


| Einführung | Das Datenbankverwaltungssystem (DBMS) ist der wichtigste Teil jedes datenintensiven Anwendungssystems. Sie können große Datenmengen und komplexe Arbeitslasten bewältigen. Sie sind jedoch schwer zu verwalten, da sie über Hunderte oder Tausende von Konfigurationsknöpfen verfügen, die Faktoren wie die für das Caching verwendete Speichermenge und die Häufigkeit, mit der Daten auf das Speichergerät geschrieben werden, steuern. Organisationen beauftragen häufig Experten mit der Feinabstimmung ihrer Kampagnen, doch für viele Unternehmen sind Experten unerschwinglich teuer. |
Dieser Artikel wurde von drei Gästen der Carnegie Mellon University gemeinsam verfasst: Dana Van Aken, Andy Pavlo und Geoff Gordon. Dieses Projekt zeigt, wie akademische Forscher das AWS Cloud Credits for Research-Programm (https://aws.amazon.com/research-credits/) nutzen können, um ihre wissenschaftlichen Durchbrüche zu unterstützen.
OtterTune ist ein neues Tool, das von Studenten und Forschern der Carnegie Mellon University Database Group (http://db.cs.cmu.edu/projects/autotune/) entwickelt wurde und die Konfiguration der DBMS-Schaltfläche automatisiert, um die entsprechenden Einstellungen zu finden. Das Ziel besteht darin, die Bereitstellung eines DBMS für jeden einfacher zu machen, auch für diejenigen, die keine Erfahrung in der Datenbankverwaltung haben.
OtterTune unterscheidet sich von anderen DBMS-Konfigurationstools, da es die Erkenntnisse aus der Optimierung zuvor bereitgestellter DBMS vollständig nutzt, um neu bereitgestellte DBMS zu optimieren. Dies reduziert den Zeit- und Ressourcenaufwand für die Optimierung eines neu bereitgestellten DBMS erheblich. Zu diesem Zweck unterhält OtterTune eine Datenbank mit Tuning-Daten, die aus früheren Tuning-Sitzungen gesammelt wurden. Mithilfe dieser Daten werden Modelle für maschinelles Lernen erstellt, die Informationen darüber erfassen, wie das DBMS auf verschiedene Konfigurationen reagiert. OtterTune verwendet diese Modelle, um Benutzer beim Ausprobieren neuer Anwendungen anzuleiten und Einstellungen vorzuschlagen, die bestimmte Ziele verbessern, wie z. B. die Reduzierung der Latenz oder die Erhöhung des Durchsatzes.
In diesem Artikel untersuchen wir jede Komponente der Machine-Learning-Pipeline von OtterTune und zeigen, wie sie miteinander in Beziehung stehen, um die Konfiguration Ihres DBMS zu optimieren. Anschließend haben wir die Leistung von OtterTune auf MySQL und Postgres bewertet, indem wir die Leistung seiner optimalen Konfiguration mit Konfigurationen verglichen haben, die von Datenbankadministratoren (DBAs) und anderen automatisierten Tuning-Tools ausgewählt wurden.
OtterTune ist ein Open-Source-Tool, das von Studenten und Forschern der Datenbankgruppe der Carnegie Mellon University entwickelt wurde. Der gesamte Code wird auf GitHub (https://github.com/cmu-db/ottertune) platziert und unter der Apache-Lizenz 2.0 veröffentlicht.
Wie es funktioniertDas Bild unten zeigt die Komponenten und den Arbeitsablauf von OtterTune.
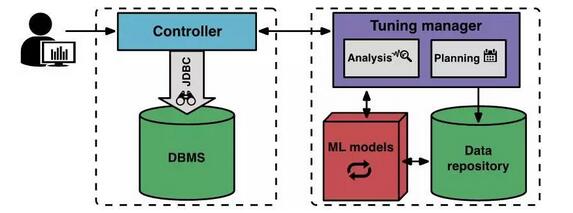
Zu Beginn einer neuen Tuning-Sitzung teilt der Benutzer OtterTune mit, für welches spezifische Ziel optimiert werden soll (z. B. Latenz oder Durchsatz). Der Client-Controller stellt eine Verbindung zum Ziel-DBMS her und erfasst den Amazon EC2-Instance-Typ und das aktuelle Ziel.
