


Die leistungsstarke Generalisierungsfähigkeit von Transformer wurde erneut bewiesen!
In den letzten Jahren haben transformatorbasierte Strukturen aufgrund ihrer hervorragenden Leistung bei verschiedenen Aufgaben weltweit Aufmerksamkeit erregt. Mithilfe dieser Struktur und der Kombination mit großen Datenmengen lassen sich die resultierenden Modelle wie etwa Large Language Models (LLM) gut an praktische Anwendungsszenarien anpassen.
Trotz ihres Erfolgs in einigen Bereichen stehen Transformer-basierte Architekturen und LLMs immer noch vor Herausforderungen, insbesondere bei der Bewältigung von Planungs- und Inferenzaufgaben. Frühere Untersuchungen haben gezeigt, dass LLM Schwierigkeiten bei der Bewältigung mehrstufiger Planungsaufgaben oder logischer Überlegungen höherer Ordnung hat.
Um die Argumentations- und Planungsleistung von Transformer zu verbessern, hat die Forschungsgemeinschaft in den letzten Jahren auch einige Methoden vorgeschlagen. Eine der gebräuchlichsten und effektivsten Methoden besteht darin, den menschlichen Denkprozess zu simulieren: Zuerst einen Zwischen-„Gedanken“ generieren und dann eine Antwort ausgeben. Beispielsweise regt die Chain of Thought (CoT)-Prompting-Methode das Modell dazu an, Zwischenschritte vorherzusagen und schrittweise „Denken“ durchzuführen. Der Denkbaum (ToT) verwendet Verzweigungsstrategien und Bewertungsmethoden, um es dem Modell zu ermöglichen, mehrere verschiedene Denkpfade zu generieren und daraus dann den besten Pfad auszuwählen. Obwohl diese Techniken oft effektiv sind, hat die Forschung gezeigt, dass diese Methoden in vielen Fällen die Modellleistung beeinträchtigen, unter anderem aus Gründen der Selbstverwirklichung.
Eine Technik, die bei einem Datensatz gut funktioniert, funktioniert bei anderen Datensätzen möglicherweise nicht gut. Dies kann auf eine Änderung der Art des erforderlichen Denkens zurückzuführen sein, beispielsweise auf eine Verlagerung von räumlichem zu mathematischem oder vernünftigem Denken.
Im Gegensatz dazu weisen traditionelle symbolische Planungs- und Suchtechniken hervorragende Denkfähigkeiten auf. Darüber hinaus verfügen die mit diesen traditionellen Methoden berechneten Lösungen häufig über formale Garantien, da symbolische Planungsalgorithmen normalerweise einem genau definierten regelbasierten Suchprozess folgen.
Um Transformer mit komplexen Argumentationsfunktionen auszustatten, hat das Team von Meta FAIR Tian Yuandong kürzlich Searchformer vorgeschlagen.

Papiertitel: Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
Papieradresse: https://arxiv.org/pdf/2402.14083.pdf
Searchformer ist ein Transformer Modell, aber für mehrstufige Planungsaufgaben wie Labyrinthnavigation und Kistenschieben kann es den optimalen Plan berechnen und die Anzahl der verwendeten Suchschritte kann weitaus geringer sein als bei symbolischen Planungsalgorithmen wie der A*-Suche.
Dazu schlug das Team eine neue Methode vor: Search Dynamics Bootstrapping. Diese Methode trainiert zunächst ein Transformer-Modell, um den Suchprozess von A* zu imitieren (wie in Abbildung 1 dargestellt), und optimiert es dann, sodass es den optimalen Plan mit weniger Suchschritten finden kann

Weitere Details in Mit anderen Worten: Der erste Schritt besteht darin, ein Transformer-Modell zu trainieren, das die A*-Suche nachahmt. Der Ansatz des Teams besteht darin, die A*-Suche anhand zufällig generierter Planungsaufgabeninstanzen durchzuführen Planen und organisieren Sie sie in Wortsequenzen, also in Token. Auf diese Weise enthält der resultierende Trainingsdatensatz die Ausführungsbahn von A* und kodiert Informationen über die Suchdynamik von A* selbst. Dies ermöglicht die Generierung dieser Token-Sequenzen entlang der optimalen Planung für jede Planungsaufgabe.
