


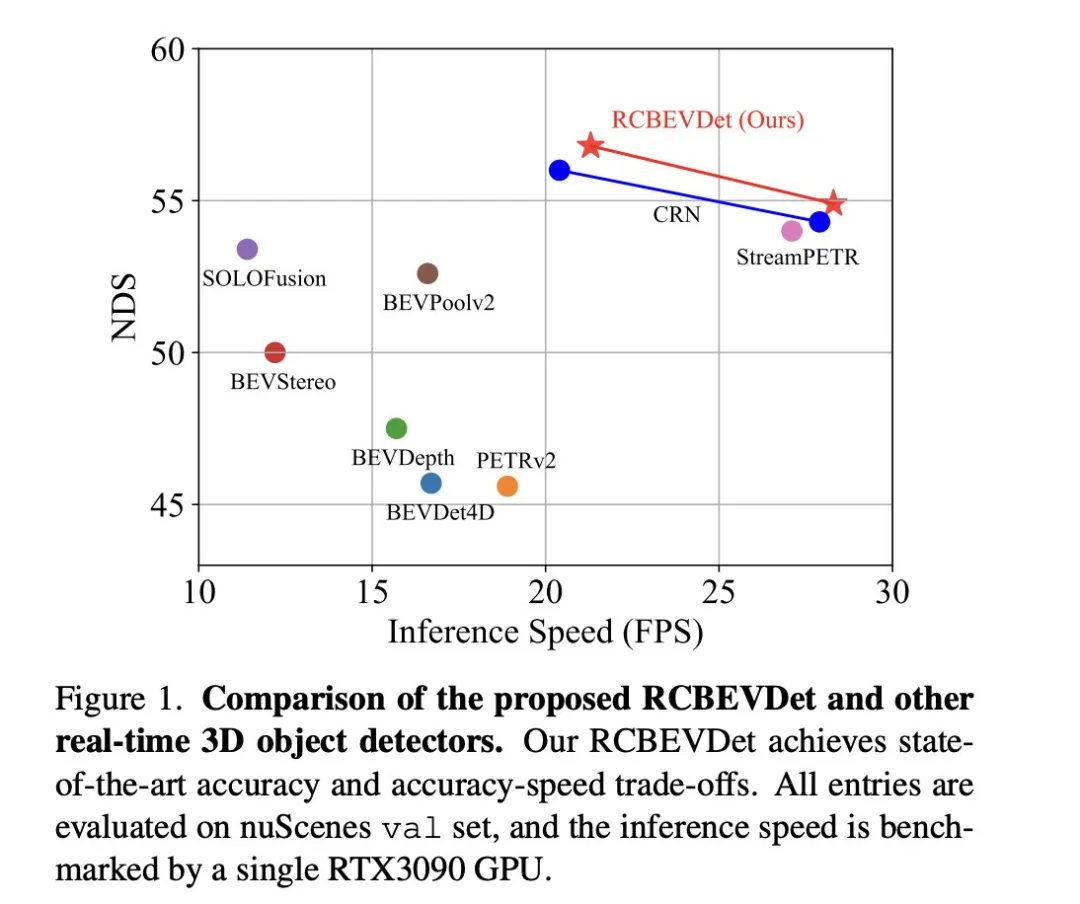
Das Hauptthema, auf das sich dieses Diskussionspapier konzentriert, ist die Anwendung der 3D-Zielerkennungstechnologie im Prozess des autonomen Fahrens. Obwohl die Entwicklung der Umgebungskameratechnologie hochauflösende semantische Informationen für die 3D-Objekterkennung liefert, ist diese Methode durch Probleme wie die Unfähigkeit, Tiefeninformationen genau zu erfassen, und schlechte Leistung bei schlechtem Wetter oder schlechten Lichtverhältnissen eingeschränkt. Als Reaktion auf dieses Problem wurde in der Diskussion eine neue Multimode-3D-Zielerkennungsmethode RCBEVDet vorgeschlagen, die Rundumsichtkameras und kostengünstige Millimeterwellenradarsensoren kombiniert. Diese Methode bietet umfangreichere semantische Informationen und eine Lösung für Probleme wie schlechte Leistung bei schlechtem Wetter oder schlechten Lichtverhältnissen, indem sie Informationen von mehreren Sensoren umfassend nutzt. Als Reaktion auf dieses Problem wurde in der Diskussion eine neue Multimode-3D-Zielerkennungsmethode RCBEVDet vorgeschlagen, die Rundumsichtkameras und kostengünstige Millimeterwellenradarsensoren kombiniert. Durch die umfassende Nutzung von Informationen von Multimode-Sensoren ist RCBEVDet in der Lage, hochauflösende semantische Informationen bereitzustellen und eine gute Leistung bei schlechtem Wetter oder schlechten Lichtverhältnissen zu zeigen. Der Kern dieser Methode zur Verbesserung des automatischen
RCBEVDet liegt in zwei Schlüsseldesigns: RadarBEVNet und Cross-Attention+Multi-Layer Fusion Module (CAMF). RadarBEVNet wurde für die effiziente Extraktion von Radarfunktionen entwickelt und umfasst einen Dual-Stream-Radar-Backbone-Netzwerk-RCS-Encoder (Radar Cross Section), der BEV-Encoder (Bird's Eye View) erkennt. Ein solches Design verwendet punktwolkenbasierte und transformatorbasierte Encoder, um Radarpunkte zu verarbeiten, Radarpunktmerkmale