


In Jin Yongs Kampfkunstromanen gibt es eine einzigartige Kampfkunstfähigkeit: Links- und Rechtskampf. Es war eine Kampfkunst, die von Zhou Botong geschaffen wurde, der mehr als zehn Jahre lang hart in einer Höhle auf der Pfirsichblüteninsel trainierte zu seinem eigenen Vergnügen zwischen der linken und der rechten Hand zu kämpfen. Diese Idee lässt sich nicht nur zum Üben von Kampfkünsten nutzen, sondern auch zum Trainieren von Machine-Learning-Modellen, wie etwa dem in den letzten Jahren in aller Munde befindlichen Generative Adversarial Network (GAN).
In der heutigen Ära der großen Modelle (LLM) haben Forscher den subtilen Einsatz der linken und rechten Interaktion entdeckt. Kürzlich schlug Gu Quanquans Team an der University of California in Los Angeles eine neue Methode namens SPIN (Self-Play Fine-Tuning) vor. Diese Methode kann die Fähigkeiten von LLM nur durch Selbstspiel ohne Verwendung zusätzlicher Feinabstimmungsdaten erheblich verbessern. Professor Gu Quanquan sagte: „Es ist besser, jemandem das Fischen beizubringen, als ihm das Fischen beizubringen: Durch Selbstspiel-Feinabstimmung (SPIN) können alle großen Modelle von schwach auf stark verbessert werden!“ Diese Forschung hat auch in sozialen Netzwerken für viele Diskussionen gesorgt. Professor Ethan Mollick von der Wharton School der University of Pennsylvania sagte beispielsweise: „Weitere Beweise zeigen, dass die KI nicht durch die Menge der von Menschen geschaffenen Dinge begrenzt sein wird.“ Für das Training verfügbare Inhalte. Dieses Papier zeigt einmal mehr, dass der Einsatz von KI mit erstellten Daten qualitativ hochwertigere Ergebnisse erzielen kann als die Verwendung nur von Menschen erstellter Daten Wir sind von dieser Methode begeistert und freuen uns auf ihre Weiterentwicklung in entsprechende Richtungen im Jahr 2024. Der Fortschritt lässt große Erwartungen erkennen. Professor Gu Quanquan sagte gegenüber Machine Heart: „Wenn Sie ein großes Modell über GPT-4 hinaus trainieren möchten, ist dies definitiv einen Versuch wert.“ /2401.01335.pdf.
Ein wichtiger Fortschritt von LLM ist der Ausrichtungsprozess nach dem Training, der dafür sorgen kann, dass sich das Modell besser anforderungsgemäß verhält, aber dieser Prozess basiert oft auf kostspieligen, von Menschen gekennzeichneten Daten. Zu den klassischen Ausrichtungsmethoden gehören Supervised Fine-Tuning (SFT) basierend auf menschlichen Demonstrationen und Reinforcement Learning basierend auf Human Preference Feedback (RLHF).
Und diese Ausrichtungsmethoden erfordern alle eine große Menge an vom Menschen gekennzeichneten Daten. Um den Ausrichtungsprozess zu rationalisieren, hoffen die Forscher daher, Feinabstimmungsmethoden zu entwickeln, die menschliche Daten effektiv nutzen.
Dies ist auch das Ziel dieser Forschung: neue Feinabstimmungsmethoden zu entwickeln, damit das feinabgestimmte Modell immer stärker werden kann, und dieser Feinabstimmungsprozess erfordert nicht die Verwendung von vom Menschen gekennzeichneten Daten außerhalb der Feinabstimmungsdatensatz. 
Tatsächlich beschäftigte sich die Community des maschinellen Lernens schon immer damit, wie man schwache Modelle zu starken Modellen verbessern kann, ohne zusätzliche Trainingsdaten zu verwenden. Die Forschung in diesem Bereich lässt sich sogar auf den Boosting-Algorithmus zurückführen. Es gibt auch Studien, die zeigen, dass selbstlernende Algorithmen in Hybridmodellen schwache Lernende in starke Lernende umwandeln können, ohne dass zusätzliche gekennzeichnete Daten erforderlich sind. Allerdings ist die Fähigkeit, LLM ohne externe Anleitung automatisch zu verbessern, komplex und wenig untersucht. Dies wirft die folgende Frage auf:
Können wir LLM-Selbstverbesserung ohne zusätzliche vom Menschen gekennzeichnete Daten erreichen?
Methode
Im technischen Detail können wir das LLM aus der vorherigen Iteration als pθt bezeichnen, das die Antwort y' für Eingabeaufforderung x im vom Menschen gekennzeichneten SFT-Datensatz generiert. Das nächste Ziel besteht darin, ein neues LLM pθ{t+1} zu finden, das die von pθt erzeugte Antwort y' von der von einem Menschen gegebenen Antwort y unterscheiden kann.
