


Wie weit kommt man allein mit visuellen (Pixel-)Modellen? Ein neuer Artikel der UC Berkeley und der Johns Hopkins University untersucht dieses Problem und demonstriert das Potenzial von Large Vision Models (LVM) für eine Vielzahl von CV-Aufgaben.
In jüngster Zeit sind große Sprachmodelle (LLM) wie GPT und LLaMA weltweit populär geworden.
Der Aufbau großer Visionsmodelle (LVM) ist ein großes Problem. Was brauchen wir, um dieses Ziel zu erreichen? Die Ideen, die visuelle Sprachmodelle wie
LLaVA liefern, sind interessant und es lohnt sich, sie zu erkunden, aber gemäß den Gesetzen des Tierreichs wissen wir bereits, dass visuelle Fähigkeiten und Sprachfähigkeiten nicht miteinander zusammenhängen. Viele Experimente haben beispielsweise gezeigt, dass die visuelle Welt nichtmenschlicher Primaten der des Menschen sehr ähnlich ist, obwohl ihre Sprachsysteme „identisch“ mit denen des Menschen sind.
Ein aktueller Artikel diskutiert die Antwort auf eine andere Frage: Wie weit können wir allein mit Pixeln kommen? Das Papier wurde von Forschern der University of California, Berkeley und der Johns Hopkins University verfasst .com/lvm.html

quantisierten
Token-Zeichenfolge zuzuordnen.Die ursprüngliche Bildquelle stammt vom Twitter-Konto: https://twitter.com/YutongBAI1002/status/1731512110247473608
Unter den Autoren des Papiers sind die letzten drei erfahrene Wissenschaftler auf diesem Gebiet Lebenslauf an der UC Berkeley. Professor Trevor Darrell ist Gründungs-Co-Direktor von BAIR, dem Berkeley Artificial Intelligence Research Laboratory, Professor Jitendra Malik gewann den IEEE Computer Pioneer Award 2019 und Professor Alexei A. Efros ist vor allem für seine Nearest-Neighbor-Forschung bekannt.

Von links nach rechts: Trevor Darrell, Jitendra Malik, Alexei A. Efros.
Einführung in die Methode
Der Artikel verwendet einen zweistufigen Ansatz: 1) Training eines großen visuellen Tokenizers (der an einem einzelnen Bild arbeitet), der in der Lage ist, jedes Bild in eine Reihe visueller Token umzuwandeln; 2) Training an; Visuelle Sätze Autoregressives Transformatormodell, jeder Satz wird als eine Reihe von Token dargestellt. Die Methode ist in Abbildung 2 dargestellt Tokenizer wie VQVAE oder VQGAN fassen Bildmerkmale in einem Raster aus diskreten Token zusammen. Dieser Artikel übernimmt die letztere Methode und verwendet das VQGAN-Modell zum Generieren semantischer Token.
Das LVM-Framework umfasst Codierungs- und Decodierungsmechanismen und verfügt auch über Quantisierungsschichten, wobei der Encoder und Decoder mit Faltungsschichten aufgebaut sind. Der Encoder ist mit mehreren Downsampling-Modulen ausgestattet, um die räumlichen Abmessungen der Eingabe zu verkleinern, während der Decoder mit einer Reihe gleichwertiger Upsampling-Module ausgestattet ist, um das Bild auf seine ursprüngliche Größe zurückzusetzen. Für ein bestimmtes Bild generiert der VQGAN-Tokenizer 256 diskrete Token. 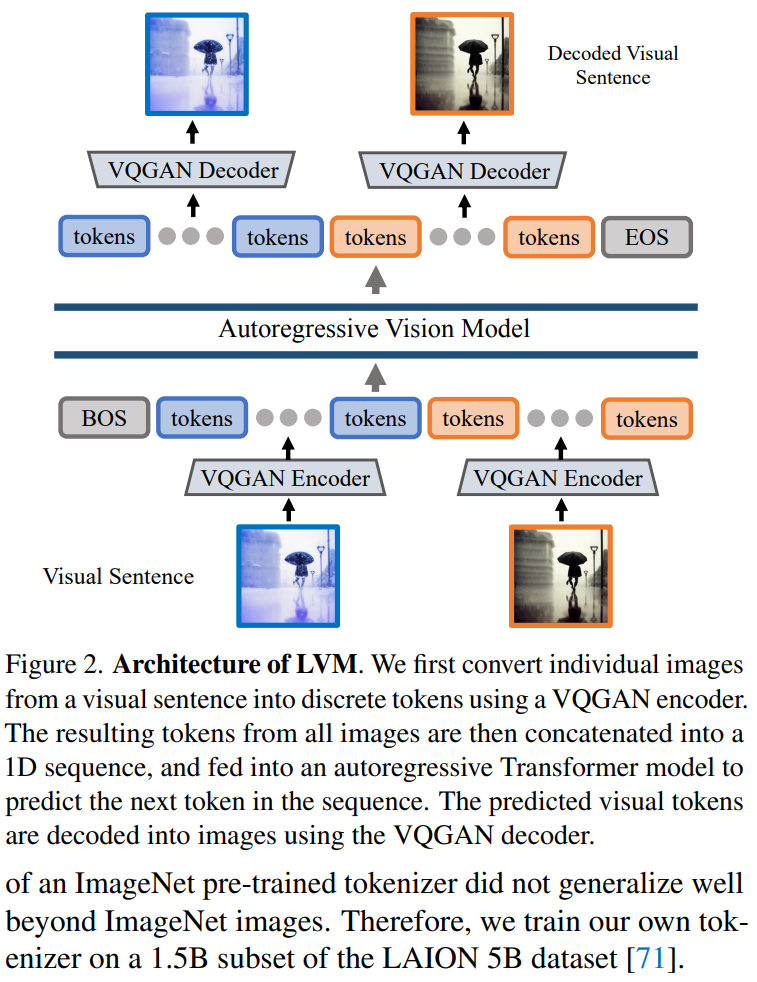
