So wie Rhysfords Zauberstab die Legende außergewöhnlicher Zauberer aller Zeiten wie Dumbledore erschuf, beherrschen traditionelle groß angelegte Sprachmodelle mit enormem Potenzial nach Vortraining/Feinabstimmung des Codekorpus Wissen, das über die ursprüngliche Quelle hinausgeht . Insbesondere die erweiterte Version des großen Modells wurde in Bezug auf Code-Schreiben, stärkeres Denken, unabhängiger Verweis auf Ausführungsschnittstellen, unabhängige Verbesserung usw. verbessert, was es einfacher macht, als KI zu dienen Agent und führt nachgelagerte Aufgaben aus. Vorteile in jeder Hinsicht. Kürzlich hat ein Forschungsteam der University of Illinois at Urbana-Champaign (UIUC) einen wichtigen Bericht veröffentlicht. 
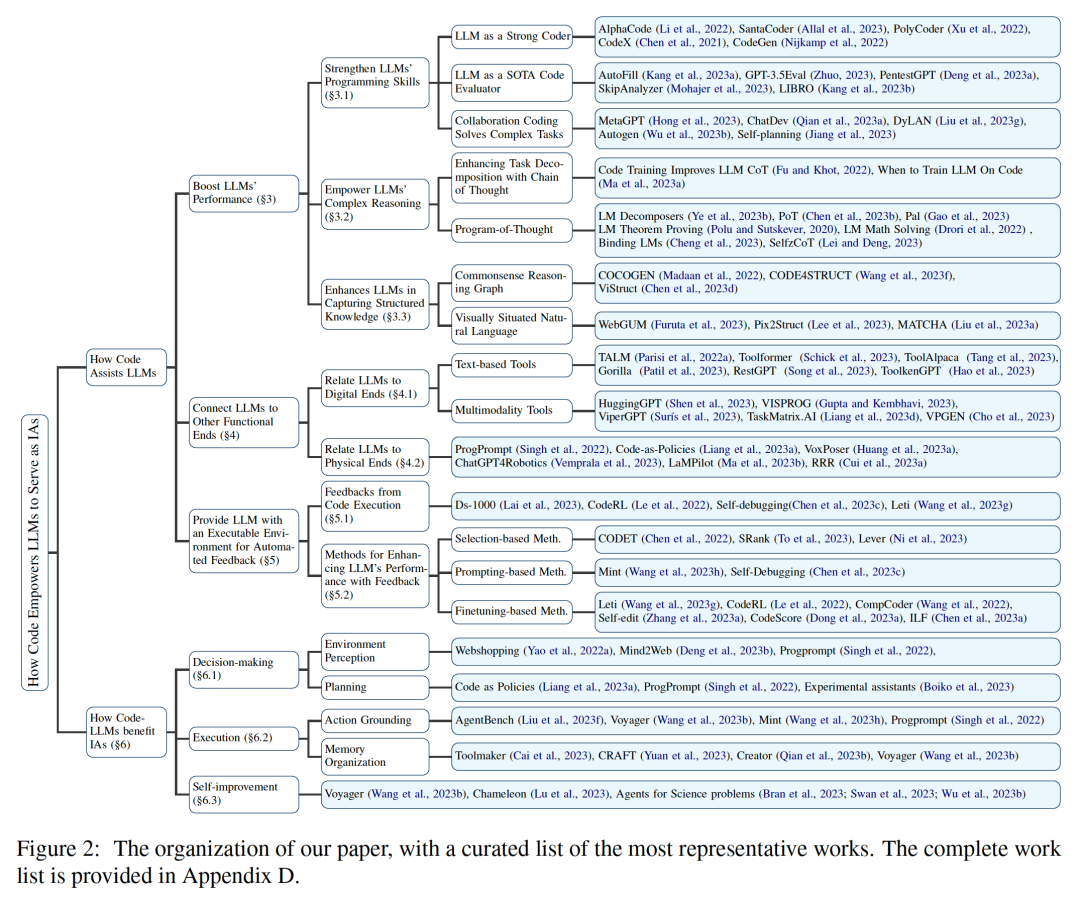
Link zum Papier: https://arxiv.org/abs/2401.00812Diese Rezension untersucht, wie Code große Sprachmodelle (LLMs) und ihre darauf basierenden intelligenten Agenten (Intelligent Agents) zu leistungsstarken Fähigkeiten befähigt . 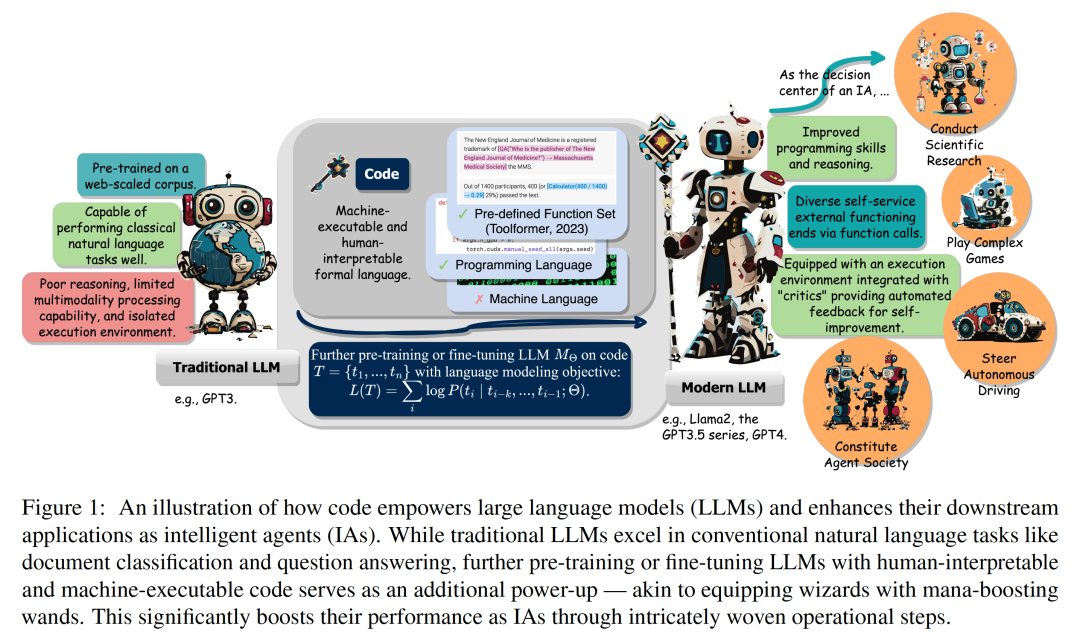 Dabei bezieht sich Code insbesondere auf eine formale Sprache, die maschinenausführbar und für Menschen lesbar ist, beispielsweise eine Programmiersprache, eine Reihe vordefinierter Funktionen usw. Ähnlich wie wir LLMs dazu anleiten, traditionelle natürliche Sprache zu verstehen/generieren, müssen