Der Controller startet dann den ersten Beobachtungszeitraum, in dem er das DBMS beobachtet und bestimmte Ziele protokolliert. Nach Ablauf des Beobachtungszeitraums sammelt der Controller interne Metriken vom DBMS, z. B. die MySQL-Anzahl der von der Festplatte gelesenen und auf die Festplatte geschriebenen Seiten. Der Controller gibt sowohl spezifische Ziele als auch interne Kennzahlen an den Tuning-Manager zurück.
Nachdem der Tuning-Manager von OtterTune die Messwerte erhalten hat, speichert er sie im Repository. OtterTune verwendet die Ergebnisse, um die nächste Konfiguration zu berechnen, die der Controller auf dem Ziel-DBMS installiert werden sollte. Der Tuning-Manager gibt diese Konfiguration an den Controller zurück und schätzt die erwarteten Verbesserungen durch tatsächliche Läufe ab. Der Benutzer kann entscheiden, die Tuning-Sitzung fortzusetzen oder zu beenden.
AnleitungOtterTune unterhält für jede unterstützte DBMS-Version eine schwarze Liste mit Schaltflächen. Die Blacklist enthält Schaltflächen, die nicht optimiert werden müssen (z. B. der Pfadname der DBMS-Speicherdatei) oder Schaltflächen, die schwerwiegende oder versteckte Folgen haben können (z. B. können dazu führen, dass das DBMS Daten verliert). Zu Beginn jeder Tuning-Sitzung stellt OtterTune den Benutzern eine Blacklist zur Verfügung, sodass sie alle weiteren Schaltflächen hinzufügen können, mit denen OtterTune das Tuning vermeiden soll.
OtterTune geht von bestimmten Annahmen aus, die seinen Nutzen für einige Benutzer einschränken können. Beispielsweise wird davon ausgegangen, dass der Benutzer über Administratorrechte verfügt, sodass der Controller die DBMS-Konfiguration ändern kann. Wenn der Benutzer nicht über Administratorrechte verfügt, kann er für OtterTune-Tuning-Experimente eine zweite Kopie der Datenbank auf anderer Hardware bereitstellen. Dies erfordert, dass Benutzer Workload-Traces wiedergeben oder Abfragen von einem DBMS der Produktionsqualität weiterleiten. Eine vollständige Diskussion der Annahmen und Einschränkungen finden Sie in unserem Dokument (http://db.cs.cmu.edu/papers/2017/tuning-sigmod2017.pdf).
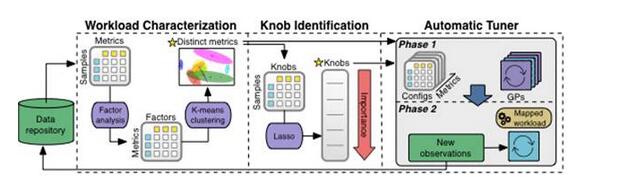
Pipeline für maschinelles LernenDas Bild unten zeigt, wie Daten verarbeitet werden, während sie die Pipeline für maschinelles Lernen von OtterTune durchlaufen. Alle Beobachtungen werden in der Datenbank von OtterTune gespeichert.
OtterTune übermittelt die Beobachtungsergebnisse zunächst an die Komponente Workload Characterization. Diese Komponente identifiziert einen kleinen Satz von DBMS-Metriken, die Leistungsänderungen und einzigartige Merkmale verschiedener Arbeitslasten am genauesten erfassen.
