Die Veröffentlichung von OpenAI Sora am 16. Februar markiert zweifellos einen großen Durchbruch im Bereich der Videogenerierung. Sora basiert auf der Diffusion Transformer-Architektur, die sich von den meisten Mainstream-Methoden auf dem Markt unterscheidet (erweitert um 2D Stable Diffusion). Warum Sora darauf besteht, Diffusion Transformer zu verwenden, die Gründe können aus dem gleichzeitig auf der ICLR 2024 veröffentlichten Artikel (VDT: General-purpose Video Diffusion Transformers via Mask Modeling) entnommen werden. Diese Arbeit wurde vom Forschungsteam der Renmin University of China geleitet und arbeitete mit der University of California, Berkeley, der University of Hong Kong usw. zusammen und wurde erstmals im Mai 2023 auf der arXiv-Website veröffentlicht. Das Forschungsteam schlug ein einheitliches Videogenerierungs-Framework basierend auf Transformer – Video Diffusion Transformer (VDT) vor und erläuterte ausführlich die Gründe für die Einführung der Transformer-Architektur. 
- Papiertitel: VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- Artikeladresse: Openreview: https://openreview.net/pdf?id=Un0rgm9f04
- arXiv-Adresse: https://arxiv.org/abs/2305.13311
- Projektadresse: VDT: Allzweck-Videodiffusionstransformatoren über Maskenmodellierung
- Codeadresse: https://github.com/RERV/VDT
1. Die Überlegenheit und Innovation von VDT Der Forscher sagte, dass sich die Überlegenheit des VDT-Modells unter Verwendung der Transformer-Architektur im Bereich der Videogenerierung widerspiegelt in:
- und U-, das hauptsächlich entworfen wurde Für Bilder kann Transformer mit seinen leistungsstarken Tokenisierungs- und Aufmerksamkeitsmechanismen langfristige oder unregelmäßige Zeitabhängigkeiten erfassen und so die Zeitdimension besser handhaben.
- Nur wenn das Modell Weltwissen (wie Raum-Zeit-Beziehungen und physikalische Gesetze) erlernt (oder auswendig lernt), kann es Videos erzeugen, die mit der realen Welt übereinstimmen. Daher wird die Kapazität des Modells zu einer Schlüsselkomponente der Videoverbreitung. Transformer hat sich als hoch skalierbar erwiesen. Beispielsweise verfügt das PaLM-Modell über bis zu 540 B-Parameter, während die größte 2D-U-Net-Modellgröße damals nur 2,6 B-Parameter (SDXL) betrug, wodurch Transformer besser geeignet ist als 3D-U -Net. Herausforderungen bei der Videogenerierung.
- Der Bereich der Videogenerierung umfasst mehrere Aufgaben, darunter bedingungslose Generierung, Videovorhersage, Interpolation und Text-zu-Bild-Generierung. Frühere Forschungen konzentrierten sich häufig auf eine einzelne Aufgabe und erforderten häufig die Einführung spezieller Module zur Feinabstimmung nachgelagerter Aufgaben. Darüber hinaus beinhalten diese Aufgaben eine Vielzahl von bedingten Informationen, die je nach Frame und Modalität unterschiedlich sein können, was eine leistungsstarke Architektur erfordert, die unterschiedliche Eingabelängen und Modalitäten verarbeiten kann. Die Einführung von Transformer kann diese Aufgaben vereinheitlichen.
Die Innovationen von VDT umfassen hauptsächlich die folgenden Aspekte:
- Anwenden der Transformer-Technologie auf die diffusionsbasierte Videogenerierung, was die Fähigkeiten des Transformers im Bereich der Videogenerierung demonstriert. Riesiges Potenzial . Der Vorteil von VDT ist seine hervorragende zeitabhängige Erfassungsfähigkeit, die die Erzeugung zeitlich kohärenter Videobilder ermöglicht, einschließlich der Simulation der physikalischen Dynamik dreidimensionaler Objekte im Zeitverlauf.
