


Große Sprachmodelle (LLMs) haben sich in den letzten zwei Jahren rasant entwickelt und einige phänomenale Modelle und Produkte wie GPT-4, Gemini, Claude usw. sind entstanden, aber die meisten davon sind Closed Source. Es besteht eine große Lücke zwischen den meisten Open-Source-LLMs, die derzeit der Forschungsgemeinschaft zugänglich sind, und Closed-Source-LLMs. Daher ist die Verbesserung der Fähigkeiten von Open-Source-LLMs und anderen kleinen Modellen, um die Lücke zwischen ihnen und großen Closed-Source-Modellen zu verringern, zu einem Forschungsschwerpunkt geworden in diesem Bereich.
Die leistungsstarken Funktionen von LLM, insbesondere Closed-Source-LLM, ermöglichen es wissenschaftlichen Forschern und Praktikern aus der Industrie, die Ergebnisse und das Wissen dieser großen Modelle beim Training ihrer eigenen Modelle zu nutzen. Bei diesem Prozess handelt es sich im Wesentlichen um einen Wissensdestillationsprozess (KD), bei dem Wissen aus einem Lehrermodell (z. B. GPT-4) in ein kleineres Modell (z. B. Llama) destilliert wird, wodurch die Fähigkeiten des kleinen Modells erheblich verbessert werden. Es ist ersichtlich, dass die Wissensdestillationstechnologie großer Sprachmodelle allgegenwärtig ist und eine kostengünstige und effektive Methode für Forscher darstellt, um das Training und die Verbesserung ihrer eigenen Modelle zu unterstützen.
Wie nutzt die aktuelle Arbeit also Closed-Source-LLM zur Wissensdestillation und Datenerfassung? Wie lässt sich dieses Wissen effizient in kleine Modelle einarbeiten? Welche leistungsstarken Fähigkeiten können kleine Modelle von Lehrermodellen erwerben? Welche Rolle spielt die Wissensdestillation von LLM in der Industrie mit Domänenmerkmalen? Diese Themen erfordern eingehende Überlegungen und Forschung.
Im Jahr 2020 veröffentlichte das Team von Tao Dacheng „Knowledge Distillation: A Survey“, das die Anwendung der Wissensdestillation beim Deep Learning umfassend untersuchte. Diese Technologie wird hauptsächlich zur Modellkomprimierung und -beschleunigung verwendet. Mit dem Aufkommen großer Sprachmodelle wurden die Anwendungsbereiche der Wissensdestillation kontinuierlich erweitert, wodurch nicht nur die Leistung kleiner Modelle verbessert, sondern auch eine Selbstverbesserung des Modells erreicht werden kann.
Anfang 2024 arbeitete das Team von Tao Dacheng mit der University of Hong Kong und der University of Maryland zusammen, um die neueste Rezension „A Survey on Knowledge Distillation of Large Language Models“ zu veröffentlichen, die 374 verwandte Arbeiten zusammenfasste und diskutierte, wie man daraus Wissen gewinnen kann Große Sprachmodelle trainieren kleinere Modelle und die Rolle der Wissensdestillation bei der Modellkomprimierung und dem Selbsttraining. Gleichzeitig befasst sich dieser Aufsatz auch mit der Destillation großer Sprachmodellfähigkeiten und der Destillation vertikaler Felder und hilft Forschern dabei, vollständig zu verstehen, wie sie ihre eigenen Modelle trainieren und verbessern können.

