


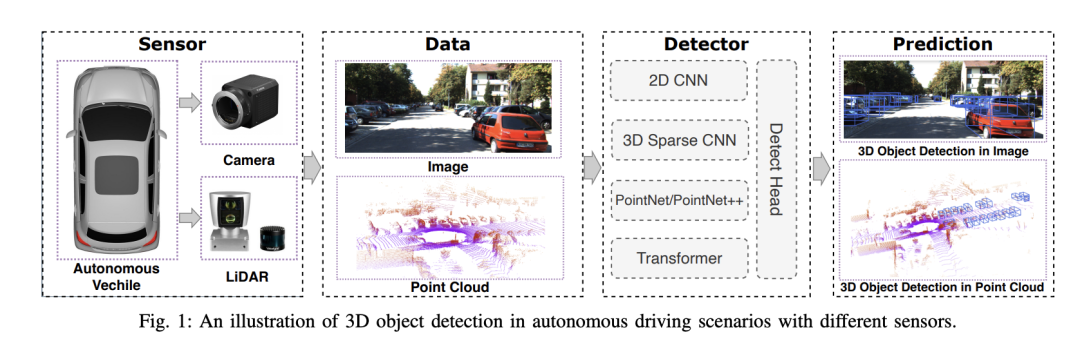
Autonomes Fahrsystem basiert auf fortschrittlicher Wahrnehmungs-, Entscheidungs- und Steuerungstechnologie, um die Umgebung durch den Einsatz verschiedener Sensoren (wie Kameras, Lidar, Radar usw.) wahrzunehmen .) und nutzen Algorithmen und Modelle für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert 3D-Objekterkennungsalgorithmen in autonomen Fahrsystemen, die Objekte in der Umgebung genau wahrnehmen und beschreiben können, einschließlich ihrer Position, Form, Größe und Kategorie. Dieses umfassende Umweltbewusstsein hilft autonomen Fahrsystemen, die Fahrumgebung besser zu verstehen und präzisere Entscheidungen zu treffen.
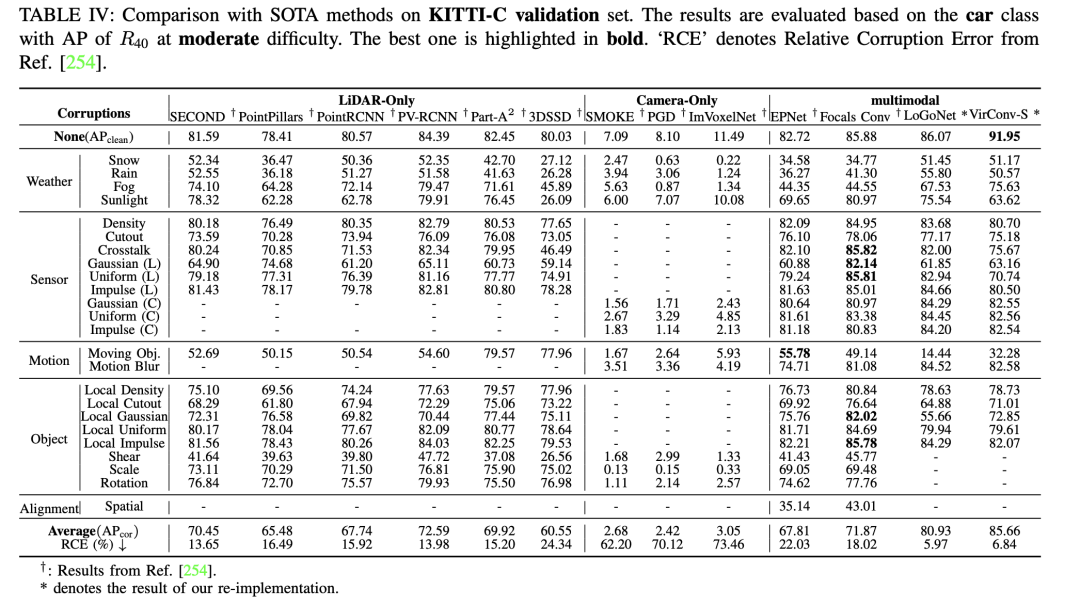
Wir haben eine umfassende Bewertung von 3D-Objekterkennungsalgorithmen beim autonomen Fahren durchgeführt, wobei wir vor allem die Robustheit berücksichtigten. Bei der Bewertung wurden drei Schlüsselfaktoren identifiziert: Umgebungsvariabilität, Sensorrauschen und Fehlausrichtung. Diese Faktoren sind wichtig für die Leistung von Erkennungsalgorithmen unter realen, variablen Bedingungen.
Befasst sich außerdem mit drei Schlüsselbereichen der Leistungsbewertung: Genauigkeit, Latenz und Robustheit.
Das Papier weist auf die erheblichen Vorteile multimodaler 3D-Erkennungsmethoden bei der Sicherheitswahrnehmung hin. Durch die Zusammenführung von Daten verschiedener Sensoren werden umfassendere und vielfältigere Wahrnehmungsfähigkeiten bereitgestellt, wodurch die Sicherheit autonomer Fahrsysteme verbessert wird.
