Kürzlich hat ein auf der Schrödinger-Brücke [1] basierendes Sprachsynthesesystem, das von der Forschungsgruppe von Professor Zhu Jun vom Fachbereich Informatik der Tsinghua-Universität veröffentlicht wurde, das Diffusionsmodell in Bezug auf Probenqualität und Abtastgeschwindigkeit aufgrund seiner „Daten- Das „Noise-to-Data“-Paradigma. 
Papierlink: https://arxiv.org/abs/2312.03491 Projektwebsite: https://bridge-tts.github.io/ Code-Implementierung: https://github.com/thu -ml/Bridge-TTS , TTS) Eine der Kernerzeugungsmethoden, wie Grad-TTS [2], vorgeschlagen vom Noah's Ark Laboratory von Huawei, und DiffSinger [3], vorgeschlagen von der Zhejiang-Universität, haben eine hohe Erzeugungsqualität erreicht. Seitdem haben viele Forschungsarbeiten die Abtastgeschwindigkeit von Diffusionsmodellen effektiv verbessert, beispielsweise durch vorherige Optimierung [2, 3, 4], Modelldestillation [5, 6], Restvorhersage [7] und andere Methoden. Da das Diffusionsmodell jedoch, wie in dieser Studie gezeigt, auf das Generierungsparadigma „Rauschen zu Daten“ beschränkt ist, liefert seine vorherige Verteilung immer nur begrenzte Informationen für das Generierungsziel und kann die bedingten Informationen nicht vollständig nutzen.
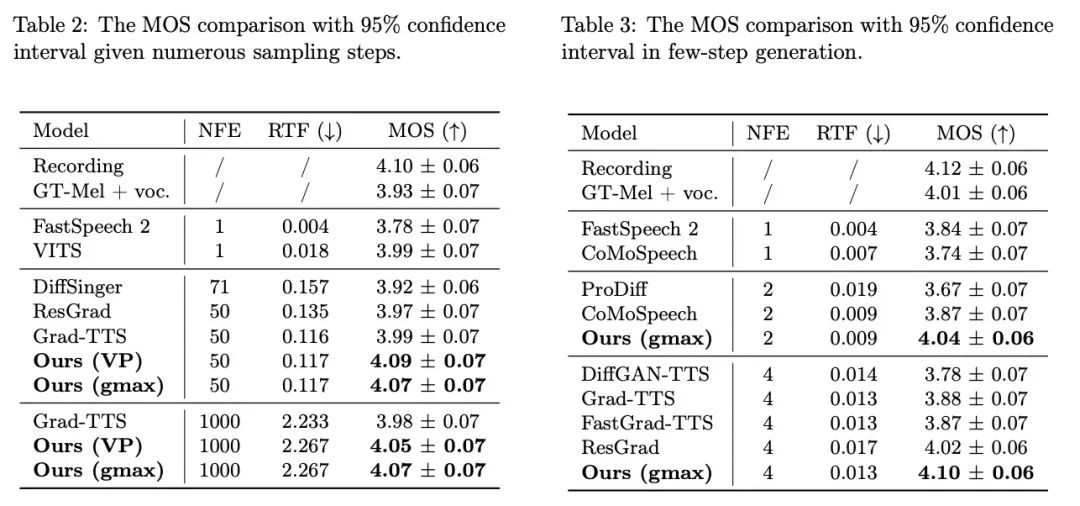
Die neueste Forschungsarbeit auf dem Gebiet der Sprachsynthese, Bridge-TTS, basiert auf seinem auf der Schrödinger-Brücke basierenden Generierungsrahmen, um den „Daten-zu-Daten“-Generierungsprozess zu realisieren. Zum ersten Mal werden die vorherigen Informationen der Sprachsynthese verwendet wird von Rauschen zu sauberen Daten geändert, wird von Verteilung zu deterministischer Darstellung geändert. Die Hauptarchitektur dieser Methode ist in der Abbildung oben dargestellt. Der Eingabetext wird zunächst über den Textcodierer extrahiert, um die latente Raumdarstellung des generierten Ziels (Mel-Spektrogramm, Mel-Spektrum) zu extrahieren. Danach unterstützt