


Die neuesten Untersuchungen der Cornell University und von Apple kamen zu dem Schluss, dass der Aufmerksamkeitsmechanismus eliminiert werden kann, um hochauflösende Bilder mit weniger Rechenleistung zu erzeugen.
Wie wir alle wissen, ist der Aufmerksamkeitsmechanismus der Kern von Die Komponenten der Transformer-Architektur sind für die Generierung hochwertiger Texte und Bilder von entscheidender Bedeutung. Aber auch sein Fehler liegt auf der Hand, nämlich dass die Rechenkomplexität mit zunehmender Sequenzlänge quadratisch zunimmt. Dies ist ein lästiges Problem bei der Verarbeitung langer Texte und hochauflösender Bilder.
Um dieses Problem zu lösen, ersetzte diese neue Forschung den Aufmerksamkeitsmechanismus in der traditionellen Architektur durch ein skalierbareres Rückgrat des Zustandsraummodells (SSM) und entwickelte ein Modell namens Diffusion State Space Model (DIFFUSSM) für eine neue Architektur. Diese neue Architektur kann weniger Rechenleistung verbrauchen, um den Bilderzeugungseffekt bestehender Diffusionsmodelle mit Aufmerksamkeitsmodulen zu erreichen oder zu übertreffen und hervorragend hochauflösende Bilder zu erzeugen.

Dank der Veröffentlichung von „Mamba“ letzte Woche erhält das Zustandsraummodell SSM immer mehr Aufmerksamkeit. Der Kern von Mamba ist die Einführung einer neuen Architektur – des „selektiven Zustandsraummodells“, das Mamba in der Sprachmodellierung mit Transformer vergleichbar macht oder es sogar übertrifft. Damals sagte der Papierautor Albert Gu, dass Mambas Erfolg ihm Vertrauen in die Zukunft von SSM gegeben habe. Nun scheint dieses Papier der Cornell University und Apple neue Beispiele für die Anwendungsaussichten von SSM hinzugefügt zu haben.
Shital Shah, leitender Forschungsingenieur bei Microsoft, warnte, dass der Aufmerksamkeitsmechanismus möglicherweise von dem Thron gerissen wird, auf dem er schon lange sitzt.
Rasche Fortschritte auf dem Gebiet der Bilderzeugung wurden durch Denoising Diffusion Probabilistic Models (DDPMs) vorangetrieben. Solche Modelle modellieren den Generierungsprozess als iteratives Entrauschen latenter Variablen, und wenn genügend Entrauschungsschritte durchgeführt werden, sind sie in der Lage, hochauflösende Stichproben zu erzeugen. Die Fähigkeit von DDPMs, komplexe visuelle Verteilungen zu erfassen, macht sie potenziell vorteilhaft für die Erstellung hochauflösender, fotorealistischer Kompositionen.
Erhebliche rechnerische Herausforderungen bestehen weiterhin bei der Skalierung von DDPMs auf höhere Auflösungen. Der größte Engpass ist die Abhängigkeit von der eigenen Aufmerksamkeit beim Erreichen einer High-Fidelity-Generierung. In der U-Nets-Architektur entsteht dieser Engpass durch die Kombination von ResNet mit Aufmerksamkeitsschichten. DDPMs gehen über generative kontradiktorische Netzwerke (GANs) hinaus, erfordern jedoch Aufmerksamkeitsschichten mit mehreren Köpfen. In der Transformer-Architektur ist Aufmerksamkeit die zentrale Komponente und daher entscheidend für die Erzielung modernster Bildsyntheseergebnisse. In beiden Architekturen skaliert die Komplexität der Aufmerksamkeit quadratisch mit der Sequenzlänge, sodass sie bei der Verarbeitung hochauflösender Bilder nicht mehr realisierbar ist.
Der Rechenaufwand hat frühere Forscher dazu veranlasst, Darstellungskomprimierungsmethoden zu verwenden. Hochauflösende Architekturen verwenden häufig Patchifizierung oder Multiskalenauflösung. Durch das Blockieren können grobkörnige Darstellungen erstellt und die Rechenkosten gesenkt werden, allerdings auf Kosten kritischer hochfrequenter räumlicher Informationen und struktureller Integrität. Die Multiskalenauflösung reduziert zwar die Berechnung von Aufmerksamkeitsebenen, reduziert aber auch räumliche Details durch Downsampling und führt zu Artefakten, wenn Upsampling angewendet wird.
