


Der Hauptzweck der AVSS-Technologie (Audiovisual Speech Separation) besteht darin, die Stimme des Zielsprechers im gemischten Signal zu identifizieren und zu trennen und dabei Gesichtsinformationen zu verwenden, um dieses Ziel zu erreichen. Diese Technologie findet vielfältige Anwendungsmöglichkeiten in zahlreichen Bereichen, darunter intelligente Assistenten, Fernkonferenzen und Augmented Reality. Durch die AVSS-Technologie kann die Qualität von Sprachsignalen in lauten Umgebungen erheblich verbessert und dadurch die Wirkung der Spracherkennung und Kommunikation verbessert werden. Die Entwicklung dieser Technologie hat das tägliche Leben und die Arbeit der Menschen komfortabler gemacht und es einfacher gemacht,
Herkömmliche audiovisuelle Sprachtrennungsmethoden erfordern normalerweise komplexe Modelle und eine große Menge an Rechenressourcen, insbesondere wenn es viele oder viele laute Hintergründe gibt In diesem Fall ist die Leistung leicht eingeschränkt. Um diese Probleme zu überwinden, begannen Forscher, Methoden zu erforschen, die auf Deep Learning basieren. Die bestehende Deep-Learning-Technologie weist jedoch die Herausforderungen einer hohen Rechenkomplexität und Schwierigkeiten bei der Anpassung an unbekannte Umgebungen auf.
Insbesondere weisen die aktuellen audiovisuellen Sprachtrennungsmethoden die folgenden Probleme auf:
Zeitbereichsmethode: Sie kann qualitativ hochwertige Audiotrennungseffekte liefern, aber aufgrund mehr Parameter ist die Berechnungskomplexität höher und die Verarbeitungsgeschwindigkeit höher ist langsamer.
Methoden im Zeit-Frequenz-Bereich: recheneffizienter, weisen jedoch in der Vergangenheit im Vergleich zu Methoden im Zeitbereich eine schlechte Leistung auf. Sie stehen vor drei Hauptherausforderungen:
1. Mangel an unabhängiger Modellierung von Zeit- und Frequenzdimensionen.
2. Visuelle Hinweise aus mehreren rezeptiven Feldern werden nicht vollständig zur Verbesserung der Modellleistung genutzt.
3. Eine unsachgemäße Verarbeitung komplexer Merkmale führt zum Verlust wichtiger Amplituden- und Phaseninformationen.
Um diese Herausforderungen zu bewältigen, schlugen Forscher des Teams von außerordentlichem Professor Hu Xiaolin von der Tsinghua-Universität ein neues audiovisuelles Sprachtrennungsmodell namens RTFS-Net vor. Das Modell verwendet eine Komprimierungs-Rekonstruktionsmethode, die die Rechenkomplexität und die Anzahl der Parameter des Modells erheblich reduziert und gleichzeitig die Trennleistung verbessert. RTFS-Net ist die erste audiovisuelle Sprachtrennungsmethode, die weniger als 1 Million Parameter verwendet, und es ist auch die erste Methode, die alle Zeitdomänenmodelle bei der multimodalen Trennung im Zeit-Frequenzbereich übertrifft.

Papieradresse: https://arxiv.org/abs/2309.17189
Papierhomepage: https://cslikai.cn/RTFS-Net/AV-Model-Demo.html
Codeadresse: https://github.com/spkgyk/RTFS-Net (bald verfügbar)
Einführung in die Methode
Die gesamte Netzwerkarchitektur von RTFS-Net ist in Abbildung 1 unten dargestellt:
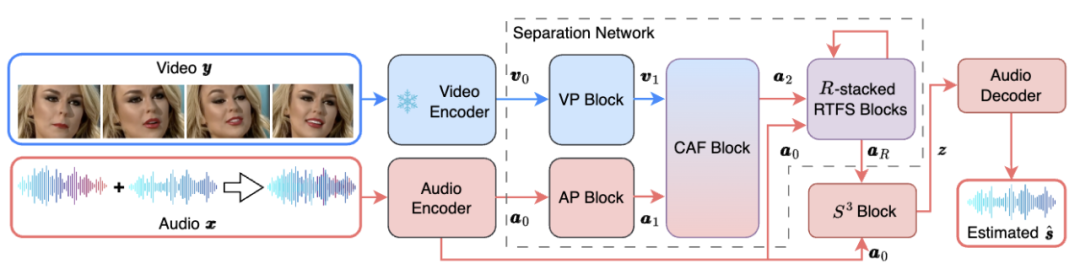
Abbildung 1. Netzwerk-Framework von RTFS-NET
Unter ihnen komprimiert der RTFS-Block (gezeigt in Abbildung 2) und modelliert unabhängig die akustischen Abmessungen (Zeit und Frequenz) und versucht, einen Unterraum mit niedriger Komplexität zu erstellen versuchen, den Informationsverlust zu reduzieren. Insbesondere verwendet der RTFS-Block eine Dual-Path-Architektur für die effiziente Verarbeitung von Audiosignalen sowohl in Zeit- als auch in Frequenzdimensionen. Mit diesem Ansatz können RTFS-Blöcke die Rechenkomplexität reduzieren und gleichzeitig eine hohe Empfindlichkeit und Genauigkeit für Audiosignale beibehalten. Das Folgende ist der spezifische Arbeitsablauf des RTFS-Blocks:
1 Zeit-Frequenz-Komprimierung: Der RTFS-Block komprimiert zunächst die Eingabeaudiofunktionen in den Zeit- und Frequenzdimensionen.