die Bridge-TTS-Methode im Gegensatz zum Diffusionsmodell, das diese Informationen in die Rauschverteilung einbezieht oder als bedingte Informationen verwendet, die direkte Verwendung als vorherige Informationen und unterstützt zufällige oder deterministische Stichproben, Hohe Qualität und schnelle Zielgenerierung. Auf LJ-Speech, einem Standarddatensatz, der die Qualität der Sprachsynthese überprüft, beschleunigte das Forschungsteam Bridge-TTS mit 9 hochwertigen Sprachsynthesesystemen und -diffusion Modelle Stichprobenmethoden wurden verglichen. Wie unten gezeigt, übertrifft diese Methode hochwertige, auf Diffusionsmodellen basierende TTS-Systeme [2, 3, 7] in der Probenqualität (1000 Schritte, 50 Schritte Sampling) und in der Probengeschwindigkeit ohne Nachbearbeitung unter Bedingungen B. die zusätzliche Modelldestillation, übertrifft es viele Beschleunigungsmethoden, wie z. B. die Restvorhersage, die progressive Destillation und die neueste Konsensdestillation [5, 6, 7]. Im Folgenden finden Sie Beispiele für die Generierungseffekte von Bridge-TTS und der auf Diffusionsmodellen basierenden Methode. Weitere Generierungsbeispielvergleiche finden Sie auf der Projektwebsite: https://bridge-tts.github.io/-
1000-Schritt-Synthese-Effektvergleich
Geben Sie den Text ein: „Drucken kann für unseren Zweck als die Kunst der Herstellung von Büchern mittels beweglicher Lettern betrachtet werden.“-
4 Vergleich der Stufensyntheseeffekte
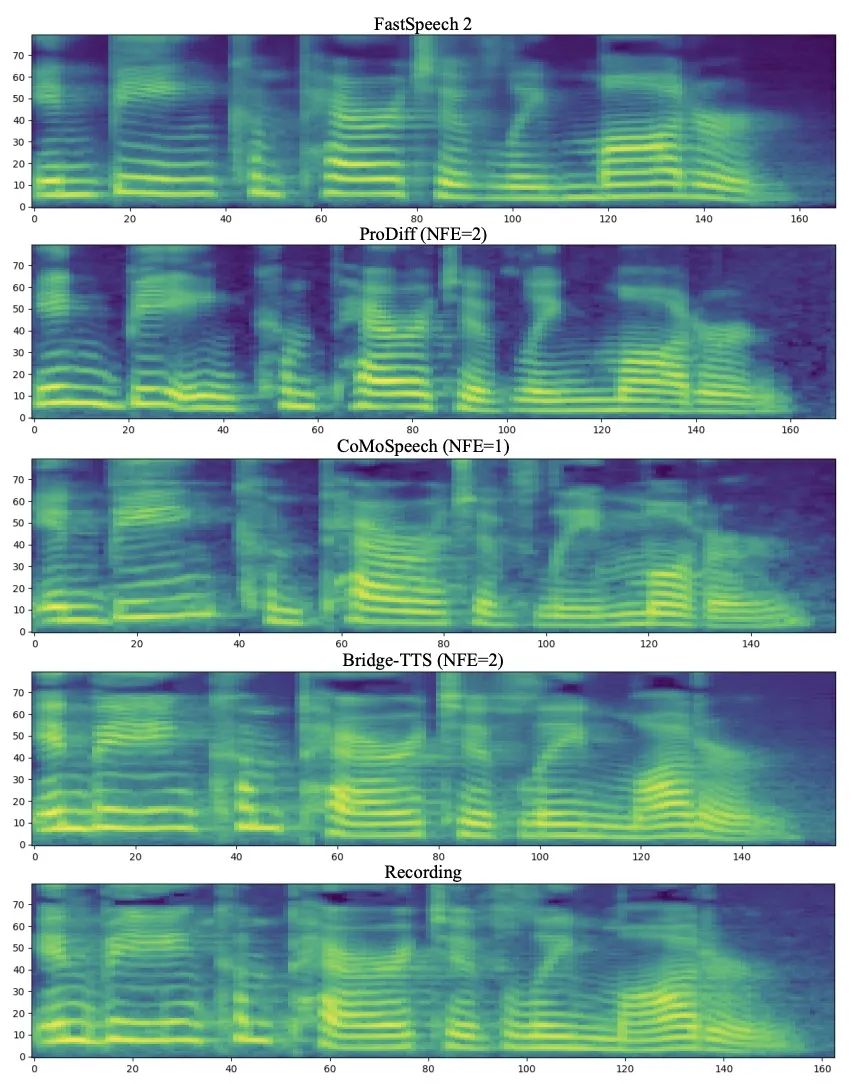
Eingabetext: „Die ersten Bücher wurden in schwarzer Schrift gedruckt, d 2 Vergleich der Stufensyntheseeffekte TTS in 2 Schritten und 4 Schritten) Fall. Bei der 4-stufigen Synthese synthetisiert diese Methode deutlich mehr Probendetails als das Diffusionsmodell, und es gibt kein Problem mit Restrauschen. In einer zweistufigen Synthese zeigt diese Methode völlig reine Abtasttrajektorien und verfeinert bei jedem Schritt mehr generierte Details. 