interaktiv zu aktualisieren und Radar-spezifische RCS-Eigenschaften als vorherige Informationen über die Zielgröße zu verwenden, um die Punktmerkmalsverteilung im BEV-Raum zu optimieren. Das CAMF-Modul löst das Azimutfehlerproblem von Radarpunkten durch einen multimodalen Kreuzaufmerksamkeitsmechanismus und erreicht eine dynamische Ausrichtung von BEV-Feature-Maps von Radar und Kameras sowie eine adaptive Fusion multimodaler Features durch Kanal- und räumliche Fusion. In der Implementierung wird die Punktmerkmalsverteilung im BEV-Raum optimiert, indem die Radarpunktmerkmale interaktiv aktualisiert werden und die Radar-spezifischen RCS-Eigenschaften als vorherige Informationen über die Zielgröße verwendet werden. Das CAMF-Modul löst das Azimutfehlerproblem von Radarpunkten durch einen multimodalen Kreuzaufmerksamkeitsmechanismus und erreicht eine dynamische Ausrichtung von BEV-Feature-Maps von Radar und Kameras sowie eine adaptive Fusion multimodaler Features durch Kanal- und räumliche Fusion.
Die im Artikel vorgeschlagene neue Methode löst die bestehenden Probleme durch die folgenden Punkte:
Die Hauptbeiträge des Papiers sind wie folgt:
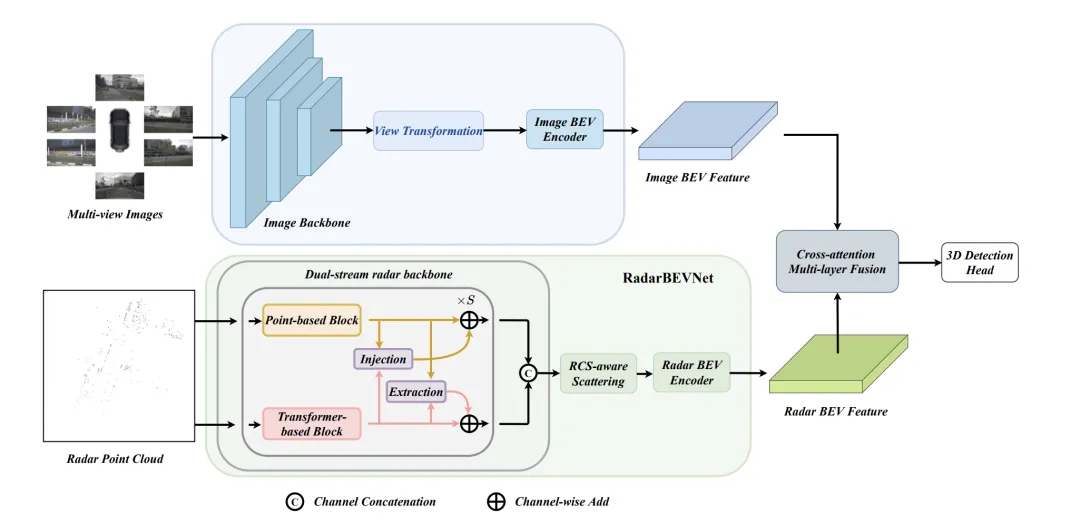
RadarBEVNet ist eine in diesem Dokument vorgeschlagene Netzwerkarchitektur für die effektive Extraktion von BEV-Funktionen (Vogelansicht). Sie umfasst hauptsächlich zwei Kernkomponenten: Dual-Stream Radar-Backbone-Netzwerk und RCS (Radar Cross Section) fähiger BEV-Encoder. Ein Dual-Stream-Radar-Backbone-Netzwerk wird verwendet, um umfangreiche Merkmalsdarstellungen aus Mehrkanal-Radardaten zu extrahieren. Es basiert auf einem Deep Convolutional Neural Network (CNN), das zwischen verschachtelten Faltungs- und Pooling-Schichten für Merkmalsextraktions- und Dimensionsreduktionsoperationen wechselt, um schrittweise das Dual-Stream-Radar-Backbone zu erhalten. Das Backbone-Netzwerk besteht aus punktbasierten Backbones und Konvertern -basierte Rückgrate. Das punktbasierte Backbone-Netzwerk lernt Radarmerkmale durch Multi-Layer-Perceptron (MLP) und Maximum-Pooling-Operationen. Der Prozess kann auf die folgende Formel vereinfacht werden:
