


Die Weiterentwicklung großer Sprachmodelle (LLMs) hat die Entwicklung des Bereichs der Codegenerierung in hohem Maße vorangetrieben. In früheren Forschungsarbeiten wurden Reinforcement Learning (RL) und Compiler-Feedbacksignale kombiniert, um den Ausgaberaum von LLMs zu untersuchen und die Qualität der Codegenerierung zu optimieren.
Aber es gibt immer noch zwei Probleme:
1. Es ist schwierig, sich direkt an „komplexe menschliche Bedürfnisse“ anzupassen, was erfordert, dass LLMs „lange Sequenzcodes“ generieren Da Unit-Tests möglicherweise keinen komplexen Code abdecken, ist die Optimierung von LLMs mithilfe nicht ausgeführter Codefragmente wirkungslos.
Um diese Herausforderungen anzugehen, schlugen Forscher ein neues Rahmenwerk für verstärkendes Lernen namens StepCoder vor, das gemeinsam von Experten der Fudan-Universität, der Huazhong-Universität für Wissenschaft und Technologie und dem Royal Institute of Technology entwickelt wurde. StepCoder enthält zwei Schlüsselkomponenten, die die Effizienz und Qualität der Codegenerierung verbessern sollen.
1. CCCS
löst Erkundungsherausforderungen, indem es Aufgaben zur Codevervollständigung in Unteraufgabenabschnitte aufteilt; -körnige Optimierung.
Papierlink: https://arxiv.org/pdf/2402.01391.pdf Projektlink: https://github.com/Ablustrund/APPS_Plus
Die Forscher haben auch APPS+ entwickelt Datensatz, der für das Reinforcement-Learning-Training verwendet wird und manuell überprüft wird, um die Korrektheit der Unit-Tests sicherzustellen. 
Experimentelle Ergebnisse zeigen, dass die Methode die Fähigkeit zur Erkundung des Ausgaberaums verbessert und modernste Methoden bei entsprechenden Benchmarks übertrifft.
StepCoder
Im Codegenerierungsprozess ist die gewöhnliche Erkundung des Verstärkungslernens (Exploration) schwierig mit „Umgebungen mit spärlichen Belohnungen und Verzögerungen“ und „komplexen Anforderungen mit langen Sequenzen“ umzugehen.
In der CCCS-Phase (Curriculum of Code Completion Subtasks) zerlegen Forscher komplexe Explorationsprobleme in eine Reihe von Teilaufgaben. Mithilfe eines Teils der kanonischen Lösung als Eingabeaufforderung kann LLM mit der Erkundung anhand einfacher Sequenzen beginnen.
Die Berechnung der Belohnungen bezieht sich nur auf ausführbare Codefragmente. Daher ist es ungenau, den gesamten Code (roter Teil im Bild) zur Optimierung von LLM (grauer Teil im Bild) zu verwenden.
In der FGO-Phase (Fine-Grained Optimization) maskieren die Forscher die nicht ausgeführten Token (roter Teil) im Unit-Test und verwenden nur die ausgeführten Token (grüner Teil), um die Verlustfunktion zu berechnen, die eine detaillierte Granularität liefern kann Optimierung. 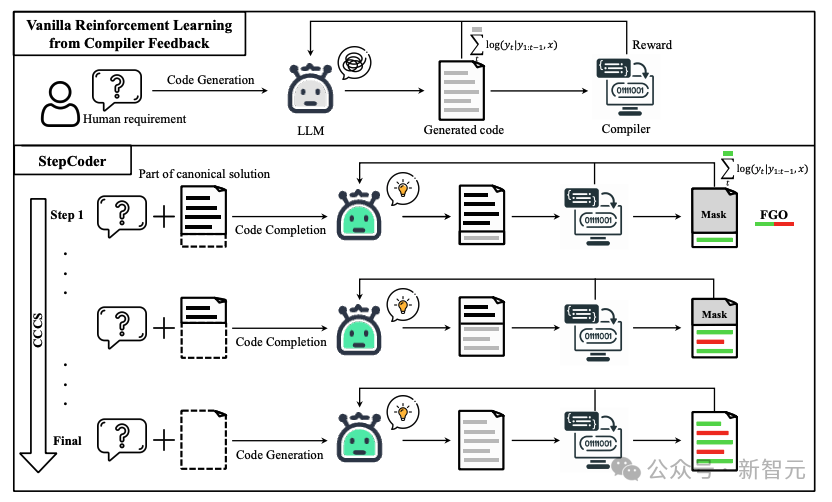
Vorkenntnisse
Angenommen,
ist ein Trainingsdatensatz für die Codegenerierung, wobei x, y, u menschliche Bedürfnisse (d. h. Aufgabenbeschreibung), Standardlösungen bzw. Unit-Test-Beispiele darstellen.
