


Möchten Sie ein Dokumentbild in das Markdown-Format konvertieren?
In der Vergangenheit erforderte diese Aufgabe mehrere Schritte wie Texterkennung, Layouterkennung und -sortierung, Verarbeitung von Formeltabellen, Textbereinigung usw. –
Diesmal mit nur einem Befehlssatz: Multimodales großes Modell Vary wird direkt an die Ausgabeergebnisse des Terminals geliefert:
 Bilder
Bilder
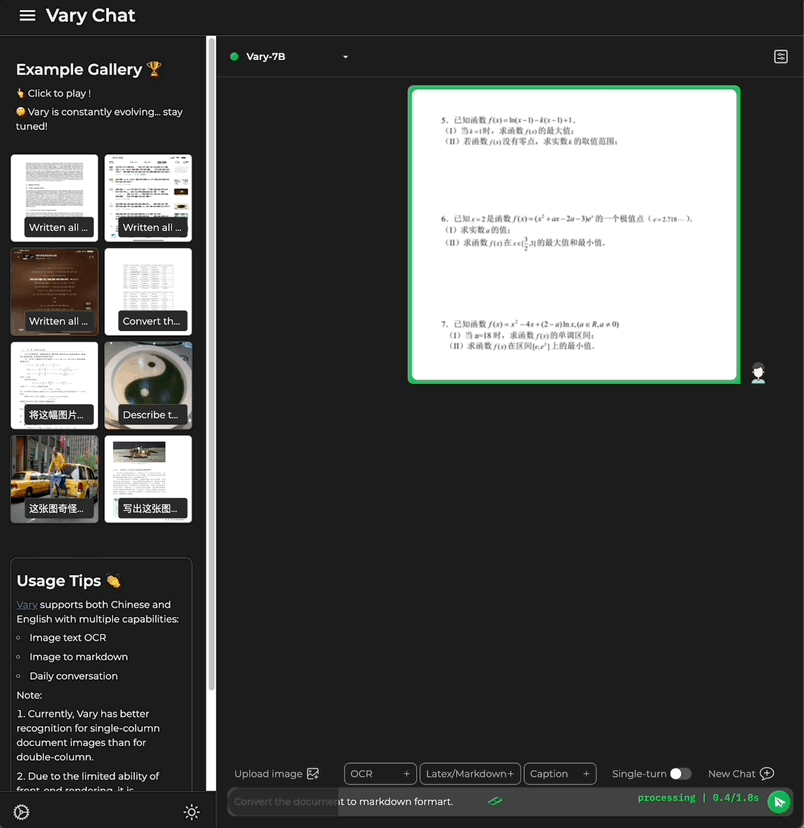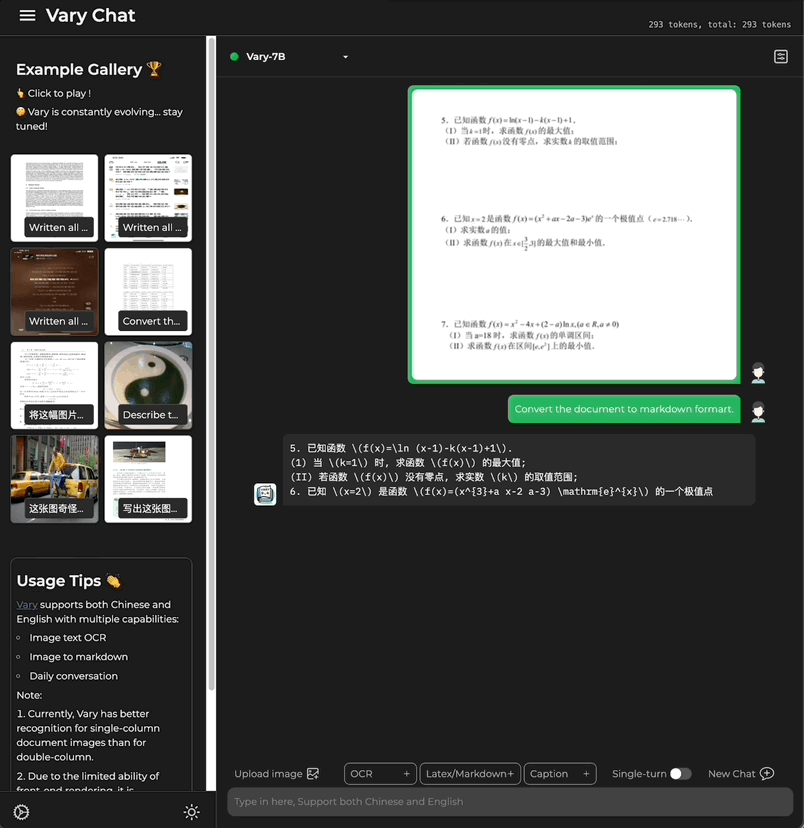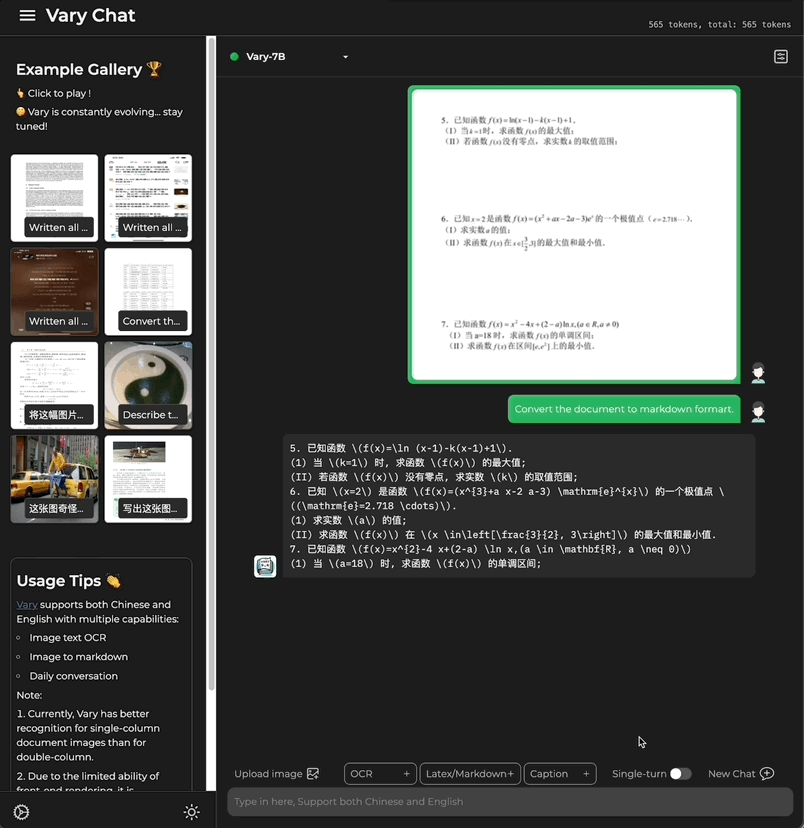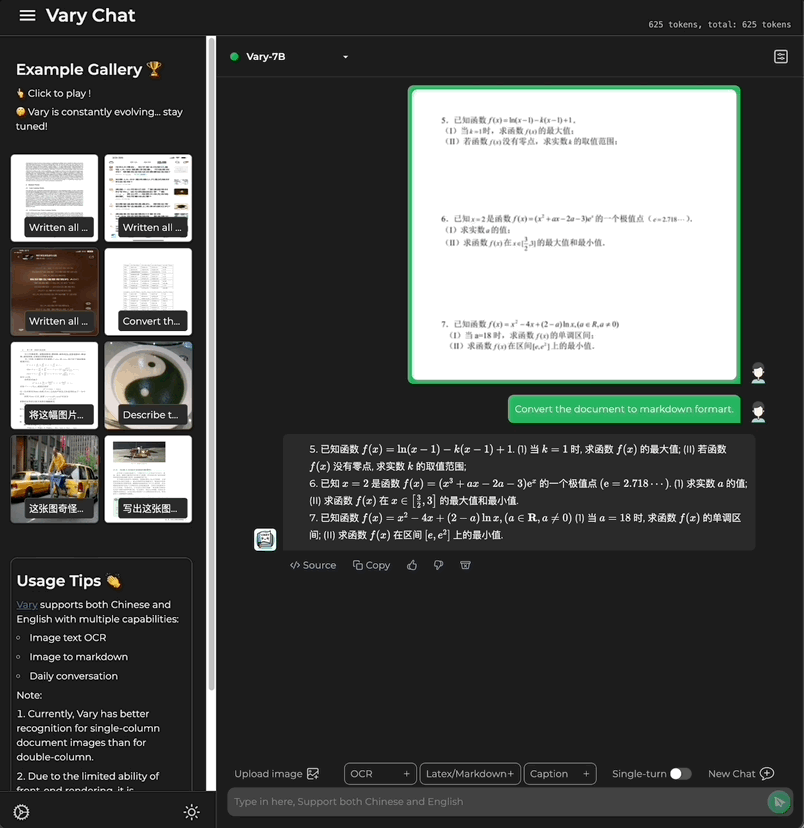
Ob es sich um einen großen Text auf Chinesisch oder Englisch handelt:
 Bilder
Bilder
Enthält auch Formeldokumentbilder
 Bilder
Bilder
oder eine mobile Seite Screenshot:
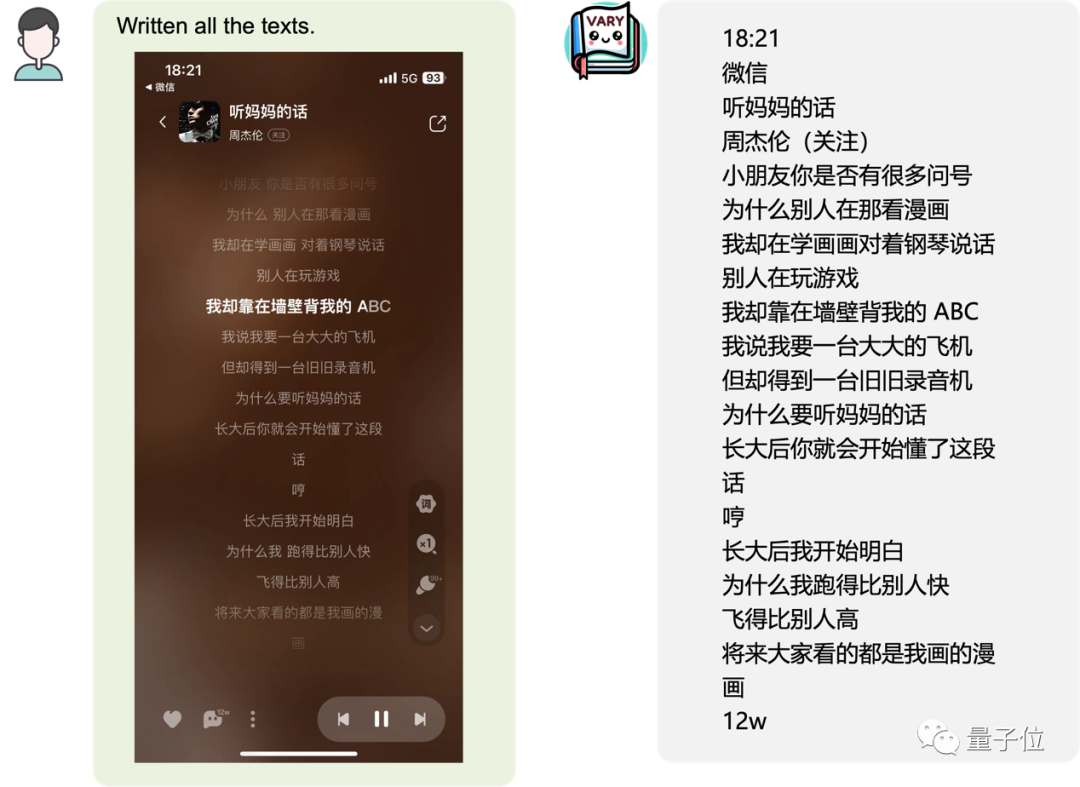 Bild