2. Unabhängige Dimensionsmodellierung: Nach Abschluss der Komprimierung modelliert der RTFS-Block unabhängig die Zeit- und Frequenzdimensionen.
3. Dimensionsfusion: Nach der unabhängigen Verarbeitung der Zeit- und Frequenzdimensionen führt der RTFS-Block die Informationen der beiden Dimensionen über ein Fusionsmodul zusammen.
4. Rekonstruktion und Ausgabe: Schließlich werden die fusionierten Merkmale durch eine Reihe von Entfaltungsschichten wieder in den ursprünglichen Zeit-Frequenz-Raum rekonstruiert.
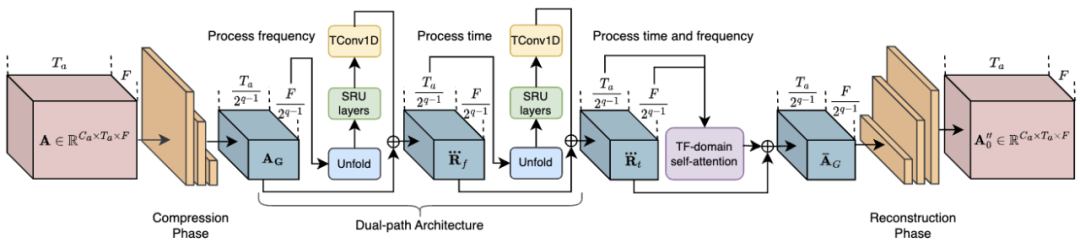
Abbildung 2. Netzwerkstruktur des RTFS-Blocks
Das Cross-Dimensional Attention Fusion (CAF)-Modul (dargestellt in Abbildung 3) führt effektiv Audio- und visuelle Informationen zusammen, verbessert den Sprachtrennungseffekt und reduziert die Rechenkomplexität Es beträgt nur 1,3 % der bisherigen SOTA-Methode. Insbesondere generiert das CAF-Modul zunächst Aufmerksamkeitsgewichte mithilfe von Tiefen- und gruppierten Faltungsoperationen. Diese Gewichtungen passen sich dynamisch an die Bedeutung der Eingabemerkmale an, sodass sich das Modell auf die relevantesten Informationen konzentrieren kann. Durch die Anwendung der generierten Aufmerksamkeitsgewichtungen auf visuelle und auditive Merkmale ist das CAF-Modul dann in der Lage, sich auf Schlüsselinformationen in mehreren Dimensionen zu konzentrieren. In diesem Schritt werden Features unterschiedlicher Dimension gewichtet und zusammengeführt, um eine umfassende Feature-Darstellung zu erstellen. Zusätzlich zum Aufmerksamkeitsmechanismus kann das CAF-Modul auch einen Gating-Mechanismus übernehmen, um den Grad der Fusion von Merkmalen aus verschiedenen Quellen weiter zu steuern. Dieser Ansatz kann die Flexibilität des Modells erhöhen und eine feinere Steuerung des Informationsflusses ermöglichen.