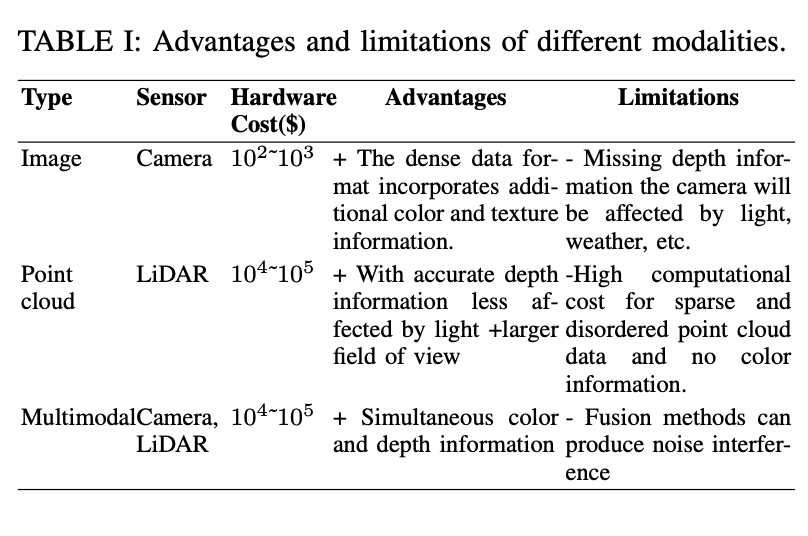
Oben wird der in autonomen Fahrsystemen verwendete 3D-Objekterkennungsdatensatz kurz vorgestellt, wobei der Schwerpunkt hauptsächlich auf der Bewertung der Vorteile und Einschränkungen verschiedener Sensormodi sowie der Eigenschaften öffentlicher Datensätze liegt .
Zunächst werden in der Tabelle drei Arten von Sensoren angezeigt: Kamera, Punktwolke und multimodal (Kamera und Lidar). Für jeden Typ werden die Hardwarekosten, Vorteile und Einschränkungen aufgeführt. Der Vorteil von Kameradaten besteht darin, dass sie reichhaltige Farb- und Texturinformationen liefern. Ihre Einschränkungen liegen jedoch im Mangel an Tiefeninformationen und in ihrer Anfälligkeit gegenüber Licht- und Wettereffekten. LiDAR kann genaue Tiefeninformationen liefern, ist jedoch teuer und verfügt über keine Farbinformationen.
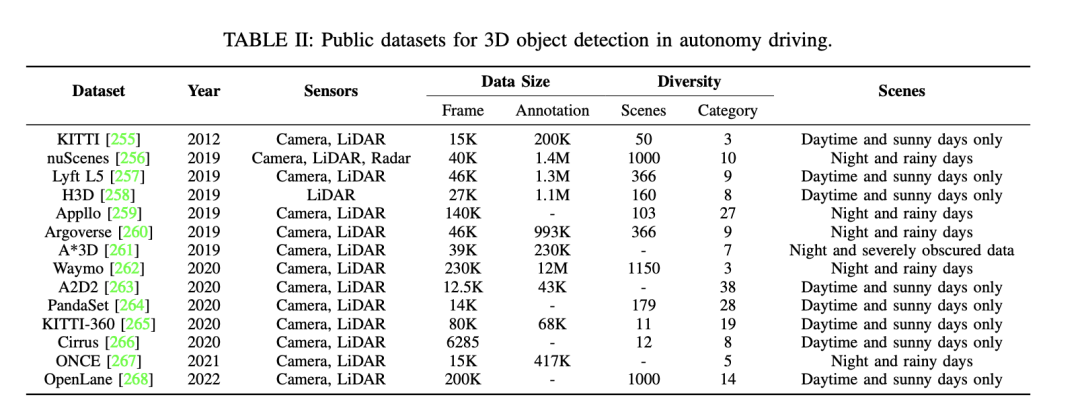
Als nächstes stehen einige weitere öffentliche Datensätze für die 3D-Objekterkennung beim autonomen Fahren zur Verfügung. Zu diesen Datensätzen gehören KITTI, nuScenes, Waymo usw. Einzelheiten zu diesen Datensätzen sind wie folgt: – Der KITTI-Datensatz enthält Daten, die über mehrere Jahre hinweg unter Verwendung verschiedener Sensortypen veröffentlicht wurden. Es bietet eine große Anzahl von Bildern und Anmerkungen sowie eine Vielzahl von Szenen, einschließlich Szenennummern und -kategorien sowie verschiedener Szenentypen wie Tag, sonnig, Nacht, regnerisch usw. – Der nuScenes-Datensatz ist ebenfalls ein wichtiger Datensatz, der auch Daten enthält, die über mehrere Jahre hinweg veröffentlicht wurden. Dieser Datensatz nutzt eine Vielzahl von Sensoren und bietet eine große Anzahl an Frames und Anmerkungen. Es deckt eine Vielzahl von Szenarien ab, darunter unterschiedliche Szenennummern und -kategorien sowie verschiedene Szenentypen. – Der Waymo-Datensatz ist ein weiterer Datensatz für autonomes Fahren, der ebenfalls Daten aus mehreren Jahren enthält. Dieser Datensatz nutzt verschiedene Arten von Sensoren und bietet eine große Anzahl an Frames und Anmerkungen. Es deckt verschiedene Bereiche ab
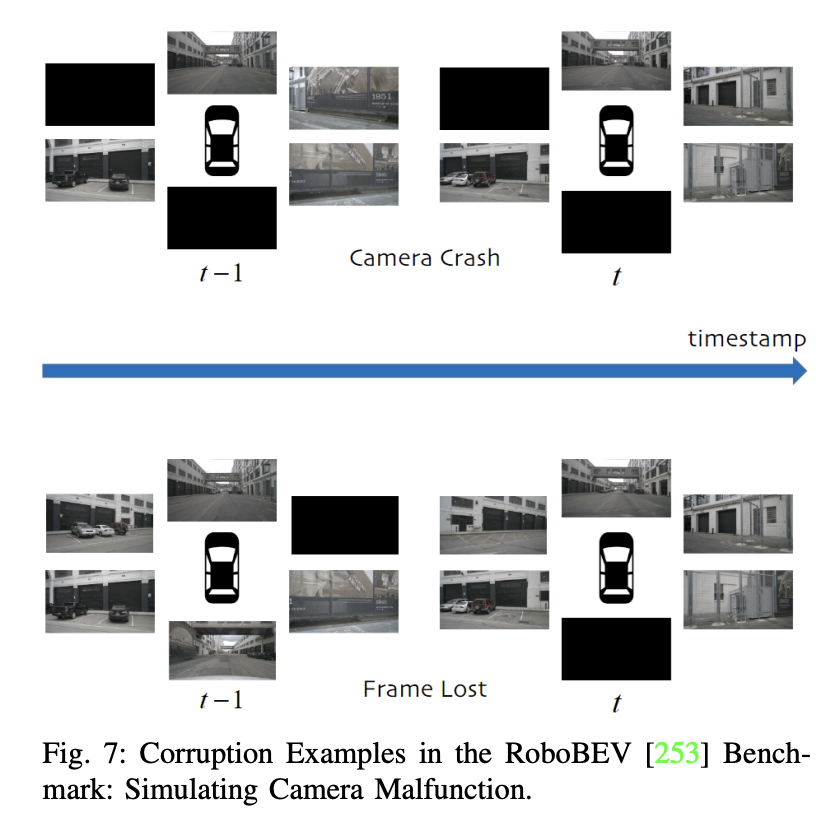
Darüber hinaus wird die Forschung zu „sauberen“ Datensätzen zum autonomen Fahren erwähnt und die Bedeutung der Bewertung der Modellrobustheit unter lauten Szenarien hervorgehoben. Einige Studien konzentrieren sich auf Kamera-Single-Modality-Methoden unter rauen Bedingungen, während andere multimodale Datensätze sich auf Lärmprobleme konzentrieren. Der GROUNDED-Datensatz konzentriert sich beispielsweise auf die Positionierung von Bodenradaren unter verschiedenen Wetterbedingungen, während der offene ApolloScape-Datensatz Lidar-, Kamera- und GPS-Daten umfasst, die eine Vielzahl von Wetter- und Lichtbedingungen abdecken.
