


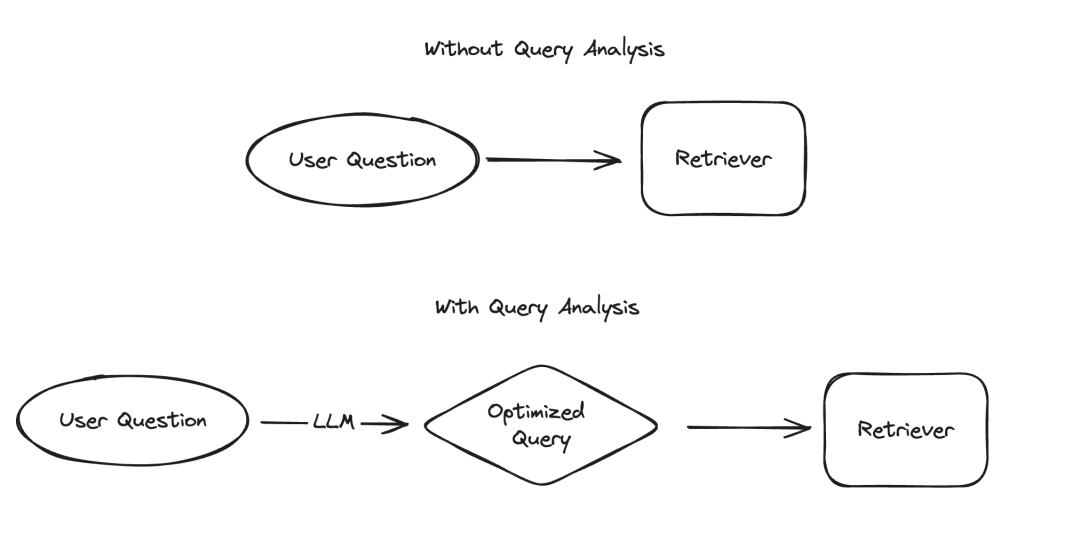
Bei der Anwendung großer Sprachmodelle (LLM) gibt es mehrere Szenarien, die eine strukturierte Darstellung von Daten erfordern, wobei Informationsextraktion und Abfrageanalyse zwei typische Beispiele sind. Wir haben kürzlich die Bedeutung der Informationsextraktion mit aktualisierter Dokumentation und einem speziellen Code-Repository hervorgehoben. Für die Abfrageanalyse haben wir auch die zugehörige Dokumentation aktualisiert. In diesen Szenarien können Datenfelder Zeichenfolgen, boolesche Werte, Ganzzahlen usw. enthalten. Unter diesen Typen ist der Umgang mit kategorialen Werten mit hoher Kardinalität (d. h. Aufzählungstypen) die größte Herausforderung.
 Bilder
Bilder
Die sogenannten „Gruppierungswerte mit hoher Kardinalität“ beziehen sich auf Werte, die aus begrenzten Optionen ausgewählt werden müssen. Diese Werte können nicht willkürlich angegeben werden, sondern müssen aus einem vordefinierten Satz stammen. In einer solchen Menge gibt es manchmal eine sehr große Anzahl gültiger Werte, die wir „Werte mit hoher Kardinalität“ nennen. Der Grund, warum der Umgang mit solchen Werten schwierig ist, liegt darin, dass LLM selbst nicht weiß, was diese realisierbaren Werte sind. Daher müssen wir LLM Informationen über diese realisierbaren Werte zur Verfügung stellen. Selbst wenn wir den Fall ignorieren, dass es nur wenige mögliche Werte gibt, können wir dieses Problem dennoch lösen, indem wir diese möglichen Werte im Hinweis explizit auflisten. Das Problem wird jedoch komplizierter, da es so viele mögliche Werte gibt.