Papiertitel: A Survey on Knowledge Destillation of Large Language Models
Papierlink: https://arxiv.org/abs/2402.13116
Projektlink: https://github. com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
Übersichtsarchitektur
Der Gesamtrahmen der Wissensdestillation in großen Sprachmodellen ist wie in der folgenden Abbildung dargestellt zusammengefasst:
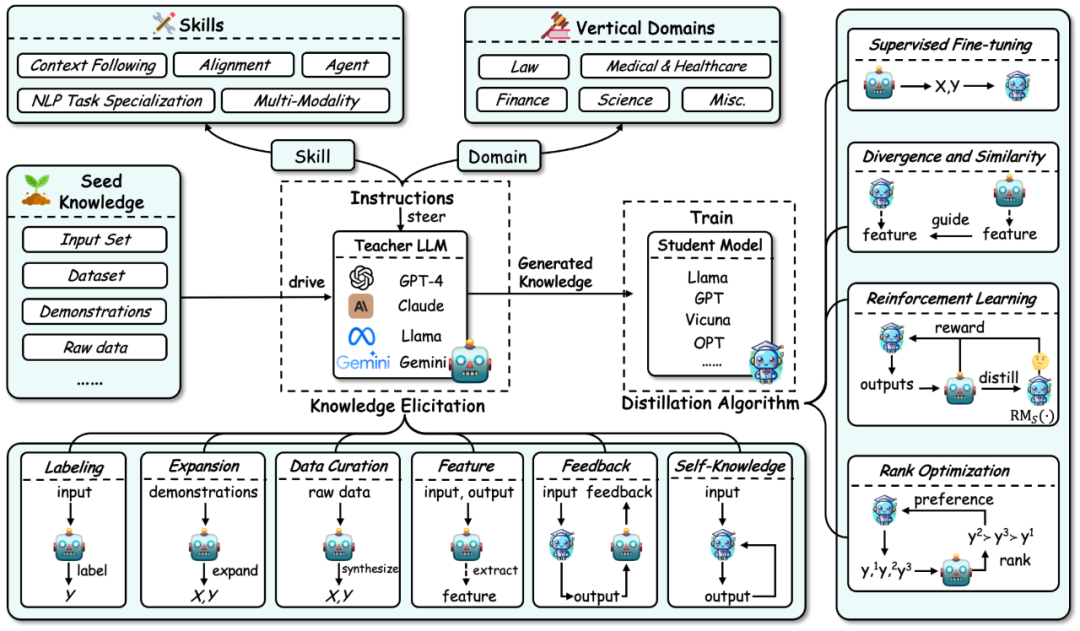
Erstens basierend auf Der Wissensdestillationsprozess für ein großes Sprachmodell unterteilt die Wissensdestillation in zwei Schritte:
Wissenserhebung: Das heißt, wie man Wissen aus dem Lehrermodell erhält. Der Prozess umfasst hauptsächlich:a) Erste Bauanweisungen zur Identifizierung der Fähigkeiten oder vertikalen Kompetenzen, die aus dem Lehrermodell destilliert werden sollen.
b) Verwenden Sie dann das Kernwissen (z. B. einen bestimmten Datensatz) als Eingabe, um das Lehrermodell anzutreiben und entsprechende Antworten zu generieren und so das entsprechende Wissen zu leiten. c) Gleichzeitig umfasst der Wissenserwerb einige spezifische Technologien: Annotation, Erweiterung, Synthese, Merkmalsextraktion, Feedback und eigenes Wissen. 2.Destillationsalgorithmen
: Das heißt, wie man das erworbene Wissen in das Studentenmodell einbringt. Zu den spezifischen Algorithmen in diesem Teil gehören: überwachte Feinabstimmung, Divergenz und Ähnlichkeit, verstärkendes Lernen (dh verstärkendes Lernen aus KI-Feedback, RLAIF) und Ranking-Optimierung.Die Klassifizierungsmethode dieser Rezension fasst verwandte Arbeiten aus drei Dimensionen basierend auf diesem Prozess zusammen: Wissensdestillationsalgorithmen, Fähigkeitsdestillation und vertikale Felddestillation. Die beiden letztgenannten werden auf der Grundlage von Wissensdestillationsalgorithmen destilliert. Die Einzelheiten dieser Klassifizierung und eine Zusammenfassung der entsprechenden verwandten Arbeiten sind in der folgenden Abbildung dargestellt.
