


Yuanxiang hat das weltweit erste Open-Source-Großmodell XVERSE-Long-256K mit einer Kontextfensterlänge von 256 KB veröffentlicht. Dieses Modell unterstützt die Eingabe von 250.000 chinesischen Zeichen und ermöglicht so den Eintritt großer Modellanwendungen in die „Langtext-Ära“. Das Modell ist vollständig Open Source und kann ohne Bedingungen kostenlos kommerziell genutzt werden. Es enthält außerdem detaillierte Schritt-für-Schritt-Schulungsanleitungen, die es einer großen Anzahl kleiner und mittlerer Unternehmen, Forscher und Entwickler ermöglichen, „große“ Projekte zu realisieren Modellfreiheit“ früher.
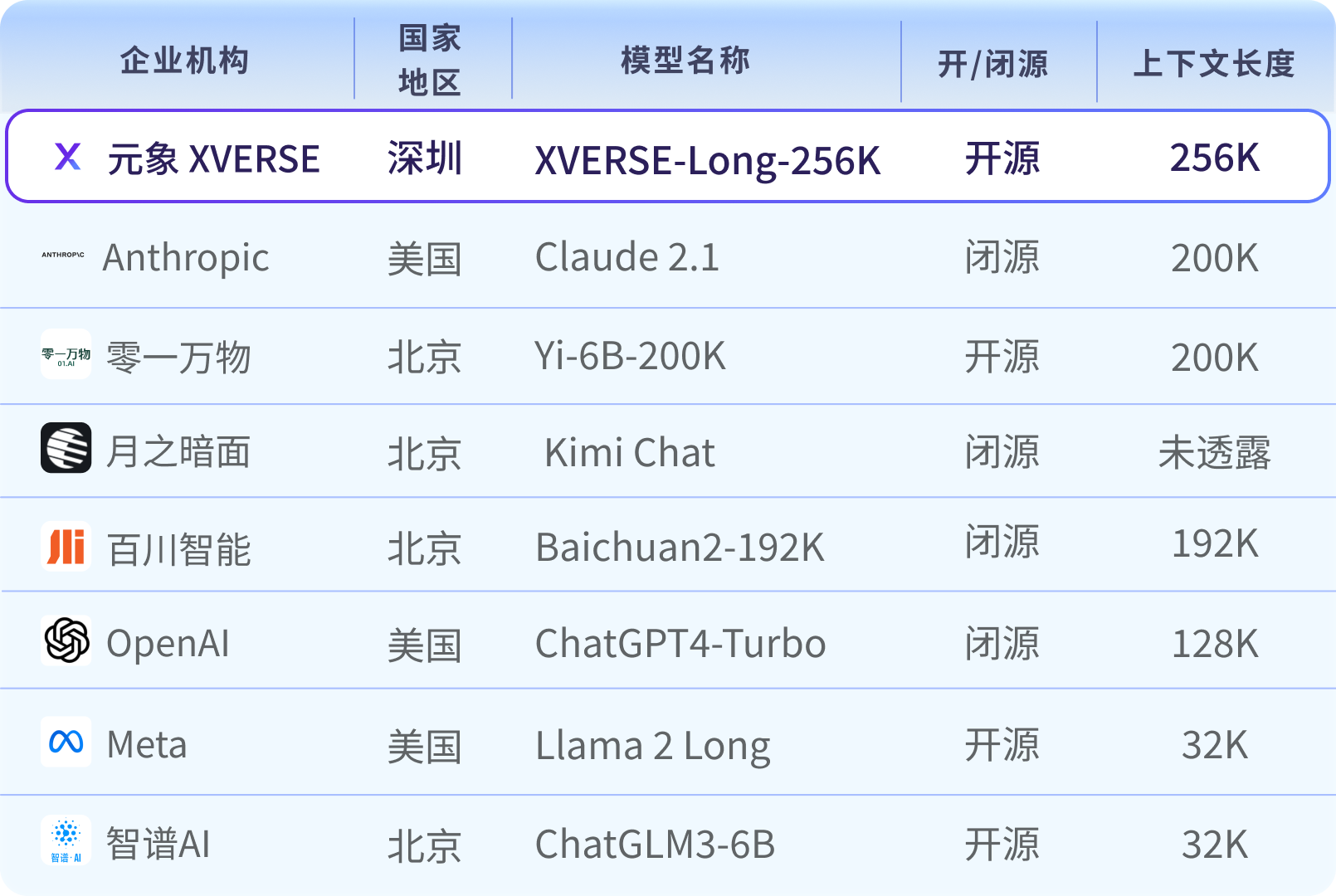 Globale Mainstream-Karte großer Langtextmodelle
Globale Mainstream-Karte großer Langtextmodelle
Die Menge der Parameter und die Menge hochwertiger Daten bestimmen die Rechenkomplexität großer Modelle, und die Langtexttechnologie (Long Context) ist der „Killer“ in der Entwicklung Aufgrund der neuen Technologie ist es schwierig zu entwickeln und zu entwickeln, und die meisten davon werden derzeit von kostenpflichtigen geschlossenen Quellen bereitgestellt.