Bild
Sie können die Tabelle im Bild sogar in Latex umwandelnFormat:
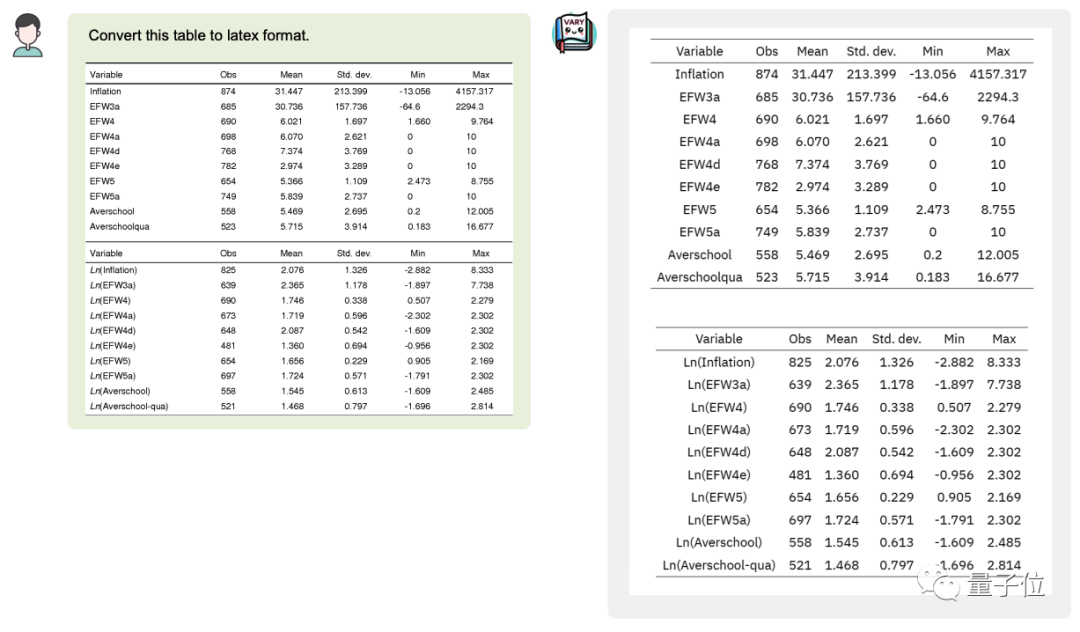 Bild
Bild
Natürlich als Multi-Modell groß Modell, die Aufrechterhaltung universeller Fähigkeiten ist unerlässlich. Die
 Bilder
Bilder
Vary zeigen großes Potenzial und eine extrem hohe Obergrenze, können keine lange Pipeline mehr erfordern, können direkt durchgängig ausgegeben werden und können verschiedene Formate wie Latex ausgeben nach Benutzeraufforderung, Wort, Markdown.
Mit starken Sprachprioritäten kann diese Architektur tippfehleranfällige Wörter in der OCR vermeiden, wie z. B. „Hebel“ und „Dupol“ usw. Bei Fuzzy-Dokumenten soll mit Hilfe von Sprachpriors auch stärkere OCR-Effekte erzielt werden