Mit zunehmender Anzahl möglicher Werte steigt auch die Schwierigkeit, LLM-Werte auszuwählen. Wenn einerseits zu viele mögliche Werte vorhanden sind, passen diese möglicherweise nicht in das Kontextfenster des LLM. Selbst wenn andererseits alle möglichen Werte in den Kontext passen, führt die Einbeziehung aller Werte zu einer langsameren Verarbeitung, höheren Kosten und verringerten LLM-Argumentationsfähigkeiten beim Umgang mit großen Kontextmengen. „Mit zunehmender Anzahl möglicher Werte nimmt die Schwierigkeit bei der LLM-Auswahl von Werten zu.“ Wenn einerseits zu viele mögliche Werte vorhanden sind, passen diese möglicherweise nicht in das Kontextfenster des LLM. Selbst wenn andererseits alle möglichen Werte in den Kontext passen, führt die Einbeziehung aller Werte zu einer langsameren Verarbeitung, höheren Kosten und verringerten LLM-Argumentationsfähigkeiten beim Umgang mit großen Kontextmengen. ` (Hinweis: Der Originaltext scheint URL-codiert zu sein. Ich habe die Codierung korrigiert und den umgeschriebenen Text bereitgestellt.)
Kürzlich haben wir eine eingehende Untersuchung der Abfrageanalyse durchgeführt und bei der Überarbeitung der relevanten Dokumentation hinzugefügt Ein spezieller Abschnitt zum Umgang damit. Seiten mit hohen Kardinalitätswerten. In diesem Blog werden wir uns mit mehreren experimentellen Ansätzen befassen und deren Ergebnisse zum Leistungsbenchmark bereitstellen.
Eine Übersicht der Ergebnisse kann bei LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev eingesehen werden. Als nächstes stellen wir im Detail vor:
 Bilder
Bilder
Der detaillierte Datensatz kann hier eingesehen werden https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc -d7def170be76 /d?ref=blog.langchain.dev.
Um dieses Problem zu simulieren, gehen wir von einem Szenario aus: Wir möchten Bücher über Außerirdische von einem bestimmten Autor finden. In diesem Szenario handelt es sich beim Writer-Feld um eine kategoriale Variable mit hoher Kardinalität. Es gibt viele mögliche Werte, diese sollten jedoch bestimmte gültige Writer-Namen sein. Um dies zu testen, haben wir einen Datensatz erstellt, der Autorennamen und gängige Aliase enthält. „Harry Chase“ könnte beispielsweise ein Alias für „Harrison Chase“ sein. Wir wollen, dass intelligente Systeme mit dieser Art von Aliasing umgehen können. In diesem Datensatz haben wir einen Datensatz erstellt, der eine Liste der Namen und Aliase der Autoren enthält. Beachten Sie, dass 10.000 zufällige Namen nicht zu viel sind – bei Systemen auf Unternehmensebene müssen Sie möglicherweise mit Kardinalitäten in Millionenhöhe rechnen.
Anhand dieses Datensatzes stellen wir die Frage: „Was sind Harry Chases Bücher über Außerirdische?“ Unser Abfrageanalysesystem sollte in der Lage sein, diese Frage in ein strukturiertes Format zu analysieren, das zwei Felder enthält: Thema und Autor. In diesem Beispiel wäre die erwartete Ausgabe {"topic": "aliens", "author": "Harrison Chase"}. Wir gehen davon aus, dass das System erkennt, dass es keinen Autor namens Harry Chase gibt, der Benutzer meinte jedoch möglicherweise Harrison Chase.
Mit diesem Setup können wir den von uns erstellten Alias-Datensatz testen, um zu überprüfen, ob er korrekt mit echten Namen übereinstimmt. Gleichzeitig erfassen wir auch die Latenz und die Kosten der Abfrage. Diese Art von Abfrageanalysesystem wird normalerweise für die Suche verwendet, daher sind wir über diese beiden Indikatoren sehr besorgt. Aus diesem Grund beschränken wir auch alle Methoden auf nur einen LLM-Aufruf. Möglicherweise werden wir in einem zukünftigen Artikel Methoden mit mehreren LLM-Aufrufen vergleichen.
Als nächstes stellen wir verschiedene Methoden und deren Leistung vor.
 Bilder
Bilder
Die vollständigen Ergebnisse können in LangSmith eingesehen werden, und den Code zum Reproduzieren dieser Ergebnisse finden Sie hier.
Zuerst führten wir einen Basistest für LLM durch, das heißt, wir forderten LLM direkt auf, eine Abfrageanalyse durchzuführen, ohne gültige Namensinformationen anzugeben. Wie erwartet wurde keine einzige Frage richtig beantwortet. Dies liegt daran, dass wir absichtlich einen Datensatz erstellt haben, der die Abfrage der Autoren nach Alias erfordert.
