


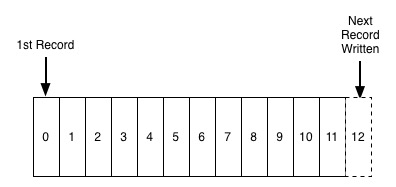
Ein Protokoll ist eine vollständig geordnete Folge von Datensätzen, die in chronologischer Reihenfolge angehängt sind. Es handelt sich tatsächlich um ein spezielles Dateiformat. Die Datei ist ein Byte-Array, und das Protokoll ist hier ein Datensatz, aber relativ zur Datei ist jedes Element hier Datensätze Man kann sagen, dass das Protokoll das einfachste Speichermodell ist. Das Lesen von Nachrichten erfolgt im Allgemeinen linear in die Protokolldatei .
Aufgrund der inhärenten Eigenschaften des Protokolls selbst werden die Datensätze der Reihe nach von links nach rechts eingefügt, was bedeutet, dass die Datensätze auf der linken Seite „älter“ sind als die Datensätze auf der rechten Seite. Mit anderen Worten, wir müssen uns nicht darauf verlassen Diese Funktion ist für verteilte Systeme sehr wichtig.
Es ist unmöglich zu wissen, wann das Protokoll erschienen ist. Möglicherweise ist es vom Konzept her zu einfach. Im Datenbankbereich werden Protokolle eher zum Synchronisieren von Daten und Indizes verwendet, z. B. das Redo-Protokoll in MySQL. Das Redo-Protokoll ist eine festplattenbasierte Datenstruktur, die verwendet wird, um die Richtigkeit und Vollständigkeit der Daten sicherzustellen System werden auch als Write-Ahead-Protokolle bezeichnet. Während der Ausführung einer Sache wird beispielsweise zuerst das Redo-Protokoll geschrieben, und dann werden die tatsächlichen Änderungen angewendet. Auf diese Weise kann das System wiederhergestellt werden wird basierend auf dem Redo-Log neu erstellt, um die Daten wiederherzustellen (während des Initialisierungsprozesses besteht zu diesem Zeitpunkt keine Client-Verbindung). Das Protokoll kann auch zur Synchronisierung zwischen dem Datenbank-Master und dem Slave verwendet werden, da im Wesentlichen alle Betriebsdatensätze der Datenbank in das Protokoll geschrieben wurden. Wir müssen nur das Protokoll mit dem Slave synchronisieren und es auf dem Slave wiedergeben, um den Master zu erreichen -Slave-Synchronisierung Hier können wir auch alle Änderungen in der Datenbank implementieren, indem wir das Redo-Protokoll abonnieren und so personalisierte Geschäftslogik implementieren, z. B. Auditing, Cache-Synchronisierung usw.
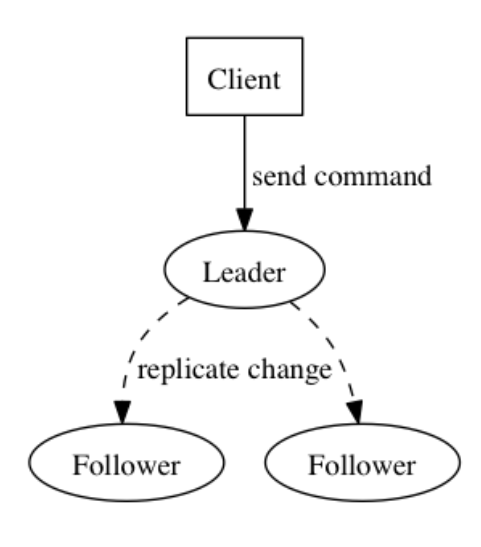
Bei verteilten Systemdiensten geht es im Wesentlichen um Zustandsänderungen, die als Zustandsmaschinen verstanden werden können (unabhängig von der externen Umgebung, wie z. B. Systemuhren, externen Schnittstellen usw.), die bei konsistenten Eingaben konsistente Ausgaben erzeugen und letztendlich aufrechterhalten ein konsistenter Zustand, und das Protokoll ist aufgrund seiner inhärenten Reihenfolge nicht auf die Systemuhr angewiesen, was zur Lösung des Problems der Änderungsreihenfolge verwendet werden kann.