- Schlagen Sie eine einheitliche räumlich-zeitliche Maskenmodellierungsmaschine vor, die es VDT ermöglicht, eine Vielzahl von Videogenerierungsaufgaben zu bewältigen und eine breite Anwendung der Technologie zu erreichen. Die flexiblen bedingten Informationsverarbeitungsmethoden von VDT, wie z. B. einfaches Token-Space-Splicing, vereinheitlichen effektiv Informationen unterschiedlicher Länge und Modalitäten. Gleichzeitig ist VDT durch die Kombination mit dem in dieser Arbeit vorgeschlagenen raumzeitlichen Maskenmodellierungsmechanismus zu einem universellen Videodiffusionswerkzeug geworden, das auf die bedingungslose Generierung, die Vorhersage nachfolgender Videobilder, die Bildinterpolation und die Bildgenerierung angewendet werden kann, ohne das Modell zu ändern Struktur Verschiedene Videogenerierungsaufgaben wie Video- und Videobildschirmvervollständigung.
2. Detaillierte Interpretation der Netzwerkarchitektur von VDT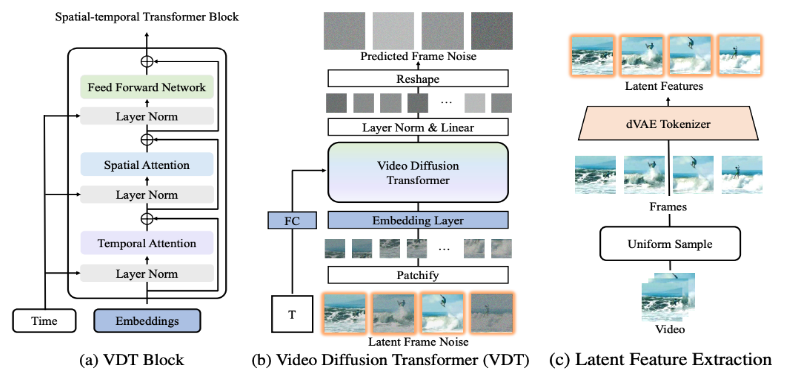 Das VDT-Framework ist dem Sora-Framework sehr ähnlich und besteht aus den folgenden Teilen: Eingabe-/Ausgabefunktionen. Das Ziel von VDT besteht darin, ein F×H×B×3-Videosegment zu generieren, das aus F Videobildern der Größe H×B besteht. Wenn jedoch Rohpixel als Eingabe für VDT verwendet werden, insbesondere wenn F groß ist, führt dies zu einem extrem hohen Rechenaufwand. Um dieses Problem zu lösen, verwendet VDT, inspiriert vom Latent Diffusion Model (LDM), einen vorab trainierten VAE-Tokenizer, um das Video in den Latentraum zu projizieren. Die Reduzierung der Vektordimensionen der Eingabe und Ausgabe auf F×H/8×B/8×C potenzieller Merkmale/Rauschen beschleunigt die Trainings- und Inferenzgeschwindigkeit von VDT, wobei die Größe der latenten Merkmale des F-Frames H/8×W beträgt /8 . Hier ist 8 die Downsampling-Rate des VAE-Tokenizers und C stellt die Dimension des latenten Merkmals dar. Lineare Einbettung. Gemäß dem Vision Transformer-Ansatz unterteilt VDT die latente Videomerkmalsdarstellung in nicht überlappende Patches der Größe N×N. Raum-Zeit-Transformatorblock. Inspiriert durch den Erfolg der räumlich-zeitlichen Selbstaufmerksamkeit in der Videomodellierung fügte VDT eine zeitliche Aufmerksamkeitsschicht in den Transformer Block ein, um Möglichkeiten zur Modellierung zeitlicher Dimensionen zu erhalten. Insbesondere besteht jeder Transformatorblock aus einer zeitlichen Mehrkopf-Aufmerksamkeit, einer räumlichen Mehrkopf-Aufmerksamkeit und einem vollständig verbundenen Feed-Forward-Netzwerk, wie in der Abbildung oben dargestellt. Ein Vergleich des neuesten technischen Berichts von Sora zeigt, dass es nur einige subtile Unterschiede in den Implementierungsdetails zwischen VDT und Sora gibt . Zunächst übernimmt VDT die Methode, den Aufmerksamkeitsmechanismus