachgeschalteten Modellen. Eigentlich empfehle ich nicht besonders, einen Porträt-AB-Test durchzuführen. Ich denke, eine bessere Anwendungsmethode besteht darin, sich an das Betriebspersonal zu wenden und ihn bei der Benutzerauswahl und der Werbung für Anlageinvestitionen und anderen Anwendungsszenarien zu verwenden, die operativer sind, z. B. Gutscheine für Große Verkäufe. Führen Sie AB-Tests in Szenarien wie der gezielten Lieferung durch. Da ihre Auswirkungen direkt auf Ihrem Porträt basieren, können Sie diese Art von anwendungsseitigem, kollaborativem Online-AB-Test mit einem relativ kurzen Link in Betracht ziehen. Darüber hinaus könnte ich vorschlagen, dass wir zusätzlich zum AB-Test auch eine andere Testmethode in Betracht ziehen – die Kreuzvalidierung, um einem Benutzer die Sortierergebnisse basierend auf den Bildern vor und nach der Optimierung zu empfehlen und den Benutzer dann bewerten zu lassen, welche davon geeignet ist besser. Beispielsweise können wir jetzt sehen, dass einige große Modellhersteller das Modell zwei Ergebnisse ausgeben lassen und dann den Benutzern die Entscheidung überlassen, welches große Modell besseren Text erzeugt. Tatsächlich denke ich, dass eine solche Gegenprüfung effektiver sein könnte und in direktem Zusammenhang mit dem Porträt selbst steht. A2: Dies bedeutet nicht, dass es im Testsatz einen Ausfall gibt, aber es bedeutet, dass wir beim Testen der Inferenz weiterhin die zufälligen Merkmale des Ausfalls im Netzwerk für zufällige Inferenz beibehalten. A3: Ehrlich gesagt gibt es in der Branche derzeit keine sehr gute Lösung. Es gibt jedoch zwei Möglichkeiten, einen gegenseitig vertrauenswürdigen Dritten für die Inferenzbereitstellung lokalisierter großer Modelle in Betracht zu ziehen. Ein weiteres, ebenfalls neues Konzept heißt „Federated Network“, was nicht „Federated Learning“ ist. Sie können einen Blick auf einige der Möglichkeiten werfen, die in „Federated Networks“ enthalten sind. A4: Zusätzlich zu den Anmerkungen gibt es auch einige Analysen und Argumente von Benutzern. Basierend auf vorhandenen Porträts können wir auf die nächste Absicht des Benutzers schließen oder eine große Menge an Benutzerdaten sammeln und ein großes Modell verwenden, um einige regionale oder andere Benutzermuster unter Einschränkungen zu analysieren. Tatsächlich gibt es dafür einige Open-Source-Demos, Sie können diese Richtung erkunden. 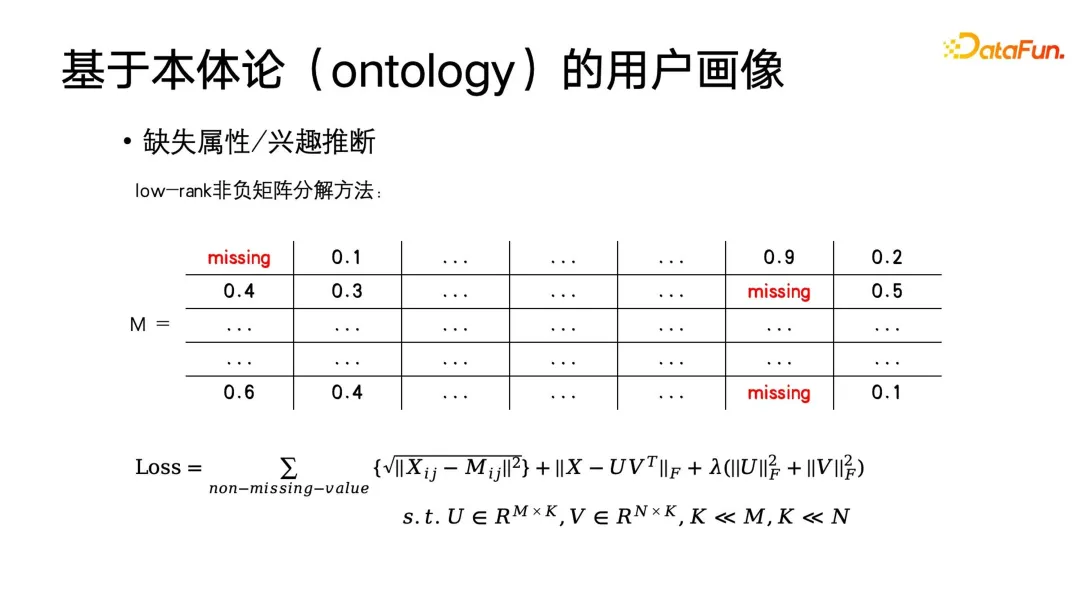