Wir nutzen diese Funktion, um viele Probleme zu lösen, die in verteilten Systemen auftreten. Beispielsweise empfängt der Hauptbroker im Standby-Knoten in RocketMQ die Anfrage des Clients und synchronisiert sie dann in Echtzeit mit dem Slave. Wenn der Master auflegt, kann der Slave damit fortfahren Verarbeiten Sie die Anfrage, z. B. das Ablehnen der Schreibanfrage und das Fortfahren mit der Bearbeitung von Leseanfragen. Das Protokoll kann nicht nur Daten aufzeichnen, sondern auch Vorgänge wie SQL-Anweisungen direkt aufzeichnen.
Das Protokoll ist die Schlüsseldatenstruktur zur Lösung des Konsistenzproblems. Das Protokoll ist wie eine Abfolge von Operationen. Beispielsweise sind die weit verbreiteten Paxos- und Raft-Protokolle allesamt Konsistenzprotokolle, die auf dem Protokoll basieren.
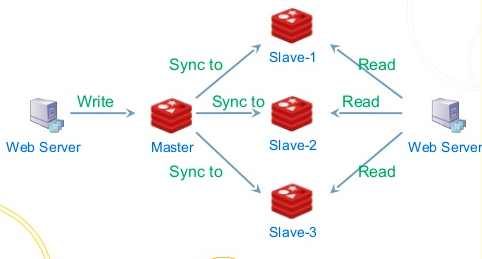
Protokolle können problemlos zur Verwaltung des Datenzuflusses und -abflusses verwendet werden. Die Datenquellen können hier aus verschiedenen Aspekten stammen, z. B. aus einem Ereignisstrom (Seitenklick, Cache-Aktualisierungserinnerung, Datenbank-Binlog-Änderungen). ) können wir Protokolle zentral in einem Cluster speichern, und Abonnenten können jeden Datensatz des Protokolls basierend auf dem Offset lesen und ihre eigenen Änderungen basierend auf den Daten und Vorgängen in jedem Datensatz anwenden.
Das Protokoll kann hier als Nachrichtenwarteschlange verstanden werden, und die Nachrichtenwarteschlange kann die Rolle der asynchronen Entkopplung und Strombegrenzung spielen. Warum sagen wir Entkopplung? Da die Verantwortlichkeiten der beiden Rollen für Verbraucher und Produzenten sehr klar sind, sind sie für die Erstellung von Nachrichten und den Konsum von Nachrichten verantwortlich, ohne sich darum zu kümmern, wer nachgelagert oder vorgelagert ist, ob es sich um das Änderungsprotokoll der Datenbank oder um ein bestimmtes Ereignis handelt Ich muss mich überhaupt nicht um eine bestimmte Partei kümmern, ich muss nur auf die Protokolle achten, die mich interessieren, und auf jeden Eintrag in den Protokollen.
