


Herkömmliche räumlich-zeitliche Vorhersagemodelle erfordern normalerweise eine große Menge an Datenunterstützung, um gute Ergebnisse zu erzielen.
Allerdings sind raumzeitliche Daten (z. B. Verkehrs- und Massenstromdaten) in vielen Bereichen aufgrund unterschiedlicher Entwicklungsniveaus verschiedener Städte und inkonsistenter Datenerfassungsrichtlinien begrenzt. Daher wird die Übertragbarkeit von Modellen besonders wichtig, wenn Daten knapp sind.
Die aktuelle Forschung stützt sich hauptsächlich auf Daten aus Quellstädten, um Modelle zu trainieren und sie auf Daten aus Zielstädten anzuwenden. Dieser Ansatz erfordert jedoch häufig komplexe Matching-Designs. Wie ein breiterer Wissenstransfer zwischen Quell- und Zielstädten erreicht werden kann, bleibt eine Herausforderung.
In letzter Zeit haben vorab trainierte Modelle erhebliche Fortschritte in den Bereichen Verarbeitung natürlicher Sprache und Computer Vision gemacht. Die Einführung der Prompt-Technologie verringert die Lücke zwischen Feinabstimmung und Vortraining, sodass sich fortschrittliche vorab trainierte Modelle schneller an neue Aufgaben anpassen können. Der Vorteil dieser Methode besteht darin, dass sie die Abhängigkeit von mühsamer Feinabstimmung reduziert und die Effizienz und Flexibilität des Modells verbessert. Durch die schnelle Technologie können Modelle die Bedürfnisse der Benutzer besser verstehen und genauere Ergebnisse liefern, wodurch den Menschen bessere Erfahrungen und Dienste geboten werden. Dieser innovative Ansatz treibt die Entwicklung der Technologie der künstlichen Intelligenz voran und eröffnet verschiedenen Branchen mehr Möglichkeiten und Chancen.
 Bilder
Bilder
Papierlink: https://openreview.net/forum?id=QyFm3D3Tzi
Offener Quellcode und Daten: //m.sbmmt.com/link/6644cb08d30b2ca55c284344a9750c2e
La Testveröffentlichung unter ICLR2024 Das Ergebnis „Spatio-Temporal Few-Shot Learning via Diffusive Neural Network Generation“ des Urban Science and Computing Research Center des Department of Electronic Engineering der Tsinghua University führte das GPD-Modell (Generative Pre-Trained Diffusion) ein und realisierte erfolgreich räumliche zeitliches Lernen in spärlichen Datenszenarien.
Diese Methode nutzt die Parameter des generativen neuronalen Netzwerks, um räumlich-zeitliches Lernen mit spärlichen Daten in ein generatives Vortrainingsproblem des Diffusionsmodells umzuwandeln. Im Gegensatz zu herkömmlichen Methoden erfordert diese Methode nicht mehr das Extrahieren übertragbarer Merkmale oder das Entwerfen komplexer Mustervergleichsstrategien, noch muss eine gute Modellinitialisierung für Szenarien mit wenigen Schüssen erlernt werden.
Stattdessen erlernt diese Methode Wissen über die Parameteroptimierung neuronaler Netzwerke durch Vortraining auf Daten aus der Quellstadt und generiert dann basierend auf Eingabeaufforderungen ein für die Zielstadt geeignetes neuronales Netzwerkmodell.
Die Innovation dieser Methode besteht darin, dass sie auf der Grundlage von „Eingabeaufforderungen“ maßgeschneiderte neuronale Netze generieren, sich effektiv an die Unterschiede in der Datenverteilung und den Merkmalen zwischen verschiedenen Städten anpassen und einen ausgeklügelten räumlich-zeitlichen Wissenstransfer erreichen kann.
Diese Forschung liefert neue Ideen zur Lösung des Problems der Datenknappheit im Urban Computing. Die Daten und der Code des Papiers sind Open Source.