Um das durch herkömmliche Radar-BEV-Encoder verursachte BEV-Feature-Sparsity-Problem zu lösen, wird ein RCS-fähiger BEV-Encoder vorgeschlagen. Es nutzt RCS als vorherige Information über die Zielgröße und verteilt Radarpunktmerkmale auf mehrere Pixel im BEV-Raum statt auf ein einzelnes Pixel, um die Dichte der BEV-Merkmale zu erhöhen. Dieser Prozess wird durch die folgende Formel implementiert:
Wobei ist die auf RCS basierende Gaußsche BEV-Gewichtskarte, die durch Maximierung der Gewichtungskarte aller Radarpunkte optimiert wird. Schließlich werden die durch RCS-Spreizung erhaltenen Merkmale von MLP verbunden und verarbeitet, um die endgültigen RCS-fähigen BEV-Merkmale zu erhalten.
Insgesamt extrahiert RadarBEVNet die Merkmale von Radardaten effizient durch die Kombination des Dual-Stream-Radar-Backbone-Netzwerks und des RCS-fähigen BEV-Encoders und verwendet RCS als a priori der Zielgröße, um die Merkmalsverteilung des BEV-Raums zu optimieren Eine Grundlage für die anschließende multimodale Fusion bietet ein starkes Fundament.
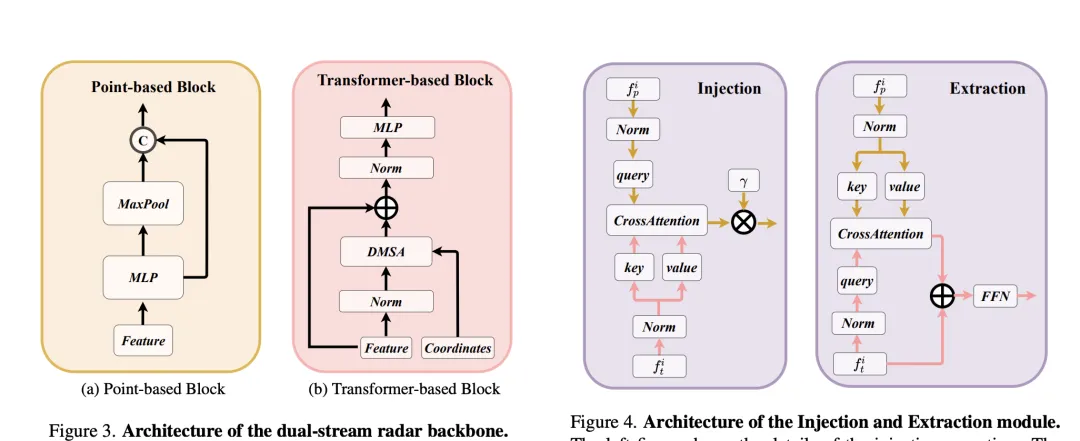
Cross-Attention Multi-layer Fusion Module (CAMF) ist eine fortschrittliche Netzwerkstruktur für die dynamische Ausrichtung und Fusion multimodaler Features, insbesondere für Radar und dynamische Ausrichtung und Fusionsdesign von kameragenerierten Bird's Eye View (BEV)-Funktionen. Dieses Modul löst hauptsächlich das Problem der Merkmalsfehlausrichtung, die durch den Azimutfehler von Radarpunktwolken verursacht wird. Durch den verformbaren Kreuzaufmerksamkeitsmechanismus (Deformable Cross-Attention) werden kleine Abweichungen von Radarpunkten effektiv erfasst und die Standardkreuzaufmerksamkeit reduziert. Rechenkomplexität.