Der zweite Schritt besteht darin, die Experteniterationsmethode zu verwenden, um das Training mithilfe der oben genannten sucherweiterten Sequenz (einschließlich der Ausführungstrajektorie von A*) weiter zu verbessern Die Experten-Iterationsmethode ermöglicht es dem Transformer, mit weniger Suchschritten optimale Lösungen zu generieren Bei der A*-Suche kann das neue Modell beispielsweise 93,7 % der Testaufgaben lösen, während die Anzahl der Suchschritte durchschnittlich 26,8 % geringer ist als bei der A*-Suche. Das Team sagte: Um den Einfluss von Trainingsdaten und Modellparametervolumen auf die Leistung des resultierenden Modells besser zu verstehen, führten sie einige Ablationsstudien durch.
Sie verwendeten zwei Arten von Datensätzen zum Trainieren des Modells: Einer hat eine Token-Sequenz, die nur Lösungen enthält (nur Lösung, in der nur Aufgabenbeschreibung und endgültige Planung enthalten sind), der andere ist eine sucherweiterte Sequenz, in der Aufgabenbeschreibung und Suche enthalten sind Baumdynamik und endgültige Planung).
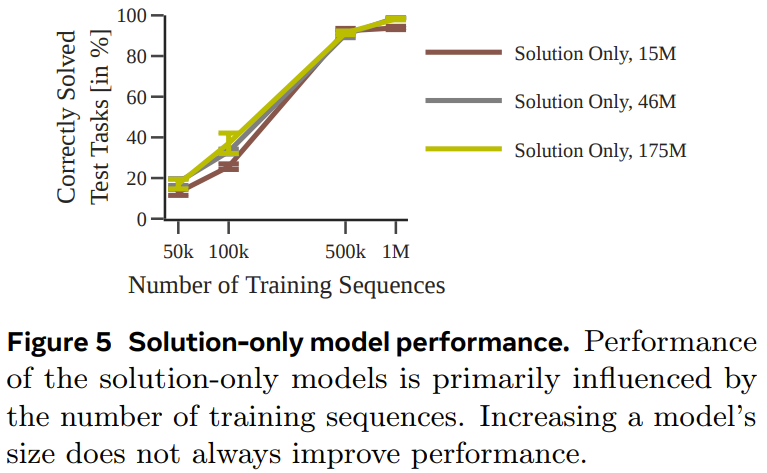
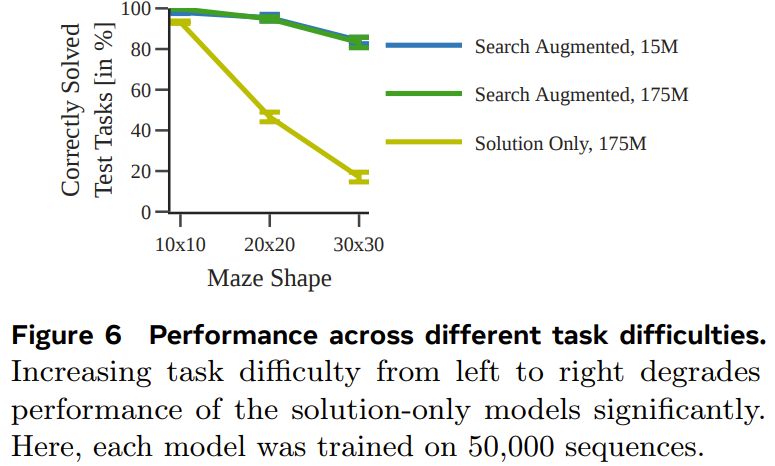
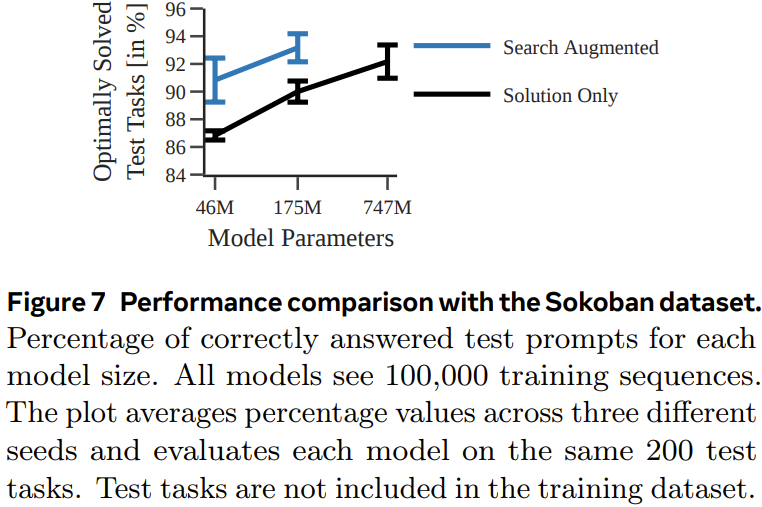
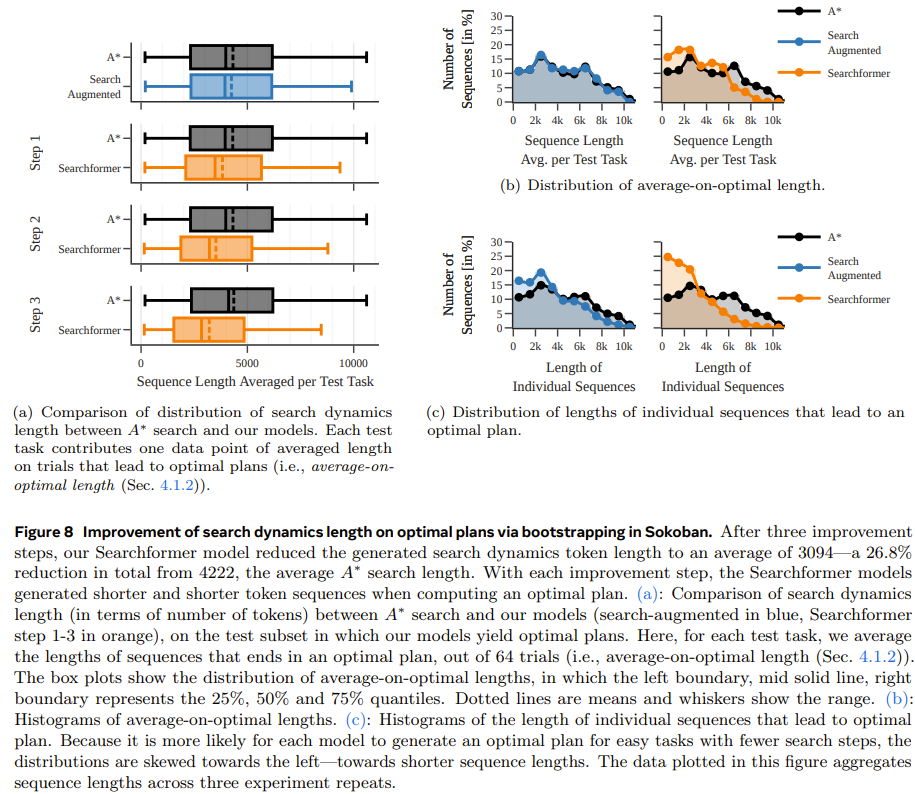