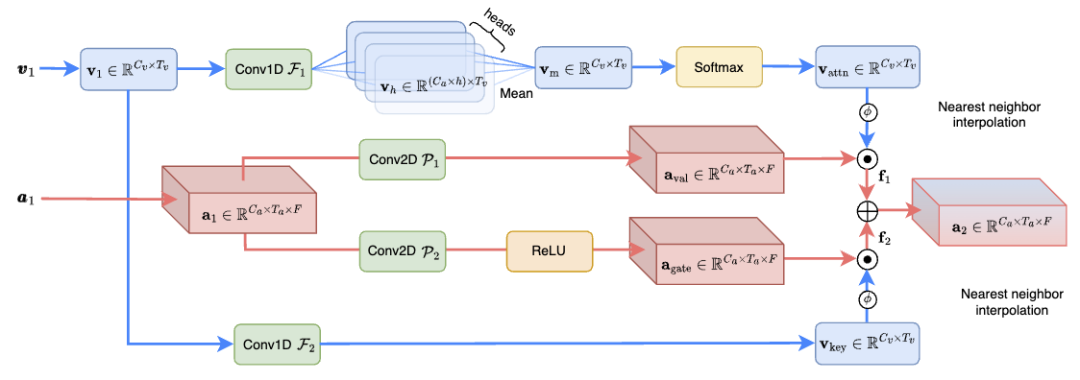
Abbildung 3. Schematisches Strukturdiagramm des CAF -Fusionsmoduls
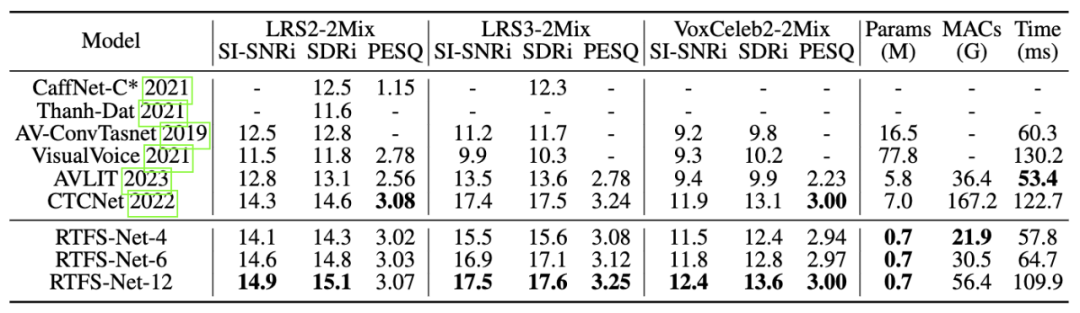
Das Entwurfskonzept der Spektrumquellenabteilung (S^3) besteht darin, die durch komplexen Zahlen dargestellten Spektralinformationen zu verwenden, um die Sprache effektiv zu extrahieren des Ziellautsprechers aus der Mixed-Audio-Funktion. Diese Methode nutzt die Phasen- und Amplitudeninformationen des Audiosignals vollständig aus und verbessert so die Genauigkeit und Effizienz der Quellentrennung. Und die Verwendung eines komplexen Netzwerks ermöglicht es dem S^3-Block, das Signal bei der Isolierung der Sprache des Zielsprechers genauer zu verarbeiten, insbesondere durch die Beibehaltung von Details und die Reduzierung von Artefakten, wie unten gezeigt. Ebenso ermöglicht das Design des S^3-Blocks eine einfache Integration in verschiedene Audioverarbeitungs-Frameworks, eignet sich für eine Vielzahl von Aufgaben zur Quellentrennung und verfügt über gute Generalisierungsfähigkeiten. Experimentelle Ergebnisse Komplexität, die sich dem aktuellen Stand der Technik annähert oder diese übertrifft. Der Kompromiss zwischen Effizienz und Leistung wird anhand von Varianten mit unterschiedlicher Anzahl von RTFS-Blöcken (4, 6, 12 Blöcke) demonstriert, wobei RTFS-Net-6 ein gutes Gleichgewicht zwischen Leistung und Effizienz bietet. RTFS-Net-12 schnitt bei allen getesteten Datensätzen am besten ab und bewies die Vorteile von Zeit-Frequenz-Domänenmethoden bei der Bewältigung komplexer Aufgaben zur Trennung von Audio- und Videosynchronisation.