3. Profiling-Algorithmus und Deep Learning
1. Der Wert des Deep-Learning-Algorithmus für den Profiling-Algorithmus

2. Strukturierte Label-Vorhersage basierend auf Deep Learning
3. Lookalike basierend auf Repräsentationslernen
4. Porträtiteration basierend auf aktivem Lernen
 An diesem Punkt haben wir festgestellt, dass ein großes Problem darin besteht, dass die Ausgabe des großen Modells unstrukturiert ist, ein relativ primitiver Textausdruck ist und eine gewisse Nachbearbeitung erfordert. Beispielsweise ist es erforderlich, Entitätserkennung, Beziehungserkennung, Rule Mining, Entitätsausrichtung usw. an der Ausgabe eines großen Modells durchzuführen, und diese Nachbearbeitung gehört zu den grundlegenden Anwendungsregeln in der Kategorie Wissensgraph oder Ontologie.
An diesem Punkt haben wir festgestellt, dass ein großes Problem darin besteht, dass die Ausgabe des großen Modells unstrukturiert ist, ein relativ primitiver Textausdruck ist und eine gewisse Nachbearbeitung erfordert. Beispielsweise ist es erforderlich, Entitätserkennung, Beziehungserkennung, Rule Mining, Entitätsausrichtung usw. an der Ausgabe eines großen Modells durchzuführen, und diese Nachbearbeitung gehört zu den grundlegenden Anwendungsregeln in der Kategorie Wissensgraph oder Ontologie.
Warum führt die Nutzung des Weltwissens über große Modelle zur Bildanmerkung zu besseren Ergebnissen und kann sogar einen Teil der Arbeit ersetzen? Da große Modelle auf einem breiten Spektrum offener Netzwerkkenntnisse basieren, verfügen Empfehlungssysteme, Suchmaschinen usw. nur über einige historische Interaktionsdaten zwischen Benutzern und Produktbibliotheken in ihren eigenen geschlossenen Plattformen Viele davon hängen miteinander zusammen und sind durch das geschlossene Wissen in der vorhandenen Plattform schwer zu interpretieren. Das Weltwissen des großen Modells kann uns jedoch dabei helfen, das im geschlossenen System fehlende Wissen zu ergänzen und so ein besseres Ergebnis zu erzielen Porträtbeschriftung oder -vorhersage. Das große Modell kann sogar als hochwertige abstrakte Darstellung des Begriffssystems der Welt selbst verstanden werden. Diese Begriffssysteme eignen sich sehr gut für Porträts und Beschriftungssysteme.

5. Fragen und Antworten
Frage 1: Die Verbindung zwischen der Porträtverarbeitung und der praktischen Anwendung kann sehr langwierig sein, was die Akzeptanz des AB-Tests in der Praxis betrifft. Bitte fragen Sie Herrn Fu Cong Haben Sie Erfahrungen zum AB-Test von Porträts?
F2: Gibt es Aussetzer beim Testsatz für das Bayes-Netzwerk?
F3: Unter Berücksichtigung von Datenschutz- und Sicherheitsproblemen: Wie können die Ergebnisse großer Modelle genutzt werden, wenn Kundendaten nicht exportiert werden können?
F4: Gibt es neben der Beschriftung noch weitere Kombinationen, die Sie in Kombination mit großen Modellen erwähnen können?
Das obige ist der detaillierte Inhalt vonAlgorithmen zur Benutzerprofilierung: Geschichte, aktuelle Situation und Zukunft. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Aktueller Bitcoin-Preistrend
Aktueller Bitcoin-Preistrend
 Was bedeutet OEM?
Was bedeutet OEM?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