separat in der räumlich-zeitlichen Dimension zu verarbeiten, während Sora die Zeit- und Raumdimensionen zusammenführt und ihn durch einen einzigen Aufmerksamkeitsmechanismus verarbeitet. Dieser Ansatz der Trennung der Aufmerksamkeit ist im Videobereich weit verbreitet und wird oft als Kompromissoption im Hinblick auf die Einschränkungen des Videospeichers angesehen. Aufgrund der begrenzten Rechenressourcen entscheidet sich VDT für die Verwendung der geteilten Aufmerksamkeit. Soras leistungsstarke videodynamische Fähigkeiten können auf dem allgemeinen Aufmerksamkeitsmechanismus von Raum und Zeit beruhen. Zweitens berücksichtigt Sora im Gegensatz zu VDT auch die Verschmelzung von Textbedingungen. Es gibt auch frühere Untersuchungen zur bedingten Textfusion auf Basis von Transformer (wie DiT). Es wird spekuliert, dass Sora seinem Modul zusätzlich einen Cross-Attention-Mechanismus hinzufügen könnte mögliche Möglichkeit. Während des Forschungsprozesses von VDT ersetzten Forscher U-Net, ein häufig verwendetes Basis-Backbone-Netzwerk, durch Transformer. Dies bestätigte nicht nur die Wirksamkeit von Transformer bei Videoverbreitungsaufgaben und zeigte die Vorteile einer einfachen Erweiterung und verbesserten Kontinuität auf, sondern regte auch dazu an, weiter über seinen potenziellen Wert nachzudenken. Mit dem Erfolg des GPT-Modells und der Beliebtheit des autoregressiven (AR) Modells haben Forscher begonnen, tiefergehende Anwendungen von Transformer im Bereich der Videogenerierung zu erforschen und zu prüfen, ob es einen neuen Weg zur Erreichung dieser Ziele bieten kann visuelle Intelligenz. Der Bereich der Videogenerierung hat eine eng damit verbundene Aufgabe – die Videovorhersage. Die Idee, das nächste Videobild als Weg zur visuellen Intelligenz vorherzusagen, mag einfach erscheinen, ist aber tatsächlich ein allgemeines Anliegen vieler Forscher. Basierend auf dieser Überlegung hoffen Forscher, ihre Modelle für Videovorhersageaufgaben weiter anpassen und optimieren zu können. Die Videovorhersageaufgabe kann auch als bedingte Generierung betrachtet werden, bei der die gegebenen bedingten Frames die ersten paar Frames des Videos sind. VDT berücksichtigt hauptsächlich die folgenden drei Methoden zur Bedingungsgenerierung:
Das VDT-Framework ist dem Sora-Framework sehr ähnlich und besteht aus den folgenden Teilen: Eingabe-/Ausgabefunktionen. Das Ziel von VDT besteht darin, ein F×H×B×3-Videosegment zu generieren, das aus F Videobildern der Größe H×B besteht. Wenn jedoch Rohpixel als Eingabe für VDT verwendet werden, insbesondere wenn F groß ist, führt dies zu einem extrem hohen Rechenaufwand. Um dieses Problem zu lösen, verwendet VDT, inspiriert vom Latent Diffusion Model (LDM), einen vorab trainierten