


Sind Sie schon einmal auf verschiedene Speicherprobleme in Linux-Systemen gestoßen? Wie Speicherlecks, Speicherfragmentierung usw. Diese Probleme können durch ein tiefes Verständnis des Linux-Speichermodells gelöst werden.
Der Linux-Kernel unterstützt drei Speichermodelle, nämlich das Flat-Memory-Modell, das Discontiguous-Memory-Modell und das Sparse-Memory-Modell. Das sogenannte Speichermodell bezieht sich tatsächlich auf die Verteilung des physischen Speichers aus Sicht der CPU und die Methode zur Verwaltung dieser physischen Speicher im Linux-Kernel. Darüber hinaus ist zu beachten, dass sich dieser Artikel hauptsächlich auf Shared-Memory-Systeme konzentriert, was bedeutet, dass sich alle CPUs einen physischen Adressraum teilen.
Der Inhalt dieses Artikels ist wie folgt aufgebaut: Um das Speichermodell klar zu analysieren, beschreiben wir einige Grundbegriffe, die in Kapitel 2 enthalten sind. Das dritte Kapitel erläutert die Funktionsprinzipien der drei Speichermodelle. Der Code stammt aus dem 4.4.6-Kernel. Für den architekturbezogenen Code verwenden wir ARM64.
1. Was ist ein Seitenrahmen?
Eine der wichtigsten Funktionen des Betriebssystems ist die Verwaltung verschiedener Ressourcen im Computersystem. Als wichtigste Ressource: den Speicher, müssen wir ihn verwalten. Im Linux-Betriebssystem wird der physische Speicher entsprechend der Seitengröße verwaltet. Die spezifische Seitengröße hängt von der Hardware ab und die Linux-Systemkonfiguration ist die klassischste Einstellung. Daher teilen wir den physischen Speicher in Seiten auf, die nach Seitengröße geordnet sind. Der Speicherbereich der Seitengröße in jedem physischen Speicher wird als Seitenrahmen bezeichnet. Wir erstellen eine Strukturseitendatenstruktur für jeden physischen Seitenrahmen, um die Nutzung jeder physischen Seite zu verfolgen: Wird sie für das Textsegment des Kernels verwendet? Oder ist es eine Seitentabelle für einen Prozess? Wird es für verschiedene Datei-Caches verwendet oder befindet es sich in einem freien Zustand...
Jeder Seitenrahmen verfügt über eine eins-zu-eins entsprechende Seitendatenstruktur, um die Seitenrahmennummer und die Seitendatenstruktur zu konvertieren. In Kapitel 3 werden wir darauf eingehen. Die drei Speichermodelle im Linux-Kernel werden ausführlich beschrieben.
2. Was ist PFN?
Für ein Computersystem sollte der gesamte physische Adressraum ein Adressraum sein, der bei 0 beginnt und mit dem maximalen physischen Speicherplatz endet, den das tatsächliche System unterstützen kann. Unter der Annahme, dass die physische Adresse im ARM-System 32 Bit beträgt, beträgt der physische Adressraum 4G. Wenn im ARM64-System die Anzahl der unterstützten physischen Adressbits 48 beträgt, beträgt der physische Adressraum 256T. Tatsächlich wird natürlich nicht jeder so große physische Adressraum für den Speicher verwendet, einige gehören auch zum E/A-Bereich (natürlich verfügen einige CPU-Architekturen über einen eigenen unabhängigen E/A-Adressraum). Daher sollte der vom Speicher belegte physische Adressraum ein begrenztes Intervall sein und es ist unmöglich, den gesamten physischen Adressraum abzudecken. Da der Speicher jedoch immer größer wird, kann der physische 4G-Adressraum für 32-Bit-Systeme die Speicheranforderungen nicht mehr erfüllen. Daher gibt es das Konzept des hohen Speichers, das später ausführlich beschrieben wird.
PFN ist die Abkürzung für Seitenrahmennummer. Der sogenannte Seitenrahmen bezieht sich auf den physischen Speicher, der in Bereiche der Seitengröße unterteilt ist. Diese Nummer ist PFN. Unter der Annahme, dass der physische Speicher bei Adresse 0 beginnt, ist der Seitenrahmen mit PFN gleich 0 die Seite, die bei Adresse 0 (physikalische Adresse) beginnt. Unter der Annahme, dass der physische Speicher bei Adresse x beginnt, lautet die erste Seitenrahmennummer (x>>PAGE_SHIFT).