Im Frequenzbereich werden unten mehr erzeugte Proben angezeigt. In 1000 Syntheseschritten erzeugt diese Methode ein Mel-Spektrum höherer Qualität im Vergleich zum Diffusionsmodell, wenn die Anzahl der Probenschritte reduziert wird Obwohl das Diffusionsmodell einige Abtastdetails geopfert hat, liefert die auf der Schrödinger-Brücke basierende Methode immer noch qualitativ hochwertige Generierungsergebnisse. Bei der 4-stufigen und 2-stufigen Synthese erfordert diese Methode keine Destillation, kein mehrstufiges Training und keine kontradiktorischen Verlustfunktionen und erzielt dennoch qualitativ hochwertige Erzeugungseffekte.
In 1000 Syntheseschritten der Mel-Spektrum-Vergleich von Bridge-TTS und der Diffusionsmodell-basierten Methode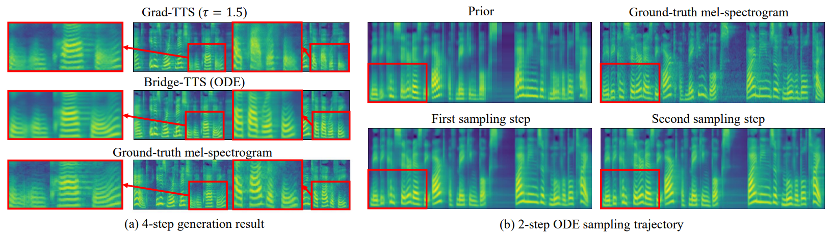 In 50 Syntheseschritten Bridge-TTS und die auf dem Diffusionsmodell basierende Methode Mel-Spektrum-Vergleich von Diffusionsmodellmethoden
In 50 Syntheseschritten Bridge-TTS und die auf dem Diffusionsmodell basierende Methode Mel-Spektrum-Vergleich von Diffusionsmodellmethoden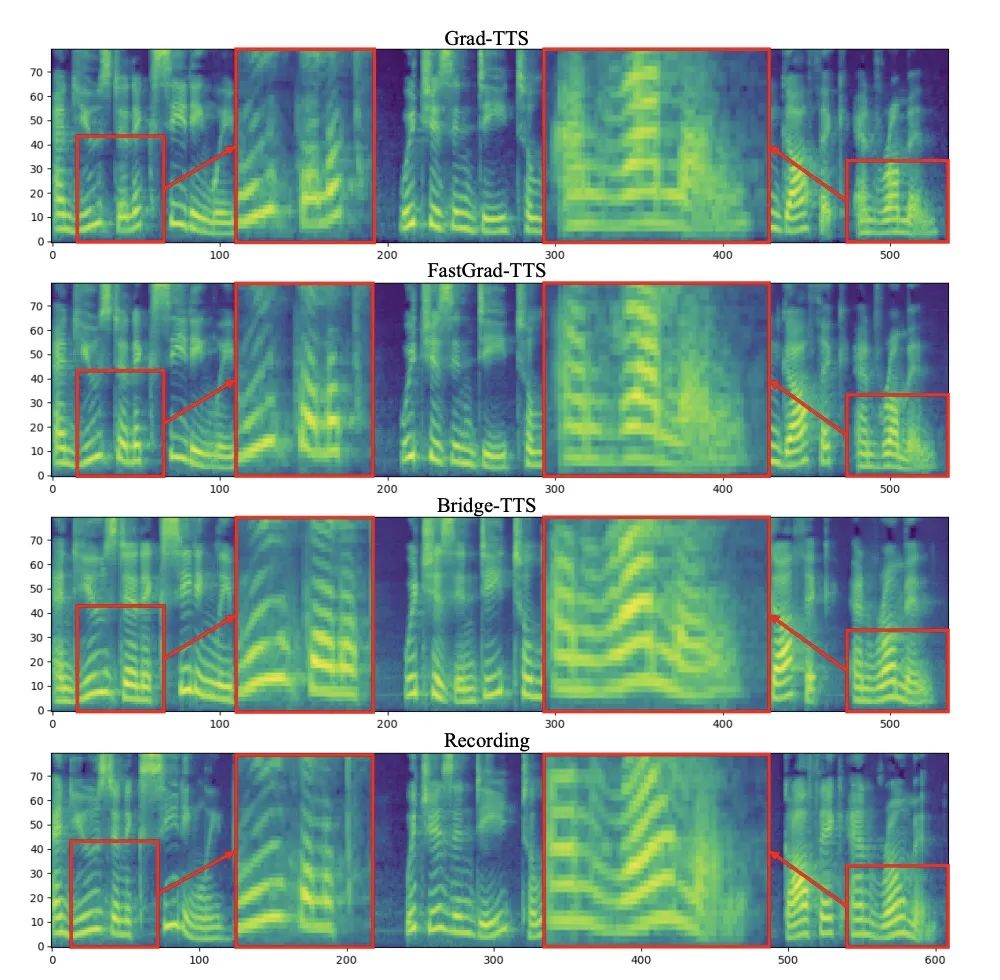