Das Projekt, das die Aufmerksamkeit vieler Internetnutzer auf sich zog, löste nach seinem Start sofort breite Diskussionen aus. Einer der Internetnutzer rief, nachdem er es gesehen hatte: „Es ist so großartig!“
 Bild
Bild
Wie wird dieser Effekt erzielt?
Derzeit verwenden fast alle multimodalen großen Modelle CLIP als Vision Encoder oder visuelles Vokabular. Tatsächlich verfügt CLIP, das auf 400 Millionen Bild-Text-Paaren trainiert wurde, über starke Fähigkeiten zur visuellen Textausrichtung und kann die Bildkodierung bei den meisten täglichen Aufgaben abdecken.
Aber bei dichten und feinkörnigen Wahrnehmungsaufgaben wie OCR auf Dokumentebene und Diagrammverständnis, insbesondere in nicht-englischen Szenarien, zeigt CLIP offensichtliche Codierungsineffizienz und Probleme mit fehlendem Wortschatz.
Wenn ein großes reines NLP-Modell (wie LLaMA) von Englisch auf Chinesisch übergeht (eine „Fremdsprache“ für das große Modell), muss das Textvokabular erweitert werden, um bessere Ergebnisse zu erzielen, da das ursprüngliche Vokabular, das Chinesisch codiert, ineffizient ist.
Das Forschungsteam hat sich davon inspirieren lassen
Jetzt steht das auf dem visuellen CLIP-Vokabular basierende multimodale große Modell vor dem gleichen Problem und stößt auf „fremdsprachige Bilder“, wie z. B. eine dicht gepackte Seite Wenn Sie Text in einer Arbeit verwenden, ist es schwierig, Bilder effizient zu tokenisieren.
Vary ist eine Lösung zur Lösung dieses Problems. Es kann das visuelle Vokabular effizient erweitern, ohne das ursprüngliche Vokabular wiederherzustellen.
