super_blocks
| super_block |
|
Dateisysteme
| file_systems_type |
|
dentry_unused
| Zahnmedizin |
|
vfsmntlist
| vfsmount |
|
inode_in_use
| inode |
|
inode_unused
| inode |
|
Super_block-, file_system_type-, dentry- und vfsmoubt-Strukturen werden alle in ihren eigenen verknüpften Listen gespeichert. Die Indexknoten können sich auf den globalen inode_in_use oder inode_unused oder auf ihren entsprechenden superschnellen lokalen verknüpften Listen befinden.
Zusätzlich zur Haupt-VFS-Struktur gibt es mehrere andere Strukturen, die mit VFS, fs_struct und files_struct, namespace, fd_set interagieren. Die folgende Abbildung erläutert, wie Prozessdeskriptoren mit dateibezogenen Strukturen verknüpft sind.
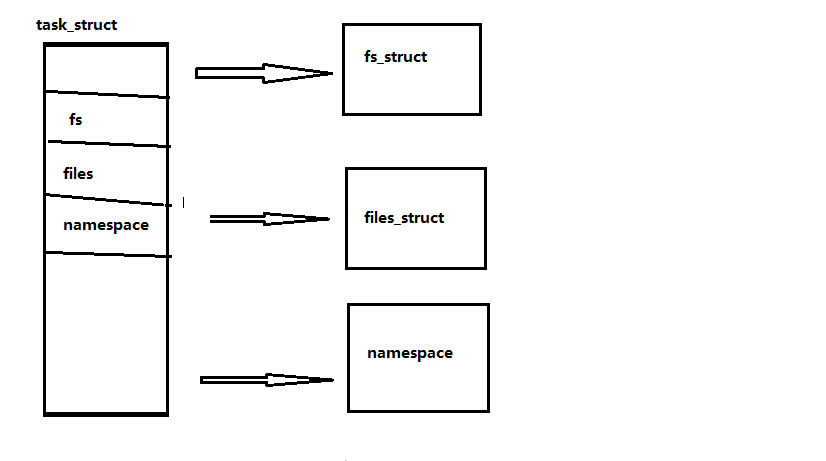
Lassen Sie uns zunächst die fs_struct-Struktur vorstellen. Der folgende Code kann in include/Linux/fs_struct.h gefunden werden Rat
struct fs_struct{
atomic_t count; //保存引用特定fs_struct的进程描述符数目
rwlock_t lock;
int umask; //保存一个掩码,表示将要在打开文件上设置的许可权
struct dentry * root, *pwd ,*altroot; //都是指针,,,,
struct vfsmount * rootmnt, *pwdmnt, *altrootmnt; //指针,
};
Nach dem Login kopieren
files_struct enthält Informationen über geöffnete Dateien und ihre Deskriptoren und verwendet diese Sammlungen, um ihre Deskriptoren zu gruppieren. Der folgende Code kann in include/linux/file.h
angezeigt werden
struct files_struct{
atomic_t count; //与fs_struct类似
spinlock_t file_lock;
int max_fds; //表示进程能够打开的文件的最大数
int max_fdset; //表示描述符的最大数
int next_fd; //保存下一个将要分配的文件描述符的值
struct file ** fd; //fd数组指向打开的文件对象的数组
fd_set *close_on_exec; //是指向文件描述符集的一个指针,这些文件描述符在exec()时候就被标志位将要关闭,如果在exec()时候被标志位“打开”的文件描述符数超过close_on_exec_init域的大小,则改变close_on_exec域的值;
fd_set *open_fds; //是一个指针,指向被标记为“打开”的文件描述符集合,
fd_set close_on_exec_init; //保存一个位域,表示打开文件对应的文件描述符
fd_set open_fds_init; //这些都是fd_set类型的域,其实都不懂,,,
struct file *fd_array[NR_OPEN_DEFAULT];//fd_array数组指针指向前32个打开的文件描述法
};
Nach dem Login kopieren
Initialisieren Sie die fs_struct-Struktur mit dem INIT_FILES-Makro:
#define INIT_FILES \
{
.count = ATOMIC_INIT(1),
.file_lock = SPIN_LOCK_UNLOCKED,
.max_fds = NR_OPEN_DEFAULT,
.max_fdset = __FD_SETSIZE,
.next_fd = 0,
.fd = &init_files.fd_array[0];
.close_on_exec = &init_files.close_on_exec_init,
.open_fds = &init_files.open_fds_init,
.close_on_exec_init = {{0, }},
.open_fda_init = {{0, }},
.fd_array = {NULL, }
}
Nach dem Login kopieren