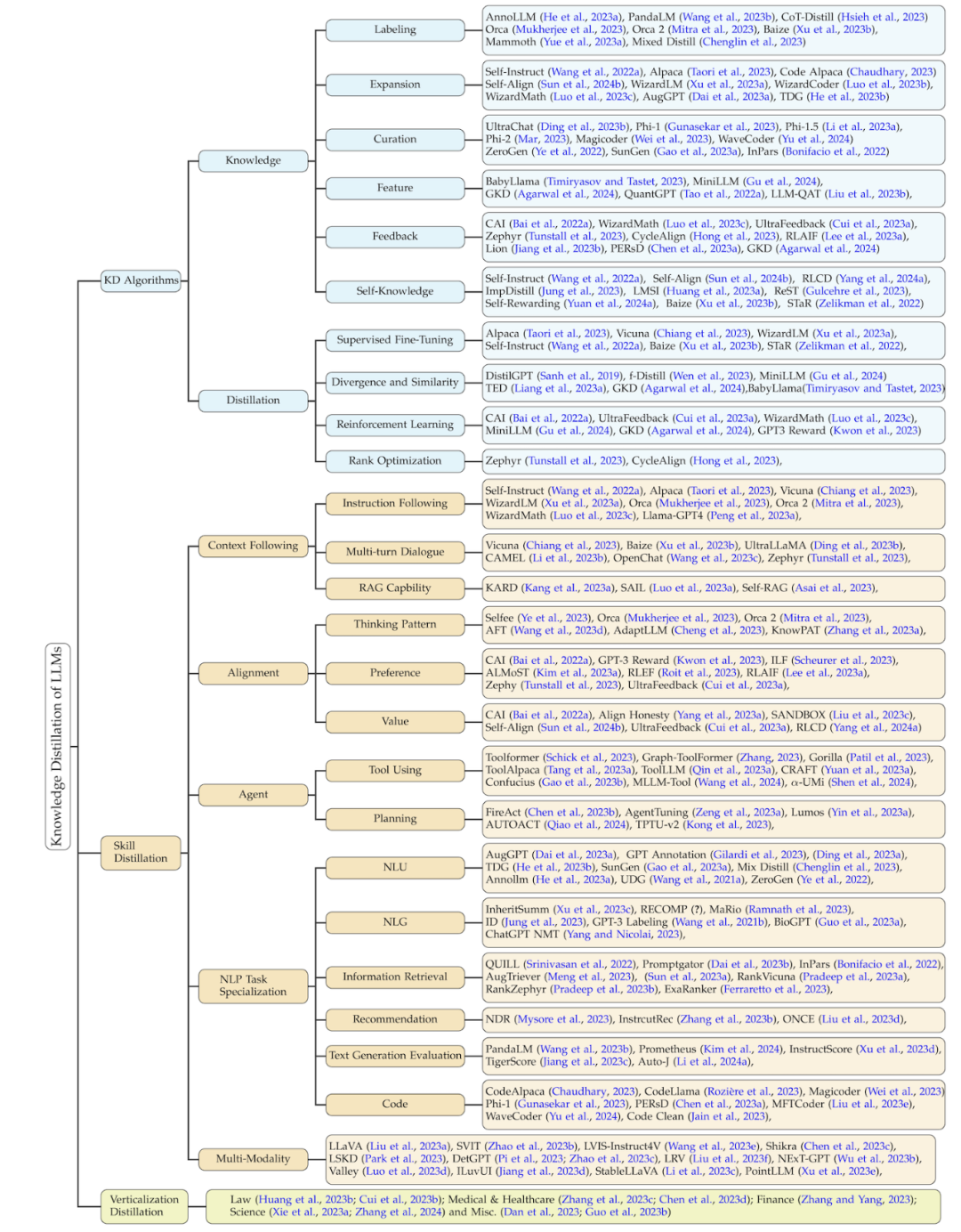 Wissensdestillationsalgorithmus
Wissensdestillationsalgorithmus
Wissenserhebung
Entsprechend der Art und Weise des Wissenserwerbs aus dem Lehrermodell unterteilt diese Rezension ihre Technologie in Kennzeichnung, Erweiterung und Datensynthese (Datenkuration) sowie Merkmalsextraktion (Feature), Feedback (Feedback), selbstgeneriertes Wissen (Self-Knowledge). Beispiele für jede Methode sind unten aufgeführt:
Beschriftung: Wissensbeschriftung bedeutet, dass Lehrer-LLMs die gegebene Eingabe als Ausgangswissen verwenden, um entsprechende Ausgabe basierend auf Anweisungen oder Beispielen zu generieren. Saatwissen ist beispielsweise die Eingabe eines bestimmten Datensatzes, und das Lehrermodell bezeichnet die Ausgabe der Denkkette.