VAE-Tokenizer, um das Video in den Latentraum zu projizieren. Die Reduzierung der Vektordimensionen der Eingabe und Ausgabe auf F×H/8×B/8×C potenzieller Merkmale/Rauschen beschleunigt die Trainings- und Inferenzgeschwindigkeit von VDT, wobei die Größe der latenten Merkmale des F-Frames H/8×W beträgt /8 . Hier ist 8 die Downsampling-Rate des VAE-Tokenizers und C stellt die Dimension des latenten Merkmals dar. Lineare Einbettung. Gemäß dem Vision Transformer-Ansatz unterteilt VDT die latente Videomerkmalsdarstellung in nicht überlappende Patches der Größe N×N. Raum-Zeit-Transformatorblock. Inspiriert durch den Erfolg der räumlich-zeitlichen Selbstaufmerksamkeit in der Videomodellierung fügte VDT eine zeitliche Aufmerksamkeitsschicht in den Transformer Block ein, um Möglichkeiten zur Modellierung zeitlicher Dimensionen zu erhalten. Insbesondere besteht jeder Transformatorblock aus einer zeitlichen Mehrkopf-Aufmerksamkeit, einer räumlichen Mehrkopf-Aufmerksamkeit und einem vollständig verbundenen Feed-Forward-Netzwerk, wie in der Abbildung oben dargestellt. Ein Vergleich des neuesten technischen Berichts von Sora zeigt, dass es nur einige subtile Unterschiede in den Implementierungsdetails zwischen VDT und Sora gibt . Zunächst übernimmt VDT die Methode, den Aufmerksamkeitsmechanismus separat in der räumlich-zeitlichen Dimension zu verarbeiten, während Sora die Zeit- und Raumdimensionen zusammenführt und ihn durch einen einzigen Aufmerksamkeitsmechanismus verarbeitet. Dieser Ansatz der Trennung der Aufmerksamkeit ist im Videobereich weit verbreitet und wird oft als Kompromissoption im Hinblick auf die Einschränkungen des Videospeichers angesehen. Aufgrund der begrenzten Rechenressourcen entscheidet sich VDT für die Verwendung der geteilten Aufmerksamkeit. Soras leistungsstarke videodynamische Fähigkeiten können auf dem allgemeinen Aufmerksamkeitsmechanismus von Raum und Zeit beruhen. Zweitens berücksichtigt Sora im Gegensatz zu VDT auch die Verschmelzung von Textbedingungen. Es gibt auch frühere Untersuchungen zur bedingten Textfusion auf Basis von Transformer (wie DiT). Es wird spekuliert, dass Sora seinem Modul zusätzlich einen Cross-Attention-Mechanismus hinzufügen könnte mögliche Möglichkeit. Während des Forschungsprozesses von VDT ersetzten Forscher U-Net, ein häufig verwendetes Basis-Backbone-Netzwerk, durch Transformer. Dies bestätigte nicht nur die Wirksamkeit von Transformer bei Videoverbreitungsaufgaben und zeigte die Vorteile einer einfachen Erweiterung und verbesserten Kontinuität auf, sondern regte auch dazu an, weiter über seinen potenziellen Wert nachzudenken. Mit dem Erfolg des GPT-Modells und der Beliebtheit des autoregressiven (AR) Modells haben Forscher begonnen, tiefergehende Anwendungen von Transformer