Die globale Definition von NR_OPEN_DEFAULT ist auf BITS_PER_LONG eingestellt, was 32 in 32-Bit-Systemen und 64 in 64-Bit-Systemen ist
Lassen Sie uns nun die Seitenpufferung vorstellen. Sehen wir uns nun an, wie sie funktioniert und implementiert wird. Unter Linux ist der Speicher in eine verknüpfte Liste aktiver Seiten und eine inaktive verknüpfte Liste unterteilt. Wenn die Seite inaktiv ist, wird sie auf die Festplatte zurückgeschrieben
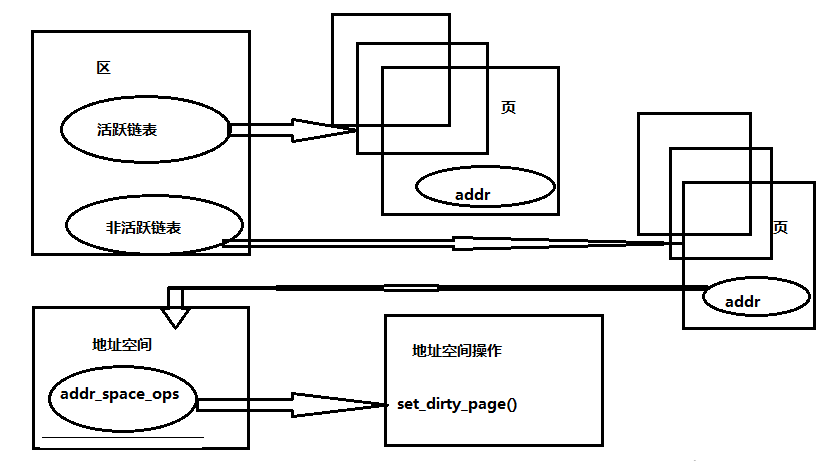 image-20240202221039708
image-20240202221039708
Der Kern der Seitenpufferung ist das Objekt „address_space“, dessen Code in include/linux/fs.h eingesehen werden kann (ich verstehe diesen Code nicht sehr gut, bitte geben Sie mir einen Rat):
struct address_space{
struct inode *host;
struct radix_tree_root page_tree;
spinlock_t tree_lock;
unsigned long nrpages;
pgoff_t writeback;
struct address_space_operations *a_ops;
struct prio_tree_root i_map;
unsigned inr i_map_lock;
struct list_head i_mmap_nonlinear;
spinlock_t i_mmap_lock;
atomic_t truncate_count;
unsigned long flags;
struct backing_dev_info *backing_dev_info;
spinlock_t private_lock;
struct list_head private_list;
struct address_space *assoc_mapping;
};
Nach dem Login kopieren
 Lassen Sie uns abschließend über den VFS-Systemaufruf und die Dateisystemebene sprechen und deren Ausführung bis zur Kernelebene verfolgen. Zunächst müssen wir vier Funktionen verstehen: open(), close(), read() und write().
Lassen Sie uns abschließend über den VFS-Systemaufruf und die Dateisystemebene sprechen und deren Ausführung bis zur Kernelebene verfolgen. Zunächst müssen wir vier Funktionen verstehen: open(), close(), read() und write().
open()-Funktion:
open-Funktion wird zum Öffnen und Erstellen von Dateien verwendet. Im Folgenden finden Sie eine kurze Beschreibung der Öffnungsfunktion
#include
int open(const char *pathname, int oflag, ... );
Nach dem Login kopieren
Rückgabewert: Bei Erfolg den Dateideskriptor zurückgeben, andernfalls -1 zurückgeben
Für die Öffnungsfunktion wird der dritte Parameter (...) nur beim Erstellen einer neuen Datei verwendet und dient zur Angabe der Zugriffsberechtigungsbits der Datei. Pfadname ist der Pfadname der zu öffnenden/erstellenden Datei (z. B. C:/cpp/a.cpp); oflag wird verwendet, um den Öffnungs-/Erstellungsmodus der Datei anzugeben (definiert). in fcntl.h) durch logisches ODER.