Dieser Prozess kann als Spielprozess zwischen zwei Spielern angesehen werden: Der Hauptakteur ist der neue LLM pθ{t+1}, dessen Ziel es ist, die Reaktion des gegnerischen Spielers pθt von der vom Menschen erzeugten Reaktion zu unterscheiden; Der Gegenspieler ist der alte LLM pθt, dessen Aufgabe es ist, Antworten zu generieren, die dem vom Menschen markierten SFT-Datensatz möglichst nahe kommen.
Das neue LLM pθ{t+1} wird durch Feinabstimmung des alten LLM pθt erhalten. Der Trainingsprozess besteht darin, dem neuen LLM pθ{t+1} eine gute Fähigkeit zu verleihen, die von pθt generierte Antwort y' zu unterscheiden und die Reaktion des Menschen. Und dieses Training ermöglicht es dem neuen LLM pθ{t+1} nicht nur, als Hauptspieler eine gute Unterscheidungsfähigkeit zu erreichen, sondern ermöglicht dem neuen LLM pθ{t+1} auch, in der nächsten Iteration eine bessere Ausrichtung als gegnerischer Spieler zu erreichen. Antworten aus dem SFT-Datensatz. In der nächsten Iteration wird der neu erhaltene LLM pθ{t+1} zur Antwort des gegnerischen Spielers.
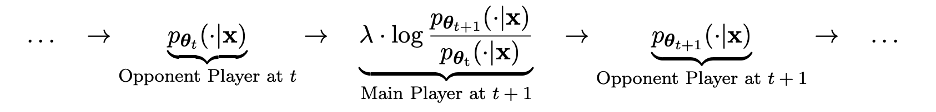

Das Ziel dieses Selbstspielprozesses besteht darin, das LLM schließlich zu pθ∗=p_data konvergieren zu lassen, sodass die vom leistungsstärksten LLM, das möglicherweise existiert, generierte Antwort nicht mehr vorhanden ist unterscheidet sich von der vorherigen Version und den Menschen. Die generierte Antwort ist anders.
Interessanterweise weist diese neue Methode Ähnlichkeit mit der kürzlich von Rafailov et al. vorgeschlagenen Methode der direkten Präferenzoptimierung (DPO) auf, der offensichtliche Unterschied der neuen Methode besteht jedoch in der Verwendung eines Selbstspielmechanismus. Daher hat diese neue Methode einen wesentlichen Vorteil: Es sind keine zusätzlichen menschlichen Präferenzdaten erforderlich.
Darüber hinaus können wir auch deutlich die Ähnlichkeit zwischen dieser neuen Methode und dem Generative Adversarial Network (GAN) erkennen, außer dass der Diskriminator (Hauptakteur) und der Generator (Gegner) in der neuen Methode dieselben LLM-Beispiele sind nach zwei benachbarten Iterationen.
Das Team führte auch einen theoretischen Beweis dieser neuen Methode durch und die Ergebnisse zeigten, dass die Methode genau dann konvergieren kann, wenn die Verteilung von LLM gleich der Zieldatenverteilung ist, d. h. p_θ_t=p_data.
Im Experiment verwendete das Team eine LLM-Instanz zephyr-7b-sft-full basierend auf der Mistral-7B-Feinabstimmung.
Die Ergebnisse zeigen, dass die neue Methode zephyr-7b-sft-full in kontinuierlichen Iterationen kontinuierlich verbessern kann. Wenn die SFT-Methode für kontinuierliches Training am SFT-Datensatz Ultrachat200k verwendet wird, erreicht die Bewertungspunktzahl dagegen die Leistung Es gab sogar einen Rückgang.
Noch interessanter ist, dass der von der neuen Methode verwendete Datensatz nur eine 50.000-Teilmenge des Ultrachat200.000-Datensatzes ist!
Die neue Methode SPIN hat eine weitere Errungenschaft: Sie kann die durchschnittliche Punktzahl des Basismodells zephyr-7b-sft-full in der HuggingFace Open LLM-Rangliste effektiv von 58,14 auf 63,16 verbessern, wobei sie auf GSM8k bessere Ergebnisse erzielen kann und TruthfulQA Eine erstaunliche Verbesserung von mehr als 10 %, sie kann auch auf MT-Bench von 5,94 auf 6,78 verbessert werden.