LLMs nur die gleichen Trainingsziele für die Sprachmodellierung auf Codedaten anwenden, um sie mit Code vertraut zu machen. Im Gegensatz zu herkömmlichen Sprachmodellen haben die heute gängigen LLMs wie Llama2 und GPT4 nicht nur ihre Größe deutlich verbessert, sondern sie haben auch ein Code-Korpus-Training durchlaufen, das vom typischen Korpus natürlicher Sprache unabhängig ist. Code verfügt über eine standardisierte Syntax, logische Konsistenz, Abstraktion und Modularität und kann übergeordnete Ziele in ausführbare Schritte umwandeln, was ihn zu einem idealen Medium für die Verbindung von Menschen und Computern macht. Wie in Abbildung 2 dargestellt, haben die Forscher in dieser Übersicht relevante Arbeiten zusammengestellt und die verschiedenen Vorteile der Integration von Code in LLM-Trainingsdaten im Detail analysiert. Konkret haben Forscher beobachtet, dass die einzigartigen Eigenschaften von Code helfen: 1. Verbessern Sie die Code-Schreibfähigkeiten, Argumentationsfähigkeiten und strukturierten Informationsverarbeitungsfähigkeiten von LLMs, sodass sie auf komplexere natürliche Zwecke angewendet werden können Sprachaufgaben; 2. Leiten Sie LLMs an, um strukturierte und präzise Zwischenschritte zu generieren, die durch Funktionsaufrufe mit der Kompilierungs- und Ausführungsumgebung verbunden werden können.
