


Mit der Weiterentwicklung multimodaler Großmodelle (LMMs) wächst auch die Notwendigkeit, die Leistung von LMMs zu bewerten. Insbesondere im chinesischen Umfeld wird es immer wichtiger, das fortgeschrittene Wissen und die Denkfähigkeit von LMM zu bewerten.
Um in diesem Zusammenhang die multimodalen Verständnisfähigkeiten des Basismodells auf Expertenebene bei verschiedenen Aufgaben auf Chinesisch zu bewerten, haben die M-A-P Open Source Community, die Hong Kong University of Science and Technology, die University of Waterloo und Zero One Wanxing hat gemeinsam den CMMMU-Benchmark (Chinese Massive Multi-Discipline Multimodal Understanding and Reasoning) eingeführt. Dieser Benchmark zielt darauf ab, eine umfassende Bewertungsplattform für umfassendes multidisziplinäres multimodales Verständnis und Denken auf Chinesisch bereitzustellen. Der Benchmark ermöglicht es Forschern, Modelle für eine Vielzahl von Aufgaben zu testen und ihre multimodalen Verständnisfähigkeiten mit professionellem Niveau zu vergleichen. Das Ziel dieses gemeinsamen Projekts besteht darin, die Entwicklung des Bereichs des multimodalen Verständnisses und Denkens in China voranzutreiben und eine standardisierte Referenz für die entsprechende Forschung bereitzustellen.
CMMMU deckt sechs Hauptkategorien von Fächern ab, darunter Kunst, Wirtschaft, Gesundheit und Medizin, Naturwissenschaften, Geistes- und Sozialwissenschaften, Technologie und Ingenieurwesen, mit mehr als 30 Unterteilungen. Die folgende Abbildung zeigt ein Beispiel einer Frage für jedes Unterfeldthema. CMMMU ist einer der ersten multimodalen Benchmarks im chinesischen Kontext und einer der wenigen multimodalen Benchmarks, der die komplexen Verständnis- und Argumentationsfähigkeiten von LMM untersucht.

Datenerfassung
Die Datenerfassung ist in drei Phasen unterteilt. Zunächst sammelten die Forscher Fragequellen für jedes Thema, das den Urheberrechtslizenzanforderungen entsprach, einschließlich Webseiten oder Büchern. Während dieses Prozesses haben sie hart daran gearbeitet, Duplikate von Fragenquellen zu vermeiden, um Datenvielfalt und -genauigkeit sicherzustellen. Zweitens leiteten die Forscher die Fragenquellen zur weiteren Kommentierung an Crowdsourcing-Annotatoren weiter. Alle Kommentatoren sind Personen mit einem Bachelor-Abschluss oder höher, um sicherzustellen, dass sie die kommentierten Fragen und zugehörigen Erklärungen überprüfen können. Während des Annotationsprozesses verlangen Forscher von den Annotatoren, dass sie sich strikt an die Annotationsprinzipien halten. Filtern Sie beispielsweise Fragen heraus, für deren Beantwortung keine Bilder erforderlich sind, Fragen, die nach Möglichkeit dasselbe Bild verwenden, und Fragen, für deren Beantwortung kein Expertenwissen erforderlich ist. Um schließlich die Anzahl der Fragen in jedem Fach im Datensatz auszugleichen, ergänzten die Forscher die Fächer gezielt durch weniger Fragen. Dadurch wird die Vollständigkeit und Repräsentativität des Datensatzes sichergestellt, sodass nachfolgende Analysen und Untersuchungen genauer und umfassender sind.
Datensatzbereinigung
Um die Datenqualität von CMMMU weiter zu verbessern, befolgen Forscher strenge Protokolle zur Datenqualitätskontrolle. Zunächst wird jede Frage von mindestens einem der Autoren der Arbeit persönlich überprüft. Zweitens haben sie zur Vermeidung von Datenverschmutzungsproblemen auch Fragen herausgefiltert, die mehrere LLMs ohne Rückgriff auf OCR-Technologie beantworten könnten. Diese Maßnahmen gewährleisten die Zuverlässigkeit und Genauigkeit der CMMMU-Daten.