Aufgrund der unerschwinglichen Kosten für die Erfassung umfangreicher verrauschter Daten in der realen Welt greifen viele Studien auf die Verwendung synthetischer Datensätze zurück. ImageNet-C ist beispielsweise eine Benchmark-Studie gegen häufige Störungen in Bildklassifizierungsmodellen. Diese Forschungsrichtung wurde anschließend auf robuste Datensätze ausgeweitet, die auf die 3D-Objekterkennung beim autonomen Fahren zugeschnitten sind. 2. Visionbasierte 3D-Objekterkennung 3D-Objekterkennung, monokulare 3D-Objekterkennung nur mit Kamera und tiefenunterstützte monokulare 3D-Objekterkennung.
Diese Methode nutzt Vorkenntnisse über in Bildern verborgene Objektformen und Szenengeometrie, um die Herausforderung der monokularen 3D-Objekterkennung zu lösen. Durch die Einführung vorab trainierter Teilnetze oder Hilfsaufgaben können Vorkenntnisse zusätzliche Informationen oder Einschränkungen liefern, um die genaue Lokalisierung von 3D-Objekten zu unterstützen und die Genauigkeit und Robustheit der Erkennung zu verbessern. Zu den allgemeinen Vorkenntnissen gehören Objektform, geometrische Konsistenz, zeitliche Einschränkungen und Segmentierungsinformationen. Beispielsweise geht der Mono3D-Algorithmus zunächst davon aus, dass das 3D-Objekt auf einer festen Grundebene liegt, und verwendet dann die vorherige 3D-Form des Objekts, um den Begrenzungsrahmen im 3D-Raum zu rekonstruieren. 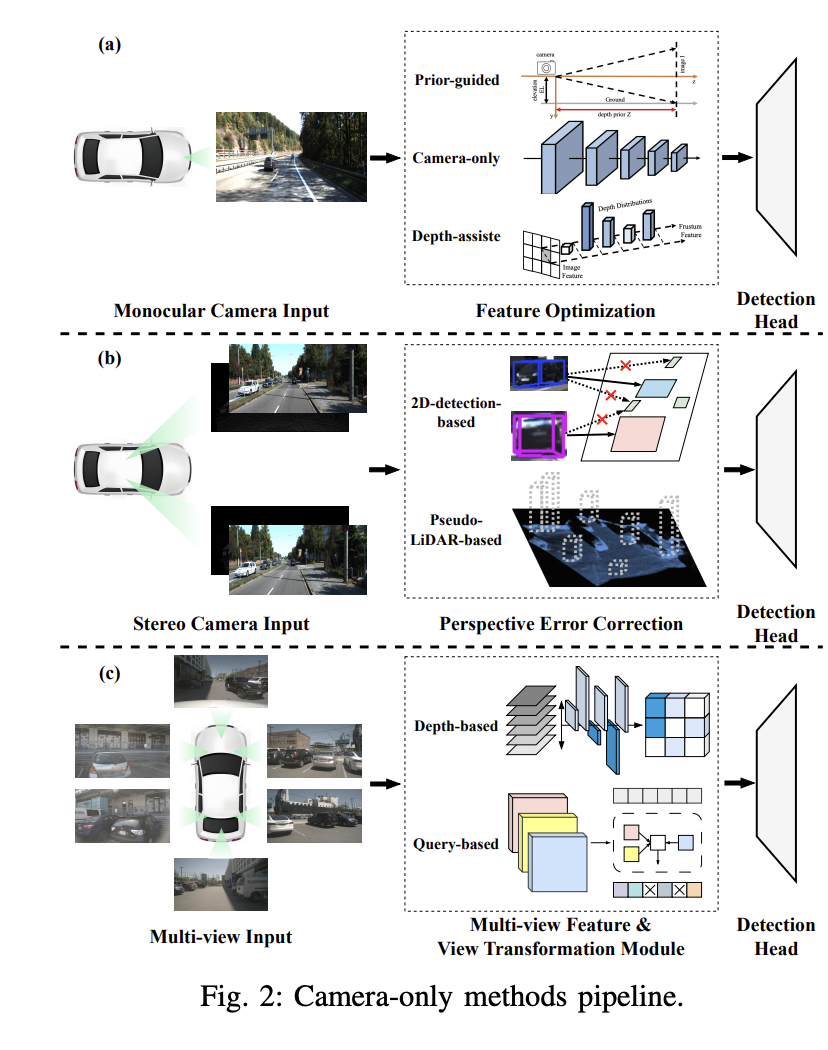
Die Tiefenschätzung spielt eine Schlüsselrolle bei der tiefenunterstützten monokularen 3D-Objekterkennung. Um genauere monokulare Erkennungsergebnisse zu erzielen, nutzen viele Studien vorab trainierte zusätzliche Netzwerke zur Tiefenschätzung. Dieser Prozess beginnt mit der Umwandlung des monokularen Bildes in ein Tiefenbild mithilfe eines vorab trainierten Tiefenschätzers wie MonoDepth. Anschließend werden zwei Hauptmethoden zur Verarbeitung von Tiefenbildern und monokularen Bildern angewendet. Beispielsweise verwendet der Pseudo-LiDAR-Detektor ein vorab trainiertes Tiefenschätzungsnetzwerk, um Pseudo-LiDAR-Darstellungen zu generieren. Aufgrund von Fehlern bei der Bild-zu-LiDAR-Erzeugung besteht jedoch eine große Leistungslücke zwischen Pseudo-LiDAR und LiDAR-basierten Detektoren. 