CAMF nutzt einen deformierten Kreuzaufmerksamkeitsmechanismus, um die BEV-Funktionen von Kameras und Radargeräten auszurichten. Bei einer Summe von BEV-Funktionen für eine Kamera und ein Radar werden zunächst lernbare Positionseinbettungen zur Summe addiert und dann als Schlüssel und Werte in Abfrage- und Referenzpunkte umgewandelt. Die Berechnung der Queraufmerksamkeit durch Mehrkopfverformung kann wie folgt ausgedrückt werden:
wobei der Index des Aufmerksamkeitskopfes, der Index des Abtastschlüssels und die Gesamtzahl der Abtastschlüssel angegeben sind. stellt den Sampling-Offset dar und ist das von und berechnete Aufmerksamkeitsgewicht.
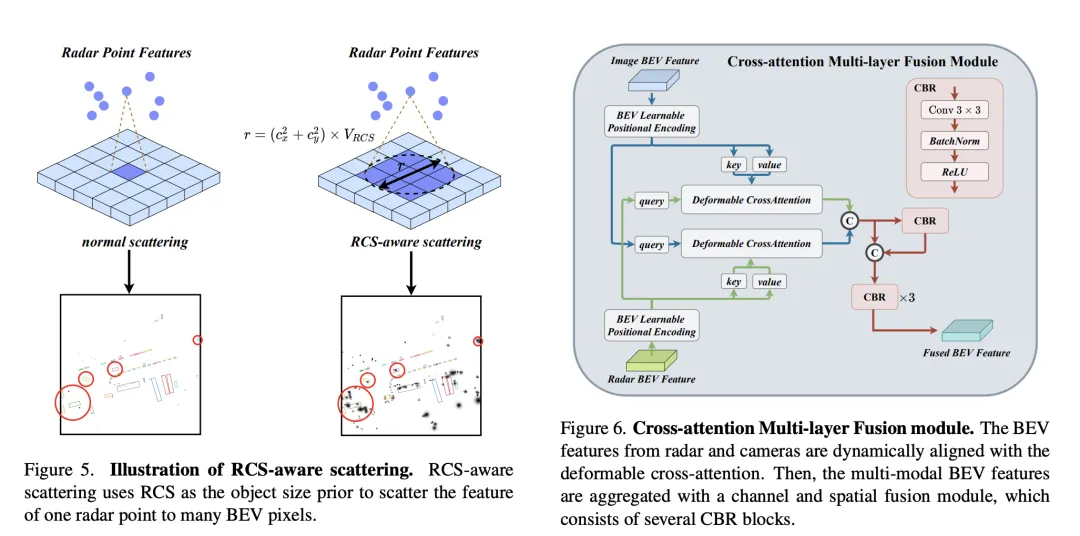
Nachdem CAMF die BEV-Funktionen von Kamera und Radar durch Kreuzaufmerksamkeit ausgerichtet hat, verwendet CAMF Kanal- und räumliche Fusionsschichten, um multimodale BEV-Funktionen zu aggregieren. Insbesondere werden zwei BEV-Merkmale zunächst verkettet und dann in den CBR-Block (Faltungs-Batch-Normalisierungs-Aktivierungsfunktion) eingespeist, und die fusionierten Merkmale werden durch Restverbindung erhalten. Der CBR-Block besteht nacheinander aus einer Faltungsschicht, einer Batch-Normalisierungsschicht und einer ReLU-Aktivierungsfunktion. Danach werden drei CBR-Blöcke nacheinander angewendet, um multimodale Merkmale weiter zu verschmelzen.
Durch den oben genannten Prozess erreicht CAMF effektiv eine präzise Ausrichtung und effiziente Fusion von Radar- und Kamera-BEV-Funktionen, stellt umfangreiche und genaue Funktionsinformationen für die 3D-Zielerkennung bereit und verbessert so die Erkennungsleistung.