ist eine Liste bedingter Anweisungen, die durch automatische Analyse des abstrakten Syntaxbaums der Standardlösung yi erhalten werden, wobei st und en die Startposition bzw. Endposition der Anweisung darstellen.
Für menschliche Anforderung 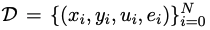
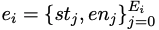
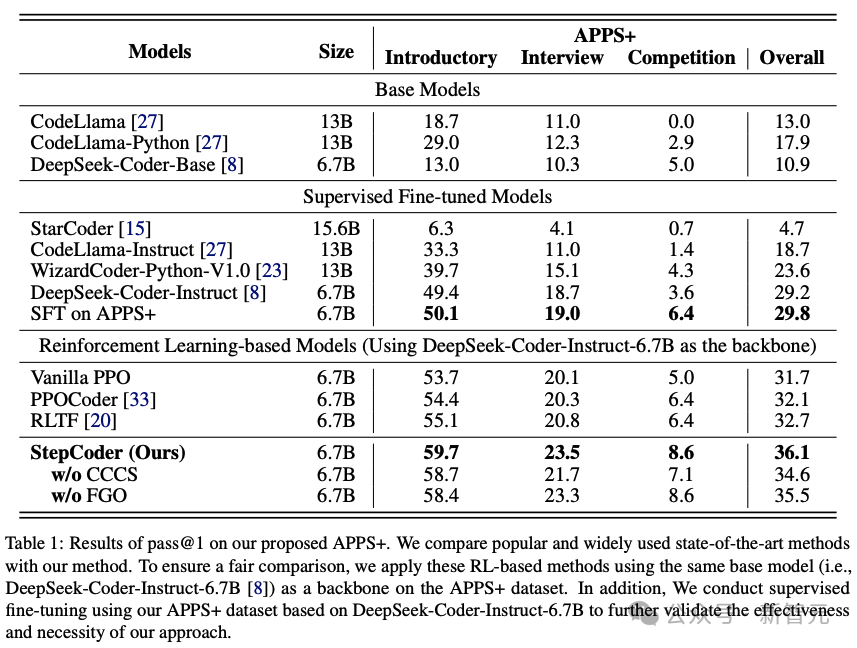
CCCS Während des Codegenerierungsprozesses erfordert die Lösung komplexer menschlicher Bedürfnisse oft, dass das Richtlinienmodell eine lange Abfolge von Aktionen durchführt. Gleichzeitig ist das Compiler-Feedback verzögert und spärlich, d. h. das Richtlinienmodell erhält erst dann Belohnungen, wenn der gesamte Code generiert wurde. In diesem Fall ist die Erkundung sehr schwierig. Der Kern dieser Methode besteht darin, eine so lange Liste von Erkundungsproblemen in eine Reihe kurzer, leicht zu erforschender Unteraufgaben zu zerlegen. Die Forscher vereinfachen die Codegenerierung in Unteraufgaben zur Codevervollständigung, wobei die Unteraufgaben durch typische dargestellt werden Beispiele im Trainingsdatensatz. Die Lösung wird automatisch erstellt. Für menschliche Bedürfnisse x ist in der frühen Trainingsphase von CCCS der Ausgangspunkt s* für die Erkundung ein Zustand nahe dem Endzustand. Konkret stellen die Forscher die menschliche Nachfrage x und die erste Hälfte der Standardlösung Unter der Annahme, dass y^ die kombinierte Folge von xp und der Ausgabetrajektorie τ ist, also yˆ=(xp,τ), liefert das Belohnungsmodell eine Belohnung r basierend auf der Korrektheit des Codefragments τ mit y^ als Eingabe. Die Forscher verwendeten den PPO-Algorithmus (Proximal Policy Optimization), um das Richtlinienmodell πθ durch Nutzung der Belohnung r und der Trajektorie τ zu optimieren. Während der Optimierungsphase wird das zur Bereitstellung von Hinweisen verwendete kanonische Lösungscodesegment xp maskiert, sodass es keinen Einfluss auf den Gradienten der Aktualisierung des Richtlinienmodells πθ hat. CCCS optimiert das Richtlinienmodell πθ durch Maximierung der Oppositionsfunktion, wobei π^ref das Referenzmodell in PPO ist, initialisiert durch das SFT-Modell. Mit fortschreitendem Training bewegt sich der Startpunkt s* der Erkundung schrittweise in Richtung des Startpunkts der Standardlösung. Insbesondere wird für jedes Trainingsbeispiel ein Schwellenwert ρ festgelegt und die Anhäufung von Codesegmenten jedes Mal generiert Zeit πθ Wenn die Genauigkeitsrate größer als ρ ist, wird der Startpunkt an den Anfang verschoben. In den späteren Phasen des Trainings entspricht der Erkundungsprozess dieser Methode dem des ursprünglichen Verstärkungslernens, d. h. s*=0, und das Richtlinienmodell generiert nur Code mit menschlichen Bedürfnissen als Eingabe. Probieren Sie den anfänglichen Erkennungspunkt s* an der Startposition der bedingten Anweisung aus, um das verbleibende ungeschriebene Codesegment