DIFFUSSM ist ein Diffusionszustandsraummodell, das den Aufmerksamkeitsmechanismus nicht verwendet und darauf ausgelegt ist, die Probleme zu lösen, die bei der Anwendung des Aufmerksamkeitsmechanismus bei der hochauflösenden Bildsynthese auftreten. DIFFUSSM verwendet im Diffusionsprozess ein Gated State Space Model (SSM). Frühere Studien haben gezeigt, dass das SSM-basierte Sequenzmodell ein effektives und effizientes allgemeines neuronales Sequenzmodell ist. Durch die Übernahme dieser Architektur kann der SSM-Kern in die Lage versetzt werden, feinkörnigere Bilddarstellungen zu verarbeiten, wodurch globale Kacheln oder Ebenen mit mehreren Maßstäben entfallen. Um die Effizienz weiter zu verbessern, verwendet DIFFUSSM eine Sanduhrarchitektur in den dichten Komponenten des Netzwerks.
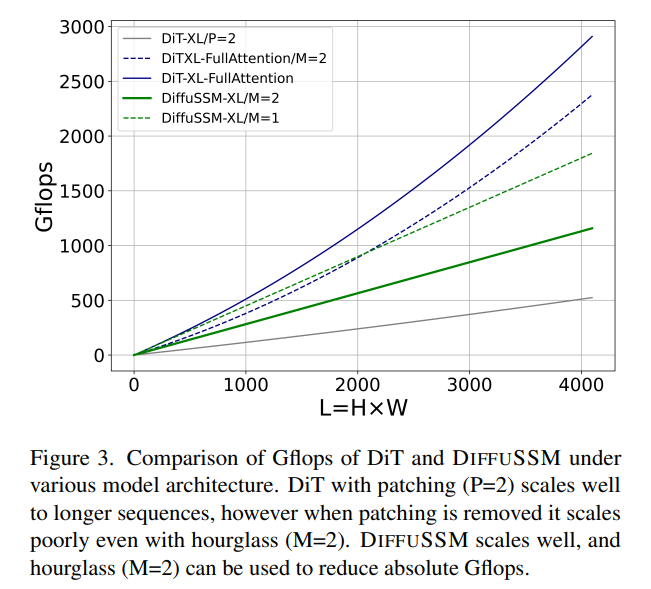
Die Autoren überprüften die Leistung von DIFFUSSM bei verschiedenen Auflösungen. Experimente auf ImageNet zeigen, dass DIFFUSSM bei verschiedenen Auflösungen konsistente Verbesserungen bei FID, sFID und Inception Score mit insgesamt weniger Gflops erzielt.

Link zum Papier: https://arxiv.org/pdf/2311.18257.pdf
Um die ursprüngliche Bedeutung nicht zu ändern, muss der Inhalt ins Chinesische umgeschrieben werden. Das Ziel der Autoren bestand darin, eine Diffusionsarchitektur zu entwerfen, die in der Lage ist, weitreichende Wechselwirkungen mit hoher Auflösung zu lernen, ohne dass eine „Längenreduzierung“ wie Blockierung erforderlich ist. Ähnlich wie DiT funktioniert dieser Ansatz, indem er das Bild flacher macht und es als Sequenzmodellierungsproblem behandelt. Im Gegensatz zu Transformer verwendet diese Methode jedoch subquadratische Berechnungen bei der Verarbeitung der Länge dieser Sequenz. DIFFUSSM ist die Kernkomponente eines Gated-Bidirektional-SSM, der für die Verarbeitung langer Sequenzen optimiert ist. Um die Effizienz zu verbessern, führte der Autor die Sanduhrarchitektur in der MLP-Schicht ein. Dieses Design erweitert und verkleinert abwechselnd die Sequenzlänge um den bidirektionalen SSM herum, während die Sequenzlänge im MLP selektiv reduziert wird. Die vollständige Modellarchitektur ist in Abbildung 2 dargestellt