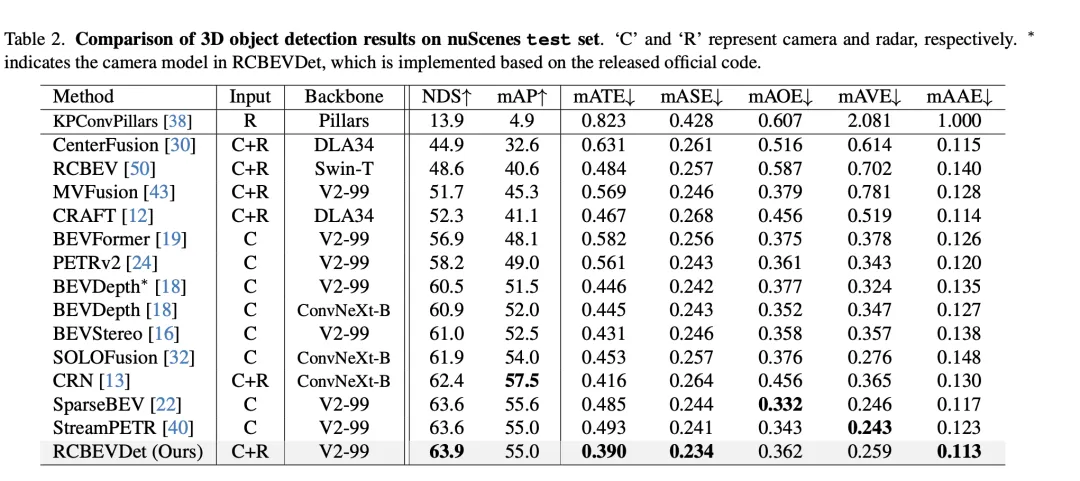
Beim Vergleich der 3D-Zielerkennungsergebnisse im VoD-Validierungssatz erreichte RadarBEVNet durch die Fusion von Kamera und durchschnittlicher Genauigkeit (mAP) sowohl im gesamten Annotationsbereich als auch im interessierenden Bereich Radardaten zeigten eine hervorragende Leistung. Insbesondere für den gesamten kommentierten Bereich erreichte RadarBEVNet AP-Werte von 40,63 %, 38,86 % bzw. 70,48 % bei der Erkennung von Autos, Fußgängern und Radfahrern, wodurch sich der umfassende mAP auf 49,99 % erhöhte. Im interessierenden Bereich, also im fahrzeugnahen Fahrkanal, ist die Leistung von RadarBEVNet noch herausragender und erreicht AP-Werte von 72,48 %, 49,89 % und 87,01 % bei der Erkennung von Autos, Fußgängern usw Radfahrer und die umfassende Karte erreichte 69,80 %.
Diese Ergebnisse offenbaren mehrere wichtige Punkte. Erstens ist RadarBEVNet durch die effektive Zusammenführung von Kamera- und Radareingängen in der Lage, die komplementären Vorteile der beiden Sensoren voll auszunutzen und die Gesamterkennungsleistung zu verbessern. Im Vergleich zu Methoden, die nur Radar verwenden, wie PointPillar und RadarPillarNet, weist RadarBEVNet eine deutliche Verbesserung des umfassenden mAP auf, was zeigt, dass die multimodale Fusion besonders wichtig ist, um die Erkennungsgenauigkeit zu verbessern. Zweitens schneidet RadarBEVNet in Interessensgebieten besonders gut ab, was für autonome Fahranwendungen besonders wichtig ist, da Ziele in Interessensgebieten normalerweise den größten Einfluss auf Fahrentscheidungen in Echtzeit haben. Obwohl der AP-Wert von RadarBEVNet bei der Erkennung von Autos und Fußgängern etwas niedriger ist als bei einigen monomodalen oder anderen multimodalen Methoden, zeigt RadarBEVNet seine Gesamtleistungsvorteile bei der Radfahrererkennung und der umfassenden mAP-Leistung. RadarBEVNet erzielt eine hervorragende Leistung im VoD-Verifizierungssatz durch die Zusammenführung multimodaler Daten von Kameras und Radargeräten und demonstriert insbesondere starke Erkennungsfähigkeiten in Interessenbereichen, die für das autonome Fahren von entscheidender Bedeutung sind, und beweist damit seine Wirksamkeit als Potenzial von 3D-Objekterkennungsmethoden.