Erweiterung: Ein wesentliches Merkmal dieser Technologie besteht darin, die kontextuellen Lernfähigkeiten von LLMs zu nutzen, um auf der Grundlage des bereitgestellten Seed-Beispiels Daten zu generieren, die dem Beispiel ähneln. Der Vorteil besteht darin, dass durch Beispiele vielfältigere und umfangreichere Datensätze generiert werden können. Da jedoch die generierten Daten weiter zunehmen, können Probleme mit der Datenhomogenität auftreten.
Datenkuration: Eine Besonderheit der Datensynthese besteht darin, dass Daten von Grund auf synthetisiert werden. Es nutzt eine große Menge an Metainformationen (wie Themen, Wissensdokumente, Originaldaten usw.) als vielfältige und riesige Mengen an Seed-Wissen, um umfangreiche und qualitativ hochwertige Datensätze von Lehrer-LLMs zu erhalten.
Feature-Erfassung (Feature): Die typische Methode zum Erhalten von Feature-Wissen besteht darin, die Eingabe- und Ausgabesequenzen an Lehrer-LLMs auszugeben und dann deren interne Darstellung zu extrahieren. Diese Methode eignet sich hauptsächlich für Open-Source-LLMs und wird häufig zur Modellkomprimierung verwendet.
Feedback: Feedback-Wissen gibt dem Lehrermodell in der Regel Feedback zum Output des Schülers, z. B. durch die Angabe von Präferenzen, Bewertungen oder Korrekturinformationen, um den Schülern dabei zu helfen, einen besseren Output zu erzielen.
Selbstwissen: Wissen kann auch von Studierenden selbst erworben werden, was als selbstgeneriertes Wissen bezeichnet wird. In diesem Fall fungiert dasselbe Modell sowohl als Lehrer als auch als Schüler und verbessert sich iterativ, indem es Techniken destilliert und seine eigenen, zuvor generierten Ergebnisse verbessert. Dieser Ansatz funktioniert gut für Open-Source-LLMs.
Zusammenfassung: Derzeit ist die Erweiterungsmethode immer noch weit verbreitet, und die Datensynthesemethode hat sich allmählich zum Mainstream entwickelt, da sie eine große Menge hochwertiger Daten generieren kann. Feedback-Methoden können Wissen liefern, das Schülermodellen dabei hilft, ihre Ausrichtungsfähigkeiten zu verbessern. Methoden zum Erwerb von Merkmalen und zum selbstgenerierten Wissen sind aufgrund der Verwendung großer Open-Source-Modelle als Lehrermodelle populär geworden. Die Feature-Acquisition-Methode hilft dabei, Open-Source-Modelle zu komprimieren, während die selbstgenerierte Wissensmethode große Sprachmodelle kontinuierlich verbessern kann. Wichtig ist, dass die oben genannten Methoden effektiv kombiniert werden können und Forscher verschiedene Kombinationen erkunden können, um effektiveres Wissen zu gewinnen.