Im Experiment verwendete das Team eine deterministische und nicht deterministische Variante der A*-Suche, um jeden Sequenzdatensatz zu generieren eine Reihe von Encoder-Decoder-Transformator-Modellen zur Vorhersage des optimalen Pfads in einem 30×30-Labyrinth Abbildung 4 zeigt, dass durch die Vorhersage zwischenliegender Rechenschritte eine robustere Leistung erzielt werden kann, wenn die Datenmenge klein ist. Abbildung 5 zeigt die Leistung des Modells, das nur mit Lösungen trainiert wurde. Abbildung 6 zeigt die Auswirkung der Aufgabenschwierigkeit auf die Leistung jedes Modells. Obwohl das nur mit der Lösung trainierte Modell den optimalen Plan vorhersagen kann, wenn der verwendete Trainingsdatensatz groß genug und vielfältig genug ist, ist die Leistung des durch die Suche erweiterten Modells insgesamt deutlich besser, wenn die Datenmenge klein ist und lässt sich auch für schwierigere Aufgaben besser skalieren. Pushing Boxes Um zu testen, ob bei verschiedenen und komplexeren Aufgaben (mit unterschiedlichen Tokenisierungsmodi) ähnliche Ergebnisse erzielt werden können, hat das Team außerdem einen Planungsdatensatz von Pushing Boxes zum Testen erstellt. Abbildung 7 zeigt die Wahrscheinlichkeit, mit der jedes Modell den richtigen Plan für jede Testaufgabe generiert. Es ist ersichtlich, dass das sucherweiterte Modell, wie im vorherigen Experiment, durch das Training mithilfe von Ausführungsspuren das Modell übertrifft, das nur mithilfe von Lösungen