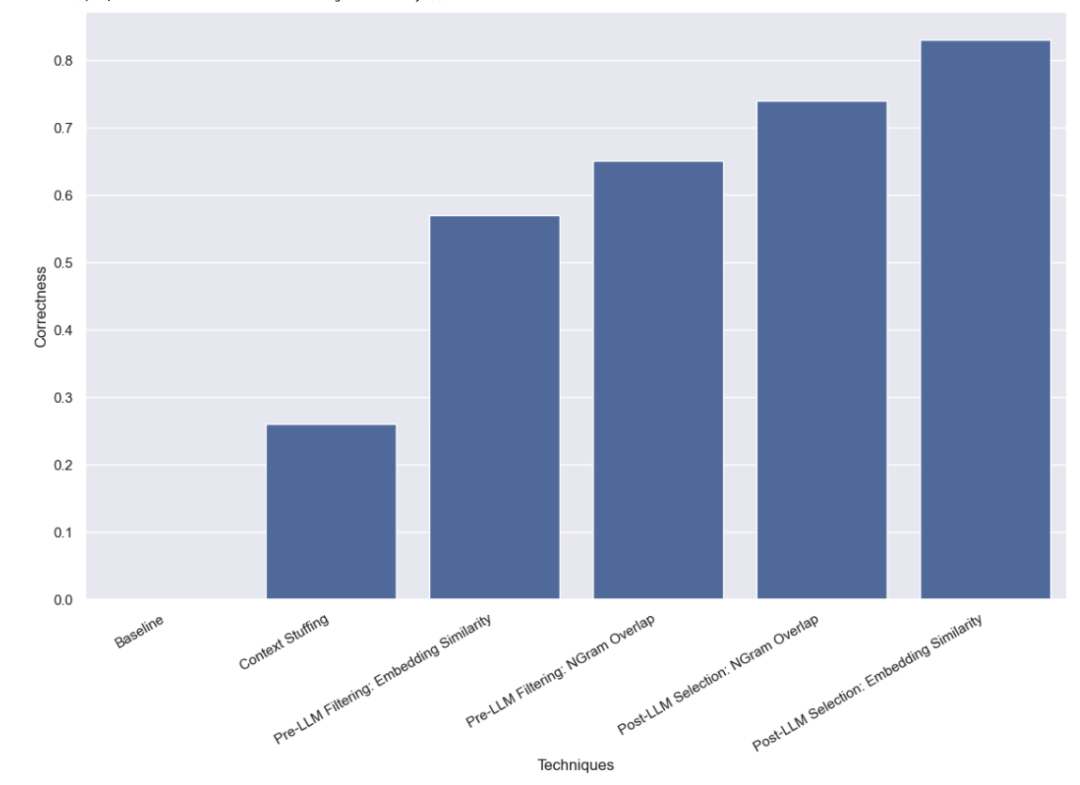
Bei dieser Methode geben wir alle 10.000 legalen Autorennamen in die Eingabeaufforderung ein und bitten LLM, sich bei der Abfrageanalyse daran zu erinnern, dass es sich um legale Autorennamen handelt. Einige Modelle (z. B. GPT-3.5) können diese Aufgabe aufgrund der Einschränkungen des Kontextfensters einfach nicht ausführen. Bei anderen Modellen mit längeren Kontextfenstern hatten sie ebenfalls Schwierigkeiten, den richtigen Namen genau auszuwählen. GPT-4 wählte nur in 26 % der Fälle den richtigen Namen. Der häufigste Fehler besteht darin, Namen zu extrahieren, sie aber nicht zu korrigieren. Diese Methode ist nicht nur langsam, sondern auch teuer: Sie dauert durchschnittlich 5 Sekunden und kostet insgesamt 8,44 US-Dollar.
Die Methode, die wir als Nächstes getestet haben, besteht darin, die Liste möglicher Werte zu filtern, bevor sie an das LLM übergeben wird. Dies hat den Vorteil, dass nur eine Teilmenge der möglichen Namen an LLM übergeben wird, sodass LLM weitaus weniger Namen berücksichtigen muss, was hoffentlich eine schnellere, kostengünstigere und genauere Durchführung der Abfrageanalyse ermöglicht. Dies führt jedoch auch zu einem neuen potenziellen Fehlermodus: Was passiert, wenn die anfängliche Filterung schief geht?