Die Funktion visueller Sätze besteht darin, verschiedene visuelle Daten in eine einheitliche Bildsequenzstruktur zu formatieren
Implementierungsdetails. Nach der Tokenisierung jedes Bildes im visuellen Satz in 256 Token werden diese in diesem Artikel zu einer 1D-Token-Sequenz verkettet. In Bezug auf die visuelle Token-Sequenz ist das Transformer-Modell in diesem Artikel tatsächlich dasselbe wie das autoregressive Sprachmodell, sodass sie die Transformer-Architektur von LLaMA übernehmen. Dieser Inhalt verwendet eine Kontextlänge von 4096 Token, ähnlich dem Sprachmodell. Fügen Sie am Anfang jedes visuellen Satzes ein [BOS]-Token (Satzanfang) und am Ende ein [EOS]-Token (Satzende) hinzu und verwenden Sie während des Trainings Sequenzspleißen, um die Effizienz zu verbessern
Dieses Papier schneidet gut ab Für den gesamten UVDv1-Datensatz (4200 100 Millionen Token) wurden insgesamt 4 Modelle mit unterschiedlichen Parameterzahlen trainiert: 300 Millionen, 600 Millionen, 1 Milliarde und 3 Milliarden.
 Die experimentellen Ergebnisse müssen neu geschrieben werden
Die experimentellen Ergebnisse müssen neu geschrieben werden
Die Studie führte Experimente zur Bewertung des Modells durch. Um das Geschäft zu erweitern, müssen wir neue Marktchancen finden. Wir planen, unsere Produktpalette weiter auszubauen, um der wachsenden Nachfrage gerecht zu werden. Gleichzeitig werden wir Marketingstrategien stärken und die Markenbekanntheit steigern. Durch die aktive Teilnahme an Branchenmessen und Werbeaktivitäten werden wir uns bemühen, mehr Kundengruppen zu erschließen. Wir glauben, dass wir durch diese Bemühungen größere Erfolge erzielen und unsere Fähigkeiten und die Fähigkeit, eine Vielzahl von Aufgaben zu verstehen und zu beantworten, kontinuierlich steigern können. Um unser Geschäft auszubauen, müssen wir neue Marktchancen finden. Wir planen, unsere Produktpalette weiter auszubauen, um der wachsenden Nachfrage gerecht zu werden. Gleichzeitig werden wir Marketingstrategien stärken und die Markenbekanntheit steigern. Durch die aktive Teilnahme an Branchenmessen und Werbeaktivitäten werden wir uns bemühen, mehr Kundengruppen zu erschließen. Wir glauben, dass wir durch diese Bemühungen größere Erfolge erzielen und nachhaltiges Wachstum erzielen können. Wie in Abbildung 3 dargestellt, untersuchte die Studie zunächst den Trainingsverlust von LVMs unterschiedlicher Größe Das größere Modell wies bei allen Aufgaben eine geringere Komplexität auf, was darauf hindeutet, dass die Gesamtleistung des Modells auf eine Reihe nachgelagerter Aufgaben übertragen werden kann.