Vergleich von Mel-Spektren zwischen Bridge-TTS- und diffusionsmodellbasierten Methoden in der 4-Schritt-SyntheseIn der 2-Schritt-Synthese, Bridge-TTS und diffusionsbasierten Methoden Methoden Mel-Spektrum-Vergleich von ModellmethodenBridge-TTS erregte nach seiner Veröffentlichung mit seinem neuartigen Design und dem hochwertigen Syntheseeffekt bei der Sprachsynthese begeisterte Aufmerksamkeit auf Twitter und erhielt Hunderte von Kommentaren mit mehr als Mit 100 Retweets und Hunderten von Likes wurde Huggingface am 12.7 in die Tageszeitung von Huggingface aufgenommen und belegte an diesem Tag den ersten Platz in der Unterstützungsrate. Gleichzeitig wurde er auf vielen in- und ausländischen Plattformen wie LinkedIn, Weibo, Zhihu, verfolgt. und Xiaohongshu. Many Fremdsprach -Websites haben auch gemeldet und diskutiert: Die Schrodinger -Brücke ist eine Art von Modell, die kürzlich nach dem Diffusionsmodell entstanden ist Das tiefe generative Modell hat vorläufige Anwendungen in der Bilderzeugung, Bildübersetzung und anderen Bereichen [8,9]. Im Gegensatz zum Diffusionsmodell, das einen Transformationsprozess zwischen Daten und Gaußschem Rauschen etabliert, unterstützt die Schrödinger-Brücke die Transformation zwischen zwei beliebigen Grenzverteilungen. In der Studie zu Bridge-TTS schlugen die Autoren ein