 Bilder funktioniert in zwei Phasen:
Bilder funktioniert in zwei Phasen:
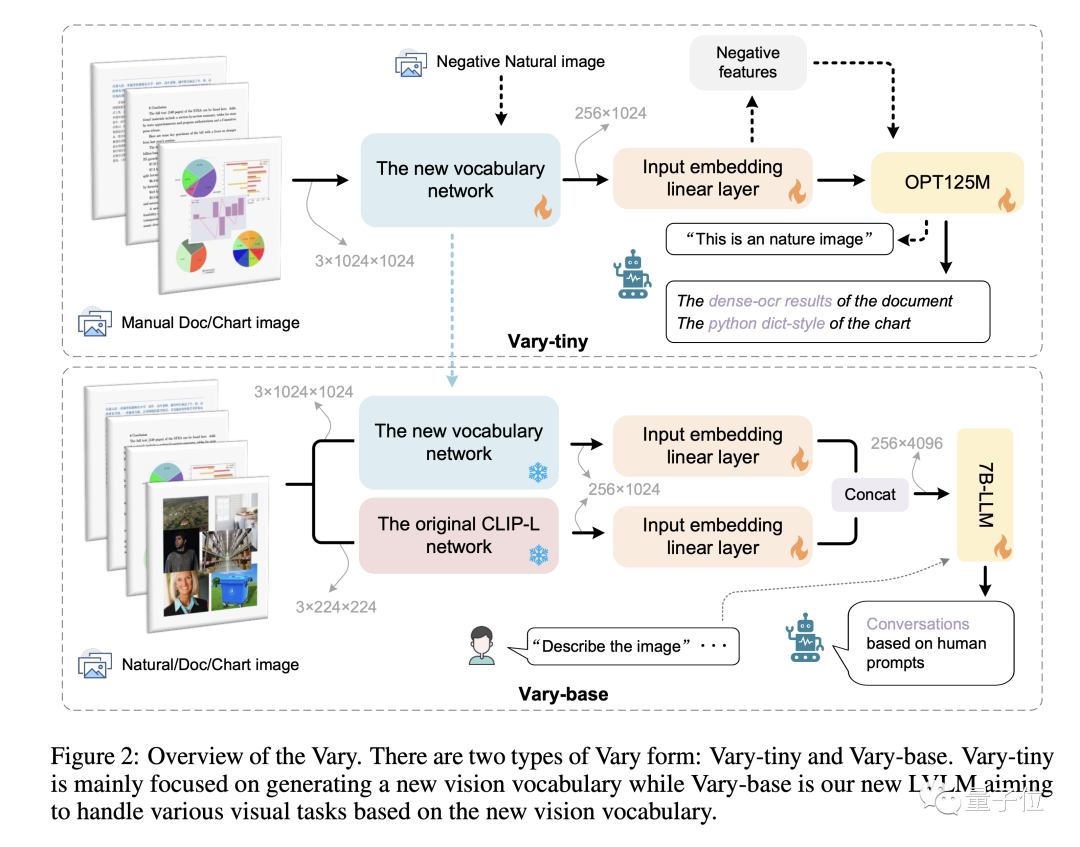 Vary wird auf öffentlichen Datensätzen und gerenderten Dokumentdiagrammen trainiert und verbessert die Feinkörnigkeit erheblich visuelle Wahrnehmungsfähigkeiten.
Vary wird auf öffentlichen Datensätzen und gerenderten Dokumentdiagrammen trainiert und verbessert die Feinkörnigkeit erheblich visuelle Wahrnehmungsfähigkeiten.
Während die multimodalen Vanilla-Funktionen erhalten bleiben, bietet es durchgängige chinesische und englische Bild-, Formel-Screenshots- und Diagrammverständnisfunktionen.
Darüber hinaus stellte das Forschungsteam fest, dass der Seiteninhalt, der ursprünglich möglicherweise Tausende von Token erforderte, durch Dokumentbilder eingegeben wurde und die Informationen in 256 Bildtoken komprimiert wurden, was auch mehr Fantasie für die weitere Seitenanalyse und den Zusammenfassungsraum bot.
Derzeit sind Varys Code und Modell Open Source, und es wird auch eine Webdemo bereitgestellt, die jeder ausprobieren kann.
Interessierte Freunde können es ausprobieren~
Das obige ist der detaillierte Inhalt vonDas multimodale Open-Source-Großmodell von Megvii unterstützt OCR auf Dokumentebene und deckt Chinesisch und Englisch ab. Markiert es das Ende von OCR?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn im Skript der aktuellen Seite ein Fehler auftritt?
Was tun, wenn im Skript der aktuellen Seite ein Fehler auftritt?
 So legen Sie Kopf- und Fußzeilen in Word fest
So legen Sie Kopf- und Fußzeilen in Word fest
 Was ist der Unterschied zwischen Leerzeichen voller Breite und Leerzeichen halber Breite?
Was ist der Unterschied zwischen Leerzeichen voller Breite und Leerzeichen halber Breite?
 Software für virtuelle Maschinen
Software für virtuelle Maschinen
 Welche Bildbearbeitungssoftware gibt es?
Welche Bildbearbeitungssoftware gibt es?
 So legen Sie ein PPT-Hintergrundbild fest
So legen Sie ein PPT-Hintergrundbild fest
 Verwendung von Kordelzug
Verwendung von Kordelzug
 WLAN zeigt an, dass keine IP zugewiesen ist
WLAN zeigt an, dass keine IP zugewiesen ist








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