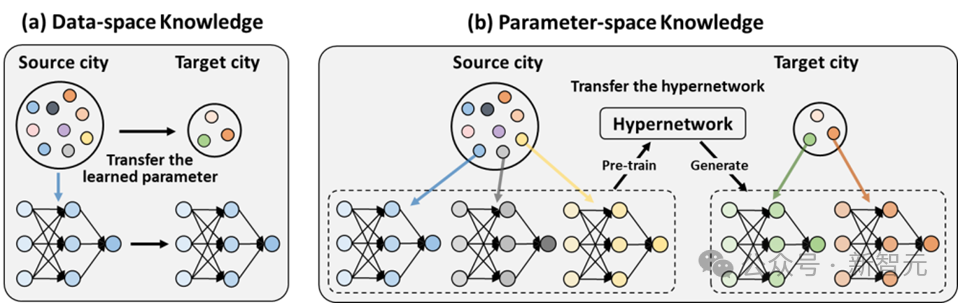 Abbildung 1: Wissenstransfer auf Datenmusterebene vs. Wissenstransfer auf neuronaler Netzwerkebene
Abbildung 1: Wissenstransfer auf Datenmusterebene vs. Wissenstransfer auf neuronaler Netzwerkebene
Wie in Abbildung 1(a) gezeigt, ist die traditionelle Wissenstransfermethode normalerweise am Quelle Trainieren Sie das Modell anhand von Stadtdaten und wenden Sie es dann auf die Zielstadt an. Es kann jedoch erhebliche Unterschiede in der Datenverteilung zwischen verschiedenen Städten geben, was zu einer direkten Migration des Quellstadtmodells führt, das möglicherweise nicht gut mit der Datenverteilung der Zielstadt übereinstimmt.
Deshalb müssen wir unsere Abhängigkeit von der unordentlichen Datenverteilung aufgeben und nach einer grundlegenderen und übertragbareren Möglichkeit des Wissensaustauschs suchen. Im Vergleich zur Datenverteilung weist die Verteilung neuronaler Netzwerkparameter mehr Merkmale „höherer Ordnung“ auf.
Abbildung 1 zeigt den Transformationsprozess von der Datenmusterebene zum Wissenstransfer auf neuronaler Netzwerkebene. Durch das Training eines neuronalen Netzwerks anhand von Daten aus einer Quellstadt und deren Umwandlung in einen Prozess zur Generierung neuronaler Netzwerkparameter, die an die Zielstadt angepasst sind, können die Datenverteilung und die Eigenschaften der Zielstadt besser angepasst werden.
1 Vorbereitungsphase des neuronalen Netzwerks: Zunächst trainiert die Studie a Separates räumlich-zeitliches Vorhersagemodell und Speichern seiner optimierten Netzwerkparameter. Die Modellparameter für jede Region werden unabhängig und ohne Parameterfreigabe optimiert, um sicherzustellen, dass sich das Modell optimal an die Merkmale der jeweiligen Region anpassen kann. 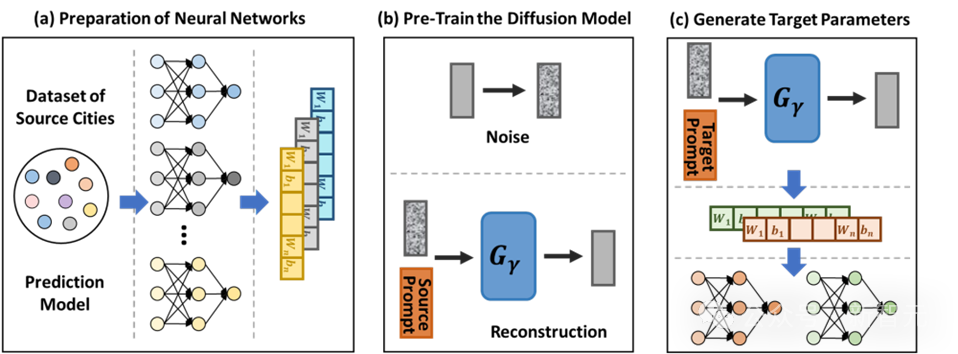
2. Vortraining des Diffusionsmodells: Dieses Framework verwendet die gesammelten vorab trainierten Modellparameter als Trainingsdaten, um das Diffusionsmodell zu trainieren und den Prozess der Modellparametergenerierung zu erlernen. Das Diffusionsmodell generiert Parameter durch schrittweises Entrauschen, ein Prozess, der dem Parameteroptimierungsprozess ab einer zufälligen Initialisierung ähnelt, und ist daher besser in der Lage, sich an die Datenverteilung der Zielstadt anzupassen.