Für Anwälte, Finanzanalysten oder Berater Lehrer, Prompt-Ingenieure, wissenschaftliche Forscher usw. können die Arbeit der Analyse und Verarbeitung längerer Texte 2 lösen. In Rollenspielen oder Chat-Anwendungen kann es das Gedächtnisproblem des Modells „Vergessen“ lindern; der vorherige Dialog oder das „Halluzinations“-Problem des Unsinns; 3. KI-Agenten besser bei der Planung und Entscheidungsfindung auf der Grundlage historischer Informationen unterstützen; 4. KI-nativen Anwendungen dabei helfen, ein kohärentes und personalisiertes Benutzererlebnis aufrechtzuerhalten;
Bisher hat XVERSE-Long-256K die Lücke im Open-Source-Ökosystem geschlossen und mit Yuanxiangs bisherigen 7-Milliarden-, 13-Milliarden- und 65-Milliarden-Parameter-Großmodellen einen „Hochleistungs-Familieneimer“ gebildet inländischen Open Source auf das weltweit erstklassige Niveau. 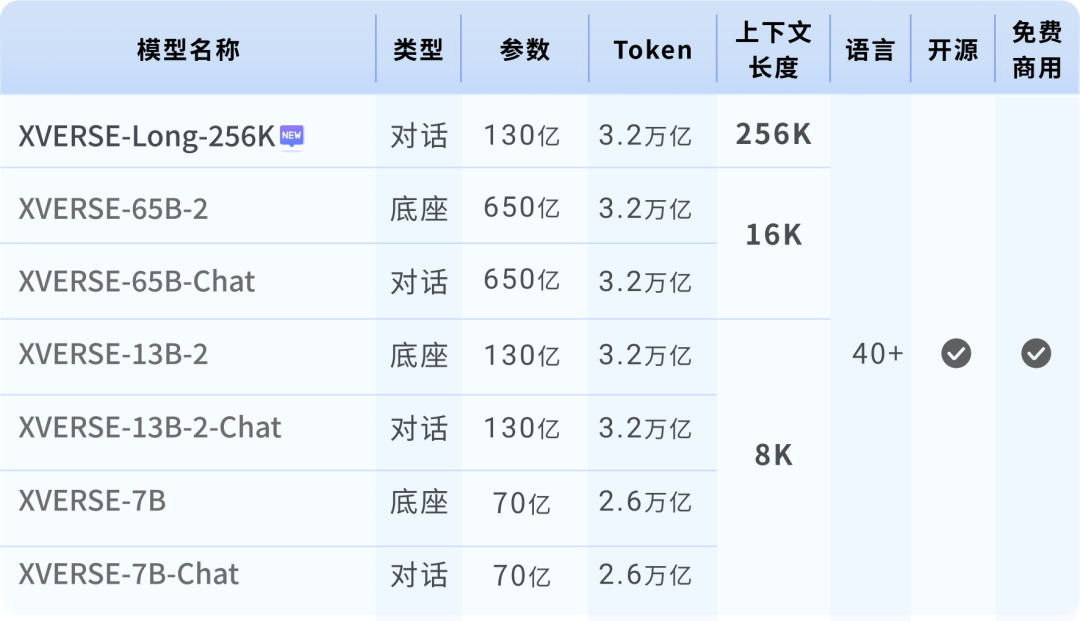 Yuanxiang-Großmodellserie
Yuanxiang-Großmodellserie
Kostenloser Download des Yuanxiang-Großmodells
Um sicherzustellen, dass die Branche über ein umfassendes, objektives und langfristiges Verständnis des Yuanxiang-Großmodells verfügt, haben die Forscher auf maßgebliche Branchenbewertungen zurückgegriffen und eine umfassende Bewertung mit 9 Punkten entwickelt Bewertungssystem in sechs Dimensionen. XVERSE-Long-256K schneiden alle gut ab und übertreffen andere Langtextmodelle.