Tiefenbasierte Multi-View-Methoden: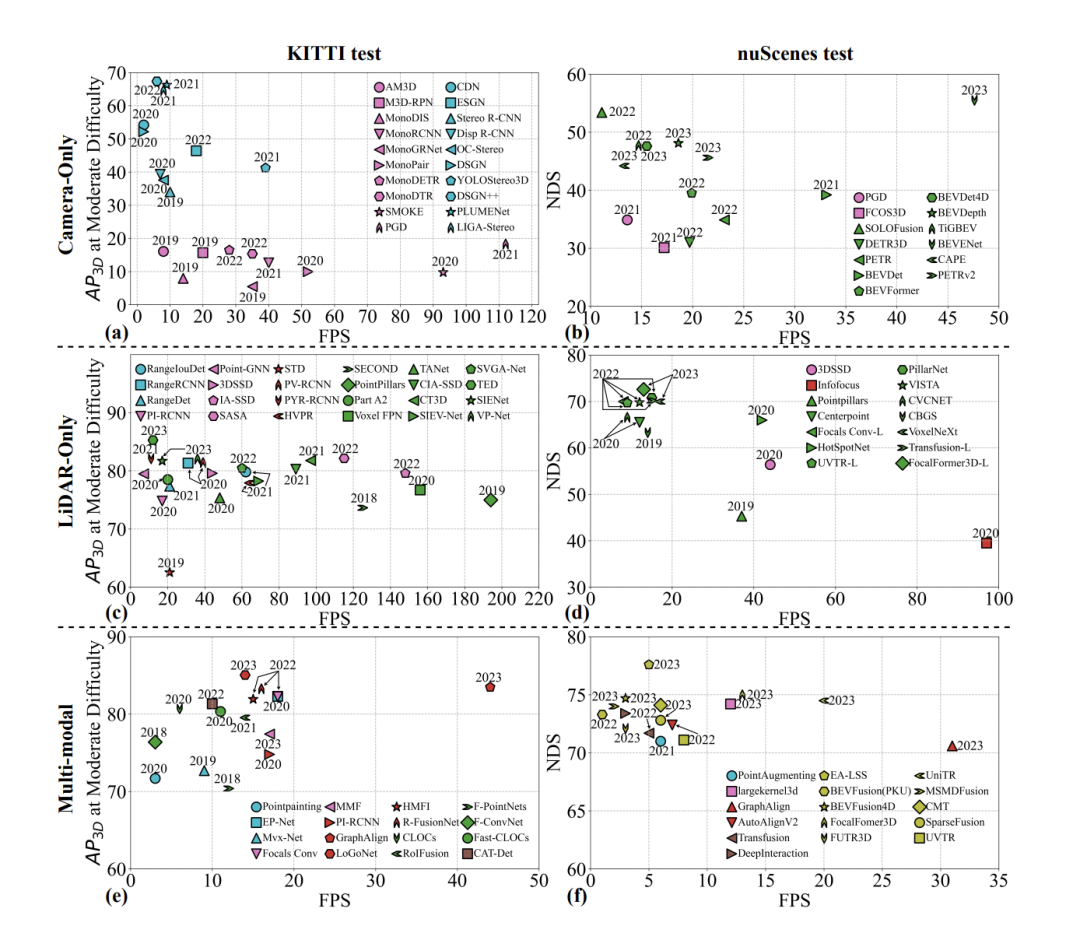
Die voxelbasierte 3D-Objekterkennungsmethode schlägt vor, spärliche Punktwolken zu segmentieren und in regelmäßige Voxel zu verteilen, um eine dichte Datendarstellung zu bilden. Im Vergleich zu ansichtsbasierten Methoden nutzen voxelbasierte Methoden räumliche Faltung, um 3D-Rauminformationen effektiv wahrzunehmen und eine höhere Erkennungsgenauigkeit zu erreichen, was für die Sicherheitswahrnehmung beim autonomen Fahren von entscheidender Bedeutung ist. Allerdings stehen diese Methoden noch vor folgenden Herausforderungen:
Um diese Herausforderungen zu meistern, ist es notwendig, die Einschränkungen der Datendarstellung zu überwinden, die Netzwerkfunktionsfähigkeiten und die Zielpositionierungsgenauigkeit zu verbessern und das Verständnis des Algorithmus für komplexe Szenen zu stärken. Obwohl Optimierungsstrategien unterschiedlich sind, zielen sie im Allgemeinen darauf ab, sowohl die Datendarstellung als auch die Modellstruktur zu optimieren.