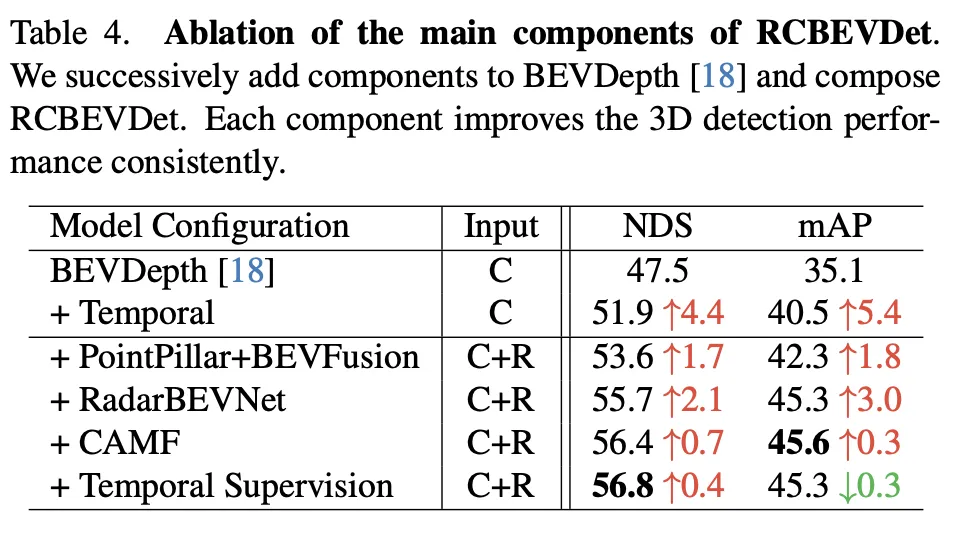
Dieses Ablationsexperiment zeigt die kontinuierliche Verbesserung der 3D-Objekterkennungsleistung von RadarBEVNet durch das schrittweise Hinzufügen wichtiger Komponenten. Ausgehend vom Basismodell BEVDepth verbessern die bei jedem Schritt hinzugefügten Komponenten NDS (Kernmetrik, die die Erkennungsgenauigkeit und -vollständigkeit widerspiegelt) und mAP (durchschnittliche Präzision, die die Fähigkeit des Modells zur Objekterkennung widerspiegelt) erheblich.
Insgesamt zeigt diese Reihe von Ablationsexperimenten deutlich den Beitrag jeder Hauptkomponente in RadarBEVNet zur Verbesserung der 3D-Objekterkennungsleistung, von der Einführung zeitlicher Informationen bis hin zur komplexen multimodalen Fusionsstrategie, jeder Schritt bringt Leistungsverbesserungen mit sich Modell. Insbesondere die ausgefeilten Verarbeitungs- und Fusionsstrategien für Radar- und Kameradaten belegen die Bedeutung der multimodalen Datenverarbeitung in komplexen autonomen Fahrumgebungen.
Die im Artikel vorgeschlagene RadarBEVNet-Methode verbessert effektiv die Genauigkeit und Robustheit der 3D-Zielerkennung durch die Zusammenführung multimodaler Daten von Kameras und Radargeräten, insbesondere in komplexen autonomen Fahrszenarien. Durch die Einführung von RadarBEVNet und dem Cross-Attention Multi-Layer Fusion Module (CAMF) optimiert RadarBEVNet nicht nur den Merkmalsextraktionsprozess von Radardaten, sondern erreicht auch eine präzise Merkmalsausrichtung und Fusion zwischen Radar- und Kameradaten und überwindet so das Problem der Verwendung eines einzigen Einschränkungen der Sensordaten, wie Radarpeilungsfehler und Verschlechterung der Kameraleistung bei schlechten Lichtverhältnissen oder widrigen Wetterbedingungen.