Als nächstes generiert die Knob-Identification-Komponente eine Schaltflächen-Sortierliste, in der die Schaltflächen aufgelistet sind, die den größten Einfluss auf die Leistung des DBMS haben. OtterTune leitet dann alle diese Informationen an den Automatic Tuner weiter. Diese Komponente ordnet die Arbeitslast des Ziel-DBMS der ähnlichsten Arbeitslast im Datenrepository zu und verwendet die Arbeitslastdaten wieder, um eine geeignetere Konfiguration zu generieren.
Lassen Sie uns nun in jede Komponente der Machine-Learning-Pipeline eintauchen.
Workload-Charakterisierung: OtterTune verwendet die internen Laufzeitmetriken des DBMS, um die Verhaltensmerkmale der Workload zu beschreiben. Diese Metriken stellen die Arbeitslast genau dar, da sie viele Aspekte des Laufzeitverhaltens erfassen. Viele Metriken sind jedoch redundant: Einige sind dieselben Metriken, die in unterschiedlichen Einheiten aufgezeichnet werden, und andere stellen unabhängige Teile des DBMS dar, die stark numerisch korrelieren. Die Optimierung redundanter Metriken ist wichtig, da dadurch die Komplexität der maschinellen Lernmodelle, die sie verwenden, verringert wird. Zu diesem Zweck unterteilen wir DBMS-Metriken basierend auf Korrelationsmustern in Cluster. Anschließend wählen wir aus jedem Cluster eine repräsentative Metrik aus, insbesondere diejenige, die dem Clusterzentrum am nächsten liegt. Nachfolgende Komponenten in der Pipeline für maschinelles Lernen verwenden diese Metriken.
Knopfidentifikation: Ein DBMS verfügt möglicherweise über Hunderte von Schaltflächen, aber nur eine kleine Anzahl von Schaltflächen beeinträchtigt die Leistung des DBMS. OtterTune verwendet eine beliebte Funktionsauswahltechnik namens Lasso, um zu entscheiden, welche Tasten die Gesamtleistung Ihres Systems erheblich beeinflussen. Durch die Anwendung dieser Technik auf Daten in einer Datenbank kann OtterTune die Bedeutung der Schaltflächenreihenfolge im DBMS ermitteln.
OtterTune muss dann entscheiden, wie viele Tasten in der vorgeschlagenen Konfiguration verwendet werden sollen. Die Verwendung zu vieler Schaltflächen verlängert die Optimierungszeit von OtterTune erheblich. Die Verwendung zu weniger Tasten verhindert, dass OtterTune die optimale Konfiguration findet. Um diesen Prozess zu automatisieren, verwendet OtterTune einen inkrementellen Ansatz. Dadurch wird die Anzahl der in einer Tuning-Sitzung verwendeten Tasten schrittweise erhöht. Dieser Ansatz ermöglicht es OtterTune, Konfigurationen für einen kleinen Satz der wichtigsten Tasten zu erkunden und zu optimieren und dann den Umfang zu erweitern, um zusätzliche Tasten zu berücksichtigen.
Automatischer Tuner: Die Komponente „Automatisches Tuning“ bestimmt, welche Konfiguration OtterTune empfehlen soll, indem sie nach jedem Beobachtungszeitraum eine zweistufige Analyse durchführt.
Zuerst identifiziert das System die Arbeitslast aus einer vorherigen Optimierungssitzung, die die Ziel-DBMS-Arbeitslast am besten repräsentiert, indem es Leistungsdaten anhand der in der Komponente „Arbeitslastcharakterisierung“ identifizierten Metriken verwendet. Es vergleicht die Sitzungsmetriken mit Metriken früherer Arbeitslasten, um zu sehen, welche auf unterschiedliche Tasteneinstellungen ähnlich reagieren.
Dann wählt OtterTune eine andere Tastenkonfiguration aus, um es auszuprobieren. Es passt statistische Modelle an die gesammelten Daten sowie an Daten der ähnlichsten Workloads im Repository an. Mit diesem Modell kann OtterTune vorhersagen, wie das DBMS bei jeder möglichen Konfiguration funktionieren wird. OtterTune optimiert die nächste Konfiguration, um ein Gleichgewicht zwischen Erkundung (Sammeln von Informationen zur Verbesserung des Modells) und Ausnutzung (bestmögliche Leistung bei einer bestimmten Metrik) zu finden.