Die globalen Mainstream-Langtext-Open-Source-Großmodell-Evaluierungsergebnisse Dieser Test verbirgt einen Satz in einem langen Textkorpus, der nichts mit seinem Inhalt zu tun hat, und verwendet Fragen in natürlicher Sprache, damit das große Modell den Satz genau extrahieren kann.
Roman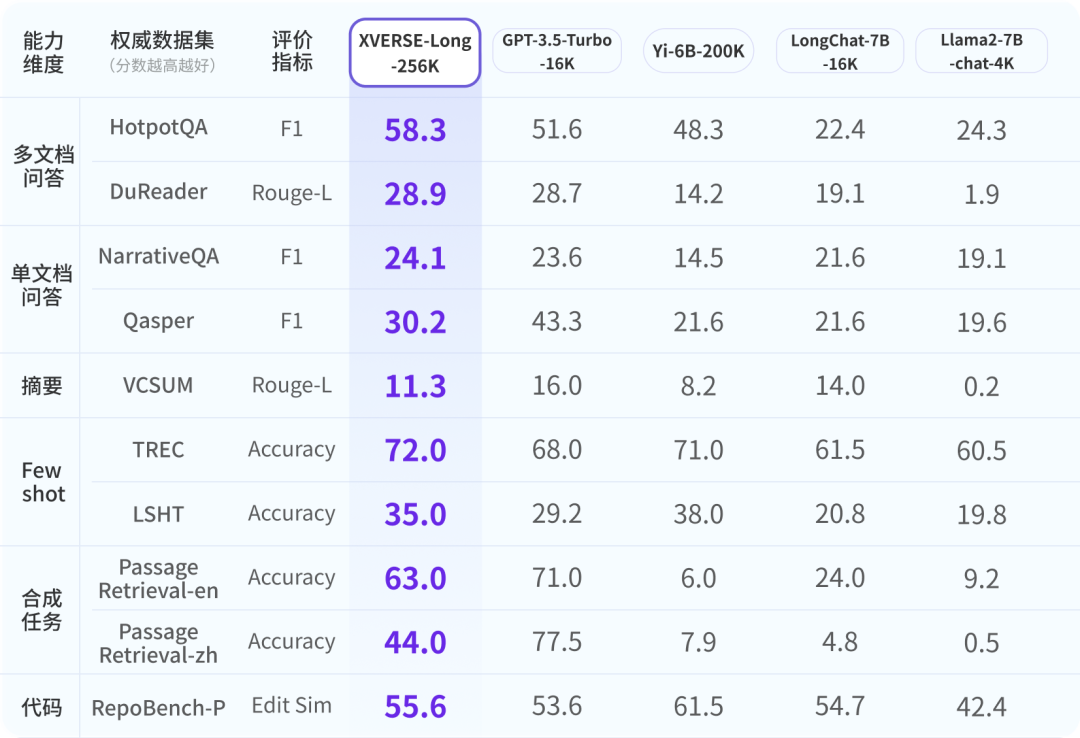
Leseverständnis
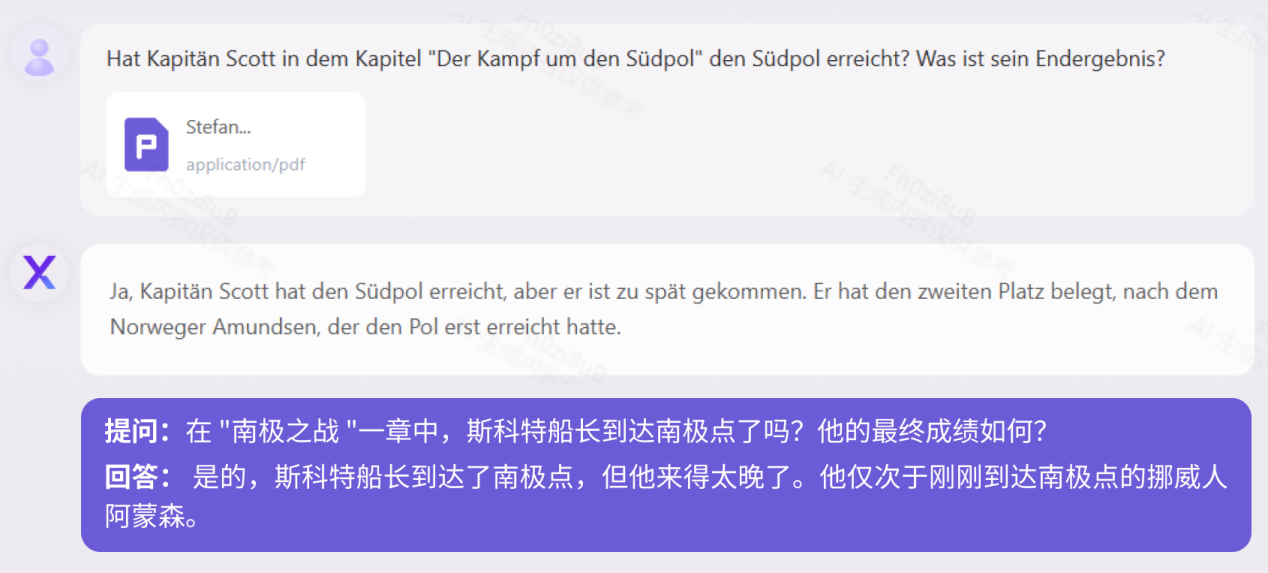
Derzeit unterstützen die meisten großen Modelle in China nur zweisprachig Chinesisch und Englisch, Yuanxiang unterstützt jedoch mehr als 40 Sprachen. Wir haben den russischen Romanklassiker „How the Steel Was Tempered“ mit 160.000 Zeichen und die deutsche historische Biografie „When the Stars of Mankind Shine“ mit 410.000 Zeichen getestet. Test „How Steel Was Tempered (Russische Version)“
Test „When Human Stars Shine (Deutsche Version)“Gesetze und Vorschriften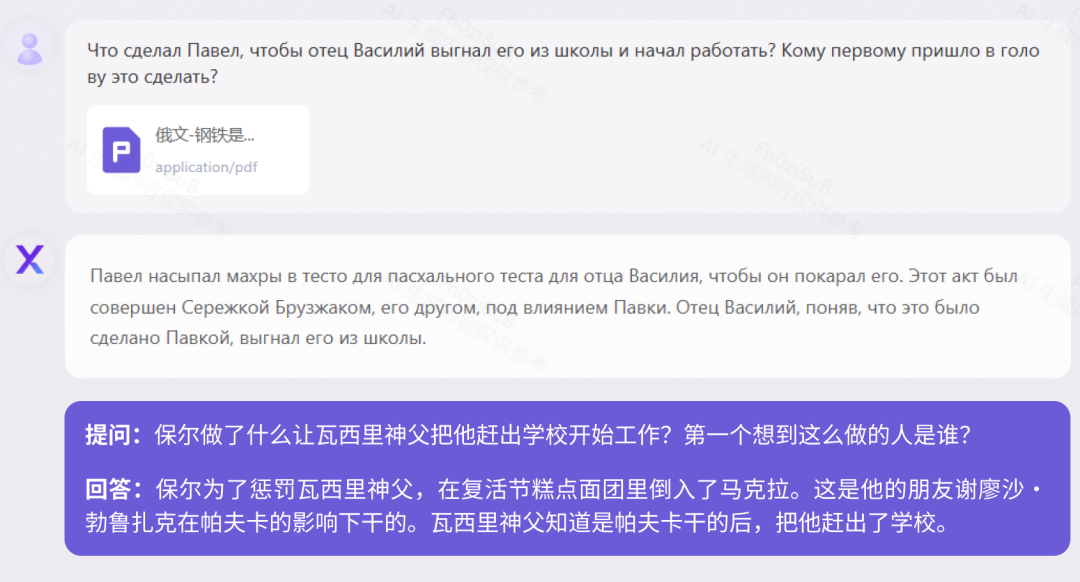