Sprachsynthese-Framework vor, das auf der Schrödinger-Brücke zwischen gepaarten Daten basiert und eine Vielzahl von Vorwärtsprozessen, Vorhersagezielen und Abtastprozessen flexibel unterstützt. Eine Übersicht über die Methode ist in der folgenden Abbildung dargestellt: 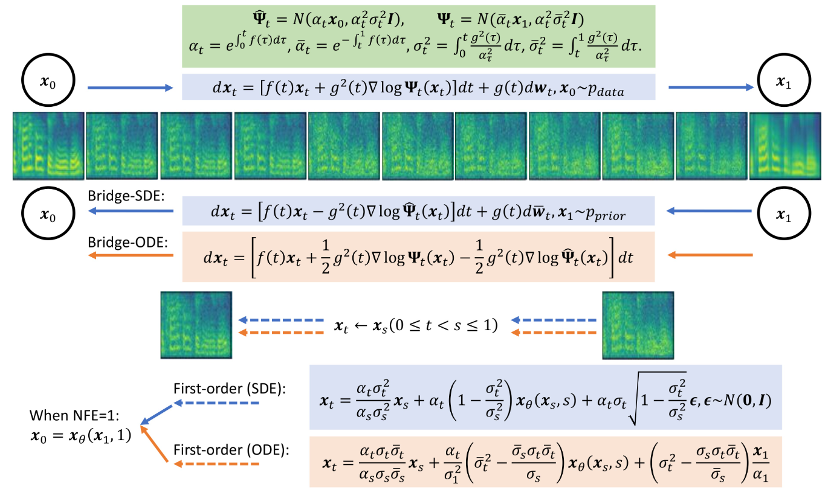
- Vorwärtsprozess: Diese Forschung baut eine vollständig lösbare Schrödinger-Brücke zwischen starken Informationsprioritäten und Generierungszielen auf und unterstützt einen flexiblen Vorwärtsprozess. Wählen Sie aus symmetrischem Rauschen Strategien:
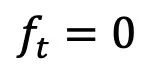 , konstante
, konstante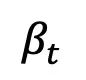 und asymmetrische Rauschstrategien:
und asymmetrische Rauschstrategien:  , lineare
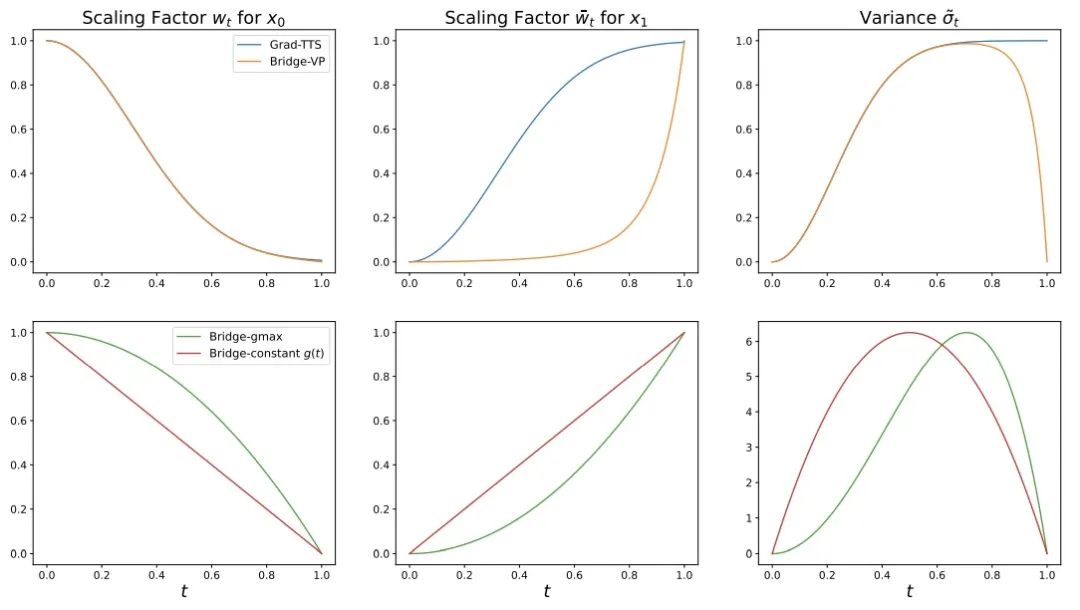
, lineare sowie varianzerhaltende (VP)Rauschstrategien, die direkt Diffusionsmodellen entsprechen. Diese Methode ergab, dass asymmetrische Rauschstrategien: lineare
sowie varianzerhaltende (VP)Rauschstrategien, die direkt Diffusionsmodellen entsprechen. Diese Methode ergab, dass asymmetrische Rauschstrategien: lineare  (gmax) und VP-Prozesse bei Sprachsyntheseaufgaben bessere Erzeugungseffekte haben als symmetrische Rauschstrategien.