Wie in Abbildung 5 dargestellt, hat jede Datenkomponente einen wichtigen Einfluss auf nachgelagerte Aufgaben. LVM profitiert nicht nur von größeren Datenmengen, sondern verbessert sich auch mit der Vielfalt des Datensatzes
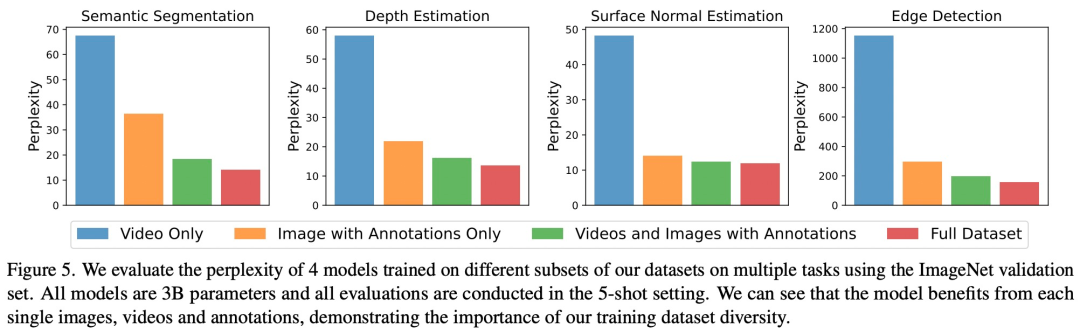
Um den Inhalt umzuschreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache in Chinesisch umgeschrieben werden. Der Originalsatz sollte erscheinen
Um die Fähigkeit von LVM zu testen, verschiedene Eingabeaufforderungen zu verstehen, wurde in dieser Studie zunächst ein Bewertungsexperiment mit LVM an einer Sequenzbegründungsaufgabe durchgeführt. Unter diesen ist die Eingabeaufforderung sehr einfach: Stellen Sie dem Modell eine Sequenz von 7 Bildern zur Verfügung und bitten Sie es, das nächste Bild vorherzusagen. Die experimentellen Ergebnisse müssen wie in Abbildung 6 unten dargestellt umgeschrieben werden:

Die Studie wird ebenfalls angezeigt Eine Liste von Elementen in der Kategorie. Behandeln Sie sie als Sequenz und lassen Sie LVM Bilder derselben Kategorie vorhersagen. Die experimentellen Ergebnisse müssen wie in Abbildung 15 unten dargestellt umgeschrieben werden:

Also, wie viel Kontext ist erforderlich, um genau zu sein Nachfolgende Frames vorhersagen?
In dieser Studie bewerten wir die Frame-Generierungsstörung unseres Modells, indem wir kontextbezogene Eingabeaufforderungen unterschiedlicher Länge (1 bis 15 Frames) geben. Die Ergebnisse zeigen, dass sich die Verwirrung mit zunehmender Anzahl der Bilder allmählich verbessert. Die spezifischen Daten sind in Abbildung 7 unten dargestellt. Die Verwirrung verbesserte sich deutlich von Frame 1 bis Frame 11 und stabilisierte sich dann (62,1 → 48,4). Leistung, indem komplexere Eingabeaufforderungsstrukturen wie Analogie-Eingabeaufforderungen bewertet werden.
