


Video Scene Graph Generation (VidSGG) zielt darauf ab, Objekte in visuellen Szenen zu identifizieren und visuelle Beziehungen zwischen ihnen abzuleiten.
Diese Aufgabe erfordert nicht nur ein umfassendes Verständnis jedes über die Szene verstreuten Objekts, sondern auch eine eingehende Untersuchung ihrer Bewegung und Interaktion im Laufe der Zeit.
Kürzlich veröffentlichten Forscher der Sun Yat-sen-Universität einen Artikel in der Top-Zeitschrift für künstliche Intelligenz IEEE T-IP. Sie untersuchten verwandte Aufgaben und stellten fest, dass jedes Paar von Objektkombinationen und ihre Beziehung in jedem Raum vorhanden sind -Vorkommenskorrelation innerhalb von Bildern und zeitliche Konsistenz/Übersetzungskorrelation zwischen verschiedenen Bildern.

Link zum Papier: https://arxiv.org/abs/2309.13237
Basierend auf diesem Vorwissen schlugen die Forscher einen Transformer (STKET) vor, der auf der Einbettung von raumzeitlichem Wissen basiert, um das frühere raumzeitliche Wissen zu integrieren Das Wissen wird in einen Multi-Head-Cross-Attention-Mechanismus integriert, um repräsentativere visuelle Beziehungsdarstellungen zu lernen.
Konkret werden räumliche Koexistenz und zeitliche Transformationskorrelationen zunächst statistisch erlernt. Anschließend wird eine räumlich-zeitliche Wissenseinbettungsschicht entwickelt, um die Interaktion zwischen visueller Darstellung und Wissen vollständig zu untersuchen und räumliche und zeitliche Wissenseinbettungen zu erzeugen Darstellung; schließlich aggregieren die Autoren diese Merkmale, um die endgültigen semantischen Bezeichnungen und ihre visuellen Beziehungen vorherzusagen.
Eine große Anzahl von Experimenten zeigt, dass das in diesem Artikel vorgeschlagene Framework deutlich besser ist als die aktuellen Konkurrenzalgorithmen. Derzeit wurde das Papier angenommen.
Mit der rasanten Entwicklung des Bereichs des Szenenverständnisses haben viele Forscher begonnen, verschiedene Frameworks zu verwenden, um die Aufgabe der Szenendiagrammgenerierung (SGG) zu lösen, und haben gute Fortschritte gemacht.
Allerdings berücksichtigen diese Methoden oft nur ein einzelnes Bild und ignorieren die große Menge an Kontextinformationen, die in der Zeitreihe vorhanden sind, was dazu führt, dass die meisten vorhandenen Algorithmen zur Szenendiagrammgenerierung den in einem bestimmten Video enthaltenen Inhalt nicht genau identifizieren können visuelle Beziehung.
Daher engagieren sich viele Forscher für die Entwicklung von Video Scene Graph Generation (VidSGG)-Algorithmen, um dieses Problem zu lösen.
Aktuelle Arbeiten konzentrieren sich hauptsächlich auf die Aggregation visueller Informationen auf Objektebene aus räumlichen und zeitlichen Perspektiven, um entsprechende visuelle Beziehungsdarstellungen zu lernen.
Aufgrund der großen Varianz im visuellen Erscheinungsbild verschiedener Objekte und interaktiver Aktionen und der erheblichen Long-Tail-Verteilung visueller Beziehungen, die durch die Videosammlung verursacht wird, kann die alleinige Verwendung visueller Informationen jedoch leicht dazu führen, dass das Modell falsche visuelle Vorhersagen trifft Beziehungen.
Als Reaktion auf die oben genannten Probleme haben Forscher die folgenden zwei Aspekte der Arbeit durchgeführt:
Erstens wird vorgeschlagen, das in Trainingsbeispielen enthaltene vorherige räumlich-zeitliche Wissen zu ermitteln, um den Bereich der Erzeugung von Videoszenengraphen voranzutreiben. Zu den räumlich-zeitlichen Vorkenntnissen gehören unter anderem:
1) Räumliche Kookkurrenzkorrelation: Die Beziehung zwischen bestimmten Objektkategorien tendiert zu spezifischen Interaktionen.
