



Neuigkeiten vom 29. Dezember: Die Reichweite großer Sprachmodelle (LLM) hat sich von der einfachen Verarbeitung natürlicher Sprache auf multimodale Felder wie Text, Audio, Video usw. ausgeweitet. Und einer der Schlüssel ist die Video-Timing-Positionierung (Video-Erdung, VG).
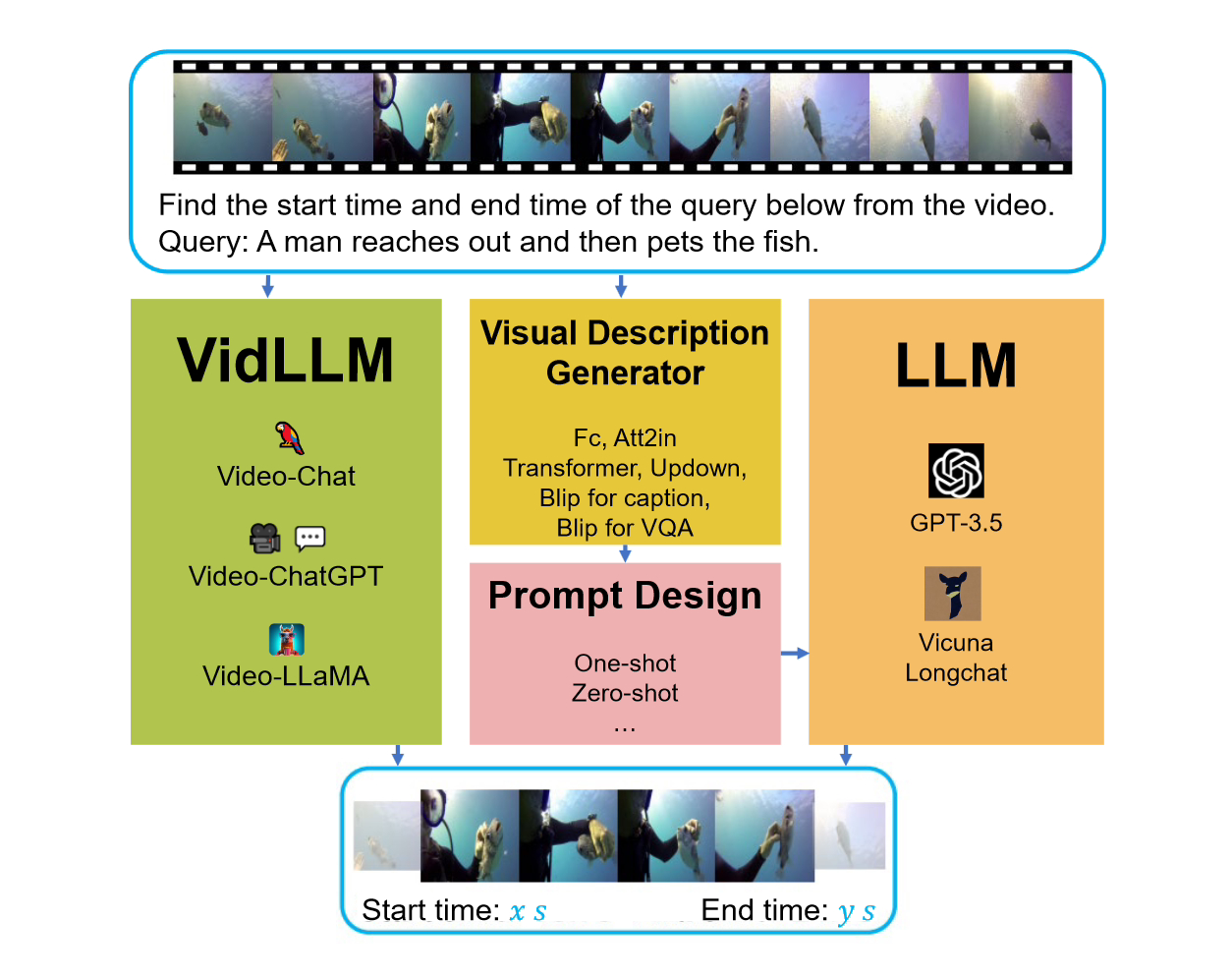
Das Ziel der VG-Aufgabe besteht darin, die Start- und Endzeit des Zielvideosegments basierend auf der gegebenen Abfrage zu ermitteln. Die zentrale Herausforderung dieser Aufgabe besteht darin, die Zeitgrenzen genau zu bestimmen.