Dabei bezieht sich Code insbesondere auf eine formale Sprache, die maschinenausführbar und für Menschen lesbar ist, beispielsweise eine Programmiersprache, eine Reihe vordefinierter Funktionen usw. Ähnlich wie wir LLMs dazu anleiten, traditionelle natürliche Sprache zu verstehen/generieren, müssen LLMs nur die gleichen Trainingsziele für die Sprachmodellierung auf Codedaten anwenden, um sie mit Code vertraut zu machen. Im Gegensatz zu herkömmlichen Sprachmodellen haben die heute gängigen LLMs wie Llama2 und GPT4 nicht nur ihre Größe deutlich verbessert, sondern sie haben auch ein Code-Korpus-Training durchlaufen, das vom typischen Korpus natürlicher Sprache unabhängig ist. Code verfügt über eine standardisierte Syntax, logische Konsistenz, Abstraktion und Modularität und kann übergeordnete Ziele in ausführbare Schritte umwandeln, was ihn zu einem idealen Medium für die Verbindung von Menschen und Computern macht. Wie in Abbildung 2 dargestellt, haben die Forscher in dieser Übersicht relevante Arbeiten zusammengestellt und die verschiedenen Vorteile der Integration von Code in LLM-Trainingsdaten im Detail analysiert. Konkret haben Forscher beobachtet, dass die einzigartigen Eigenschaften von Code helfen: 1. Verbessern Sie die Code-Schreibfähigkeiten, Argumentationsfähigkeiten und strukturierten Informationsverarbeitungsfähigkeiten von LLMs, sodass sie auf komplexere natürliche Zwecke angewendet werden können Sprachaufgaben; 2. Leiten Sie LLMs an, um strukturierte und präzise Zwischenschritte zu generieren, die durch Funktionsaufrufe mit der Kompilierungs- und Ausführungsumgebung verbunden werden können.
Darüber hinaus haben die Forscher auch eingehend beobachtet, wie die durch den Code vorgegebenen Optimierungselemente dieser LLMs sie als Entscheidungszentrum des intelligenten Agenten stärken können, indem sie Anweisungen verstehen, Ziele zerlegen, Aktionen planen und ausführen usw Verbesserung der Serienfähigkeiten.
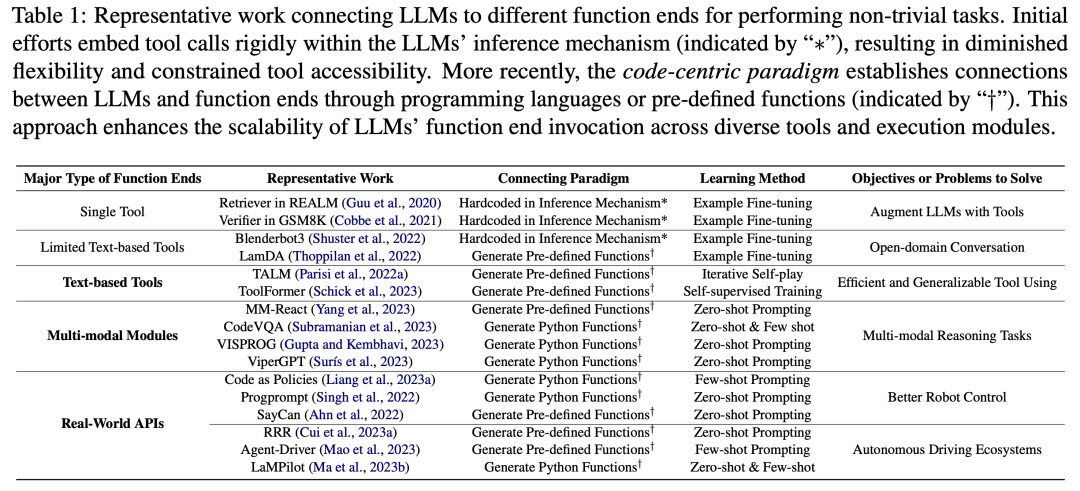
Wie in Abbildung 3 gezeigt, stellten die Forscher im ersten Teil fest, dass das Vortraining von LLMs auf Code den Aufgabenbereich von LLMs über die natürliche Sprache hinaus erweitert hat. Diese Modelle können eine Vielzahl von Anwendungen unterstützen, darunter die Codegenerierung für mathematische Theorien, allgemeine Programmieraufgaben und den Datenabruf. Der Code muss eine logisch kohärente, geordnete Abfolge von Schritten erzeugen, die für eine effektive Ausführung unerlässlich ist. Darüber hinaus ermöglicht die Ausführbarkeit jedes Schritts im Code eine schrittweise Überprüfung