Algorithmen destillieren
Nach dem Erwerb des Wissens muss es in das Studentenmodell destilliert werden. Zu den Destillationsalgorithmen gehören: überwachte Feinabstimmung, Divergenz und Ähnlichkeit, verstärkendes Lernen und Ranking-Optimierung. Ein Beispiel ist in der folgenden Abbildung dargestellt:
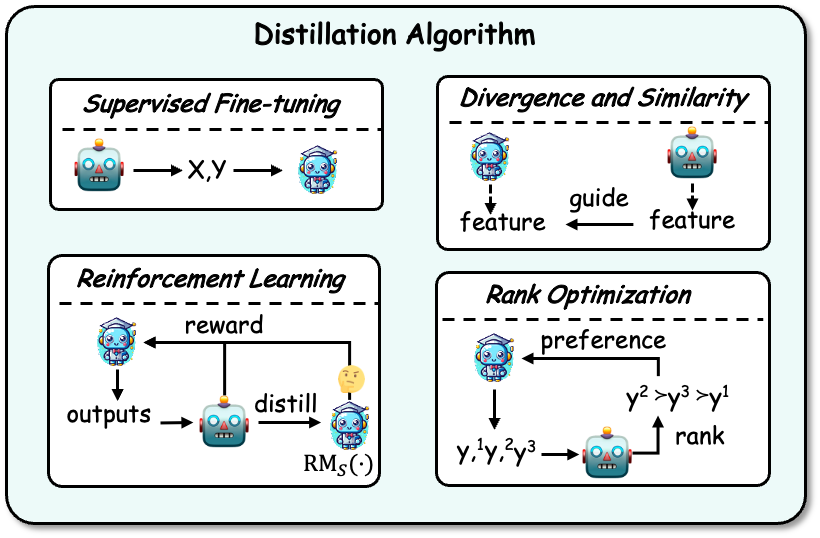
Überwachte Feinabstimmung: Überwachte Feinabstimmung (SFT) optimiert das Schülermodell, indem die Wahrscheinlichkeit der vom Lehrermodell generierten Sequenzen maximiert wird, was dem Schüler ermöglicht Modell zur Nachahmung des Lehrermodells. Dies ist derzeit die am häufigsten verwendete Technik zur Wissensdestillation von LLMs.
Divergenz und Ähnlichkeit: Dieser Algorithmus nutzt das interne Parameterwissen des Lehrermodells als Überwachungssignal für das Schülermodelltraining und ist für Open-Source-Lehrermodelle geeignet. Auf Divergenz und Ähnlichkeit basierende Methoden richten Wahrscheinlichkeitsverteilungen bzw. verborgene Zustände aus.
Reinforcement Learning: Dieser Algorithmus eignet sich für die Nutzung von Lehrer-Feedback-Wissen zum Trainieren von Schülermodellen, also der RLAIF-Technologie. Es gibt zwei Hauptaspekte: (1) Training eines Schülerbelohnungsmodells mithilfe von Lehrern generierter Feedbackdaten, (2) Optimierung des Schülermodells durch Maximierung der erwarteten Belohnung durch das trainierte Belohnungsmodell. Lehrer können auch direkt als Belohnungsmodelle dienen.
Rank-Optimierung: Die Ranking-Optimierung kann auch Präferenzwissen in das Studentenmodell einbringen. Ihre Vorteile sind Stabilität und hohe Recheneffizienz, wie z. B. einige klassische Algorithmen wie DPO, RRHF usw.
Fähigkeitsdestillation
Es ist bekannt, dass große Sprachmodelle viele hervorragende Fähigkeiten haben. Durch die Wissensdestillationstechnologie werden Anweisungen bereitgestellt, um Lehrer zu steuern, um Wissen mit entsprechenden Fähigkeiten zu generieren und Schülermodelle zu trainieren, damit sie diese Fähigkeiten erwerben können. Zu diesen Fähigkeiten gehören hauptsächlich Fähigkeiten wie das Verfolgen von Kontexten (z. B. Anweisungen), Ausrichtung, Agenten, Aufgaben zur Verarbeitung natürlicher Sprache (NLP) und Multimodalität.