ErreichtOtterTune ist in Python geschrieben.
Was die Workload-Charakterisierung und Knob-Identifizierung betrifft, ist die Laufzeitleistung nicht das Hauptproblem, über das man sich Sorgen machen muss. Deshalb haben wir scikit-learn verwendet, um den entsprechenden Algorithmus für maschinelles Lernen zu implementieren. Diese Algorithmen laufen im Hintergrund und integrieren neue Daten, sobald sie in der Datenbank von OtterTune verfügbar sind.
Was den Automatic Tuner betrifft, befindet sich der Algorithmus für maschinelles Lernen auf dem kritischen Weg. Sie werden nach jedem Beobachtungszeitraum ausgeführt und integrieren neue Daten, sodass OtterTune eine Tastenkonfiguration auswählen kann, die als nächstes ausprobiert werden soll. Da die Leistung eine Rolle spielt, haben wir diese Algorithmen mit TensorFlow implementiert.
Um Daten zu DBMS-Hardware, Tastenkonfigurationen und Laufzeitleistungsmetriken zu sammeln, haben wir den Controller von OtterTune in das Benchmarking-Framework OLTP-Bench integriert.
BewertungZur Bewertung haben wir die beste von OtterTune ausgewählte Konfiguration mit den folgenden Konfigurationen für die Leistung von MySQL und Postgres verglichen:
Wir haben alle Experimente auf Amazon EC2 Spot-Instances durchgeführt. Wir haben jeden Versuch auf zwei Instanzen durchgeführt: eine für den Controller von OtterTune und eine andere für das bereitgestellte Ziel-DBMS-System. Wir haben die Instanztypen m4.large bzw. m3.xlarge verwendet. Wir haben den Tuning-Manager und die Datendatenbank von OtterTune auf einem lokalen Server bereitgestellt, der mit 20 Kernen und 128 GB Speicher ausgestattet ist.
Wir haben den TPC-C-Workload verwendet, den Industriestandard zur Bewertung der Leistung von Online-Transaktionsverarbeitungssystemen (OLTP).
Wir haben Latenz und Durchsatz für jede Datenbank gemessen, die wir in unseren Experimenten verwendet haben: MySQL und Postgres. Die folgenden Abbildungen zeigen die Ergebnisse. Das erste Diagramm zeigt die Latenzzeit im 99. Perzentil, die die „Worst-Case“-Zeit darstellt, die für den Abschluss einer Transaktion benötigt wird. Das zweite Diagramm zeigt die Ergebnisse für den Durchsatz, gemessen als durchschnittliche Anzahl abgeschlossener Transaktionen pro Sekunde.
MySQL-Ergebnisse:
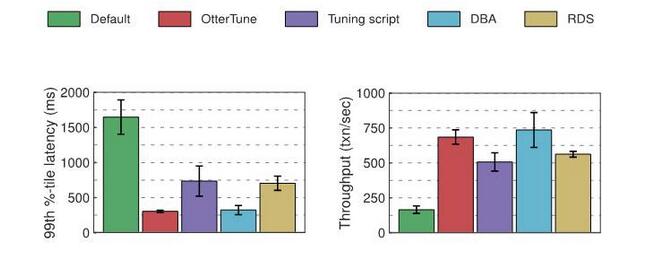
Wenn Sie die von OtterTune generierte optimale Konfiguration mit der vom Tuning-Skript und RDS generierten Konfiguration vergleichen, werden Sie feststellen, dass bei Verwendung der OtterTune-Konfiguration die Latenz von MySQL um etwa 60 % reduziert und der Durchsatz um 35 % erhöht wird. OtterTune erzeugt auch Konfigurationen mit Ergebnissen, die genauso gut sind wie die vom Datenbankadministrator gewählten.