trainiert wurde. Searchformer: Verbesserung der Suchdynamik durch Bootstrapping Als letztes Experiment untersuchte das Team, wie sucherweiterte Modelle iterativ verbessert werden können, um optimale Pläne mit weniger Suchschritten zu berechnen. Ziel ist es, die Länge der Suchtrajektorie zu verkürzen und dennoch die optimale Lösung zu erhalten. Abbildung 8 zeigt, dass die neu vorgeschlagene Methode zur dynamischen Suchführung die Länge der vom Searchformer-Modell generierten Sequenz iterativ verkürzen kann. 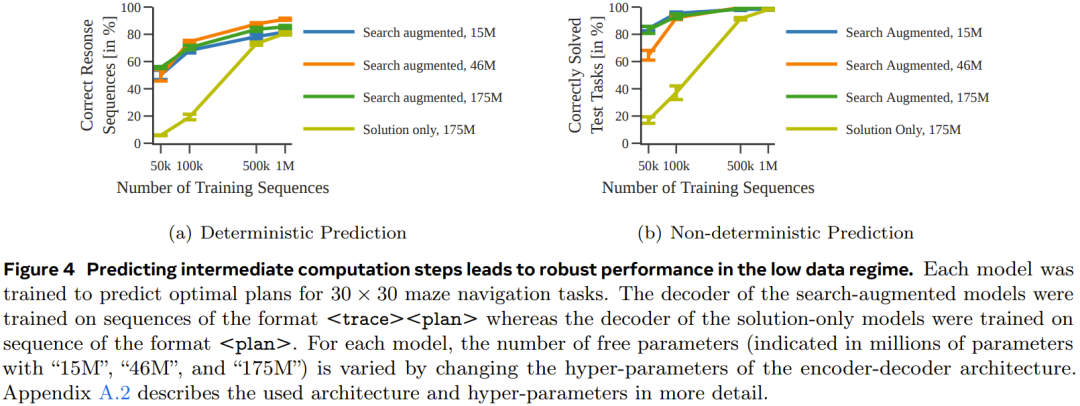

Das obige ist der detaillierte Inhalt vonUm die Mängel der Transformer-Planung auszugleichen, wurde der Searchformer des Tian Yuandong-Teams populär. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 Empfohlene Reihenfolge zum Erlernen von C++ und der C-Sprache
Empfohlene Reihenfolge zum Erlernen von C++ und der C-Sprache
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 Methode zur Reparatur von Datenbankzweifeln
Methode zur Reparatur von Datenbankzweifeln
 Timeout-Lösung für Serveranfragen
Timeout-Lösung für Serveranfragen
 IIS unerwarteter Fehler 0x8ffe2740 Lösung
IIS unerwarteter Fehler 0x8ffe2740 Lösung
 navigator.useragent
navigator.useragent
 So erhalten Sie ein Token
So erhalten Sie ein Token








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