3. Generierung neuronaler Netzwerkparameter: Nach dem Vortraining können Parameter mithilfe regionaler Hinweise der Zielstadt generiert werden. Dieser Ansatz nutzt Hinweise, um den Wissenstransfer und den präzisen Parameterabgleich zu erleichtern und dabei die Ähnlichkeiten zwischen Stadtregionen voll auszunutzen.
Es ist erwähnenswert, dass im Rahmen der Feinabstimmung der Cues vor dem Training die Auswahl der Cues sehr flexibel ist, solange sie die Merkmale einer bestimmten Region erfassen kann. Hierzu können beispielsweise verschiedene statische Merkmale wie Bevölkerung, regionale Fläche, Funktionen und Verteilung von Points of Interest (POIs) genutzt werden.
Diese Arbeit nutzt regionale Hinweise sowohl aus räumlichen als auch aus zeitlichen Aspekten: Räumliche Hinweise stammen aus Knotendarstellungen in städtischen Wissensgraphen [1,2], die nur Beziehungen wie regionale Nachbarschaft und funktionale Ähnlichkeit nutzen, die in allen Städten leicht vorkommen zugänglich; die zeitlichen Hinweise stammen vom Encoder des selbstüberwachten Lernmodells. Weitere Informationen zum Prompt-Design finden Sie im Originalartikel.
Darüber hinaus untersuchte diese Studie auch verschiedene Methoden zur Einführung von Hinweisen, und Experimente bestätigten, dass die Einführung von Hinweisen auf der Grundlage von Vorkenntnissen die optimale Leistung erbringt: Verwendung räumlicher Hinweise zur Steuerung der Generierung neuronaler Netzwerkparameter zur Modellierung räumlicher Korrelation und Verwendung zeitlicher Hinweise dazu Leitfaden für die Generierung von Netzwerkparametern im temporalen neuronalen Netzwerk.
Das Team beschrieb die experimentellen Einstellungen im Papier ausführlich, um anderen Forschern die Reproduktion ihrer Ergebnisse zu erleichtern. Sie stellten auch das Originalpapier und den Open-Source-Datencode zur Verfügung, auf deren experimentelle Ergebnisse wir uns hier konzentrieren.
Um die Wirksamkeit des vorgeschlagenen Rahmenwerks zu bewerten, wurden in dieser Studie Experimente zu zwei Arten klassischer räumlich-zeitlicher Vorhersageaufgaben durchgeführt: Vorhersage des Menschenstroms und Vorhersage der Verkehrsgeschwindigkeit, wobei mehrere Stadtdatensätze abgedeckt wurden.
 Bilder
Bilder
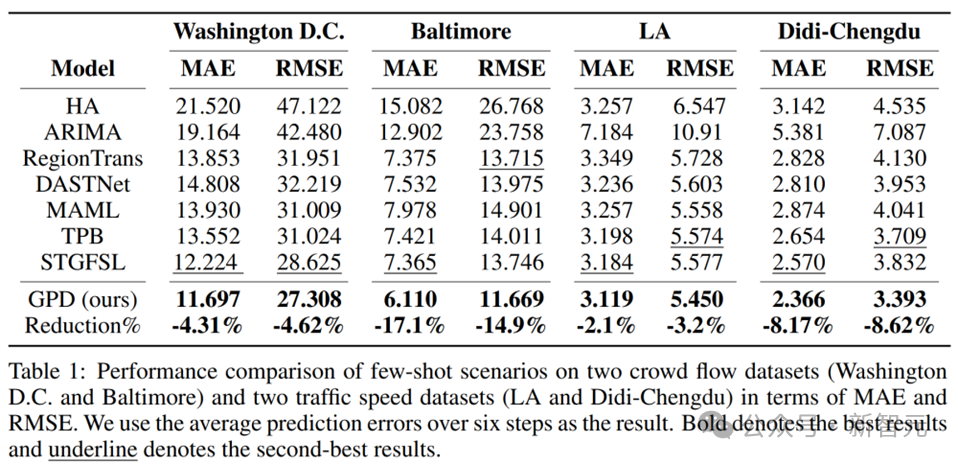
Tabelle 1 zeigt die Vergleichsergebnisse mit modernsten Basismethoden für vier Datensätze. Basierend auf diesen Ergebnissen können die folgenden Beobachtungen gemacht werden:
1) GPD weist erhebliche Leistungsvorteile gegenüber dem Basismodell auf und schneidet in verschiedenen Datenszenarien durchweg besser ab, was darauf hindeutet, dass GPD einen effektiven Wissenstransfer auf der Ebene der neuronalen Netzwerkparameter erreicht.