Das Forschungsteam der Tsinghua-Universität hat kürzlich den „LLM4VG“-Benchmark eingeführt, der speziell zur Bewertung der Leistung von LLM bei VG-Aufgaben entwickelt wurde.
Bei der Betrachtung dieses Benchmarks wurden zwei Hauptstrategien berücksichtigt. Die erste Strategie besteht darin, ein Videosprachenmodell (LLM) direkt auf dem Textvideodatensatz (VidLLM) zu trainieren. Diese Methode lernt den Zusammenhang zwischen Video und Sprache durch Training an einem großen Videodatensatz, um die Leistung des Modells zu verbessern. Die zweite Strategie besteht darin, ein traditionelles Sprachmodell (LLM) mit einem vorab trainierten Vision-Modell zu kombinieren. Diese Methode basiert auf einem vorab trainierten visuellen Modell, das die visuellen Eigenschaften des Videos kombiniert. In einer Strategie verarbeitet das VidLLM-Modell direkt den Videoinhalt und die VG-Aufgabenanweisungen und sagt die Text-Video-Beziehung basierend auf seiner Trainingsausgabe voraus. Beziehung.
Die zweite Strategie ist komplexer und beinhaltet die Verwendung von LLM (Language and Vision Models) und visuellen Beschreibungsmodellen. Diese Modelle sind in der Lage, Textbeschreibungen von Videoinhalten in Kombination mit VG-Aufgabenanweisungen (Video Game) zu generieren, und diese Beschreibungen werden mit sorgfältig gestalteten Eingabeaufforderungen implementiert. 
Und die zweite Strategie ist besser als VidLLM und zeigt eine vielversprechende Richtung für zukünftige Forschung auf. Diese Strategie wird hauptsächlich durch die Einschränkungen des visuellen Modells und des Designs der Stichwortwörter eingeschränkt. Um detaillierte und genaue Videobeschreibungen generieren zu können, kann ein verfeinertes grafisches Modell die VG-Leistung von LLM erheblich verbessern.

Zusammenfassend liefert diese Studie eine bahnbrechende Bewertung der Anwendung von LLM auf VG-Aufgaben und unterstreicht die Notwendigkeit ausgefeilterer Methoden für das Modelltraining und das Cue-Design.
Die Referenzadresse des Artikels ist dieser Website beigefügt: 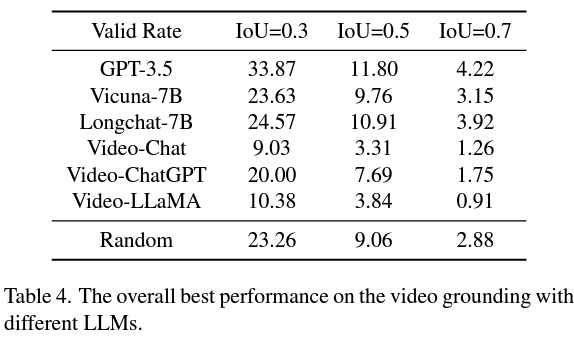
Das obige ist der detaillierte Inhalt vonBewerten Sie die Leistung des von der Tsinghua-Universität entwickelten LLM4VG-Benchmarks bei der Video-Timing-Positionierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Drei Möglichkeiten, einen Thread in Java zu beenden
Drei Möglichkeiten, einen Thread in Java zu beenden
 Einführung in SEO-Diagnosemethoden
Einführung in SEO-Diagnosemethoden
 So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
So legen Sie fest, dass beide Enden in CSS ausgerichtet sind
 So lösen Sie das Problem, dass der PHPStudy-Port belegt ist
So lösen Sie das Problem, dass der PHPStudy-Port belegt ist
 orientdb
orientdb
 Was sind die beschrifteten Münzen?
Was sind die beschrifteten Münzen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