Datensatzübersicht
CMMMU verfügt über insgesamt 12.000 Fragen, die in Entwicklungssätze mit wenigen Stichproben, Verifizierungssätze und Testsätze unterteilt sind. Der Entwicklungssatz mit wenigen Stichproben enthält etwa 5 Fragen für jedes Thema, der Validierungssatz enthält 900 Fragen und der Testsatz enthält 11.000 Fragen. Die Fragen umfassen 39 Arten von Bildern, darunter pathologische Diagramme, Notendiagramme, Schaltpläne, chemische Strukturdiagramme usw. Die Fragen sind in drei Schwierigkeitsstufen unterteilt: leicht (30 %), mittel (58 %) und schwer (12 %), basierend auf der logischen Schwierigkeit und nicht auf der intellektuellen Schwierigkeit. Weitere Fragenstatistiken finden Sie in Tabelle 2 und Tabelle 3. Das Team testete die Leistung verschiedener gängiger zweisprachiger LMMs auf Chinesisch und Englisch sowie mehrerer LLMs auf CMMMU. Es sind sowohl Closed-Source- als auch Open-Source-Modelle enthalten. Der Bewertungsprozess verwendet Zero-Shot-Einstellungen anstelle von Feinabstimmungs- oder Wenig-Shot-Einstellungen, um die Rohfunktionen des Modells zu überprüfen. LLM fügte außerdem Experimente hinzu, bei denen Bild-OCR-Ergebnisse + Text als Eingabe verwendet werden. Alle Experimente wurden auf einem NVIDIA A100-Grafikprozessor durchgeführt.
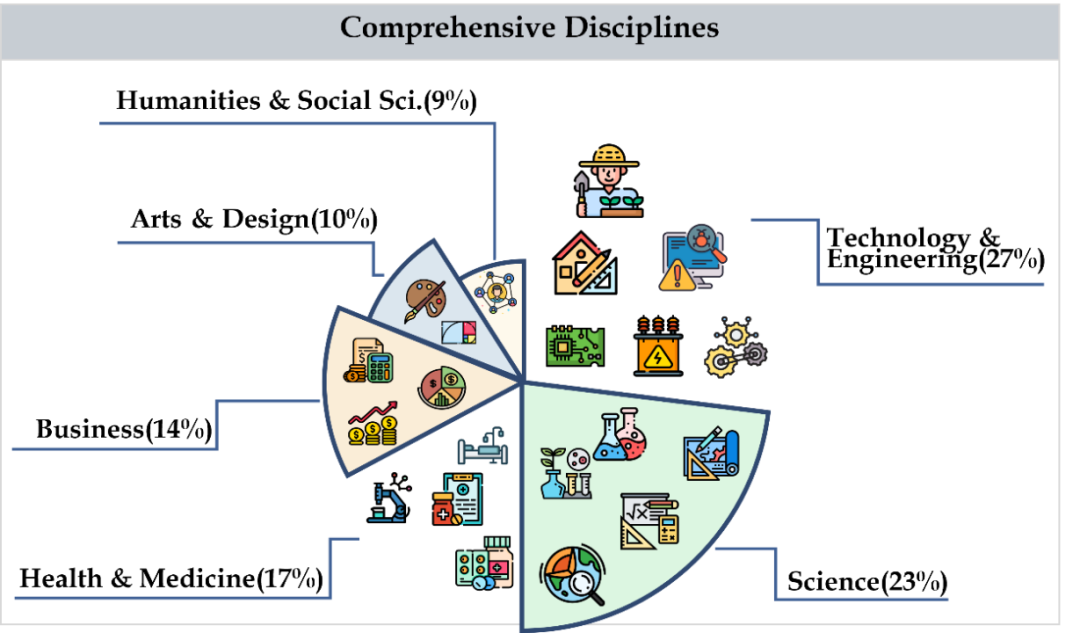
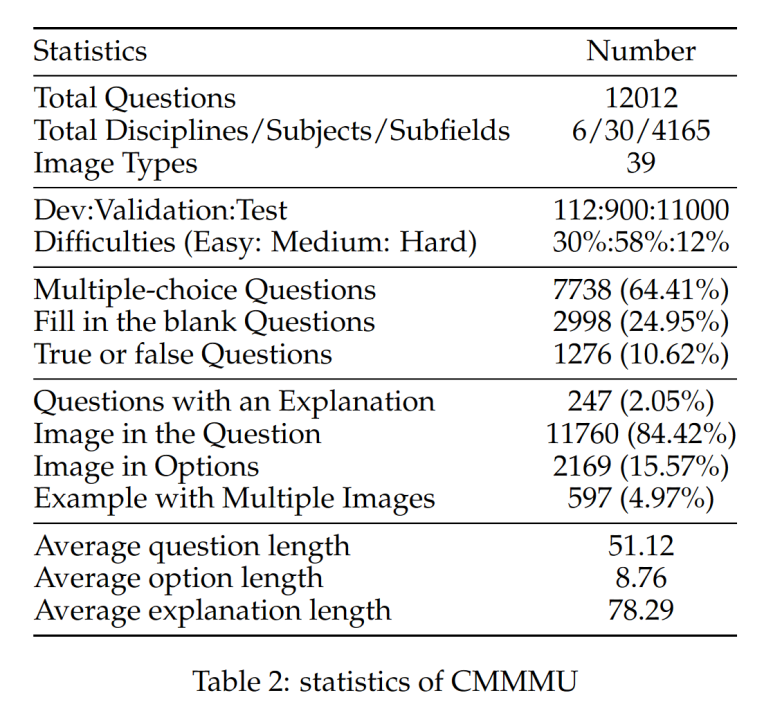
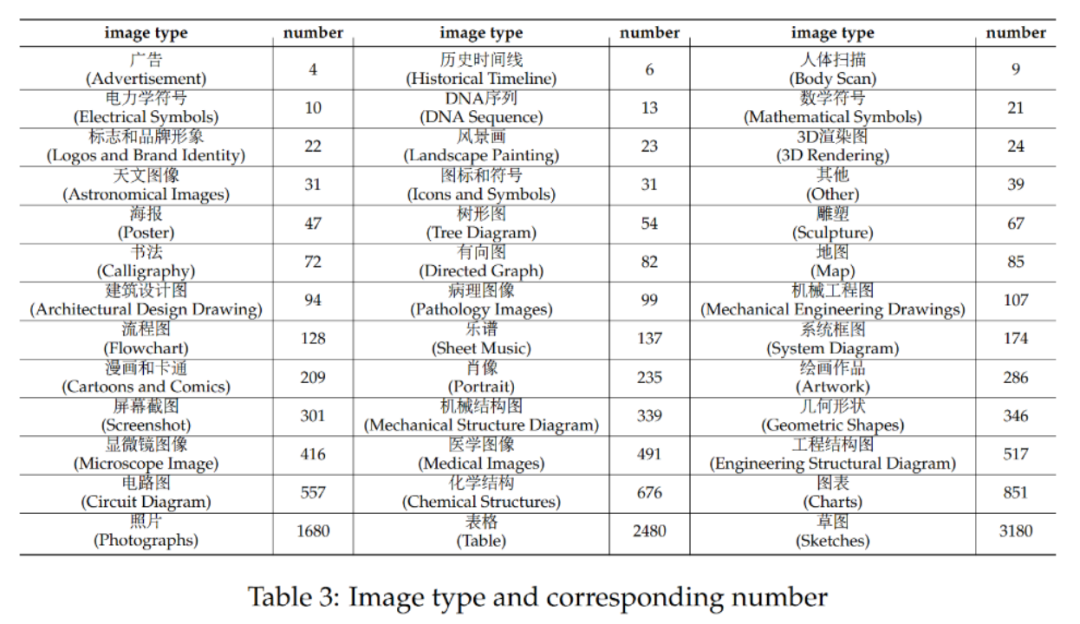 Tabelle 4 zeigt die Versuchsergebnisse:
Tabelle 4 zeigt die Versuchsergebnisse:
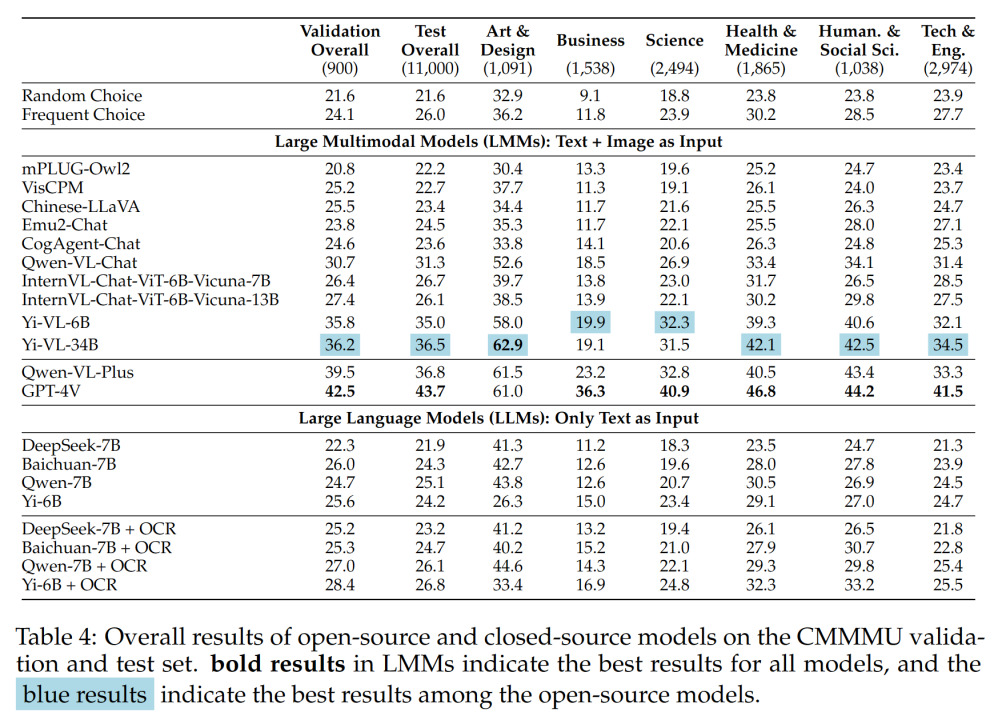
Einige wichtige Erkenntnisse sind:
– CMMMU ist anspruchsvoller als MMMU, und dies setzt voraus, dass MMMU bereits sehr herausfordernd ist.
Die Genauigkeit von GPT-4V im chinesischen Kontext beträgt nur 41,7 %, während die Genauigkeit im englischen Kontext 55,7 % beträgt. Dies zeigt, dass bestehende sprachübergreifende Generalisierungsmethoden selbst für hochmoderne Closed-Source-LMMs nicht gut genug sind.
- Im Vergleich zu MMMU ist die Lücke zwischen inländischen repräsentativen Open-Source-Modellen und GPT-4V relativ gering.
Der Unterschied zwischen Qwen-VL-Chat und GPT-4V auf MMMU beträgt 13,3 %, während der Unterschied zwischen BLIP2-FLAN-T5-XXL und GPT-4V auf MMMU 21,9 % beträgt. Überraschenderweise verringert Yi-VL-34B sogar die Lücke zwischen dem zweisprachigen Open-Source-LMM und GPT-4V auf CMMMU auf 7,5 %, was bedeutet, dass im chinesischen Umfeld das zweisprachige Open-Source-LMM GPT-4V entspricht ein vielversprechender Fortschritt in der Open-Source-Community.
- In der Open-Source-Community hat das Streben nach multimodaler künstlicher allgemeiner Intelligenz (AGI) durch chinesische Experten gerade erst begonnen. Das
-Team wies darauf hin, dass mit Ausnahme des kürzlich veröffentlichten Qwen-VL-Chat, Yi-VL-6B und Yi-VL-34B alle zweisprachigen LMMs aus der Open-Source-Community nur eine Genauigkeit erreichen können, die mit der von CMMMU vergleichbar ist Auswahl.