In Bezug auf die Vorteile besteht der Hauptbeitrag von RadarBEVNet in seiner Fähigkeit, komplementäre Informationen zwischen multimodalen Daten effektiv zu verarbeiten und zu nutzen und so die Erkennungsgenauigkeit und Systemrobustheit zu verbessern. Durch die Einführung von RadarBEVNet wird die Verarbeitung von Radardaten effizienter, und das CAMF-Modul sorgt für eine effektive Fusion unterschiedlicher Sensordaten und gleicht so deren jeweilige Defizite aus. Darüber hinaus zeigte RadarBEVNet in Experimenten eine hervorragende Leistung bei mehreren Datensätzen, insbesondere in Interessenbereichen, die für das autonome Fahren von entscheidender Bedeutung sind, und zeigte sein Potenzial in praktischen Anwendungsszenarien.
In Bezug auf die Mängel hat RadarBEVNet zwar bemerkenswerte Ergebnisse im Bereich der multimodalen 3D-Zielerkennung erzielt, aber auch die Komplexität seiner Implementierung hat entsprechend zugenommen und erfordert möglicherweise mehr Rechenressourcen und Verarbeitungszeit, was seine Verwendung auf ein bestimmtes Maß beschränkt Umfang. Einsatz in Echtzeit-Anwendungsszenarien. Obwohl RadarBEVNet bei der Erkennung von Radfahrern und der Gesamtleistung eine gute Leistung erbringt, besteht bei bestimmten Kategorien (z. B. Autos und Fußgänger) noch Raum für Leistungsverbesserungen, für deren Lösung möglicherweise eine weitere Algorithmusoptimierung oder effizientere Feature-Fusion-Strategien erforderlich sind.
Zusammenfassend hat RadarBEVNet durch seine innovative multimodale Fusionsstrategie erhebliche Leistungsvorteile im Bereich der 3D-Objekterkennung gezeigt. Obwohl es einige Einschränkungen gibt, wie z. B. eine höhere Rechenkomplexität und Raum für Leistungsverbesserungen bei bestimmten Erkennungskategorien, kann das Potenzial zur Verbesserung der Genauigkeit und Robustheit autonomer Fahrsysteme nicht ignoriert werden. Zukünftige Arbeiten können sich auf die Optimierung der Recheneffizienz des Algorithmus und die weitere Verbesserung seiner Leistung bei verschiedenen Zielerkennungen konzentrieren, um den weit verbreiteten Einsatz von RadarBEVNet in tatsächlichen autonomen Fahranwendungen zu fördern.
Der Artikel stellt RadarBEVNet und Cross-Attention Multi-Layer Fusion Module (CAMF) durch die Zusammenführung von Kamera- und Radardaten vor und zeigt deutliche Leistungsverbesserungen im Bereich der 3D-Zielerkennung, insbesondere im Schlüssel zum autonomen Fahren. Hervorragende Leistung in der Szene. Es nutzt effektiv die komplementären Informationen zwischen multimodalen Daten, um die Erkennungsgenauigkeit und Systemrobustheit zu verbessern. Trotz der Herausforderungen hoher Rechenkomplexität und Raum für Leistungsverbesserungen in einigen Kategorien haben wir großes Potenzial und Wert bei der Förderung der Entwicklung autonomer Fahrtechnologien gezeigt, insbesondere bei der Verbesserung der Wahrnehmungsfähigkeiten autonomer Fahrsysteme. Zukünftige Arbeiten können sich auf die Optimierung der Algorithmuseffizienz und die weitere Verbesserung der Erkennungsleistung konzentrieren, um eine bessere Anpassung an die Anforderungen von Echtzeitanwendungen für autonomes Fahren zu ermöglichen.
Das obige ist der detaillierte Inhalt vonDie Leistung der RV-Fusion ist erstaunlich! RCBEVDet: Radar hat auch Frühling, das neueste SOTA!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
So speichern Sie Bilder im Douyin-Kommentarbereich auf dem Mobiltelefon
 Top Ten der Rangliste der digitalen Geldwechsel
Top Ten der Rangliste der digitalen Geldwechsel
 Der Grund, warum die Header-Funktion einen 404-Fehler zurückgibt
Der Grund, warum die Header-Funktion einen 404-Fehler zurückgibt
 Mango-TV-Plug-in
Mango-TV-Plug-in
 Was sind die Javabean-Attribute?
Was sind die Javabean-Attribute?
 Wap-Browser
Wap-Browser
 Kosteneffizienzanalyse des Lernens von Python und C++
Kosteneffizienzanalyse des Lernens von Python und C++
 Was ist eine Mac-Adresse?
Was ist eine Mac-Adresse?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