zu vervollständigen. Insbesondere gilt: Je mehr bedingte Anweisungen, desto mehr unabhängige Pfade hat das Programm und desto höher ist die Logikkomplexität. Die Komplexität erfordert eine häufigere Stichprobe, um die Trainingsqualität zu verbessern, während Programme mit weniger bedingten Anweisungen dies nicht tun müssen häufig. Diese Stichprobenmethode kann repräsentative Codestrukturen gleichmäßig extrahieren und gleichzeitig sowohl komplexe als auch einfache semantische Strukturen im Trainingsdatensatz berücksichtigen. Um die Trainingsphase zu beschleunigen, setzten die Forscher die Anzahl der Kurse für die i-te Stichprobe auf Die Hauptpunkte von CCCS lassen sich wie folgt zusammenfassen: 1 Es ist einfach, die Erkundung von einem Zustand aus zu beginnen, der dem Ziel nahe ist (d. h. dem Endzustand); 2 Sie können die Erkundung in einem Zustand beginnen, der weit vom Zielgeschlecht entfernt ist. Die Erkundung wird jedoch einfacher, wenn Sie den Zustand erreichen können, in dem Sie gelernt haben, wie Sie Ihre Ziele erreichen. FGO Die Beziehung zwischen Belohnungen und Aktionen bei der Codegenerierung unterscheidet sich von anderen Verstärkungslernaufgaben (wie bei Atari). Bei der Codegenerierung handelt es sich um eine Reihe von Belohnungen, die für die Berechnung der Belohnungen in der Codegenerierung irrelevant sind generierter Code kann ausgeschlossen werden. Insbesondere bei Unit-Tests bezieht sich das Feedback des Compilers nur auf das ausgeführte Codefragment. Bei normalen RL-Optimierungszielen sind jedoch alle Aktionen auf der Trajektorie an der Gradientenberechnung beteiligt, und die Gradientenberechnung ist ungenau. Um die Optimierungsgenauigkeit zu verbessern, haben die Forscher die nicht ausgeführten Aktionen (d. h. Token) im Unit-Test und den Verlust des Strategiemodells abgeschirmt. APPS+Datensatz Verstärkendes Lernen erfordert eine große Menge hochwertiger Trainingsdaten. Während der Untersuchung stellten die Forscher fest, dass unter den derzeit verfügbaren Open-Source-Datensätzen Nur APPS erfüllt diese Anforderung. Eine Anfrage. Aber es gibt einige fehlerhafte Fälle in APPS, wie z. B. fehlende Eingaben, Ausgaben oder Standardlösungen, bei denen die Standardlösung möglicherweise nicht kompiliert oder ausgeführt wird, oder es kann Unterschiede in der Ausführungsausgabe geben. Um den APPS-Datensatz zu verbessern, haben die Forscher Instanzen mit fehlenden Eingaben, Ausgaben oder Standardlösungen herausgefiltert und dann die Formate der Eingaben und Ausgaben standardisiert, um dann die Ausführung und den Vergleich von Komponententests für jede Instanz zu erleichtern Es wurden Komponententests und manuelle Analysen durchgeführt, um Fälle von unvollständigem oder irrelevantem Code, Syntaxfehlern, API-Missbrauch oder fehlenden Bibliotheksabhängigkeiten zu beseitigen. Bei Unterschieden in der Ausgabe überprüfen