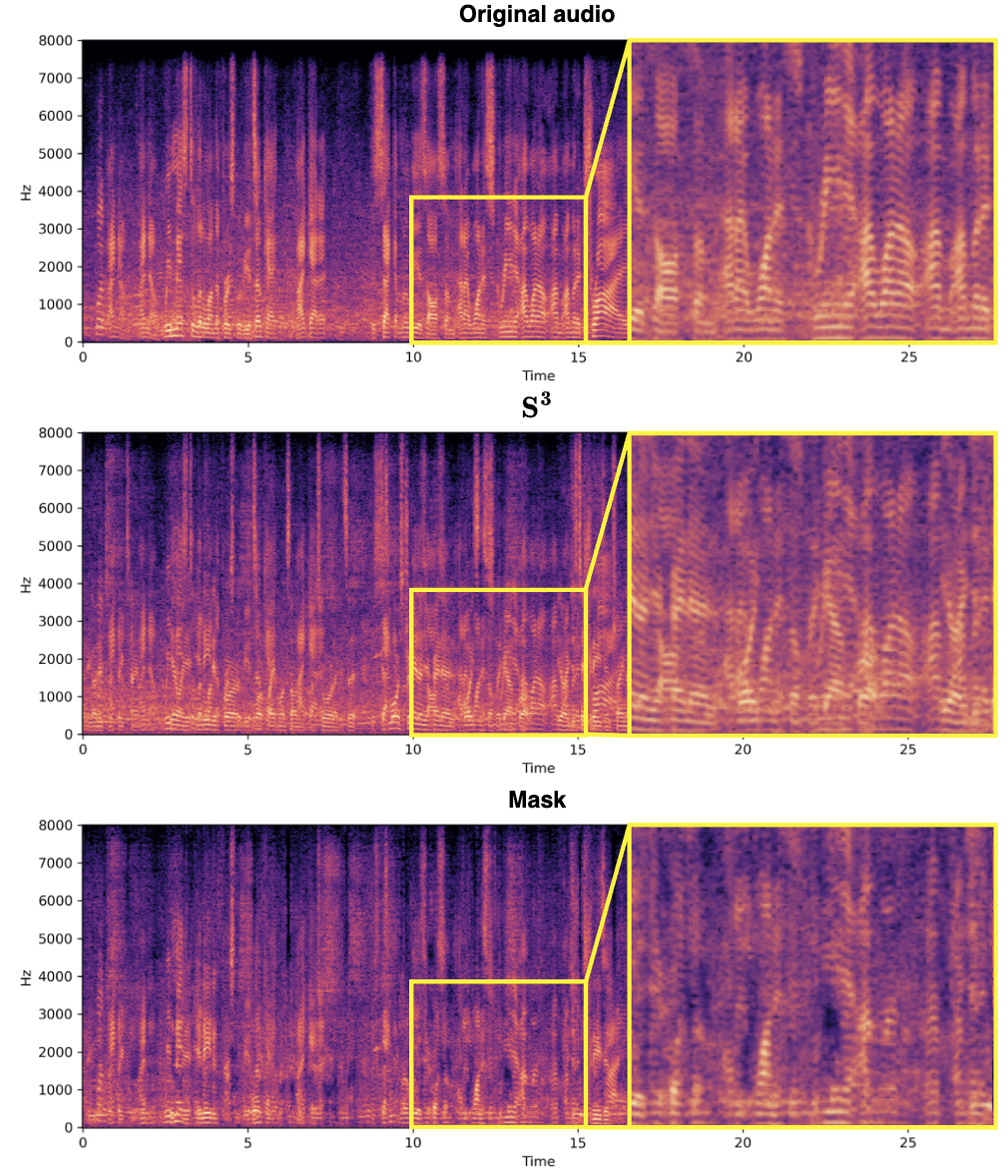
Echte Effekte
Gemischtes Video: Audio für weibliche Sprecher:
Audio für männliche Sprecher:
Zusammenfassung
Mit dem Kontinuierliche Weiterentwicklung der großen Modelltechnologieentwicklung, audiovisuelle Die Auch im Bereich der Sprachtrennung werden große Modelle zur Verbesserung der Trennqualität verfolgt. Für Endgeräte ist dies jedoch nicht realisierbar. RTFS-Net erzielt erhebliche Leistungsverbesserungen bei gleichzeitig deutlich reduzierter Rechenkomplexität und Anzahl der Parameter. Dies zeigt, dass eine Verbesserung der AVSS-Leistung nicht unbedingt größere Modelle erfordert, sondern vielmehr innovative, effiziente Architekturen, die das komplexe Zusammenspiel zwischen Audio- und visuellen Modalitäten besser erfassen.
Das obige ist der detaillierte Inhalt vonICLR 2024 |. Um eine neue Perspektive für die Audio- und Videotrennung zu bieten, hat das Hu Xiaolin-Team der Tsinghua-Universität RTFS-Net ins Leben gerufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