Dank des Erfolgs von PC im Bereich Deep Learning übernimmt die punktbasierte 3D-Objekterkennung viele ihrer Frameworks und schlägt vor, 3D-Objekte ohne Vorverarbeitung direkt von Originalpunkten aus zu erkennen. Im Vergleich zu voxelbasierten Methoden behält die ursprüngliche Punktwolke die maximale Menge an Originalinformationen bei, was sich positiv auf die feinkörnige Merkmalserfassung auswirkt und zu einer hohen Genauigkeit führt. Gleichzeitig bietet eine Reihe von Arbeiten zu PointNet natürlich eine solide Grundlage für punktbasierte Methoden. Punktbasierte 3D-Objektdetektoren bestehen aus zwei Grundkomponenten: Punktwolken-Sampling und Feature-Learning. Derzeit wird die Leistung punktbasierter Methoden noch von zwei Faktoren beeinflusst: der Anzahl der Kontextpunkte und dem beim Feature-Lernen verwendeten Kontextradius. . Beispielsweise können durch Erhöhen der Anzahl der Kontextpunkte detailliertere 3D-Informationen erhalten werden, die Inferenzzeit des Modells wird jedoch erheblich verlängert. Ebenso kann die Reduzierung des Kontextradius den gleichen Effekt haben. Daher kann die Auswahl geeigneter Werte für diese beiden Faktoren es dem Modell ermöglichen, ein Gleichgewicht zwischen Genauigkeit und Geschwindigkeit zu erreichen. Da außerdem jeder Punkt in der Punktwolke berechnet werden muss, ist der Punktwolken-Sampling-Prozess der Hauptfaktor, der den Echtzeitbetrieb punktbasierter Methoden einschränkt. Um die oben genannten Probleme zu lösen, sind die meisten vorhandenen Methoden insbesondere auf die beiden Grundkomponenten punktbasierter 3D-Objektdetektoren optimiert: 1) Punktabtastung 2) Merkmalslernen
Punktbasierte 3D-Objekterkennungsmethoden erben viele Deep-Learning-Frameworks und schlagen vor, 3D-Objekte ohne Vorverarbeitung direkt aus Rohpunktwolken zu erkennen. Im Vergleich zu voxelbasierten Methoden behält die ursprüngliche Punktwolke die ursprünglichen Informationen maximal bei, was der Erfassung feinkörniger Merkmale förderlich ist und dadurch eine hohe Genauigkeit erreicht. Gleichzeitig bietet die PointNet-Arbeitsreihe eine solide Grundlage für punktbasierte Methoden. Bisher wird die Leistung punktbasierter Methoden jedoch noch von zwei Faktoren beeinflusst: der Anzahl der Kontextpunkte und dem Kontextradius, der beim Feature-Learning verwendet wird. Wenn Sie beispielsweise die Anzahl der Kontextpunkte erhöhen, können detailliertere 3D-Informationen erhalten werden, die Inferenzzeit des Modells wird jedoch erheblich verlängert. Ebenso wird durch die Reduzierung des Kontextradius derselbe Effekt erzielt. Durch die Auswahl geeigneter Werte für diese beiden Faktoren kann das Modell daher ein Gleichgewicht zwischen Genauigkeit und Geschwindigkeit erreichen. Darüber hinaus ist der Punktwolken-Sampling-Prozess der Hauptfaktor, der den Echtzeitbetrieb punktbasierter Methoden einschränkt, da Berechnungen für jeden Punkt in der Punktwolke durchgeführt werden müssen. Um diese Probleme zu lösen, optimieren bestehende Methoden hauptsächlich um zwei grundlegende Komponenten punktbasierter 3D-Objektdetektoren: 1) Punktwolkenabtastung; 2) Merkmalslernen.
Farth Point Sampling (FPS) ist von PointNet++ abgeleitet und eine Punktwolken-Sampling-Methode, die häufig in punktbasierten Methoden verwendet wird. Sein Ziel besteht darin, einen repräsentativen Satz von Punkten aus der ursprünglichen Punktwolke auszuwählen, um den Abstand zwischen ihnen zu maximieren und so die räumliche Verteilung der gesamten Punktwolke bestmöglich abzudecken. PointRCNN ist ein bahnbrechender zweistufiger Detektor für punktbasierte Methoden, der PointNet++ als Backbone-Netzwerk verwendet. Im ersten Schritt werden 3D-Vorschläge aus Punktwolken von unten nach oben generiert. In der zweiten Stufe werden die Vorschläge durch die Kombination semantischer Merkmale und lokaler räumlicher Merkmale verfeinert. Bestehende FPS-basierte Methoden sind jedoch immer noch mit einigen Problemen konfrontiert: 1) Punkte, die nichts mit der Erkennung zu tun haben, sind ebenfalls am Abtastprozess beteiligt, was einen zusätzlichen Rechenaufwand mit sich bringt. 2) Punkte sind in verschiedenen Teilen des Objekts ungleichmäßig verteilt, was zu suboptimalen Abtaststrategien führt. Um diese Probleme anzugehen, übernahmen nachfolgende Arbeiten ein FPS-ähnliches Designparadigma und führten Verbesserungen durch, wie z. B. durch Segmentierung gesteuerte Hintergrundpunktfilterung, Zufallsstichprobe, Merkmalsraumstichprobe, Voxel-basierte Stichprobe und Strahlengruppierungs-basierte Stichprobe.