im Bereich der Videogenerierung zu erforschen und zu prüfen, ob es einen neuen Weg zur Erreichung dieser Ziele bieten kann visuelle Intelligenz. Der Bereich der Videogenerierung hat eine eng damit verbundene Aufgabe – die Videovorhersage. Die Idee, das nächste Videobild als Weg zur visuellen Intelligenz vorherzusagen, mag einfach erscheinen, ist aber tatsächlich ein allgemeines Anliegen vieler Forscher. Basierend auf dieser Überlegung hoffen Forscher, ihre Modelle für Videovorhersageaufgaben weiter anpassen und optimieren zu können. Die Videovorhersageaufgabe kann auch als bedingte Generierung betrachtet werden, bei der die gegebenen bedingten Frames die ersten paar Frames des Videos sind. VDT berücksichtigt hauptsächlich die folgenden drei Methoden zur Bedingungsgenerierung:
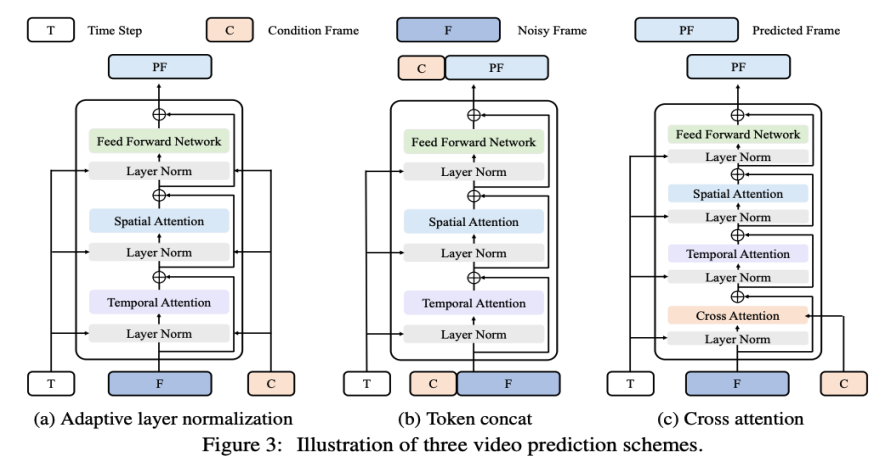
Adaptive Layer-Normalisierung. Eine einfache Möglichkeit, eine Videovorhersage zu erreichen, besteht darin, bedingte Rahmenmerkmale in die Schichtnormalisierung von VDT-Blöcken zu integrieren, ähnlich wie wir zeitliche Informationen in den Diffusionsprozess integrieren. Queraufmerksamkeit. Forscher haben auch die Verwendung von Kreuzaufmerksamkeit als Videovorhersageschema untersucht, bei dem bedingte Frames als Schlüssel und Werte und Rauschframes als Abfragen verwendet werden. Dies ermöglicht die Fusion von bedingten Informationen mit Rauschrahmen. Bevor Sie die Queraufmerksamkeitsschicht betreten, extrahieren Sie mit dem VAE-Tokenizer die Funktionen des bedingten Rahmens und patchen sie. Mittlerweile werden auch räumliche und zeitliche Positionseinbettungen hinzugefügt, um unserem VDT dabei zu helfen, die entsprechenden Informationen in bedingten Frames zu lernen. Token-Splicing. Das VDT-Modell verwendet eine reine Transformer-Architektur, daher ist die direkte Verwendung von bedingten Frames als Eingabetoken eine intuitivere Methode für VDT. Dies erreichen wir durch die Verkettung von konditionierten Frames (latenten Merkmalen) und Noise-Frames auf Token-Ebene, die dann in den VDT eingespeist werden. Als nächstes segmentierten sie die Ausgabe-Frame-Sequenz von VDT und nutzten die vorhergesagten Frames, um einen Diffusionsprozess durchzuführen, wie in Abbildung 3 (b) dargestellt. Die Forscher fanden heraus, dass dieses Schema im Vergleich zu den ersten beiden Methoden die schnellste Konvergenzgeschwindigkeit aufwies und bei den Endergebnissen eine bessere Leistung lieferte. Darüber hinaus stellten die Forscher fest, dass VDT auch dann bedingte Frames mit fester Länge während des Trainings verwenden kann, wenn sie bedingte Frames beliebiger Länge als Eingabe- und Ausgabekonsistente Vorhersagemerkmale akzeptieren können. Um die Videovorhersageaufgabe im Rahmen von VDT zu erfüllen, müssen keine