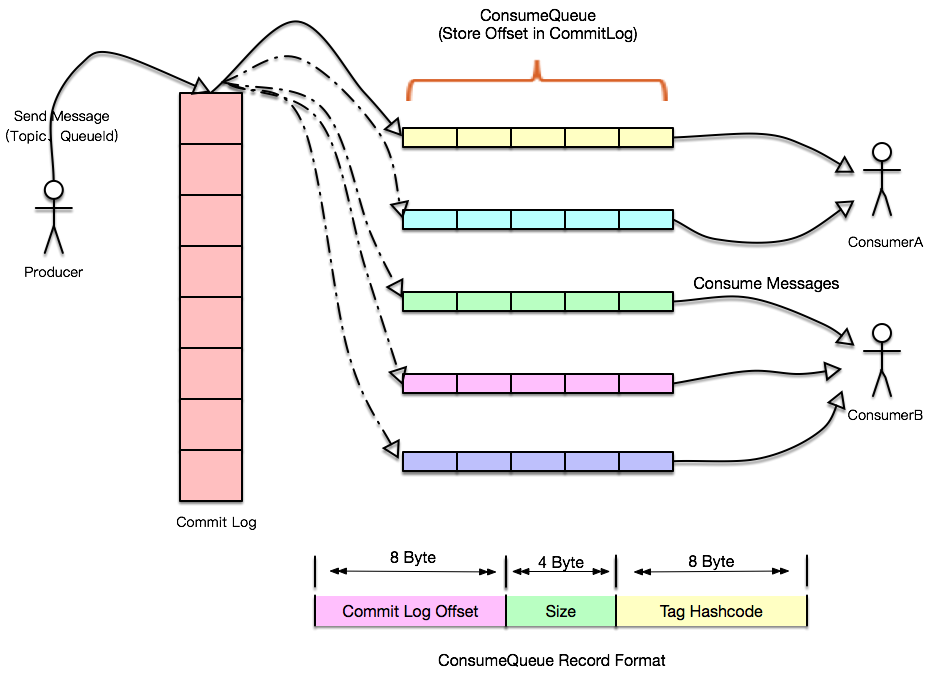
Wir wissen, dass die QPS der Datenbank sicher ist und Anwendungen der oberen Ebene im Allgemeinen horizontal erweitert werden können. Wenn zu diesem Zeitpunkt ein plötzliches Anforderungsszenario wie Double 11 auftritt und die Datenbank überlastet ist, können wir Nachrichtenwarteschlangen einführen um die Vorgänge der Datenbank jedes Teams zu kombinieren. Schreiben Sie in das Protokoll, und eine andere Anwendung ist dafür verantwortlich, diese Protokolldatensätze zu verbrauchen und auf die Datenbank anzuwenden. Selbst wenn die Datenbank hängt, kann die Verarbeitung bei der Wiederherstellung an der Position der letzten Nachricht fortgesetzt werden RocketMQ und Kafka unterstützen die Exactly Once-Semantik. Auch wenn die Geschwindigkeit des Produzenten von der Geschwindigkeit des Verbrauchers abweicht, hat das Protokoll hier keine Auswirkungen. Es kann alle Datensätze im Protokoll speichern und synchronisieren Regelmäßig an den Slave-Knoten gesendet, sodass die Rückstandskapazität erheblich verbessert werden kann, da das Schreiben von Protokollen vom Master-Knoten verarbeitet wird. Eine davon ist Tail-Read, was bedeutet, dass die Verbrauchsgeschwindigkeit mithalten kann Mit der Schreibgeschwindigkeit können Sie direkt zum Cache gehen, und der andere ist der Verbraucher, der hinter der Schreibanforderung zurückbleibt. Diese Art kann über die E/A-Isolation und einige Dateirichtlinien gelesen werden Mit dem Betriebssystem wie Pagecache, Cache-Read-Ahead usw. kann die Leistung erheblich verbessert werden.
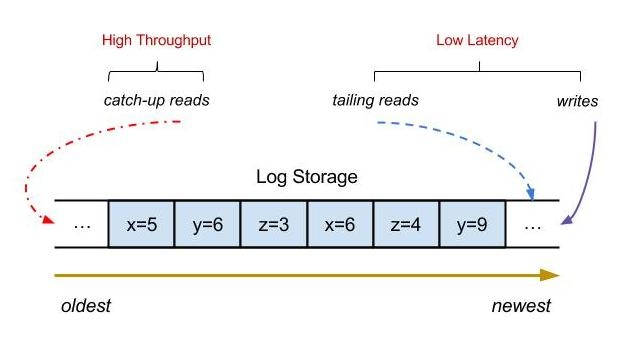
Horizontale Skalierbarkeit ist ein sehr wichtiges Merkmal in einem verteilten System. Probleme, die durch das Hinzufügen von Maschinen gelöst werden können, sind kein Problem. Wie implementiert man also eine Nachrichtenwarteschlange, die eine horizontale Erweiterung erreichen kann? Wenn wir eine eigenständige Nachrichtenwarteschlange haben, werden E/A, CPU, Bandbreite usw. mit zunehmender Anzahl von Themen allmählich zu Engpässen und die Leistung nimmt langsam ab. Wie geht es hier weiter? Wie sieht es mit der Leistungsoptimierung aus?
Das obige ist der detaillierte Inhalt vonDer Kern verteilter Systeme sind Protokolle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