Im Einzelnen erhält jede Sanduhrschicht eine verkürzte und abgeflachte Eingabesequenz I ∈ R^(J×D), wobei M = L/J das Reduktionsverhältnis ist Erweiterung. Gleichzeitig wird der gesamte Block, einschließlich des bidirektionalen SSM, auf der ursprünglichen Länge berechnet, wodurch der globale Kontext voll ausgenutzt wird. σ wird in diesem Artikel zur Darstellung der Aktivierungsfunktion verwendet. Für l ∈ {1 . L}, wobei j = ⌊l/M⌋, m = l mod M, D_m = 2D/M, lautet die Berechnungsgleichung jeweils wie folgt: Layer Integrieren Sie Gated SSM-Blöcke mithilfe von Skip-Verbindungen. Die Autoren integrieren eine Kombination aus Klassenbezeichnung y ∈ R^(L×1) und Zeitschritt t ∈ R^(L×1) an jeder Stelle, wie in Abbildung 2 dargestellt. 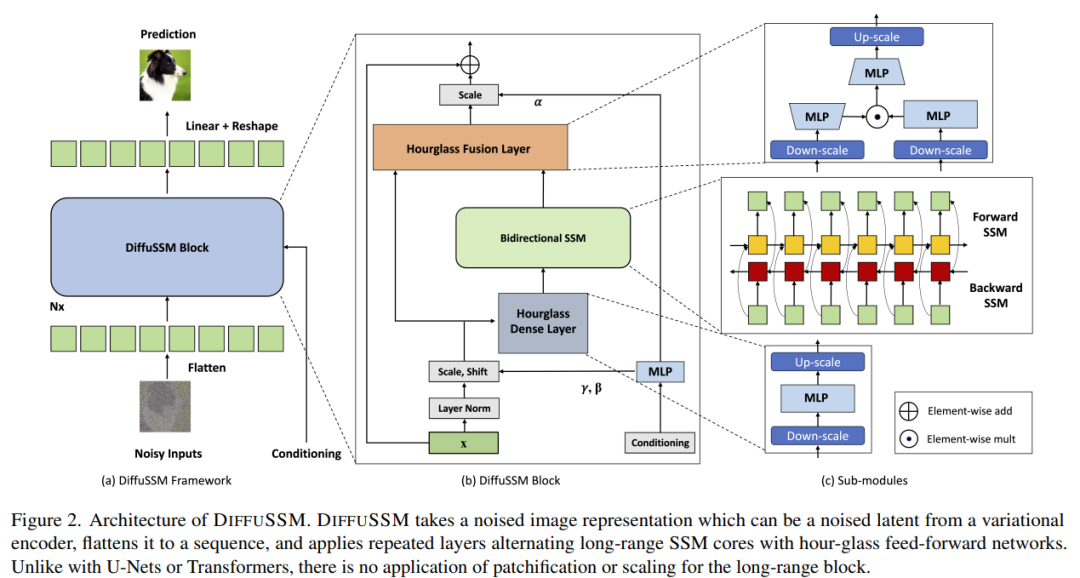
Parameter: Die Anzahl der Parameter im DIFFUSSM-Block wird hauptsächlich durch die lineare Transformation W bestimmt, die 9D^2 + 2MD^2 Parameter enthält. Wenn M = 2, ergibt dies 13D^2 Parameter. Der DiT-Transformationsblock verfügt über 12D^2-Parameter in seiner Kerntransformationsschicht, die DiT-Architektur verfügt jedoch über viel mehr Parameter in anderen Schichtkomponenten (adaptive Schichtnormalisierung). Die Forscher passten die Parameter in ihren Experimenten durch den Einsatz zusätzlicher DIFFUSSM-Schichten an.
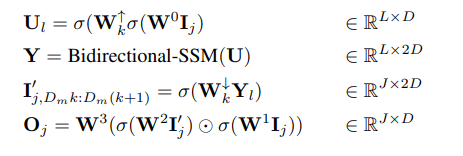 FLOPs: Abbildung 3 vergleicht Gflops zwischen DiT und DIFFUSSM. Die gesamten Flops einer DIFFUSSM-Schicht betragen
FLOPs: Abbildung 3 vergleicht Gflops zwischen DiT und DIFFUSSM. Die gesamten Flops einer DIFFUSSM-Schicht betragen
, wobei α die durch FFT implementierte Konstante darstellt. Dies ergibt ungefähr 7,5LD^2 Gflops, wenn M = 2 und lineare Schichten die Berechnung dominieren. Wenn im Vergleich dazu in dieser Sanduhr-Architektur Selbstaufmerksamkeit in voller Länge anstelle von SSM verwendet wird, gibt es zusätzliche 2DL^2-Flops.