3. Was ist NUMA?
Beim Entwurf einer Speicherarchitektur für Multiprozessorsysteme gibt es zwei Optionen: Eine davon ist UMA (Uniform Memory Access). Alle Prozessoren im System teilen sich einen einheitlichen und konsistenten physischen Speicherraum, unabhängig davon, welcher Prozessor den Zugriff auf die Speicheradresse initiiert ist dasselbe. NUMA (Non-Uniform Memory Access) unterscheidet sich von UMA. Der Zugriff auf eine bestimmte Speicheradresse hängt von der relativen Position zwischen Speicher und Prozessor ab. Beispielsweise dauert der Zugriff auf den lokalen Speicher für einen Prozessor auf einem Knoten länger als auf den Remote-Speicher.
1. Was ist das FLAT-Speichermodell?
Wenn aus der Sicht eines Prozessors im System beim Zugriff auf den physischen Speicher der physische Adressraum ein kontinuierlicher Adressraum ohne Lücken ist, dann ist das Speichermodell dieses Computersystems ein flacher Speicher. Bei diesem Speichermodell ist die Verwaltung des physischen Speichers relativ einfach. Jeder physische Seitenrahmen verfügt über eine Seitendatenstruktur, um ihn zu abstrahieren. Daher gibt es im System ein Array von Strukturseiten (mem_map), auf die jeder Array-Eintrag verweist ein tatsächlicher physischer Seitenrahmen (Seitenrahmen). Bei flachem Speicher ist die Beziehung zwischen PFN (Seitenrahmennummer) und mem_map-Array-Index linear (es gibt einen festen Versatz. Wenn die dem Speicher entsprechende physische Adresse gleich 0 ist, ist PFN der Array-Index). Daher ist es sehr einfach, von PFN zur entsprechenden Seitendatenstruktur zu wechseln und umgekehrt. Weitere Informationen finden Sie in den Definitionen von page_to_pfn und pfn_to_page. Darüber hinaus gibt es für das flache Speichermodell nur einen Knoten (struct pglist_data) (um den gleichen Mechanismus wie das diskontinuierliche Speichermodell zu verwenden). Das Bild unten beschreibt die Situation des flachen Speichers:
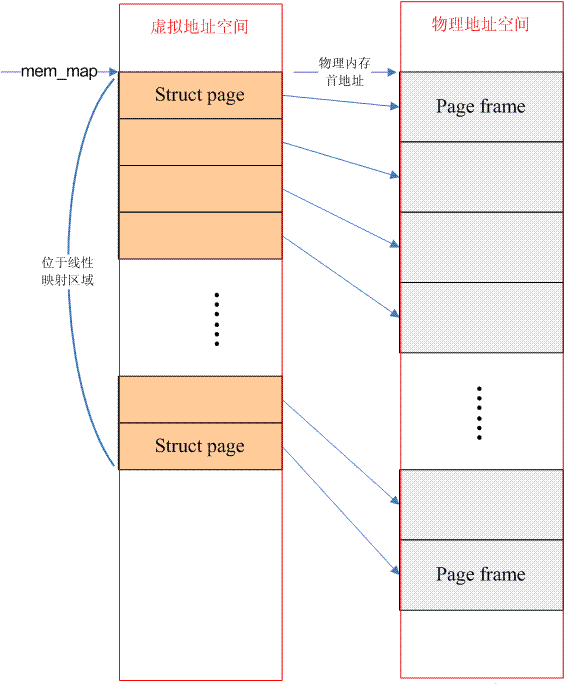
Es sollte betont werden, dass der von der Strukturseite belegte Speicher im direkt zugeordneten Bereich liegt, sodass das Betriebssystem keine Seitentabelle dafür erstellen muss.