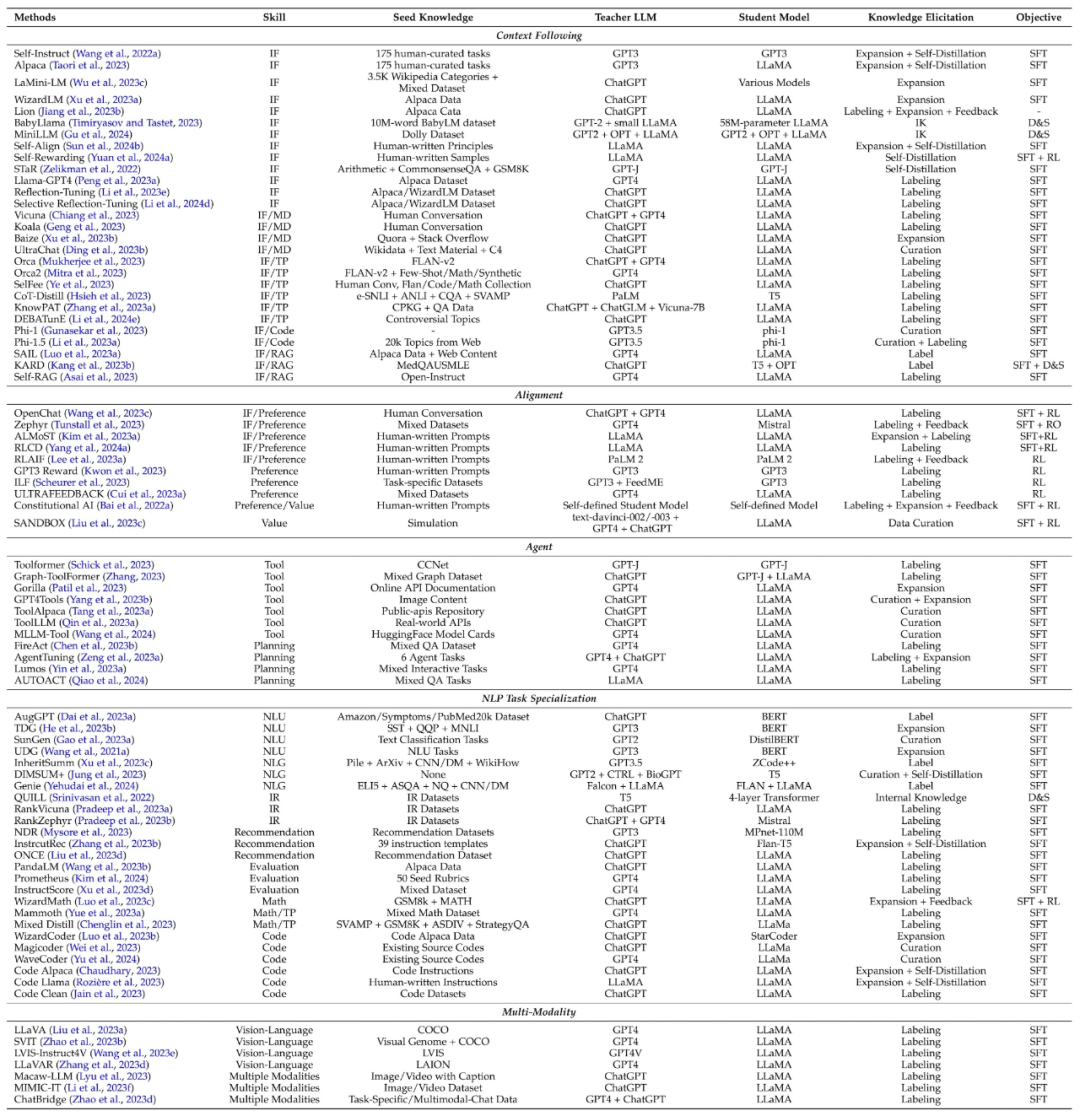
Die folgende Tabelle fasst die klassische Arbeit der Fähigkeitsdestillation zusammen und fasst auch die Fähigkeiten, das Kernwissen, das Lehrermodell, das Schülermodell, die Methoden zum Wissenserwerb und die Destillationsalgorithmen zusammen, die an jeder Arbeit beteiligt sind.