Änderungen an der Netzwerkstruktur vorgenommen werden, sondern nur die Eingabe des Modells muss geändert werden. Diese Erkenntnis führt zu einer intuitiven Frage: Können wir diese Skalierbarkeit weiter nutzen, um VDT auf vielfältigere Videogenerierungsaufgaben auszudehnen – wie zum Beispiel die Bildgenerierung von Videos –, ohne zusätzliche Module oder Parameter einzuführen ? Bei der Überprüfung der Fähigkeiten von VDT bei der bedingungslosen Generierung und Videovorhersage besteht der einzige Unterschied in der Art der Eingabefunktionen. Insbesondere kann die Eingabe rein verrauschte latente Merkmale oder eine Verkettung von bedingten und verrauschten latenten Merkmalen sein. Anschließend führte der Forscher die einheitliche räumlich-zeitliche Maskenmodellierung ein, um die bedingte Eingabe zu vereinheitlichen, wie in Abbildung 4 unten dargestellt: 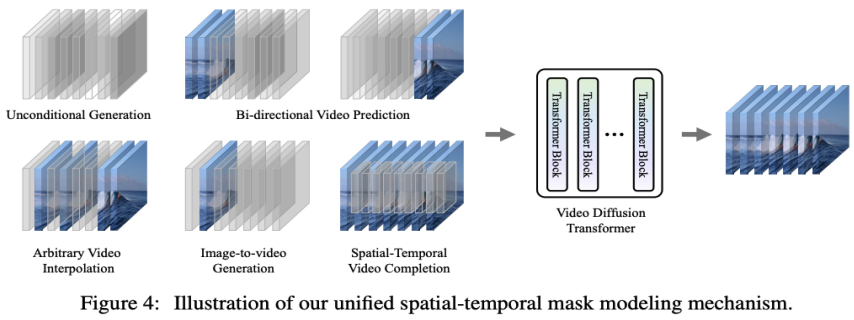
3. Leistungsbewertung von VDT Durch die obige Methode kann das VDT-Modell nicht nur bedingungslose Videogenerierungs- und Videovorhersageaufgaben nahtlos verarbeiten, sondern kann durch einfaches Anpassen auch auf einen breiteren Bereich von Videogenerierungsfeldern wie Video erweitert werden die Eingabefunktionen. Diese Verkörperung von Flexibilität und Skalierbarkeit zeigt das leistungsstarke Potenzial des VDT-Frameworks und bietet neue Richtungen und Möglichkeiten für die zukünftige Videogenerierungstechnologie. 
Interessanterweise demonstrierte OpenAI neben Text-to-Video auch andere erstaunliche Aufgaben von Sora, einschließlich der bildbasierten Generierung, der Vorder- und Rückseitenvideovorhersage und Beispielen für die Fusion verschiedener Videoclips usw. usw Die von den Forschern vorgeschlagenen Downstream-Aufgaben, die durch Unified Spatial-Temporal Mask Modeling unterstützt werden, sind auch in den Referenzen sehr ähnlich. Daher wird spekuliert, dass die unterste Schicht von Sora ebenfalls eine MAE-ähnliche Trainingsmethode verwendet. Forscher untersuchten auch die Simulation einfacher physikalischer Gesetze durch das generative Modell VDT. Sie führten Experimente mit dem Physion-Datensatz durch, wobei VDT die ersten 8 Frames als bedingte Frames verwendet und die nächsten 8 Frames vorhersagt. Im ersten Beispiel (obere zwei Reihen) und im dritten Beispiel (untere zwei Reihen) simuliert VDT erfolgreich physikalische Prozesse, bei denen ein Ball sich entlang einer parabolischen Flugbahn bewegt und ein Ball auf einer Ebene rollt und mit einem Zylinder kollidiert. Im zweiten Beispiel (mittlere zwei Reihen) erfasst der VDT die Geschwindigkeit/den Impuls des Balls, wenn er zum Stillstand kommt, bevor er den Zylinder trifft. Dies beweist, dass die Transformer-Architektur bestimmte physikalische Gesetze lernen kann. 