2. Was ist ein diskontinuierliches Speichermodell?
Wenn der Adressraum der CPU einige Lücken aufweist und beim Zugriff auf den physischen Speicher diskontinuierlich ist, dann ist das Speichermodell dieses Computersystems diskontinuierlicher Speicher. Im Allgemeinen ist das Speichermodell eines NUMA-basierten Computersystems diskontinuierlicher Speicher. Die beiden Konzepte sind jedoch tatsächlich unterschiedlich. NUMA betont die Positionsbeziehung zwischen Speicher und Prozessor, die nichts mit dem Speichermodell zu tun hat. Da jedoch Speicher und Prozessor auf demselben Knoten eine engere Kopplungsbeziehung haben (schnellerer Zugriff), sind mehrere Knoten erforderlich, um ihn zu verwalten. Diskontinuierlicher Speicher ist im Wesentlichen eine Erweiterung des Speichermodells mit flachem Speicher. Der größte Teil des Adressraums des gesamten physischen Speichers ist ein großer Teil des Speichers, mit einigen Lücken in der Mitte. Jeder Teil des Speicheradressraums gehört zu einem Knoten ist auf eins beschränkt. Intern ist das Speichermodell des Knotens ein flacher Speicher. Das Bild unten beschreibt die Situation des diskontinuierlichen Gedächtnisses:
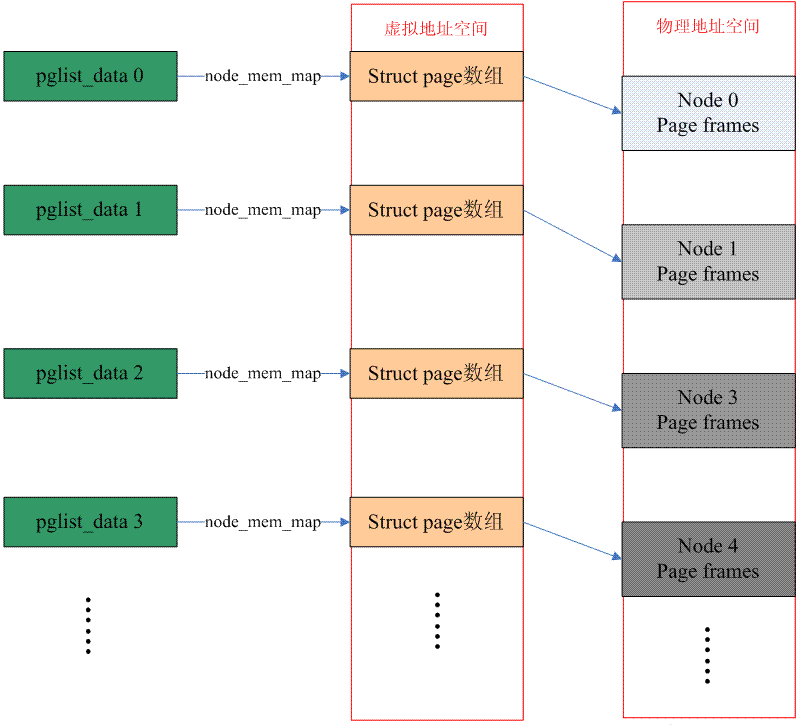
Daher gibt es unter diesem Speichermodell mehrere Knotendaten (Struktur pglist_data), und die Makrodefinition NODE_DATA kann die Struktur pglist_data des angegebenen Knotens abrufen. Der von jedem Knoten verwaltete physische Speicher wird jedoch im Mitglied node_mem_map der Datenstruktur struct pglist_data gespeichert (das Konzept ähnelt mem_map im flachen Speicher). Zu diesem Zeitpunkt wird die Konvertierung von PFN in eine bestimmte Strukturseite etwas komplizierter sein. Zuerst müssen wir die Knoten-ID von PFN abrufen und dann die entsprechende pglist_data-Datenstruktur basierend auf dieser ID und dann das entsprechende Seitenarray finden . Die nachfolgende Methode ist ein ähnlicher Flat-Memory.
3. Was ist ein Sparse-Memory-Modell?
Speichermodell ist auch ein evolutionärer Prozess. Zu Beginn wurde flacher Speicher verwendet, um einen kontinuierlichen Speicheradressraum (mem_maps[]) zu abstrahieren. Nach dem Aufkommen von NUMA wurde der gesamte diskontinuierliche Speicherraum in mehrere Knoten unterteilt Es handelt sich um einen kontinuierlichen Speicheradressraum, das heißt, aus den ursprünglichen einzelnen mem_maps [] sind mehrere mem_maps [] geworden. Alles scheint perfekt zu sein, aber das Aufkommen von Speicher-Hotplugs macht das ursprüngliche perfekte Design unvollkommen, da sogar mem_maps[] in einem Knoten diskontinuierlich sein können. Tatsächlich ist das diskontinuierliche Speichermodell nach dem Aufkommen nicht mehr so wichtig. Es liegt auf der Hand, dass spärlicher Speicher den diskontinuierlichen Speicher ersetzen kann. Der 4.4-Kernel verfügt noch über drei Speichermodelle wähle aus.