Die Feature-Lernphase punktbasierter 3D-Objekterkennungsmethoden zielt darauf ab, diskriminierende Feature-Darstellungen aus spärlichen Punktwolkendaten zu extrahieren. Das in der Feature-Lernphase verwendete neuronale Netzwerk sollte die folgenden Eigenschaften aufweisen: 1) Invarianz, das Punktwolken-Backbone-Netzwerk sollte unempfindlich gegenüber der Reihenfolge der Eingabepunktwolke sein. 2) Es verfügt über lokale Wahrnehmungsfähigkeiten und kann lokale Bereiche erfassen und modellieren und lokale Merkmale extrahieren; 3) Die Fähigkeit, Kontextinformationen zu integrieren und Merkmale aus globalen und lokalen Kontextinformationen zu extrahieren. Basierend auf den oben genannten Eigenschaften ist eine große Anzahl von Detektoren für die Verarbeitung roher Punktwolken ausgelegt. Die meisten Methoden können nach den verwendeten Kernoperatoren unterteilt werden: 1) PointNet-basierte Methoden; 2) Graph-Neuronale Netzwerk-basierte Methoden;
PointNet-basierte Methoden basieren hauptsächlich auf der Mengenabstraktion, um die Originalpunkte herunterzurechnen, lokale Informationen zu aggregieren und Kontextinformationen zu integrieren und gleichzeitig die Symmetrieinvarianz der Originalpunkte beizubehalten. Point-RCNN ist die erste zweistufige Arbeit unter den punktbasierten Methoden und erzielt eine hervorragende Leistung, steht jedoch immer noch vor dem Problem hoher Rechenkosten. Nachfolgende Arbeiten lösten dieses Problem, indem sie eine zusätzliche semantische Segmentierungsaufgabe in den Erkennungsprozess einführten, um Hintergrundpunkte herauszufiltern, die nur minimal zur Erkennung beitragen.
Graphische neuronale Netze (GNN) verfügen über adaptive Strukturen, dynamische Nachbarschaften, die Fähigkeit, lokale und globale Kontextbeziehungen aufzubauen, und sind robust gegenüber unregelmäßigen Stichproben. Point-GNN ist eine bahnbrechende Arbeit, die ein einstufiges graphisches neuronales Netzwerk entwirft, um die Kategorie und Form von Objekten durch automatische Registrierungsmechanismen, Zusammenführungs- und Bewertungsvorgänge vorherzusagen und die Verwendung graphischer neuronaler Netzwerke als neue Methode zur 3D-Objekterkennung demonstriert. Potenzial.
In den letzten Jahren wurden Transformer (Transformer) in der Punktwolkenanalyse untersucht und haben bei vielen Aufgaben gute Leistungen erbracht. Pointformer führt beispielsweise lokale und globale Aufmerksamkeitsmodule ein, um 3D-Punktwolken zu verarbeiten, das lokale Transformer-Modul dient zur Modellierung von Interaktionen zwischen Punkten in lokalen Regionen und der globale Transformer zielt darauf ab, kontextsensitive Darstellungen auf Szenenebene zu erlernen. Group-free nutzt direkt alle Punkte in der Punktwolke, um die Merkmale jedes Objektkandidaten zu berechnen, wobei der Beitrag jedes Punkts durch ein automatisch erlerntes Aufmerksamkeitsmodul bestimmt wird. Diese Methoden demonstrieren das Potenzial transformatorbasierter Methoden bei der Verarbeitung unstrukturierter und ungeordneter Rohpunktwolken.
Punktwolkenbasierte 3D-Objekterkennungsmethoden bieten eine hohe Auflösung und bewahren die räumliche Struktur der Originaldaten, sind jedoch bei der Verarbeitung spärlicher Daten mit hoher Rechenkomplexität und geringer Effizienz konfrontiert. Im Gegensatz dazu bieten voxelbasierte Methoden eine strukturierte Datendarstellung, verbessern die Recheneffizienz und erleichtern die Anwendung der traditionellen Faltungs-Neuronalen-Netzwerk-Technologie. Durch den Diskretisierungsprozess gehen jedoch häufig feine räumliche Details verloren. Um diese Probleme zu lösen, wurden Punkt-Voxel (PV)-basierte Methoden entwickelt. Punkt-Voxel-Methoden zielen darauf ab, die feinkörnigen Informationserfassungsfähigkeiten punktbasierter Methoden und die Recheneffizienz voxelbasierter Methoden zu nutzen. Durch die Integration dieser Methoden können Punkt-Voxel-basierte Methoden Punktwolkendaten detaillierter verarbeiten und globale Strukturen und mikrogeometrische Details erfassen. Dies ist für die Sicherheitswahrnehmung beim autonomen Fahren von entscheidender Bedeutung, da die Entscheidungsgenauigkeit des autonomen Fahrsystems von hochpräzisen Erkennungsergebnissen abhängt.
Das Hauptziel der Punkt-Voxel-Methode besteht darin, durch Punkt-zu-Voxel- oder Voxel-zu-Punkt-Konvertierung eine Merkmalsinteraktion zwischen Voxeln und Punkten zu erreichen. In vielen Arbeiten wurde die Idee untersucht, die Punkt-Voxel-Merkmalsfusion in Backbone-Netzwerken zu nutzen. Diese Methoden können in zwei Kategorien unterteilt werden: 1) frühe Fusion; 2) späte Fusion.