2) GPD schneidet in langfristigen Vorhersageszenarien gut ab. Dieser bedeutende Trend ist auf die Gewinnung wesentlicherer Kenntnisse durch das Framework zurückzuführen, was dazu beiträgt, langfristiges raumzeitliches Musterwissen auf Zielstädte zu übertragen.
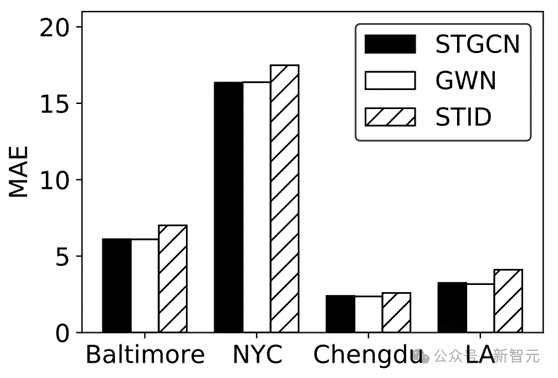 Abbildung 3 Leistungsvergleich verschiedener raumzeitlicher Vorhersagemodelle
Abbildung 3 Leistungsvergleich verschiedener raumzeitlicher Vorhersagemodelle
Darüber hinaus überprüfte diese Studie auch die Flexibilität des GPD-Frameworks für die Anpassung verschiedener raumzeitlicher Vorhersagemodelle. Zusätzlich zur klassischen raumzeitlichen Graphenmethode STGCN werden in dieser Studie auch GWN und STID als raumzeitliche Vorhersagemodelle eingeführt und ein Diffusionsmodell zur Generierung ihrer Netzwerkparameter verwendet.
Experimentelle Ergebnisse zeigen, dass die Überlegenheit des Frameworks durch die Modellauswahl nicht beeinträchtigt wird, sodass es an verschiedene fortgeschrittene Modelle angepasst werden kann.
Darüber hinaus führt die Studie eine Fallanalyse durch, indem sie die Musterähnlichkeit in zwei synthetischen Datensätzen manipuliert.
Abbildung 4 zeigt, dass die Regionen A und B sehr ähnliche Zeitreihenmuster aufweisen, während Region C deutlich unterschiedliche Muster aufweist. Abbildung 5 zeigt, dass die Knoten A und B symmetrische räumliche Positionen haben.
Daher können wir schließen, dass die Regionen A und B sehr ähnliche räumlich-zeitliche Muster aufweisen, während es deutliche Unterschiede zu C gibt. Die vom Modell generierten Ergebnisse der Parameterverteilung des neuronalen Netzwerks zeigen, dass die Parameterverteilungen von A und B ähnlich sind, sich jedoch erheblich von der Parameterverteilung von C unterscheiden. Dies bestätigt weiter die Fähigkeit des GPD-Frameworks, neuronale Netzwerkparameter mit unterschiedlichen räumlich-zeitlichen Mustern effektiv zu generieren.