2) Zeitliche Konsistenz/Übergangskorrelation: Ein bestimmtes Beziehungspaar neigt dazu, über aufeinanderfolgende Videoclips hinweg konsistent zu sein, oder es besteht eine hohe Wahrscheinlichkeit, dass es in eine andere spezifische Beziehung übergeht.
Zweitens wird ein neuartiges Transformer-Framework (Spatial-Temporal Knowledge-Embedded Transformer, STKET) vorgeschlagen, das auf der Einbettung von räumlich-zeitlichem Wissen basiert.
Dieses Framework integriert vorheriges raumzeitliches Wissen in den Mehrkopf-Kreuzaufmerksamkeitsmechanismus, um repräsentativere visuelle Beziehungsdarstellungen zu lernen. Den Vergleichsergebnissen des Test-Benchmarks zufolge kann festgestellt werden, dass das von den Forschern vorgeschlagene STKET-Framework die bisherigen Methoden auf dem neuesten Stand der Technik übertrifft.

Abbildung 1: Aufgrund des variablen visuellen Erscheinungsbilds und der Long-Tail-Verteilung visueller Beziehungen ist die Generierung von Videoszenendiagrammen voller Herausforderungen.
Unter diesen manifestiert sich die räumliche Korrelation des gemeinsamen Vorkommens insbesondere darin, dass bei der Kombination eines bestimmten Objekts seine visuelle Beziehungsverteilung stark verzerrt ist (z. B. die Verteilung der visuellen Beziehung zwischen „Person“ und „Tasse“) offensichtlich anders als „Hund“ und „Hund“) Die Verteilung zwischen „Spielzeug“) und die Zeitübertragungskorrelation manifestieren sich insbesondere darin, dass sich die Übergangswahrscheinlichkeit jeder visuellen Beziehung erheblich ändert, wenn die visuelle Beziehung im vorherigen Moment gegeben ist (z. B Wenn beispielsweise bekannt ist, dass die visuelle Beziehung im vorherigen Moment „essen“ ist, ist die Wahrscheinlichkeit, dass die visuelle Beziehung im nächsten Moment auf „schreiben“ übertragen wird, stark verringert.
Wie in Abbildung 2 gezeigt, kann der Vorhersageraum erheblich reduziert werden, nachdem Sie die gegebene Objektkombination oder die vorherige visuelle Beziehung intuitiv erfühlen können.
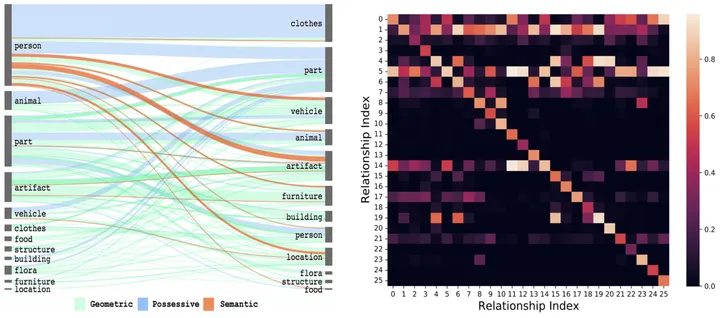
Abbildung 2: Räumliche Koauftrittswahrscheinlichkeit [3] und zeitliche Übergangswahrscheinlichkeit der visuellen Beziehung
Insbesondere für die Kombination des i-ten Objekts und des j-ten Objekts und sein vorheriger Moment Für den x-ten Beziehungstyp erhalten Sie zunächst durch Statistik die entsprechende räumliche Wahrscheinlichkeitsmatrix E^{i,j} und die Zeitübergangswahrscheinlichkeitsmatrix Ex^{i,j}.