Analyse verschiedener Frageschwierigkeiten und Fragetypen
- Verschiedene Fragetypen
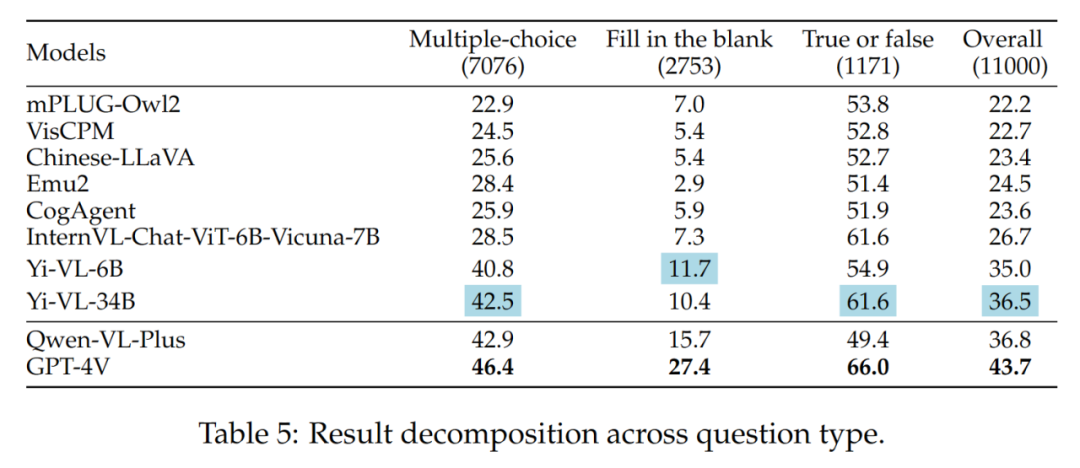
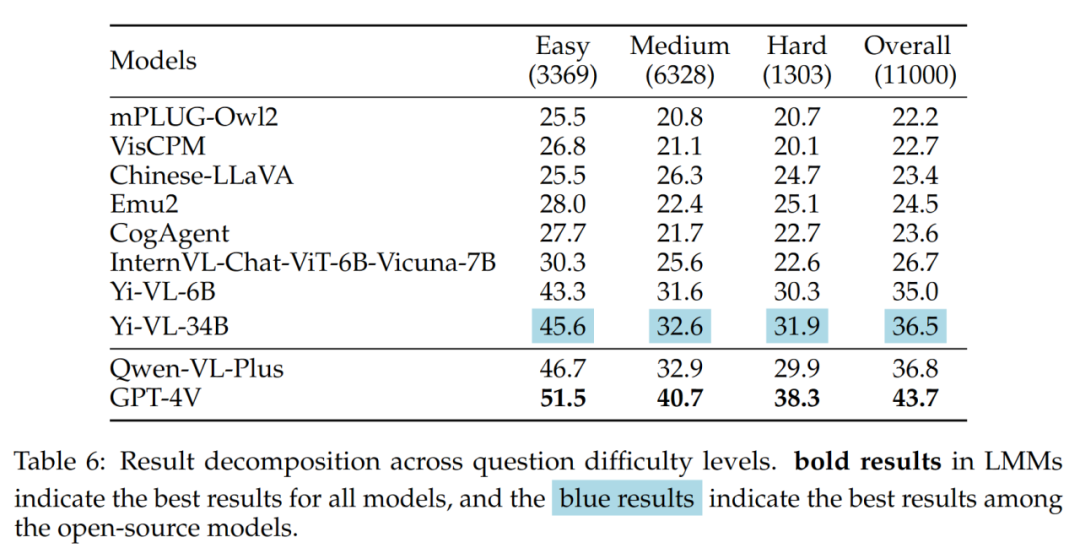
Die Unterschiede zwischen der Yi-VL-Serie, Qwen-VL-Plus und GPT-4V sind hauptsächlich auf Sie zurückzuführen unterscheiden sich in ihrer Fähigkeit, Multiple-Choice-Fragen zu beantworten. Die Ergebnisse der verschiedenen Fragetypen sind in Tabelle 5 dargestellt: VL-34B) und GPT-4V haben bei mittleren und schwierigen Problemen einen großen Abstand. Dies ist ein weiterer starker Beweis dafür, dass der Hauptunterschied zwischen Open-Source-LMMs und GPT-4V in der Fähigkeit liegt, unter komplexen Bedingungen zu rechnen und zu argumentieren.