Einige MySQL-Schaltflächen haben einen erheblichen Einfluss auf die Leistung von TPC-C-Workloads. Die von OtterTune und dem Datenbankadministrator generierten Konfigurationen bieten gute Einstellungen für jede dieser Schaltflächen. RDS schnitt etwas schlechter ab, da für eine Taste nicht optimale Einstellungen bereitgestellt wurden. Die Konfiguration des Tuning-Skripts schnitt am schlechtesten ab, da nur eine Schaltfläche geändert wurde.
Ergebnisse für Postgres:
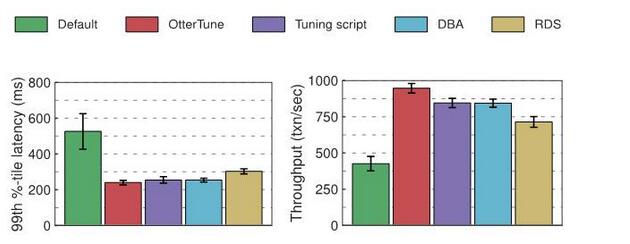
In Bezug auf die Latenz zeigen OtterTune, Tuning-Tools, Datenbankverwaltung und RDS-generierte Konfigurationen ähnliche Verbesserungen gegenüber den Standardeinstellungen von Postgres. Wir können dies wahrscheinlich auf den Overhead zurückführen, der für den Roundtrip zwischen dem OLTP-Bench-Client und dem DBMS über das Netzwerk erforderlich ist. Was den Durchsatz betrifft: Wenn Sie die von OtterTune empfohlene Konfiguration verwenden, ist die Leistung von Postgres etwa 12 % höher als die vom Datenbankadministrator und Optimierungsskript ausgewählte Konfiguration und etwa 32 % höher als die von RDS.
Ähnlich wie bei MySQL gibt es nur wenige Schaltflächen, die einen erheblichen Einfluss auf die Leistung von Postgres haben. OtterTune, Datenbankadministratoren, Optimierungsskripte und RDS-generierte Konfigurationen modifizieren alle diese Schaltflächen und die meisten bieten ziemlich gute Einstellungen.
FazitOtterTune automatisiert den Prozess der Suche nach den richtigen Einstellungen für die Konfigurationsschaltflächen eines DBMS. Um ein neu bereitgestelltes DBMS zu optimieren, verwendet es Trainingsdaten, die aus früheren Optimierungssitzungen gesammelt wurden. Da OtterTune nicht die Generierung anfänglicher Datensätze zum Trainieren von Modellen für maschinelles Lernen erfordert, wird die Abstimmungszeit erheblich verkürzt.
Was kommt als nächstes? Um der wachsenden Beliebtheit von DBaaS-Bereitstellungen Rechnung zu tragen, die keinen Fernzugriff auf das Hostsystem des DBMS haben, wird OtterTune bald in der Lage sein, die Hardwarefunktionen des Ziel-DMBS automatisch zu erkennen, ohne dass ein Fernzugriff erforderlich ist.
Weitere Informationen zu OtterTune finden Sie in unserem Dokument oder im Code auf GitHub. Bitte beachten Sie diese Website (http://ottertune.cs.cmu.edu/), wir werden in Kürze OtterTune starten, einen Online-Tuning-Dienst.
Über den Autor:
Dana Van Aken ist Doktorandin der Informatik an der Carnegie Mellon University und wird von Dr. Andrew Pavlo betreut.
Andy Pavlo ist Assistenzprofessor für Datenbankwissenschaft am Fachbereich Informatik der Carnegie Mellon University.
Geoff Gordon ist außerordentlicher Professor und stellvertretender Bildungsdirektor in der Abteilung für maschinelles Lernen an der Carnegie Mellon University.
Das obige ist der detaillierte Inhalt vonWird maschinelles Lernen die Betreiber von Datenbankverwaltungssystemen arbeitslos machen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