Betrachten Sie zwei experimentelle Szenarien: 1) D ≈ L = 1024, was zu zusätzlichen 2LD^2 Flops führt, 2) 4D ≈ L = 4096, was zu 8LD^2 Flops führt und die Kosten erheblich erhöht . Da die Kernkosten von bidirektionalem SSM im Vergleich zu den Kosten für die Nutzung von Aufmerksamkeit gering sind, funktioniert die Verwendung einer Sanduhrarchitektur für aufmerksamkeitsbasierte Modelle nicht. Wie bereits erwähnt, vermeidet DiT diese Probleme durch die Verwendung von Chunking auf Kosten der komprimierten Darstellung. 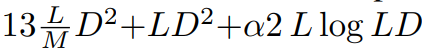 Experimentelle Ergebnisse
Experimentelle Ergebnisse
Wenn „Keine“ verwendet wird. Bei der Führung durch einen Klassifikator übertrifft DIFFUSSM andere Diffusionsmodelle sowohl im FID als auch im sFID, indem es die beste Punktzahl des vorherigen potenziellen Diffusionsmodells ohne Klassifikatorführung von 9,62 auf 9,07 reduziert und gleichzeitig die Anzahl der verwendeten Trainingsschritte reduziert auf 1/3 oder so. Bezogen auf die insgesamt trainierten Gflops reduziert das unkomprimierte Modell die Gesamt-Gflops im Vergleich zu DiT um 20 %. Wenn eine klassifikatorfreie Führung eingeführt wird, erreicht das Modell den besten sFID-Score unter allen DDPM-basierten Modellen und übertrifft damit andere hochmoderne Strategien, was darauf hindeutet, dass von DIFFUSSM erzeugte Bilder robuster gegenüber räumlichen Verzerrungen sind.
Der FID-Score von DIFFUSSM übertrifft alle Modelle bei Verwendung einer klassifikatorfreien Führung und weist im Vergleich zu DiT einen relativ kleinen Abstand (0,01) auf. Beachten Sie, dass DIFFUSSM, das mit einer Reduzierung der Gesamt-Gflops um 30 % trainiert wurde, DiT bereits übertrifft, ohne eine klassifikatorfreie Anleitung anzuwenden. U-ViT ist eine weitere Transformer-basierte Architektur, verwendet jedoch eine UNet-basierte Architektur mit Long-Hop-Verbindungen zwischen Blöcken. U-ViT verwendet weniger FLOPs und bietet eine bessere Leistung bei einer Auflösung von 256×256, aber das ist im 512×512-Datensatz nicht der Fall. Der Autor vergleicht hauptsächlich mit DiT. Aus Gründen der Fairness wird dieser weitreichende Zusammenhang nicht übernommen. Der Autor glaubt, dass die Idee, U-Vit zu übernehmen, sowohl für DiT als auch für DIFFUSSM von Vorteil sein könnte. Die Autoren führen außerdem Vergleiche mit Benchmarks mit höherer Auflösung unter Verwendung einer klassifikatorfreien Anleitung durch. Die Ergebnisse von DIFFUSSM sind relativ stark und kommen den hochaufgelösten Modellen auf dem neuesten Stand der Technik nahe, sind DiT auf sFID nur unterlegen und erzielen vergleichbare FID-Werte. DIFFUSSM wurde auf 302 Millionen Bildern trainiert, beobachtete 40 % der Bilder und verwendete 25 % weniger Gflops als DiT des Vergleichs sind in Tabelle 2 aufgeführt. Die Untersuchungen der Autoren ergaben, dass DIFFUSSM mit vergleichbaren Trainingsbudgets wie LDM vergleichbare FID-Werte (Unterschiede von -0,08 und 0,07) erzielte. Dieses Ergebnis unterstreicht die Anwendbarkeit von DIFFUSSM auf verschiedene Benchmarks und verschiedene Aufgaben. Ähnlich wie LDM übertrifft diese Methode ADM bei der LSUN-Bedrooms-Aufgabe nicht, da sie nur 25 % des gesamten Trainingsbudgets von ADM beansprucht. Für diese Aufgabe übertrifft das beste GAN-Modell das Diffusionsmodell in der Modellkategorie Weitere Einzelheiten finden Sie im Originalpapier
Das obige ist der detaillierte Inhalt vonMambas beliebtes SSM erregt die Aufmerksamkeit von Apple und Cornell: Geben Sie das Ablenkungsmodell auf. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So erstellen Sie eine Datenbank in MySQL
So erstellen Sie eine Datenbank in MySQL
 Minidump-Bluescreen
Minidump-Bluescreen
 Was sind die Unterschiede zwischen C++ und der C-Sprache?
Was sind die Unterschiede zwischen C++ und der C-Sprache?
 Detaillierte Erläuterung des Ereignisses onbeforeunload
Detaillierte Erläuterung des Ereignisses onbeforeunload
 Methode zur Reparatur von Datenbankzweifeln
Methode zur Reparatur von Datenbankzweifeln
 Auf welcher Plattform kann ich Ripple-Coins kaufen?
Auf welcher Plattform kann ich Ripple-Coins kaufen?
 Welche Rundungsmethoden gibt es in SQL?
Welche Rundungsmethoden gibt es in SQL?
 Was sind die Marquee-Parameter?
Was sind die Marquee-Parameter?

