Die Filtermethode, die wir ursprünglich verwendet haben, war die Einbettungsmethode und wählte die 10 Namen aus, die der Abfrage am ähnlichsten sind. Beachten Sie, dass wir die gesamte Abfrage mit dem Namen vergleichen, was kein idealer Vergleich ist!
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 57 % der Fälle korrekt verarbeiten konnte. Diese Methode ist viel schneller und kostengünstiger als frühere Methoden und dauert durchschnittlich nur 0,76 Sekunden, wobei die Gesamtkosten nur 0,002 US-Dollar betragen.
Die zweite Filtermethode, die wir verwenden, besteht darin, die 3-Gramm-Zeichenfolge aller gültigen Namen mit TF-IDF zu vektorisieren und die vektorisierten gültigen Namen mit der vektorisierten Kosinusähnlichkeit zwischen Benutzereingaben zu verwenden wird verwendet, um die relevantesten 10 gültigen Namen auszuwählen, die den Modelleingabeaufforderungen hinzugefügt werden sollen. Beachten Sie außerdem, dass wir die gesamte Abfrage mit dem Namen vergleichen, was kein idealer Vergleich ist!
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 65 % der Fälle korrekt bearbeiten konnte. Diese Methode ist außerdem viel schneller und kostengünstiger als frühere Methoden, da sie durchschnittlich nur 0,57 Sekunden in Anspruch nimmt und die Gesamtkosten nur 0,002 US-Dollar betragen.
Die letzte von uns getestete Methode bestand darin, zu versuchen, etwaige Fehler zu korrigieren, nachdem LLM die vorläufige Abfrageanalyse abgeschlossen hatte. Wir haben zunächst eine Abfrageanalyse für Benutzereingaben durchgeführt, ohne in der Eingabeaufforderung Informationen zu gültigen Autorennamen anzugeben. Dies ist derselbe Basistest, den wir ursprünglich durchgeführt haben. Anschließend führten wir einen weiteren Schritt durch, bei dem wir die Namen im Feld „Autor“ verwendeten und den ähnlichsten gültigen Namen suchten.
Zuerst führten wir eine Ähnlichkeitsprüfung mit der Einbettungsmethode durch.
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 83 % der Fälle korrekt bearbeiten konnte. Diese Methode ist viel schneller und kostengünstiger als frühere Methoden, sie dauert durchschnittlich nur 0,66 Sekunden und die Gesamtkosten betragen nur 0,001 $.
Abschließend versuchen wir, einen 3-Gramm-Vektorisierer zur Ähnlichkeitsprüfung zu verwenden.
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 74 % der Fälle korrekt bearbeiten konnte. Diese Methode ist außerdem viel schneller und kostengünstiger als frühere Methoden, da sie durchschnittlich nur 0,48 Sekunden in Anspruch nimmt und die Gesamtkosten nur 0,001 US-Dollar betragen.
Wir haben mehrere Benchmarks zu Abfrageanalysemethoden für den Umgang mit kategorialen Werten mit hoher Kardinalität durchgeführt. Wir haben uns darauf beschränkt, nur einen LLM-Aufruf durchzuführen, um reale Latenzbeschränkungen zu simulieren. Wir haben festgestellt, dass die Einbettung ähnlichkeitsbasierter Auswahlmethoden nach der Verwendung von LLM am besten funktioniert.
Es gibt andere Methoden, die es wert sind, weiter getestet zu werden. Insbesondere gibt es viele verschiedene Möglichkeiten, den ähnlichsten kategorialen Wert vor oder nach dem LLM-Aufruf zu finden. Darüber hinaus ist die Kategoriebasis in diesem Datensatz nicht so hoch wie in vielen Unternehmenssystemen. Dieser Datensatz verfügt über etwa 10.000 Werte, während viele reale Systeme möglicherweise Kardinalitäten in Millionenhöhe verarbeiten müssen. Daher wäre ein Benchmarking anhand von Daten mit höherer Kardinalität sehr wertvoll.
Das obige ist der detaillierte Inhalt vonPraktische Leistungsbewertung für LLM-Abfragen mit extrem langem Kontext. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