Warum heißt es, dass spärlicher Speicher letztendlich diskontinuierlichen Speicher ersetzen kann? Tatsächlich ist der kontinuierliche Adressraum im Sparse-Memory-Speichermodell in Abschnitte unterteilt (z. B. 1G), und jeder Abschnitt ist hotplugged. Daher kann der Speicheradressraum im Sparse-Speicher in mehrere Abschnitte unterteilt werden Detaillierte Abschnitte, unterstützt diskreteren diskontinuierlichen Speicher. Darüber hinaus standen NUMA und diskontinuierlicher Speicher vor dem Aufkommen von spärlichem Speicher immer in einer verwirrenden Beziehung: NUMA legte die Kontinuität seines Speichers nicht fest, und das diskontinuierliche Speichersystem war nicht unbedingt ein NUMA-System, aber diese beiden Konfigurationen sind alle multi- Knoten. Mit Sparse Memory können wir das Konzept der Speicherkontinuität endlich von NUMA trennen: Ein NUMA-System kann Flat Memory oder Sparse Memory sein, und ein Sparse Memory-System kann NUMA oder UMA sein.
Das Bild unten zeigt, wie Sparse-Speicher Seitenrahmen verwaltet (SPARSEMEM_EXTREME ist konfiguriert):
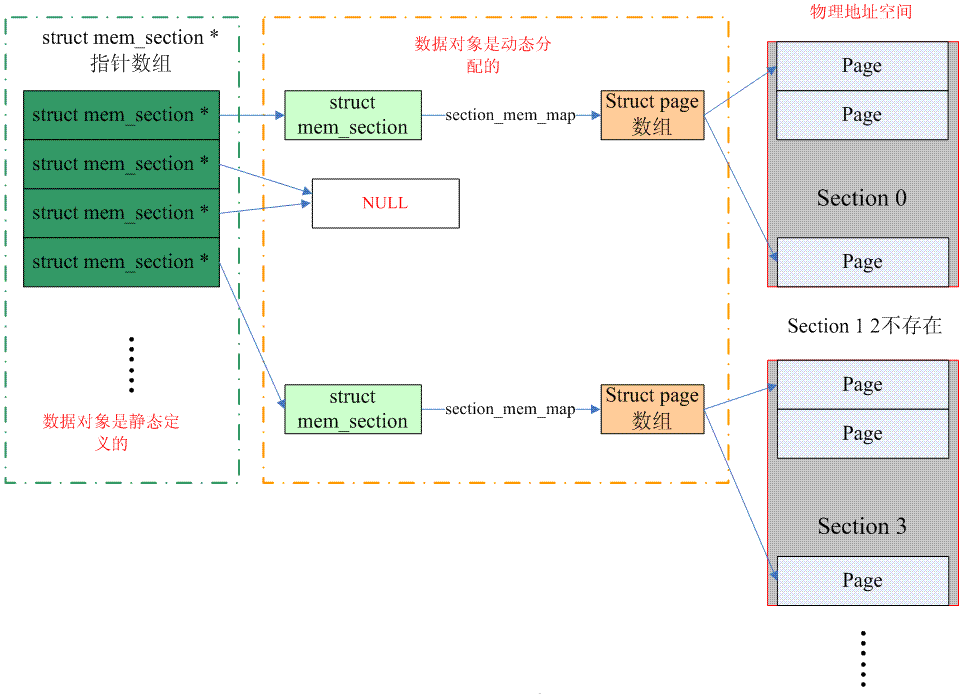
(Hinweis: Ein mem_section-Zeiger im obigen Bild sollte auf eine Seite zeigen, und es gibt mehrere struct mem_section-Dateneinheiten auf einer Seite)
Der gesamte kontinuierliche physische Adressraum wird abschnittsweise abgeschnitten. Der Speicher jedes Abschnitts ist kontinuierlich (das heißt, er entspricht den Eigenschaften des flachen Speichers. Daher ist das Seitenarray von mem_map an die Abschnittsstruktur angehängt. struct mem_section) Anstelle der Knotenstruktur (struct pglist_data). Unabhängig davon, welches Speichermodell verwendet wird, muss natürlich die Korrespondenz zwischen PFN und Seite verarbeitet werden. Sparse-Speicher verfügt jedoch über ein zusätzliches Abschnittskonzept, das die Konvertierung in PFNSectionpage ermöglicht.