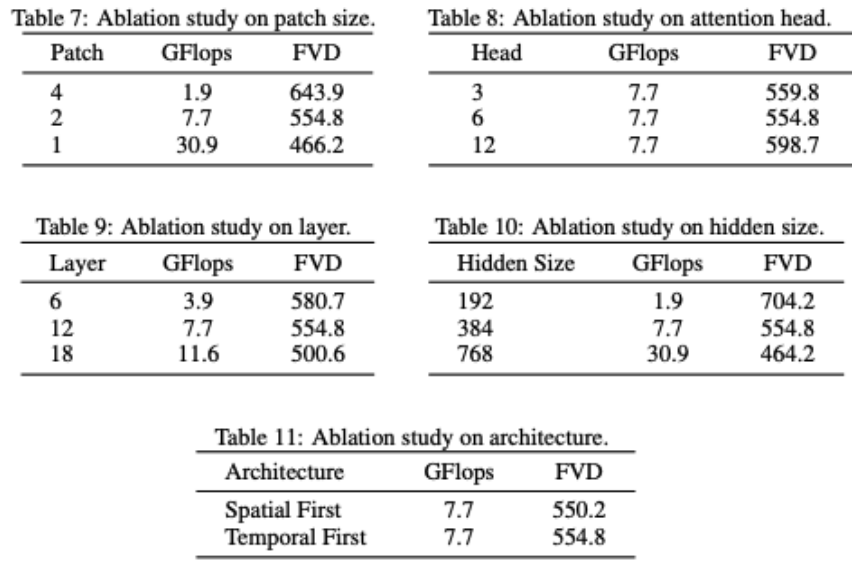
VDT trägt die Netzwerkstruktur teilweise ab. Es lässt sich feststellen, dass die Modellleistung stark mit GFlops zusammenhängt und einige Details der Modellstruktur selbst keinen großen Einfluss haben. Dies steht auch im Einklang mit den Ergebnissen von DiT. Die Forscher führten auch einige strukturelle Ablationsstudien am VDT-Modell durch. Die Ergebnisse zeigen, dass eine Reduzierung der Patchgröße, eine Erhöhung der Anzahl der Ebenen und eine Erhöhung der versteckten Größe die Leistung des Modells weiter verbessern kann. Der Ort der zeitlichen und räumlichen Aufmerksamkeit sowie die Anzahl der Aufmerksamkeitsköpfe haben kaum Einfluss auf die Ergebnisse des Modells. Es sind einige Designkompromisse erforderlich, aber insgesamt gibt es keinen signifikanten Unterschied in der Modellleistung bei Beibehaltung der gleichen GFlops. Eine Erhöhung der GFlops führt jedoch zu besseren Ergebnissen und demonstriert die Skalierbarkeit der VDT- oder Transformer-Architektur. Die Testergebnisse von VDT zeigen die Wirksamkeit und Flexibilität der Transformer-Architektur bei der Verarbeitung der Videodatengenerierung. Aufgrund begrenzter Rechenressourcen wurden VDT-Experimente nur an einigen kleinen akademischen Datensätzen durchgeführt. Wir freuen uns auf zukünftige Forschungen zur weiteren Erforschung neuer Richtungen und Anwendungen der auf VDT basierenden Videoerzeugungstechnologie und freuen uns auch darauf, dass chinesische Unternehmen so bald wie möglich inländische Sora-Modelle auf den Markt bringen. Das obige ist der detaillierte Inhalt vonInländische Universitäten bauen ein Sora-ähnliches VDT-Modell, und der universelle Videodiffusionstransformer wurde von der ICLR 2024 akzeptiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
Der Unterschied zwischen PD-Schnellladen und allgemeinem Schnellladen
 So generieren Sie eine Bin-Datei mit MDK
So generieren Sie eine Bin-Datei mit MDK
 Zu welcher Währung gehört USDT?
Zu welcher Währung gehört USDT?
 ISP-Chip
ISP-Chip
 Was soll ich tun, wenn Chaturbate hängen bleibt?
Was soll ich tun, wenn Chaturbate hängen bleibt?
 Was ist ein optisches Laufwerk?
Was ist ein optisches Laufwerk?
 ps Vollbild-Tastenkombination beenden
ps Vollbild-Tastenkombination beenden
 Grundbausteine von Präsentationen
Grundbausteine von Präsentationen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