close()函数
进程使用完文件后,发出close()系统调用:
sysopsis
#include
int close(int fd);
Nach dem Login kopieren
参数:fd文件描述符
函数返回值:0成功,-1出错
参数fd是要关闭的文件描述符。需要说明的是:当一个进程终止时,内核对该进程所有尚未关闭的文件描述符调用close关闭,所以即使用户程序不调用close,在终止时内核也会自动关闭它打开的所有文件。但是对于一个长年累月运行的程序(比如网络服务器),打开的文件描述符一定要记得关闭,否则随着打开的文件越来越多,会占用大量文件描述符和系统资源。
read()函数
当用户级别程序调用read()函数时,Linux把它转换成系统调sys_read():
功能描述:从文件读取数据。
所需头文件: #include
函数原型:ssize_t read(int fd, void *buf, size_t count);
参数:
-
fd: 将要读取数据的文件描述词。
-
buf:指缓冲区,即读取的数据会被放到这个缓冲区中去。
-
count:表示调用一次read操作,应该读多少数量的字符。
-
返回值:返回所读取的字节数;0(读到EOF);-1(出错)。
-
以下几种情况会导致读取到的字节数小于 count :
-
读取普通文件时,读到文件末尾还不够 count 字节。例:如果文件只有 30 字节,而我们想读取 100,字节,那么实际读到的只有 30 字节, 函数返回 30 。此时再使用 read 函数作用于这个文件会导致 read 返回 0
-
从终端设备(terminal device)读取时,一般情况下每次只能读取一行。
-
从网络读取时,网络缓存可能导致读取的字节数小于 count字节。
-
读取 pipe 或者 FIFO 时,pipe 或 FIFO 里的字节数可能小于 count 。
-
从面向记录(record-oriented)的设备读取时,某些面向记录的设备(如磁带)每次最多只能返回一个记录。
-
在读取了部分数据时被信号中断,读操作始于 cfo 。在成功返回之前,cfo 增加,增量为实际读取到的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下)::
#include
#include
#include
#include
#include
#include
int main(void)
{
void* buf ;
int handle;
int bytes ;
buf=malloc(10);
/*
LooksforafileinthecurrentdirectorynamedTEST.$$$andattempts
toread10bytesfromit.Tousethisexampleyoushouldcreatethe
fileTEST.$$$
*/
handle=open("TEST.$$$",O_RDONLY|O_BINARY,S_IWRITE|S_IREAD);
if(handle==-1)
{
printf("ErrorOpeningFile\n");
exit(1);
}
bytes=read(handle,buf,10);
if(bytes==-1)
{
printf("ReadFailed.\n");
exit(1);
}
else
{
printf("Read:%dbytesread.\n",bytes);
}
return0 ;
}
Nach dem Login kopieren
write()函数
功能描述:向文件写入数据。
所需头文件: #include
函数原型:ssize_t write(int fd, void *buf, size_t count);
返回值:写入文件的字节数(成功);-1(出错)
功能:write 函数向 filedes 中写入 count 字节数据,数据来源为 buf 。返回值一般总是等于 count,否则就是出错了。常见的出错原因是磁盘空间满了或者超过了文件大小限制。对于普通文件,写操作始于 cfo 。如果打开文件时使用了 O_APPEND,则每次写操作都将数据写入文件末尾。成功写入后,cfo 增加,增量为实际写入的字节数。
例程如下(程序是网上找的例子,贴下来以以供大家理解一下):
#include
#include
#include
#include
#include
#include
int main(void)
{
int *handle; char string[40];
int length, res;/* Create a file named "TEST.$$$" in the current directory and write a string to it. If "TEST.$$$" already exists, it will be overwritten. */
if ((handle = open("TEST.$$$", O_WRONLY | O_CREAT | O_TRUNC, S_IREAD | S_IWRITE)) == -1)
{
printf("Error opening file.\n");
exit(1);
}
strcpy(string, "Hello, world!\n");
length = strlen(string);
if ((res = write(handle, string, length)) != length)
{
printf("Error writing to the file.\n");
exit(1);
}
printf("Wrote %d bytes to the file.\n", res);
close(handle); return 0; }
Nach dem Login kopieren
小结
今天看的代码不多,差不多都是网上找的代码,有些解释也是查阅资料写上去的,有些还是不懂,希望各路大神指教,这里我总结了有关Linux文件系统实现的问题,但是具体的细节方面并没有提及到,大家看了之后应该只能有一个大致的最Linux文件系统的了解,有读者问我看的是哪些书,这里我说明一下,看了Linux内核编程,还有深入理解Linux内核以及网上各种资料或者其他大牛写的好的博客。这里我是总结了一下,并且把自己不懂的还有觉得重要的说了一下,希望各位大神给些建议,thanks~



















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