a) Frühe Fusion: Einige Methoden haben die Verwendung neuer Faltungsoperatoren zur Fusion von Voxel- und Punktmerkmalen untersucht, und PVCNN ist möglicherweise die erste Arbeit in dieser Richtung. Bei diesem Ansatz wandelt der voxelbasierte Zweig zunächst Punkte in ein Voxelgitter mit niedriger Auflösung um und aggregiert benachbarte Voxelmerkmale durch Faltung. Anschließend werden die Merkmale auf Voxelebene durch einen als Devoxelisierung bezeichneten Prozess wieder in Merkmale auf Punktebene umgewandelt und mit Merkmalen verschmolzen, die durch den punktbasierten Zweig erhalten wurden. Der punktbasierte Zweig extrahiert Features für jeden einzelnen Punkt. Da keine Nachbarinformationen aggregiert werden, kann diese Methode mit höheren Geschwindigkeiten ausgeführt werden. Anschließend wurde SPVCNN auf den Bereich der Objekterkennung basierend auf PVCNN ausgeweitet. Andere Methoden versuchen aus unterschiedlichen Perspektiven zu verbessern, etwa durch Hilfsaufgaben oder Multiskalen-Feature-Fusion.
b) Post-Fusion: Diese Methodenreihe verwendet hauptsächlich ein zweistufiges Erkennungsframework. Zunächst werden vorläufige Objektvorschläge mithilfe eines voxelbasierten Ansatzes generiert. Anschließend werden Merkmale auf Punktebene verwendet, um den Erkennungsrahmen genau zu unterteilen. Das von Shi et al. vorgeschlagene PV-RCNN ist ein Meilenstein in der Punkt-Voxel-basierten Methode. Es verwendet SECOND als Detektor der ersten Stufe und schlägt eine Verfeinerungsstufe der zweiten Stufe mit RoI-Grid-Pooling für die Fusion von Schlüsselpunktmerkmalen vor. Nachfolgende Arbeiten folgen hauptsächlich dem oben genannten Paradigma und konzentrieren sich auf den Fortschritt der Erkennung in der zweiten Stufe. Zu den bemerkenswerten Entwicklungen gehören Aufmerksamkeitsmechanismen, skalenbewusstes Pooling und punktdichtebewusste Verfeinerungsmodule.
Punktvoxelbasierte Methoden verfügen sowohl über die Recheneffizienz voxelbasierter Methoden als auch über die Fähigkeit punktbasierter Methoden, feinkörnige Informationen zu erfassen. Der Aufbau von Punkt-zu-Voxel- oder Voxel-zu-Punkt-Beziehungen sowie die Merkmalsfusion von Voxeln und Punkten bringen jedoch zusätzlichen Rechenaufwand mit sich. Daher können Punkt-Voxel-basierte Methoden im Vergleich zu Voxel-basierten Methoden eine bessere Erkennungsgenauigkeit erreichen, allerdings auf Kosten einer längeren Inferenzzeit. 4. Multimodale 3D-Objekterkennung und Bildfunktionen integrieren. Der Schlüssel liegt hier darin, sich auf die Projektion während der Feature-Fusion zu konzentrieren und nicht auf andere Projektionsprozesse in der Fusionsphase, wie z. B. Datenerweiterung usw. Abhängig von den verschiedenen Arten von Projektionen, die in der Fusionsphase verwendet werden, können projektionsbasierte 3D-Objekterkennungsmethoden weiter in die folgenden Kategorien unterteilt werden:
3D-Objekterkennung basierend auf Merkmalsprojektion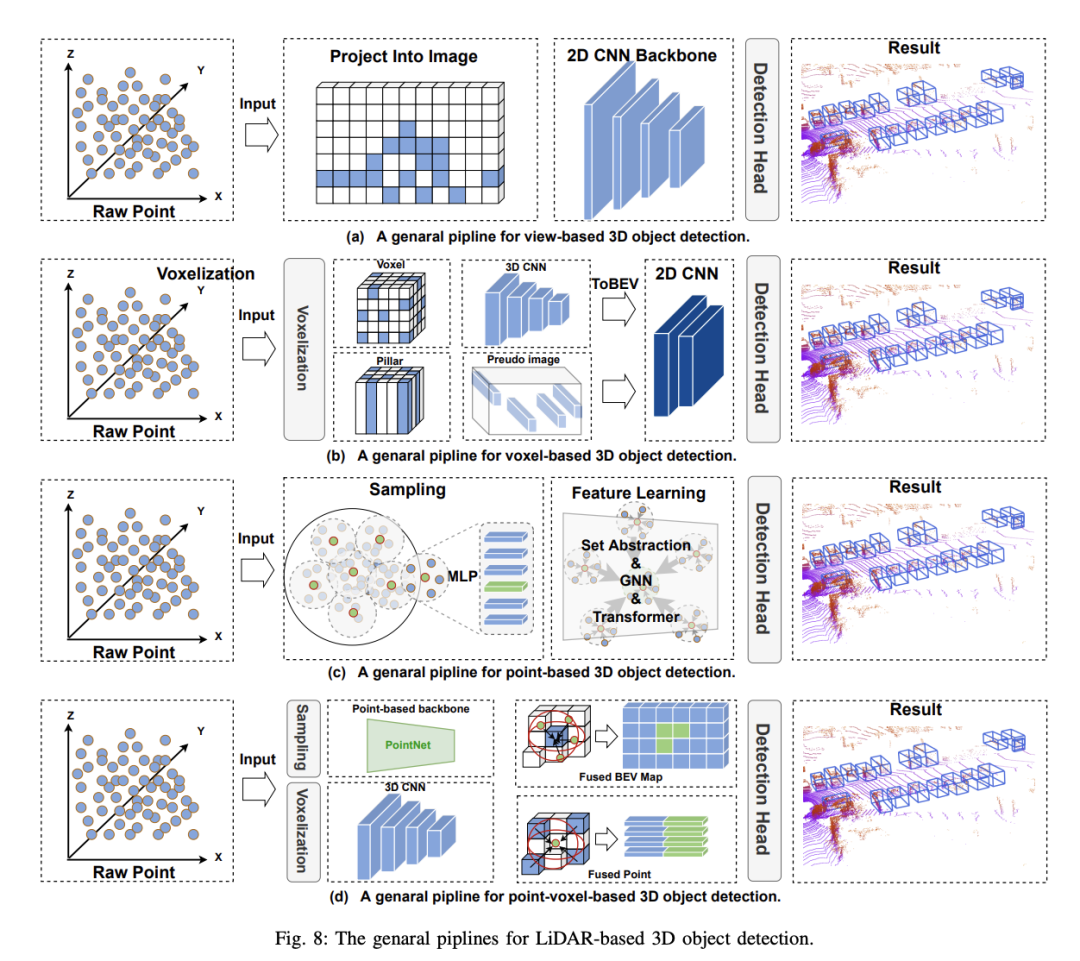 : Im Gegensatz zu Methoden, die auf Punktprojektion basieren, konzentriert sich diese Art von Methode hauptsächlich auf die Fusion von Punktwolkenmerkmalen mit Bildmerkmalen in der Phase der Punktwolkenmerkmalsextraktion. In diesem Prozess werden Punktwolke und Bildmodalitäten effektiv verschmolzen, indem eine Kalibrierungsmatrix angewendet wird, um das 3D-Koordinatensystem von Voxeln in das Pixelkoordinatensystem des Bildes umzuwandeln. Beispielsweise führt ContFuse Faltungs-Feature-Maps mit mehreren Maßstäben durch kontinuierliche Faltung zusammen.