Genaue Anwendung
Basierend auf „China Taking the Civil.“ Das Gesetzbuch der Volksrepublik China zeigt als Beispiel die Erklärung juristischer Begriffe, die logische Analyse von Fällen und die flexible Anwendung in Kombination mit der Realität: Test „Zivilgesetzbuch“
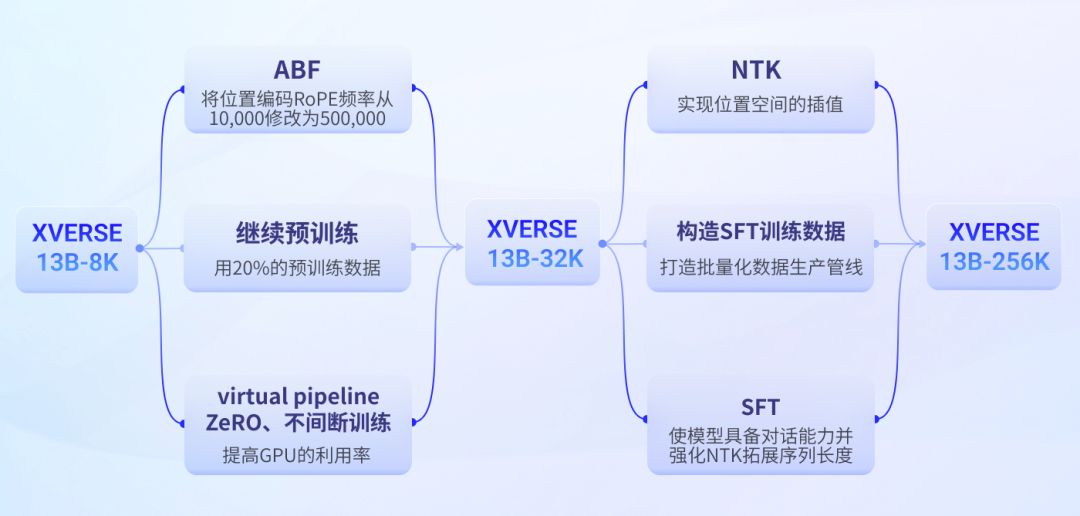
Lernen Sie Schritt für Schritt So trainieren Sie große Langtextmodelle 


Technische Herausforderung
Yuanxiang Langtext-Trainingsprozess für große Modelle
GitHub: https://github.com/xverse-ai/XVERSE-13B
umarmendes Gesicht: https://huggingface.co/xverse/XVERSE-13B-256KMagic Match: https://modelscope.cn/models/xverse/XVERSE-13B-256KFür Anfragen senden Sie bitte: opensource @ xverse.cn
Das obige ist der detaillierte Inhalt vonDas weltweit längste Open-Source-Modell XVERSE-Long-256K, das für die kommerzielle Nutzung bedingungslos kostenlos ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was sind die Python-Bibliotheken für künstliche Intelligenz?
Was sind die Python-Bibliotheken für künstliche Intelligenz?
 So löschen Sie eine Datenbank
So löschen Sie eine Datenbank
 Was bedeutet Uplink-Port?
Was bedeutet Uplink-Port?
 So beheben Sie einen DNS-Auflösungsfehler
So beheben Sie einen DNS-Auflösungsfehler
 Können aufgeladene Telefonrechnungen von Douyin erstattet werden?
Können aufgeladene Telefonrechnungen von Douyin erstattet werden?
 So stellen Sie Dateien wieder her, die aus dem Papierkorb geleert wurden
So stellen Sie Dateien wieder her, die aus dem Papierkorb geleert wurden
 So verwenden Sie „Gruppieren nach'.
So verwenden Sie „Gruppieren nach'.
 Neueste Nachrichten zu Shib-Münzen
Neueste Nachrichten zu Shib-Münzen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