Die Ergebnisse verschiedener Frageschwierigkeiten sind in Tabelle 6 dargestellt:
Fehleranalyse
Die Forscher analysierten sorgfältig die falschen Antworten von GPT-4V. Wie in der folgenden Abbildung dargestellt, sind die Hauptfehlertypen Wahrnehmungsfehler, mangelndes Wissen, Argumentationsfehler, Antwortverweigerung und Anmerkungsfehler. Die Analyse dieser Fehlertypen ist der Schlüssel zum Verständnis der Fähigkeiten und Einschränkungen aktueller LMMs und kann auch als Leitfaden für zukünftige Verbesserungen von Design- und Trainingsmodellen dienen.
 - Wahrnehmungsfehler (26 %):
- Wahrnehmungsfehler (26 %):
Wahrnehmungsfehler sind einer der Hauptgründe, warum GPT-4V falsche Beispiele erzeugt. Wenn das Modell einerseits das Bild nicht verstehen kann, führt dies zu einer Verzerrung der zugrunde liegenden Wahrnehmung des Bildes, was zu falschen Antworten führt. Wenn ein Modell andererseits auf Unklarheiten im domänenspezifischen Wissen, implizite Bedeutungen oder unklare Formeln stößt, weist es häufig domänenspezifische Wahrnehmungsfehler auf. In diesem Fall verlässt sich GPT-4V tendenziell mehr auf auf Textinformationen basierende Antworten (d. h. Fragen und Optionen) und räumt Textinformationen Vorrang vor visuellen Eingaben ein, was zu einer Verzerrung beim Verständnis multimodaler Daten führt.
- Inferenzfehler (26%):
Inferenzfehler sind ein weiterer wichtiger Faktor dafür, dass GPT-4V fehlerhafte Beispiele erzeugt. Selbst wenn Modelle die durch Bilder und Texte vermittelte Bedeutung richtig wahrnehmen, können beim Lösen von Problemen, die komplexe logische und mathematische Überlegungen erfordern, Fehler beim Denken auftreten. Typischerweise wird dieser Fehler durch die schwachen logischen und mathematischen Denkfähigkeiten des Modells verursacht.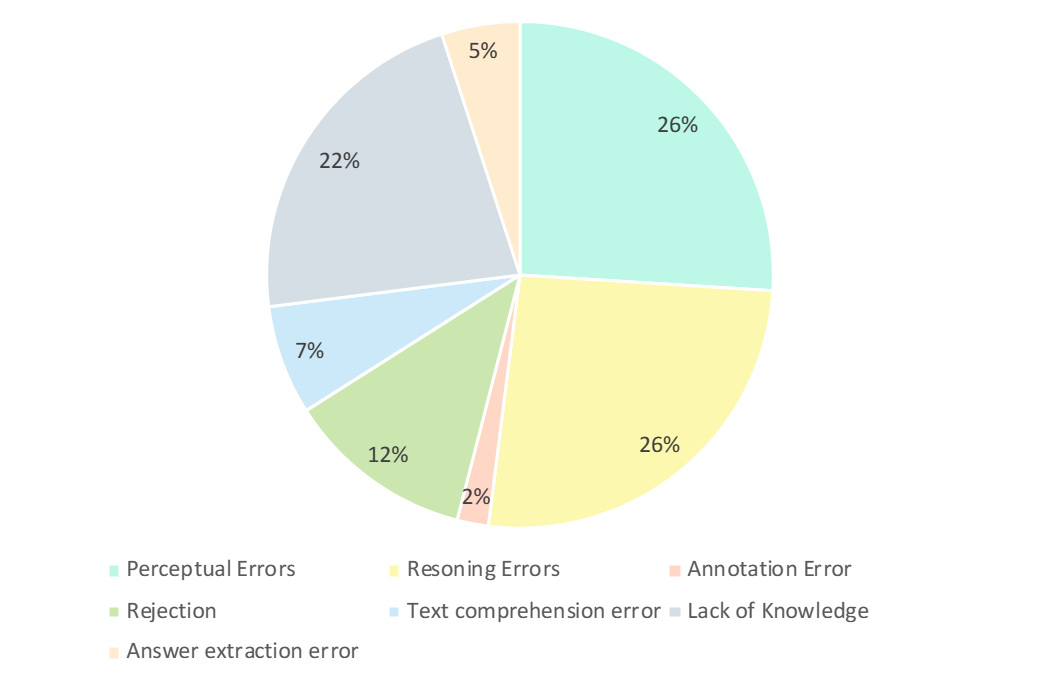
- Mangelndes Wissen (22%): Mangelndes Fachwissen ist auch einer der Gründe für falsche Antworten auf GPT-4V. Da CMMMU ein Maßstab für die Bewertung von LMM-Experten-AGI ist, sind Kenntnisse auf Expertenebene in verschiedenen Disziplinen und Teilbereichen erforderlich. Daher ist die Einbringung von Expertenwissen in LMM auch eine der Richtungen, an denen gearbeitet werden kann.