der Logik. Die Nutzung und Einbettung dieser Codeattribute im Vortraining verbessert die Chain of Thought (CoT)-Leistung von LLMs in vielen traditionellen Downstream-Aufgaben in natürlicher Sprache und bestätigt ihre Verbesserung der Fähigkeiten zum komplexen Denken. Gleichzeitig erbringen codeLLMs durch das implizite Erlernen des strukturierten Formats von Code eine bessere Leistung bei Aufgaben des strukturierten Denkens mit gesundem Menschenverstand, beispielsweise im Zusammenhang mit Markup-Sprachen, HTML und Diagrammverständnis. 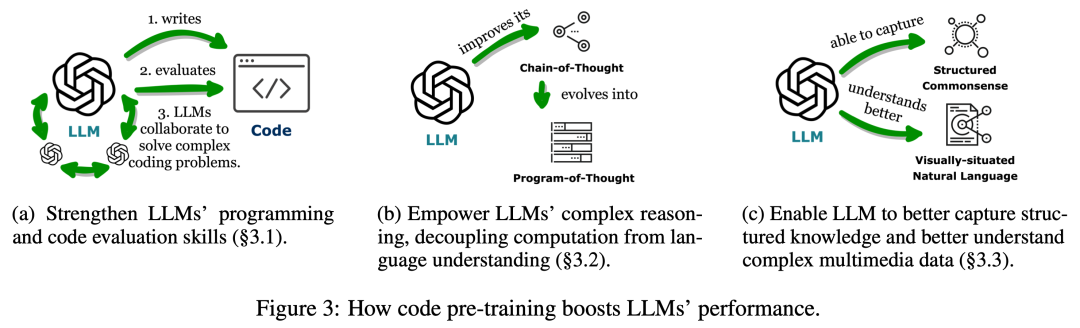 Wie in Abbildung 4 dargestellt, hilft die Verbindung von LLMs mit anderen funktionalen Enden (d. h. die Erweiterung der LLM-Funktionen durch externe Tools und Ausführungsmodule) dabei, dass LLMs Aufgaben genauer und zuverlässiger ausführen. Im zweiten Teil beobachteten die Forscher, wie in Tabelle 1 dargestellt, einen allgemeinen Trend: LLMs stellen Verbindungen mit anderen funktionalen Endpunkten her, indem sie Programmiersprachen generieren oder vordefinierte Funktionen nutzen. Dieses „codezentrierte Paradigma“ unterscheidet sich vom starren Ansatz der strikten Hardcodierung von Toolaufrufen im Inferenzmechanismus von LLMs, der es LLMs ermöglicht, dynamisch Token zu generieren, die Ausführungsmodule aufrufen, mit einstellbaren Parametern. Dieses Paradigma bietet LLMs eine einfache und klare Möglichkeit, mit anderen funktionalen Enden zu interagieren und so die Flexibilität und Skalierbarkeit ihrer Anwendungen zu verbessern. Noch wichtiger ist, dass es LLMs auch die Interaktion mit zahlreichen funktionalen Endpunkten ermöglicht, die mehrere Modalitäten und Domänen abdecken. Durch die Erweiterung der Anzahl und Vielfalt der für LLMs zugänglichen Funktionsterminals sind LLMs in der Lage, komplexere Aufgaben zu bewältigen. Wie in Abbildung 5 dargestellt, kann durch die Einbettung von LLMs in die Codeausführungsumgebung ein automatisiertes Feedback und eine unabhängige Modellverbesserung erreicht werden. LLMs leisten mehr als ihre Trainingsparameter, was teilweise auf ihre Fähigkeit zurückzuführen ist, auf Feedback einzugehen. Allerdings muss das Feedback sorgfältig ausgewählt werden, da verrauschte Cue-Eingaben die Leistung von LLMs bei nachgelagerten Aufgaben beeinträchtigen können. Da zudem Personalressourcen teuer sind, muss Feedback automatisch gesammelt und gleichzeitig die Authentizität gewahrt bleiben. Im dritten Teil stellten die Forscher fest, dass die Einbettung von LLMs in die Codeausführungsumgebung Feedback liefern kann, das alle diese Kriterien erfüllt.