Sehen wir uns zunächst an, wie man von PFN in eine Seitenstruktur konvertiert: Ein mem_section-Zeigerarray ist statisch im Kernel definiert. Ein Abschnitt umfasst oft mehrere Seiten, daher ist es notwendig, PFN durch Rechtsverschiebung unter Verwendung der Abschnittsnummer in eine Abschnittsnummer umzuwandeln. Für den Index kann die dem PFN entsprechende Abschnittsdatenstruktur im mem_section-Zeigerarray gefunden werden. Nachdem Sie den Abschnitt gefunden haben, können Sie die entsprechende Seitendatenstruktur entlang seiner section_mem_map finden. Übrigens verwendete Sparse-Speicher am Anfang ein eindimensionales Array „memory_section“ (kein Zeiger-Array). Diese Implementierung verschwendet sehr viel Speicher für besonders spärliche Systeme (CONFIG_SPARSEMEM_EXTREME). Darüber hinaus ist es bequemer, den Zeiger für die Hotplug-Unterstützung zu speichern. Wenn der Zeiger gleich NULL ist, bedeutet dies, dass der Abschnitt nicht vorhanden ist. Das obige Bild beschreibt die Situation eines eindimensionalen mem_section-Zeigerarrays (SPARSEMEM_EXTREME ist konfiguriert). Das Konzept ist ähnlich. Sie können den Code für die spezifische Operation lesen.
Es ist etwas mühsam, von der Seite zum PFN zu wechseln. Tatsächlich ist PFN in zwei Teile unterteilt: Ein Teil ist der Abschnittsindex und der andere Teil ist der Versatz der Seite im Abschnitt. Wir müssen zuerst den Abschnittsindex von der Seite und dann den entsprechenden Speicherabschnitt abrufen. Wenn wir den Speicherabschnitt kennen, wissen wir, dass sich die Seite in der Abschnittsspeicherkarte befindet, und wir kennen auch den Versatz der Seite im Abschnitt . Für die Konvertierung von Seiten in Abschnittsindizes gibt es für spärlichen Speicher zwei Lösungen. Schauen wir uns zunächst die klassische Lösung an, die in page->flags gespeichert wird (SECTION_IN_PAGE_FLAGS ist konfiguriert). Das größte Problem bei dieser Methode besteht darin, dass die Anzahl der Bits in page->flags nicht unbedingt ausreicht, da dieses Flag zu viele Informationen enthält. Verschiedene Seitenflags, Knoten-IDs und Zonen-IDs fügen nun eine Abschnitts-ID hinzu, die nicht erreicht werden kann Konsistenz in verschiedenen Architekturen. Gibt es einen universellen Algorithmus? Dies ist CONFIG_SPARSEMEM_VMEMMAP. Den spezifischen Algorithmus finden Sie in der folgenden Abbildung:
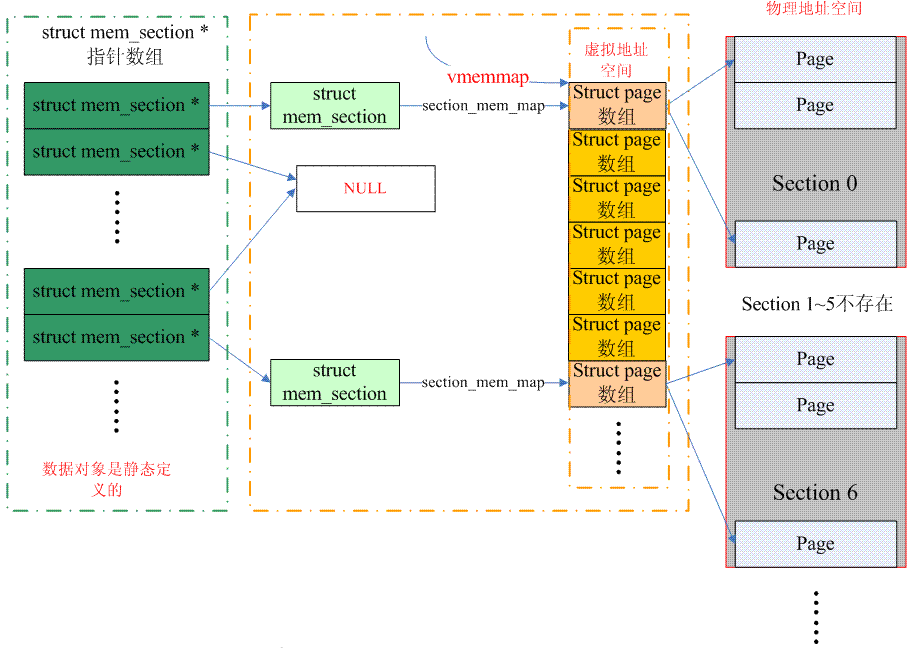
(Es gibt ein Problem mit dem Bild oben. vmemmap zeigt nur auf das erste Strukturseitenarray, wenn PHYS_OFFSET gleich 0 ist. Im Allgemeinen sollte es einen Offset geben, aber ich bin zu faul, ihn zu ändern, haha)