- Antwort verweigern (12 %): Es kommt auch häufig vor, dass Models die Antwort verweigern. Durch die Analyse wiesen sie auf mehrere Gründe hin, warum das Modell sich weigerte, die Frage zu beantworten: (1) Das Modell konnte die Informationen aus dem Bild nicht wahrnehmen. (2) Es handelte sich um eine Frage, die religiöse Themen oder persönliche Informationen aus dem wirklichen Leben betraf, und das Modell würde dies aktiv vermeiden; (3) Wenn Fragen das Geschlecht und subjektive Faktoren betreffen, vermeidet das Modell die Bereitstellung direkter Antworten.
- Seine Fehler: Zu den verbleibenden Fehlern gehören Textverständnisfehler (7 %), Anmerkungsfehler (2 %) und Antwortextraktionsfehler (5 %). Diese Fehler werden durch eine Vielzahl von Faktoren verursacht, wie z. B. komplexe Strukturverfolgungsfunktionen, komplexes Verständnis der Textlogik, Einschränkungen bei der Antwortgenerierung, Fehler bei der Datenanmerkung und Probleme bei der Extraktion der Antwortübereinstimmung.
Der CMMMU-Benchmark markiert einen bedeutenden Fortschritt in der Entwicklung der Advanced General Artificial Intelligence (AGI). CMMMU wurde entwickelt, um die neuesten großen multimodalen Modelle (LMMs) gründlich zu bewerten und grundlegende Wahrnehmungsfähigkeiten, komplexes logisches Denken und fundierte Fachkenntnisse in einem bestimmten Bereich zu testen. Diese Studie wies auf die Unterschiede hin, indem sie die Denkfähigkeit von LMM in zweisprachigen Kontexten auf Chinesisch und Englisch verglich. Diese detaillierte Bewertung ist entscheidend, um festzustellen, wie gut das Modell im Vergleich zu den Kompetenzen erfahrener Fachleute in den einzelnen Bereichen abschneidet.
Das obige ist der detaillierte Inhalt vonDas neueste Benchmark-CMMMU, das für den chinesischen LMM-Körper geeignet ist: Enthält mehr als 30 Unterteilungen und 12.000 Fragen auf Expertenebene. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Darstellungsmethode der String-Konstante
Darstellungsmethode der String-Konstante
 Einführung in die Bedeutung ungültiger Syntax
Einführung in die Bedeutung ungültiger Syntax
 Eigenschaften relationaler Datenbanken
Eigenschaften relationaler Datenbanken
 Gängige Tools zum Softwaretesten
Gängige Tools zum Softwaretesten
 Drei gängige Frameworks für das Web-Frontend
Drei gängige Frameworks für das Web-Frontend
 Was tun, wenn der Fehler „normal.dotm' auftritt?
Was tun, wenn der Fehler „normal.dotm' auftritt?
 Was bedeutet DOS-Betriebssystem?
Was bedeutet DOS-Betriebssystem?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