Geben Sie es dann in die vollständig verbundene Schicht ein, um die entsprechende Merkmalsdarstellung zu erhalten, und stellen Sie mithilfe der entsprechenden Zielfunktion sicher, dass die vom Modell gelernte Wissensdarstellung das entsprechende vorherige räumlich-zeitliche Wissen enthält. Abbildung 3: Der Prozess des Erlernens der räumlichen (a) und zeitlichen (b) Wissensrepräsentation . Zeitliches Wissen hingegen umfasst die Reihenfolge, Dauer und Intervalle zwischen Handlungen.
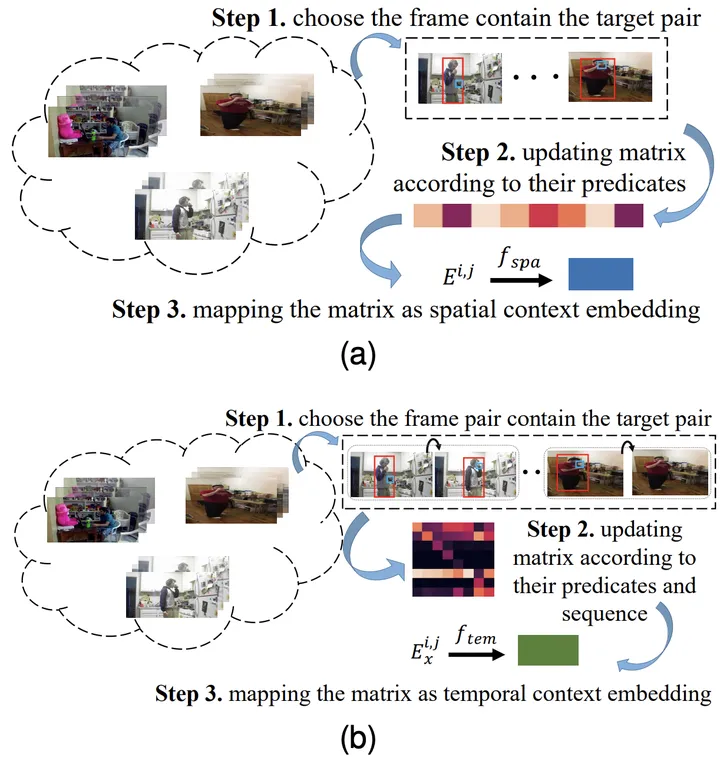 Angesichts ihrer einzigartigen Eigenschaften kann eine individuelle Behandlung eine spezielle Modellierung ermöglichen, um die inhärenten Muster genauer zu erfassen.
Angesichts ihrer einzigartigen Eigenschaften kann eine individuelle Behandlung eine spezielle Modellierung ermöglichen, um die inhärenten Muster genauer zu erfassen.
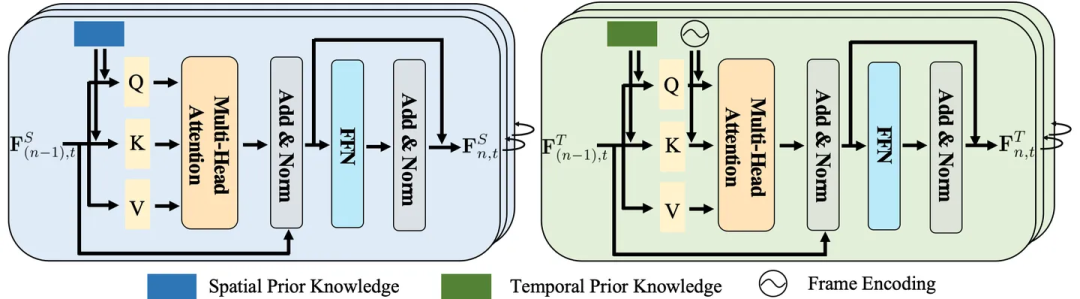
Daher haben die Forscher eine Schicht zur Einbettung von raumzeitlichem Wissen entworfen, um die Interaktion zwischen visueller Darstellung und raumzeitlichem Wissen gründlich zu untersuchen.