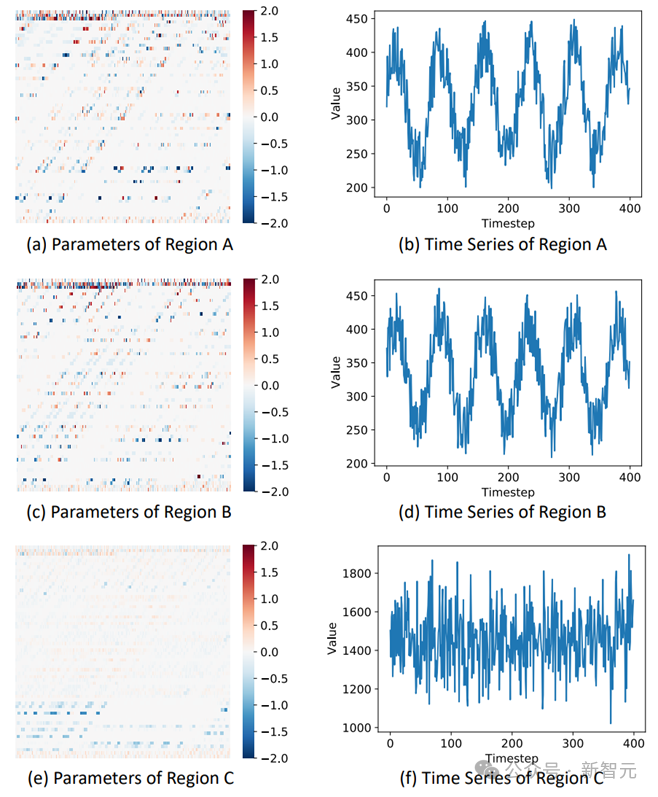
Abbildung 4 Visualisierung von Zeitreihen und neuronaler Netzwerkparameterverteilung in verschiedenen Regionen
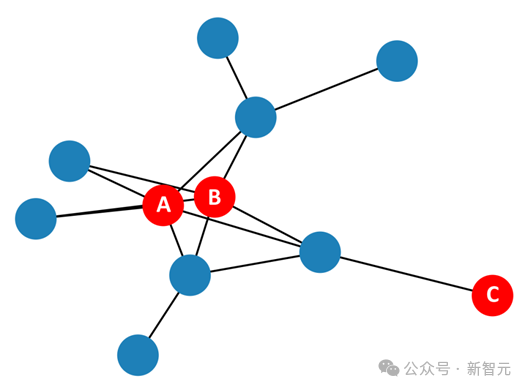
Abbildung 5 Regionale räumliche Verbindungsbeziehung des Simulationsdatensatzes
Referenz:
//m.sbmmt.com / link/6644cb08d30b2ca55c284344a9750c2e
[1] Liu, Yu, et al. „Urbankg: An urban Knowledge Graph System 14.4 (2023): 1-25.
[2] Zhou, Zhilun, et al. „Hierarchisches Wissensgraphenlernen ermöglichte die Vorhersage sozioökonomischer Indikatoren in standortbasierten sozialen Netzwerken.“
Das obige ist der detaillierte Inhalt vonEine clevere Lösung für das Problem der „Datenknappheit'! Tsinghua Open Source GPD: Verwendung eines Diffusionsmodells zur Generierung neuronaler Netzwerkparameter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So kehren Sie von einer HTML-Unterseite zur Startseite zurück
So kehren Sie von einer HTML-Unterseite zur Startseite zurück
 Die Rolle von Pycharm
Die Rolle von Pycharm
 So beheben Sie Fehler1
So beheben Sie Fehler1
 Einführung in Tastenkombinationen zum Minimieren von Windows-Fenstern
Einführung in Tastenkombinationen zum Minimieren von Windows-Fenstern
 Detaillierte Erläuterung der Verwendung der Oracle-Substr-Funktion
Detaillierte Erläuterung der Verwendung der Oracle-Substr-Funktion
 Welche Plattform ist Kuai Tuan Tuan?
Welche Plattform ist Kuai Tuan Tuan?
 WLAN ist verbunden, aber es gibt ein Ausrufezeichen
WLAN ist verbunden, aber es gibt ein Ausrufezeichen
 So öffnen Sie eine MDF-Datei
So öffnen Sie eine MDF-Datei








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