Vertikale Felddestillation
Zusätzlich zu großen Sprachmodellen in allgemeinen Bereichen gibt es mittlerweile viele Bemühungen, große Sprachmodelle in vertikalen Bereichen zu trainieren, was der Forschungsgemeinschaft und der Industrie hilft, große Sprachmodelle anzuwenden und einzusetzen. Obwohl große Sprachmodelle (wie GPT-4) über begrenzte Domänenkenntnisse in vertikalen Feldern verfügen, können sie dennoch einige Domänenkenntnisse und -funktionen bereitstellen oder vorhandene Domänendatensätze verbessern. Die hier involvierten Bereiche umfassen hauptsächlich (1) Recht, (2) medizinische Gesundheit, (3) Finanzen, (4) Wissenschaft und einige andere Bereiche. Die Taxonomie und die damit verbundene Arbeit dieses Teils sind in der folgenden Abbildung dargestellt:

Zukünftige Richtungen
Dieser Aufsatz untersucht die aktuellen Probleme der Wissensdestillation großer Sprachmodelle und mögliche zukünftige Forschungsrichtungen, hauptsächlich einschließlich:
Datenauswahl: Wie wählt man Daten automatisch aus, um bessere Destillationsergebnisse zu erzielen?
Multi-Lehrer-Destillation: Entdecken Sie die Destillation des Wissens verschiedener Lehrermodelle in einem Schülermodell.
Umfangreicheres Wissen im Lehrermodell: Sie können im Lehrermodell umfangreicheres Wissen erkunden, einschließlich Feedback und Funktionswissen, und eine Kombination mehrerer Wissenserwerbsmethoden erkunden.
Katastrophales Vergessen während der Destillation überwinden : Die Fähigkeit, das ursprüngliche Modell während der Destillation oder Übertragung von Wissen effektiv zu bewahren, bleibt eine Herausforderung.
Trusted Knowledge Destillation: Derzeit konzentriert sich KD hauptsächlich auf die Destillation verschiedener Fähigkeiten und schenkt der Glaubwürdigkeit großer Modelle relativ wenig Aufmerksamkeit.
Schwach-zu-stark-Destillation(Schwach-zu-stark-Destillation). OpenAI schlägt das Konzept der „schwach-zu-starken Generalisierung“ vor, das die Erforschung innovativer technischer Strategien erfordert, damit schwächere Modelle den Lernprozess stärkerer Modelle effektiv steuern können.
Selbstausrichtung (Selbstdestillation). Anweisungen können so gestaltet werden, dass das Schülermodell seine generierten Inhalte durch die Generierung von Feedback, Kritik und Erklärungen selbstständig verbessert und ausrichtet.
Fazit
Diese Rezension bietet eine umfassende und systematische Zusammenfassung darüber, wie das Wissen über große Sprachmodelle zur Verbesserung von Studentenmodellen genutzt werden kann, z. B. Open-Source-Modelle für große Sprachen, und umfasst auch die kürzlich beliebte Selbstdestillationstechnologie . Diese Übersicht unterteilt die Wissensdestillation in zwei Schritte: Wissenserwerb und Destillationsalgorithmus und fasst auch die Fähigkeitsdestillation und die vertikale Felddestillation zusammen. Abschließend untersucht dieser Aufsatz die zukünftige Richtung der Destillation großer Sprachmodelle und hofft, die Grenzen der Wissensdestillation großer Sprachmodelle zu erweitern und große Sprachmodelle zu erhalten, die zugänglicher, effizienter, effektiver und glaubwürdiger sind.
Das obige ist der detaillierte Inhalt vonMit einer Zusammenfassung von 374 verwandten Arbeiten veröffentlichte das Team von Tao Dacheng zusammen mit der University of Hong Kong und UMD die neueste Übersicht über die Destillation von LLM-Wissen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Gründe, warum die Homepage nicht geändert werden kann
Gründe, warum die Homepage nicht geändert werden kann
 Lösung dafür, dass Google Chrome nicht funktioniert
Lösung dafür, dass Google Chrome nicht funktioniert
 Kosten für die Servermiete
Kosten für die Servermiete
 ETH-Marktanalyse heute
ETH-Marktanalyse heute
 Welche Fehlerkorrektursysteme für Domainnamen gibt es?
Welche Fehlerkorrektursysteme für Domainnamen gibt es?
 Was sind die Konfigurationsparameter des Videoservers?
Was sind die Konfigurationsparameter des Videoservers?
 vc6.0
vc6.0
 So lesen Sie eine Spalte in Excel in Python
So lesen Sie eine Spalte in Excel in Python








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