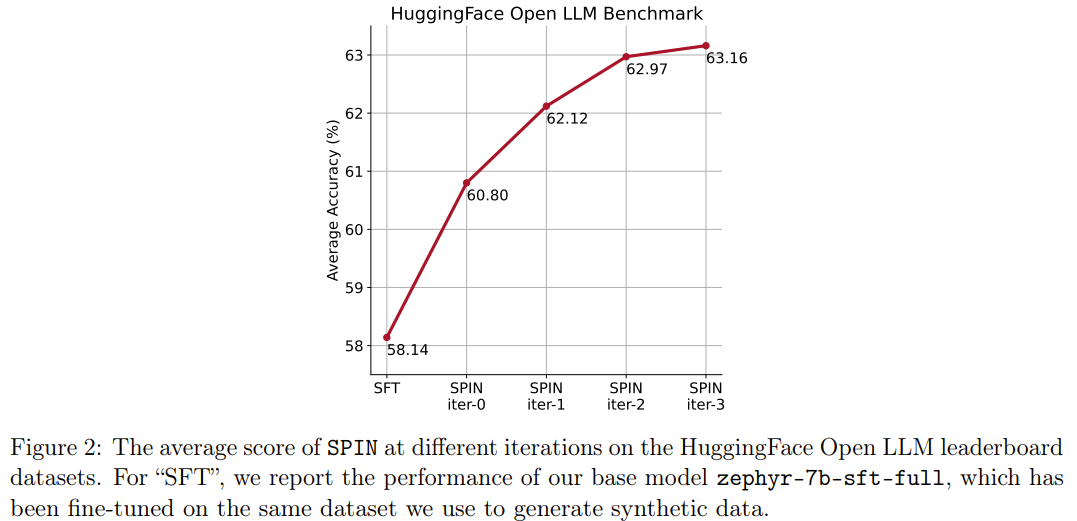
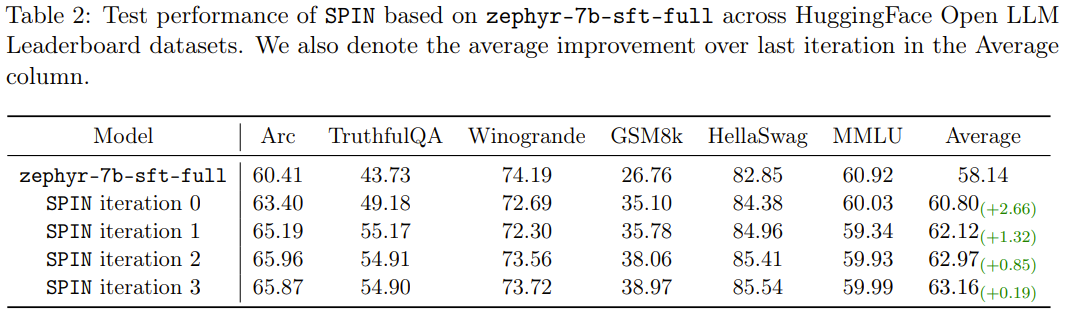
Bemerkenswert ist, dass das mit SPIN verfeinerte Modell auf der Open LLM-Bestenliste sogar mit dem Modell vergleichbar ist, das mit einem zusätzlichen 62.000-Präferenzdatensatz trainiert wurde.
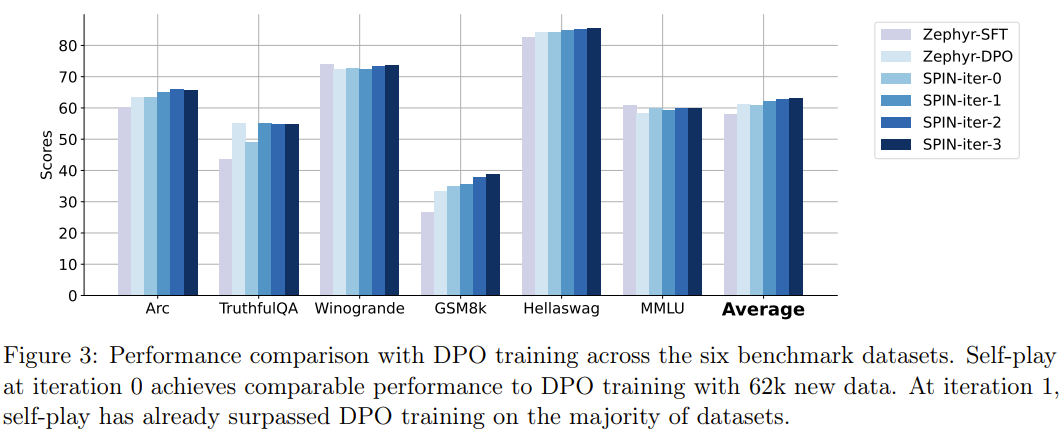
Durch die vollständige Nutzung menschlicher annotierter Daten ermöglicht SPIN, dass große Modelle durch Selbstspiel von schwach zu stark wechseln. Im Vergleich zum Verstärkungslernen basierend auf menschlichem Präferenz-Feedback (RLHF) ermöglicht SPIN LLM, sich selbst zu verbessern, ohne zusätzliches menschliches Feedback oder stärkeres LLM-Feedback. In Experimenten mit mehreren Benchmark-Datensätzen, einschließlich der HuggingFace Open LLM-Bestenliste, verbessert SPIN die Leistung von LLM deutlich und stabil und übertrifft sogar Modelle, die mit zusätzlichem KI-Feedback trainiert wurden.
Wir gehen davon aus, dass SPIN zur Entwicklung und Verbesserung großer Modelle beitragen und letztendlich künstliche Intelligenz über das menschliche Niveau hinaus erreichen kann.
Das obige ist der detaillierte Inhalt vonLLM lernt, gegeneinander zu kämpfen, und das Grundmodell kann zu Gruppeninnovationen führen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