Abbildung 8 unten zeigt die qualitativen Ergebnisse von Analogie-Eingabeaufforderungen für eine Reihe von Aufgaben: schneidet in fast allen Aufgaben besser ab als die vorherige Methode 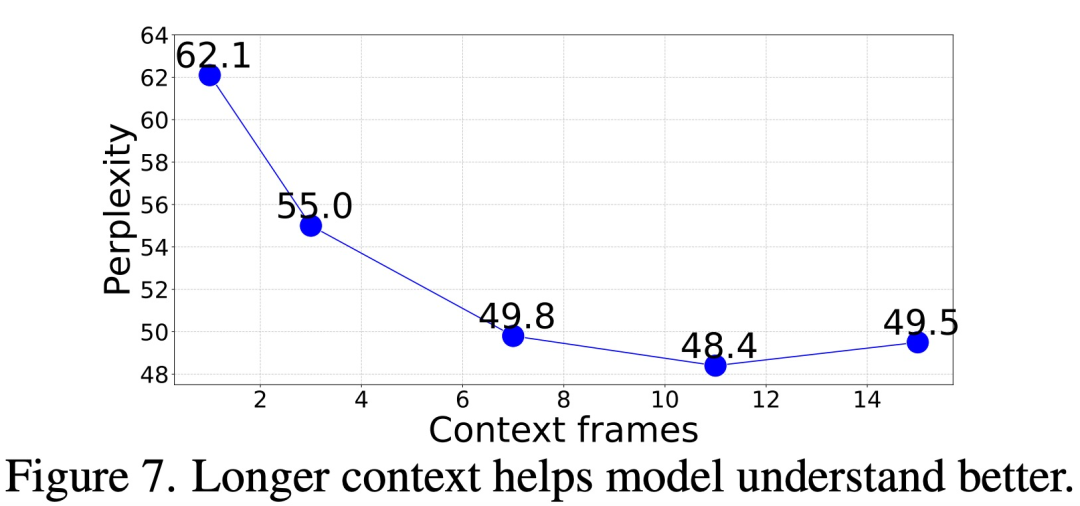
Synthetische Aufgaben. Abbildung 9 zeigt die Ergebnisse der Kombination mehrerer Aufgaben mit einer einzigen Eingabeaufforderung. Wir müssen neue Marktchancen finden. Wir planen, unsere Produktpalette weiter auszubauen, um der wachsenden Nachfrage gerecht zu werden. Gleichzeitig werden wir Marketingstrategien stärken und die Markenbekanntheit steigern. Durch die aktive Teilnahme an Branchenmessen und Werbeaktivitäten werden wir uns bemühen, mehr Kundengruppen zu erschließen. Wir glauben, dass wir durch diese Bemühungen größere Erfolge erzielen und weiteres Wachstum erzielen können. Abbildung 10 unten zeigt einige solcher Eingabeaufforderungen, die gut funktionieren.
Abbildung 11 unten zeigt einige Eingabeaufforderungen, die sich bei diesen Aufgaben möglicherweise nur schwer mit Worten beschreiben lassen.

Das obige ist der detaillierte Inhalt vonDie UC Berkeley hat erfolgreich ein großes allgemeines visuelles Argumentationsmodell entwickelt, und drei hochrangige Wissenschaftler haben sich zusammengeschlossen, um an der Forschung teilzunehmen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Antivirus für Apple-Handys
Antivirus für Apple-Handys
 Tutorial zum Kauf und Verkauf von Bitcoin auf Huobi.com
Tutorial zum Kauf und Verkauf von Bitcoin auf Huobi.com
 Was bedeutet das Formatieren eines Mobiltelefons?
Was bedeutet das Formatieren eines Mobiltelefons?
 Was sind die Python-Bibliotheken für künstliche Intelligenz?
Was sind die Python-Bibliotheken für künstliche Intelligenz?
 MySQL-Ausnahmelösung
MySQL-Ausnahmelösung
 Welches Format ist m4a?
Welches Format ist m4a?
 Zusammenfassung der Java-Grundkenntnisse
Zusammenfassung der Java-Grundkenntnisse
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