(gmax) und VP-Prozesse bei Sprachsyntheseaufgaben bessere Erzeugungseffekte haben als symmetrische Rauschstrategien.

- Modelltraining: Diese Methode behält mehrere Vorteile des Diffusionsmodell-Trainingsprozesses bei, wie z. B. Einzelstufe, Einzelmodell und Einzelverlustfunktion. Und es vergleicht verschiedene Methoden der Modellparametrisierung (Modellparametrisierung), dh die Auswahl von Netzwerktrainingszielen, einschließlich Rauschvorhersage (Rauschen), Generierungszielvorhersage (Daten) und Flussanpassungstechnologie entsprechend dem Diffusionsmodell [10,11 ] Geschwindigkeitsvorhersage (Velocity) usw. Der Artikel stellte fest, dass relativ bessere Generierungsergebnisse erzielt werden können, wenn das Generierungsziel, also das Mel-Spektrum, als Netzwerkvorhersageziel verwendet wird.
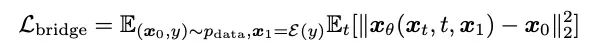
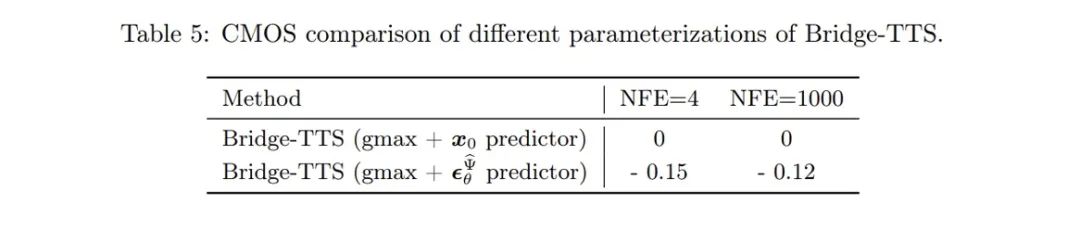
- Abtastprozess: Dank der vollständig lösbaren Form der Schrödinger-Brücke in dieser Studie erhielten die Autoren durch Transformation des der Schrödinger-Brücke entsprechenden Vorwärts-Rückwärts-SDE-Systems die Brücken-SDE und Bridge ODE wird zur Inferenz verwendet. Aufgrund der langsamen Geschwindigkeit der direkten Simulation der Bridge-SDE/ODE-Inferenz wurde in dieser Studie gleichzeitig der exponentielle Integrator [12,13] verwendet, der üblicherweise in Diffusionsmodellen verwendet wird, um die SDE erster Ordnung zu erhalten, um die Stichprobenziehung zu beschleunigen und ODE-Abtastformen der Schrödinger-Brücke:
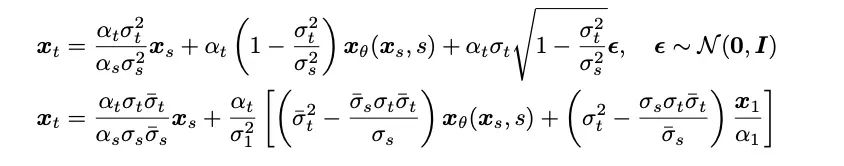
Bei der einstufigen Abtastung degenerieren die Abtastformen von SDE und ODE erster Ordnung gemeinsam zu einer einstufigen Vorhersage des Netzwerks. Gleichzeitig stehen sie in engem Zusammenhang mit der DDIM-Probenahme des posterioren Probenahme-/Diffusionsmodells, und der Artikel enthält eine detaillierte Analyse im Anhang. Der Artikel stellt auch die SDE- und ODE-Abtastalgorithmen zweiter Ordnung der Schrödinger-Brücke bereit. Die Autoren fanden heraus, dass bei der Sprachsynthese die Generierungsqualität einem Sampling-Prozess erster Ordnung ähnelt. Bei anderen Aufgaben wie Sprachverbesserung, Sprachtrennung, Sprachbearbeitung und anderen Aufgaben, bei denen die Vorinformationen ebenfalls stark sind, erwarten die Autoren, dass diese Forschung auch einen größeren Anwendungswert bringen wird. Diese Studie hat drei Co-Erstautoren: Chen Zehua, He Guande und Zheng Kaiwen, alle gehören zur Forschungsgruppe von Zhu Jun in der Abteilung für Informatik der Tsinghua-Universität Der korrespondierende Autor des Artikels ist Professor Zhu Jun, Microsoft Asia Research. Tan Xu, leitender Forschungsleiter des Instituts, ist ein Projektmitarbeiter. 