Abbildung 4: Räumliche (links) und zeitliche (rechts) Wissenseinbettungsschicht
Räumlich-zeitliches Aggregationsmodul
Wie bereits erwähnt, untersucht die räumliche Wissenseinbettungsschicht die räumliche Kohärenz innerhalb jedes Bildes Die Einbettungsschicht für zeitliches Wissen untersucht die zeitliche Übertragungskorrelation zwischen verschiedenen Bildern und erforscht so vollständig die Interaktion zwischen visueller Darstellung und räumlich-zeitlichem Wissen.
 Dennoch ignorieren diese beiden Schichten langfristige Kontextinformationen, was hilfreich ist, um die sich am dynamischsten ändernden visuellen Beziehungen zu identifizieren.
Dennoch ignorieren diese beiden Schichten langfristige Kontextinformationen, was hilfreich ist, um die sich am dynamischsten ändernden visuellen Beziehungen zu identifizieren.
Zu diesem Zweck haben die Forscher außerdem ein STA-Modul (Spatiotemporal Aggregation) entwickelt, um diese Darstellungen jedes Objektpaars zu aggregieren und die endgültigen semantischen Bezeichnungen und ihre Beziehungen vorherzusagen. Als Eingabe werden räumliche und zeitlich eingebettete Beziehungsdarstellungen derselben Subjekt-Objekt-Paare in unterschiedlichen Frames verwendet.
Konkret verketten die Forscher diese Darstellungen derselben Objektpaare, um kontextbezogene Darstellungen zu generieren.
Um dann die gleichen Subjekt-Objekt-Paare in verschiedenen Frames zu finden, werden die vorhergesagten Objektbezeichnungen und die IoU (d. h. Schnittmenge über Vereinigung) übernommen, um mit den gleichen in den Frames erkannten Subjekt-Objekt-Paaren übereinzustimmen.
Abschließend wird unter Berücksichtigung der Tatsache, dass Beziehungen in Frames in verschiedenen Stapeln unterschiedliche Darstellungen haben, die früheste Darstellung im Schiebefenster ausgewählt.
Experimentelle Ergebnisse
Um die Leistung des vorgeschlagenen Frameworks umfassend zu bewerten, wählten die Forscher zusätzlich zum Vergleich vorhandener Methoden zur Generierung von Videoszenengraphen (STTran, TPI, APT) auch fortschrittliche Methoden zur Generierung von Bildszenengraphen aus (KERN, VCTREE, ReIDN, GPS-Net) zum Vergleich.
Um einen fairen Vergleich zu gewährleisten, erreicht die Methode zur Generierung von Bildszenengraphen das Ziel, einen entsprechenden Szenengraphen für ein bestimmtes Video zu generieren, indem jedes Bildbild identifiziert wird.
Abbildung 6: Experimentelle Ergebnisse unter Verwendung des Mittelwerts Recall als Bewertungsindex für den Action Genome-Datensatz
Das obige ist der detaillierte Inhalt vonDas neue raumzeitliche Wissenseinbettungs-Framework der Sun Yat-sen-Universität treibt die neuesten Fortschritte bei der Generierung von Videoszenengraphen voran, veröffentlicht in TIP '24. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So binden Sie Daten in einer Dropdown-Liste
So binden Sie Daten in einer Dropdown-Liste
 Was ist der Unterschied zwischen der Wertübergabe und der Referenzübergabe in Java?
Was ist der Unterschied zwischen der Wertübergabe und der Referenzübergabe in Java?
 Was tun, wenn Postscript nicht geparst werden kann?
Was tun, wenn Postscript nicht geparst werden kann?
 Was tun bei einem IP-Konflikt?
Was tun bei einem IP-Konflikt?
 Die Rolle des Grafikkartentreibers
Die Rolle des Grafikkartentreibers
 So löschen Sie eine Datei unter Linux
So löschen Sie eine Datei unter Linux
 So optimieren Sie die Tomcat-Leistung
So optimieren Sie die Tomcat-Leistung
 So verwenden Sie PHP Sleep
So verwenden Sie PHP Sleep








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