Wie in Abbildung 4 dargestellt, hilft die Verbindung von LLMs mit anderen funktionalen Enden (d. h. die Erweiterung der LLM-Funktionen durch externe Tools und Ausführungsmodule) dabei, dass LLMs Aufgaben genauer und zuverlässiger ausführen. Im zweiten Teil beobachteten die Forscher, wie in Tabelle 1 dargestellt, einen allgemeinen Trend: LLMs stellen Verbindungen mit anderen funktionalen Endpunkten her, indem sie Programmiersprachen generieren oder vordefinierte Funktionen nutzen. Dieses „codezentrierte Paradigma“ unterscheidet sich vom starren Ansatz der strikten Hardcodierung von Toolaufrufen im Inferenzmechanismus von LLMs, der es LLMs ermöglicht, dynamisch Token zu generieren, die Ausführungsmodule aufrufen, mit einstellbaren Parametern. Dieses Paradigma bietet LLMs eine einfache und klare Möglichkeit, mit anderen funktionalen Enden zu interagieren und so die Flexibilität und Skalierbarkeit ihrer Anwendungen zu verbessern. Noch wichtiger ist, dass es LLMs auch die Interaktion mit zahlreichen funktionalen Endpunkten ermöglicht, die mehrere Modalitäten und Domänen abdecken. Durch die Erweiterung der Anzahl und Vielfalt der für LLMs zugänglichen Funktionsterminals sind LLMs in der Lage, komplexere Aufgaben zu bewältigen. Wie in Abbildung 5 dargestellt, kann durch die Einbettung von LLMs in die Codeausführungsumgebung ein automatisiertes Feedback und eine unabhängige Modellverbesserung erreicht werden. LLMs leisten mehr als ihre Trainingsparameter, was teilweise auf ihre Fähigkeit zurückzuführen ist, auf Feedback einzugehen. Allerdings muss das Feedback sorgfältig ausgewählt werden, da verrauschte Cue-Eingaben die Leistung von LLMs bei nachgelagerten Aufgaben beeinträchtigen können. Da zudem Personalressourcen teuer sind, muss Feedback automatisch gesammelt und gleichzeitig die Authentizität gewahrt bleiben. Im dritten Teil stellten die Forscher fest, dass die Einbettung von LLMs in die Codeausführungsumgebung Feedback liefern kann, das alle diese Kriterien erfüllt. 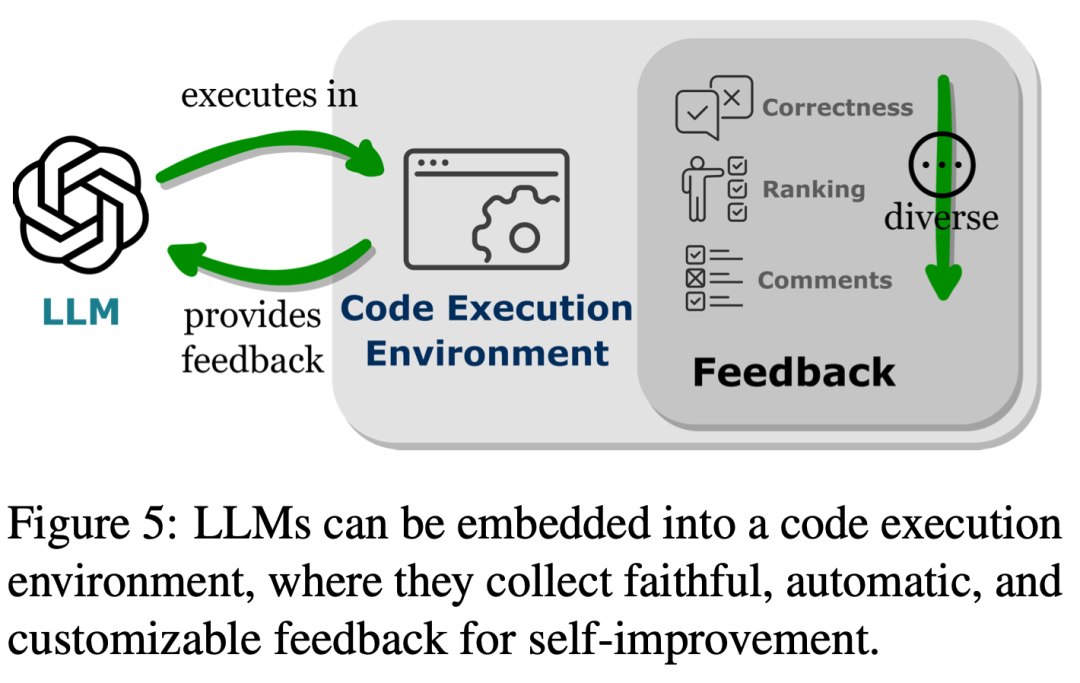
Da die Codeausführung deterministisch ist, kann das Erhalten von Feedback aus den Ergebnissen der Codeausführung die von LLM ausgeführten Aufgaben direkt und getreu widerspiegeln. Darüber hinaus bieten Code-Interpreter LLMs die Möglichkeit, internes Feedback automatisch abzufragen, sodass keine teuren menschlichen Anmerkungen erforderlich sind, wenn LLMs zum Debuggen oder Optimieren fehlerhaften Codes eingesetzt werden. Die Code-Kompilierungs- und Ausführungsumgebung ermöglicht es LLMs auch, vielfältige und umfassende externe Feedback-Formulare zu integrieren, wie z. B. die einfache Generierung binärer