Tan Xu, Chief Research Manager, Microsoft Research Asia, Soundeffekte, bioelektrische Signalsynthese und andere Anwendungen. Er absolvierte Praktika bei vielen Unternehmen wie Microsoft, JD.com und TikTok und veröffentlichte zahlreiche Beiträge auf wichtigen internationalen Konferenzen im Bereich Sprache und maschinelles Lernen, wie ICML/NeurIPS/ICASSP.

He Guande ist Masterstudent im dritten Jahr an der Tsinghua-Universität. Seine Hauptforschungsrichtung ist Unsicherheitsschätzung und generative Modelle. Er hat zuvor Artikel als Erstautor auf ICLR und anderen Konferenzen veröffentlicht.

Zheng Kaiwen ist Masterstudent im zweiten Jahr an der Tsinghua-Universität. Seine Hauptforschungsrichtung ist die Theorie und der Algorithmus tiefer generativer Modelle und deren Anwendungen in der Bild-, Audio- und 3D-Generierung. Zuvor hat er zahlreiche Artikel auf Top-Konferenzen wie ICML/NeurIPS/CVPR veröffentlicht, in denen es um Technologien wie Flow Matching und exponentielle Integratoren in Diffusionsmodellen ging. [1] Zehua Chen, Guande He, Kaiwen Zheng, Xu Tan und Jun Zhu. Schrödinger Bridges schlagen Diffusionsmodelle zur Text-to-Speech-Synthese :2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova und Mikhail A. Kudinov: A Diffusion Probabilistic Model for Text-to-Speech. 2021.[3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen und Zhou Zhao. Singing Voice Synthesis via Shallow Diffusion Mechanism.[ 4 ] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon und Tie-Yan Liu PriorGrad: Verbesserung bedingter Rauschunterdrückungsmodelle mit datenabhängigem adaptivem Prior. In ICLR, 2022. [5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui und Yi Ren. ProDiff: Progressives schnelles Diffusionsmodell für hochwertige Text-zu-Sprache ACM Multimedia, 2022. [6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu und Yike Guo: One-Step Speech and Singing Voice Synthesis via Consistency Model , 2023.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian und Danilo P. Mandic . ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech. [9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie und Anima Anandkumar: Bild-zu-Bild-Schrödinger-Brücke. 2023.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel und Matt Le. Flow Matching für generative Modellierung.[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen und Jun Zhu. Verbesserte Techniken zur Schätzung der maximalen Wahrscheinlichkeit für Diffusions-ODEs. [12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li und Jun Zhu. DPM-Solver: Ein schneller ODE-Löser für die Diffusions-Probabilistik-Modellstichprobe in etwa 10 Schritten . DPM-Solver-v3: Verbesserter Diffusions-ODE-Löser mit empirischer Modellstatistik in NeurIPS, 2023.Das obige ist der detaillierte Inhalt vonMit Hilfe der Schrödinger-Brücke entwickelt das Team von Zhu Jun an der Tsinghua-Universität ein neues Sprachsynthesesystem, um den Herausforderungen der Verbreitung zu begegnen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



 , lineare
, lineare sowie varianzerhaltende (VP)Rauschstrategien, die direkt Diffusionsmodellen entsprechen. Diese Methode ergab, dass asymmetrische Rauschstrategien: lineare
sowie varianzerhaltende (VP)Rauschstrategien, die direkt Diffusionsmodellen entsprechen. Diese Methode ergab, dass asymmetrische Rauschstrategien: lineare 















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