Beim klassischen Sparse-Memory-Modell stammt der vom Strukturseitenarray eines Abschnitts belegte Speicher aus dem direkt zugeordneten Bereich. Die Seitentabelle wird während der Initialisierung erstellt und der Seitenrahmen zugewiesen, was bedeutet, dass die virtuelle Adresse zugewiesen wird. Für SPARSEMEM_VMEMMAP wird die virtuelle Adresse jedoch von Anfang an zugewiesen. Es handelt sich um einen kontinuierlichen virtuellen Adressraum, der von vmemmap ausgeht. Natürlich gibt es nur eine virtuelle Adresse und keine physische Adresse. Wenn also ein Abschnitt erkannt wird, kann die virtuelle Adresse der entsprechenden Strukturseite sofort gefunden werden. Natürlich ist es auch erforderlich, einen physischen Seitenrahmen zuzuweisen und dann eine Seitentabelle einzurichten. Der Overhead wird etwas größer sein (ein weiterer Prozess zur Erstellung der Zuordnung).
4. Code-Analyse
Unsere Code-Analyse erfolgt hauptsächlich über include/asm-generic/memory_model.h.
1. Flaches Gedächtnis. Der Code lautet wie folgt:
“
\#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) \#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)Nach dem Login kopieren“
Aus dem Code geht hervor, dass PFN und der Index des Strukturseitenarrays (mem_map) linear miteinander verbunden sind und es einen festen Offset namens ARCH_PFN_OFFSET gibt. Dieser Offset hängt mit der geschätzten Architektur zusammen. Für ARM64 ist es in der Datei arch/arm/include/asm/memory.h definiert. Diese Definition bezieht sich natürlich auf den vom Speicher belegten physischen Adressraum (dh auf die Definition von PHYS_OFFSET).
2. Diskontinuierliches Speichermodell. Der Code lautet wie folgt:
“
\#define __pfn_to_page(pfn) \ ({ unsigned long __pfn = (pfn); \ unsigned long __nid = arch_pfn_to_nid(__pfn); \ NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\ }) \#define __page_to_pfn(pg) \ ({ const struct page *__pg = (pg); \ struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \ (unsigned long)(__pg - __pgdat->node_mem_map) + \ __pgdat->node_start_pfn; \ })Nach dem Login kopieren”
Discontiguous Memory Model需要获取node id,只要找到node id,一切都好办了,比对flat memory model进行就OK了。因此对于__pfn_to_page的定义,可以首先通过arch_pfn_to_nid将PFN转换成node id,通过NODE_DATA宏定义可以找到该node对应的pglist_data数据结构,该数据结构的node_start_pfn记录了该node的第一个page frame number,因此,也就可以得到其对应struct page在node_mem_map的偏移。__page_to_pfn类似,大家可以自己分析。
3、Sparse Memory Model。经典算法的代码我们就不看了,一起看看配置了SPARSEMEM_VMEMMAP的代码,如下:
“
\#define __pfn_to_page(pfn) (vmemmap + (pfn)) \#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)Nach dem Login kopieren”
简单而清晰,PFN就是vmemmap这个struct page数组的index啊。对于ARM64而言,vmemmap定义如下:
“
\#define vmemmap ((struct page *)VMEMMAP_START - \ SECTION_ALIGN_DOWN(memstart_addr >> PAGE_SHIFT))Nach dem Login kopieren”
毫无疑问,我们需要在虚拟地址空间中分配一段地址来安放struct page数组(该数组包含了所有物理内存跨度空间page),也就是VMEMMAP_START的定义。
总之,Linux内存模型是一个非常重要的概念,可以帮助你更好地理解Linux系统中的内存管理。如果你想了解更多关于这个概念的信息,可以查看本文提供的参考资料。
Das obige ist der detaillierte Inhalt vonLinux-Speichermodell: Ein tieferes Verständnis der Speicherverwaltung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

