Forscher manuell die Problembeschreibung, korrigieren die erwartete Ausgabe oder eliminieren die Instanz. Schließlich haben wir den APPS+-Datensatz erstellt, der 7456 Instanzen enthält. Jede Instanz enthält eine Beschreibung des Programmierproblems, eine Standardlösung, einen Funktionsnamen, einen Komponententest (d. h. Eingabe und Ausgabe) und einen Startcode (d. h. Standardlösung). . Um die Leistung anderer LLMs und StepCoder bei der Codegenerierung zu bewerten, führten die Forscher Experimente mit dem APPS+-Datensatz durch. Die Ergebnisse zeigen, dass das RL-basierte Modell andere Sprachmodelle übertrifft, einschließlich des Basismodells und des SFT-Modells. Die Forscher kamen zu dem Schluss, dass Reinforcement Learning die Qualität der Codegenerierung weiter verbessern kann, indem der Ausgaberaum des Modells anhand des Compiler-Feedbacks effizienter untersucht wird. Darüber hinaus übertraf StepCoder alle Basismodelle, einschließlich anderer RL-basierter Methoden, und erreichte die höchste Punktzahl. Insbesondere erzielte diese Methode bei den Testfragen „Einführung“, „Interview“ und „Wettbewerb“ hohe Werte von 59,7 %, 23,5 % bzw. 8,6 %. Im Vergleich zu anderen auf Verstärkungslernen basierenden Methoden zeichnet sich diese Methode durch die Vereinfachung komplexer Codegenerierungsaufgaben in Teilaufgaben zur Codevervollständigung durch die Erkundung des Ausgaberaums aus, und der FGO-Prozess spielt eine Schlüsselrolle bei der genauen Optimierung des Richtlinienmodelleffekts. Es kann auch festgestellt werden, dass StepCoder im APPS+-Datensatz, der auf demselben Architekturnetzwerk basiert, bei der Feinabstimmung eine bessere Leistung erbringt als überwachtes LLM, wobei letzteres die Erfolgsquote des generierten Codes kaum verbessert. Es wird auch direkt gezeigt, dass die Verwendung von Compiler-Feedback zur Optimierung des Modells die Qualität des generierten Codes stärker verbessern kann als die Vorhersage des nächsten Tokens bei der Codegenerierung. 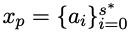 bereit und trainieren ein Richtlinienmodell, um den Code gemäß x'=(x, xp) zu vervollständigen.
bereit und trainieren ein Richtlinienmodell, um den Code gemäß x'=(x, xp) zu vervollständigen. 
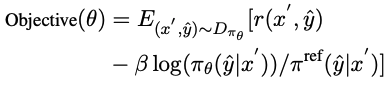
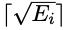 , wobei Ei die Anzahl ihrer bedingten Anweisungen ist. Die Trainingskursspanne der i-ten Stichprobe beträgt
, wobei Ei die Anzahl ihrer bedingten Anweisungen ist. Die Trainingskursspanne der i-ten Stichprobe beträgt 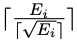 , nicht 1.
, nicht 1. 
Experimenteller Teil

Experimentelle Ergebnisse
Das obige ist der detaillierte Inhalt vonSchließe die Aufgabe „Codegenerierung' ab! Fudan et al. veröffentlichen das StepCoder-Framework: Verstärkung des Lernens aus Compiler-Feedbacksignalen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