: Im Gegensatz zu Methoden, die auf Punktprojektion basieren, konzentriert sich diese Art von Methode hauptsächlich auf die Fusion von Punktwolkenmerkmalen mit Bildmerkmalen in der Phase der Punktwolkenmerkmalsextraktion. In diesem Prozess werden Punktwolke und Bildmodalitäten effektiv verschmolzen, indem eine Kalibrierungsmatrix angewendet wird, um das 3D-Koordinatensystem von Voxeln in das Pixelkoordinatensystem des Bildes umzuwandeln. Beispielsweise führt ContFuse Faltungs-Feature-Maps mit mehreren Maßstäben durch kontinuierliche Faltung zusammen.
VirConv, MSMDFusion und SFD bilden durch Pseudopunktwolken einen einheitlichen Raum, und die Projektion erfolgt vor dem Feature-Lernen. Die durch die direkte Projektion verursachten Probleme werden durch anschließendes Feature-Lernen gelöst. Zusammenfassend stellen einheitliche, merkmalsbasierte 3D-Objekterkennungsmethoden derzeit äußerst genaue und robuste Lösungen dar. Obwohl sie eine Projektionsmatrix enthalten, findet diese Projektion nicht zwischen multimodalen Fusionen statt und wird daher als nicht-projektive 3D-Objekterkennungsmethode betrachtet. Im Gegensatz zu automatischen Projektionsmethoden zur Erkennung von 3D-Objekten lösen sie das Problem des Projektionsfehlers nicht direkt, sondern erstellen einen einheitlichen Raum und berücksichtigen mehrere Dimensionen der multimodalen 3D-Objekterkennung, um äußerst robuste multimodale Merkmale zu erhalten.
Die 3D-Objekterkennung spielt eine entscheidende Rolle bei der Wahrnehmung des autonomen Fahrens. In den letzten Jahren hat sich dieses Gebiet rasant entwickelt und eine große Anzahl von Forschungsarbeiten hervorgebracht. Basierend auf den vielfältigen Datenformen, die von Sensoren generiert werden, werden diese Methoden hauptsächlich in drei Typen unterteilt: bildbasiert, punktwolkenbasiert und multimodal. Die wichtigsten Bewertungsmaßstäbe dieser Methoden sind hohe Genauigkeit und geringe Latenz. Viele Rezensionen fassen diese Ansätze zusammen und konzentrieren sich dabei hauptsächlich auf die Kernprinzipien „hohe Genauigkeit und geringe Latenz“ und beschreiben ihre technische Entwicklung.
Im Zuge des Übergangs der autonomen Fahrtechnologie von Durchbrüchen zu praktischen Anwendungen legen die bestehenden Überprüfungen jedoch nicht den Schwerpunkt auf die Sicherheitswahrnehmung und decken nicht die aktuellen technischen Wege im Zusammenhang mit der Sicherheitswahrnehmung ab. Beispielsweise werden neuere multimodale Fusionsmethoden häufig während der experimentellen Phase auf ihre Robustheit getestet, ein Aspekt, der in der aktuellen Übersicht nicht vollständig berücksichtigt wurde.
Untersuchen Sie daher den 3D-Objekterkennungsalgorithmus erneut und konzentrieren Sie sich dabei auf „Genauigkeit, Latenz und Robustheit“ als Schlüsselaspekte. Wir klassifizieren frühere Bewertungen neu und legen dabei besonderen Wert auf die Neuklassifizierung aus Sicht der Sicherheitswahrnehmung. Es besteht die Hoffnung, dass diese Arbeit neue Einblicke in die zukünftige Forschung zur 3D-Objekterkennung liefern wird, die über die bloße Erforschung der Grenzen hoher Genauigkeit hinausgehen.

Das obige ist der detaillierte Inhalt vonKamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 ostringstream-Nutzung
ostringstream-Nutzung
 Anforderungen an die Hardwarekonfiguration des Webservers
Anforderungen an die Hardwarekonfiguration des Webservers
 So verwenden Sie die Max-Funktion
So verwenden Sie die Max-Funktion
 Der Unterschied zwischen externem Bildschirm und internem Bildschirm ist defekt
Der Unterschied zwischen externem Bildschirm und internem Bildschirm ist defekt
 n-tes Kind
n-tes Kind
 So fügen Sie ein Video in HTML ein
So fügen Sie ein Video in HTML ein
 Regelmäßige Verwendung von grep
Regelmäßige Verwendung von grep
 Was sind die beschrifteten Münzen?
Was sind die beschrifteten Münzen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