korrekter und Fehlerauswertungen, etwas komplexere Erklärungen der Ausführungsergebnisse in natürlicher Sprache und verschiedene Rankings mit Feedback-Methoden Machen Sie die Methoden zur Leistungsverbesserung hochgradig anpassbar. Durch die Analyse der verschiedenen Möglichkeiten, wie die Integration von Code-Trainingsdaten die Fähigkeiten von LLMs verbessert, stellten die Forscher außerdem fest, dass die Vorteile von Code-fähigen LLMs im wichtigsten LLM-Anwendungsfeld der Entwicklung intelligenter Agenten besonders offensichtlich sind. Abbildung 6 zeigt den Standard-Workflow eines intelligenten Assistenten. Die Forscher stellten fest, dass sich die durch das Code-Training in LLMs erzielten Verbesserungen auch auf die tatsächlichen Schritte auswirkten, die sie als intelligente Assistenten ausführten. Diese Schritte umfassen: (1) Verbesserung der Entscheidungsfähigkeiten von IA in Bezug auf Kontextbewusstsein und Planung, (2) Optimierung der Strategieausführung durch Implementierung von Aktionen in modulare Aktionsprimitive und effizientes Organisationsgedächtnis und (3) Optimierung der Leistung durch Feedback, das automatisch aus der Code-Ausführungsumgebung abgeleitet wird. Zusammenfassend analysieren und klären Forscher in diesem Review, wie Code LLMs leistungsstarke Funktionen verleiht und wie Code LLMs dabei unterstützt, als Entscheidungszentren für intelligente Agenten zu fungieren. Durch eine umfassende Literaturrecherche stellten Forscher fest, dass LLMs nach dem Code-Training ihre Programmierfähigkeiten und Denkfähigkeiten verbesserten, die Fähigkeit erlangten, flexible Verbindungen mit mehreren funktionalen Enden über Modi und Domänen hinweg zu implementieren, und die Fähigkeit zur Interaktion stärkten Das in die Code-Ausführungsumgebung integrierte Evaluierungsmodul sorgt für eine automatische Selbstverbesserung. Darüber hinaus unterstützen die durch Code-Training verbesserten Fähigkeiten von LLMs ihre Leistung als intelligente Agenten in nachgelagerten Anwendungen, was sich in spezifischen Betriebsschritten wie Entscheidungsfindung, Ausführung und Selbstverbesserung widerspiegelt. Zusätzlich zur Überprüfung früherer Forschungsergebnisse schlugen die Forscher auch mehrere Herausforderungen auf diesem Gebiet als Leitelemente für mögliche zukünftige Richtungen vor. Weitere Informationen finden Sie im Originalartikel! Das obige ist der detaillierte Inhalt vonSetzen Sie hervorragende Programmierressourcen frei, riesige Modelle und Agenten werden mächtigere Kräfte auslösen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!




















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



