


Meta hat kürzlich ein KI-Klangerzeugungsmodell namens Audiobox auf den Markt gebracht. Dieses Modell kann sowohl Sprach- als auch Texteingaben empfangen, und Benutzer können den erforderlichen Ton durch Sprach- und Textbeschreibung generieren
Es wird berichtet, dass dieses Modell auf dem von Meta im Juni dieses Jahres eingeführten Voicebox-KI-Modell basiert und in der Lage sein soll, verschiedene Umgebungsgeräusche und natürliche Konversationssprache zu erzeugen, und Funktionen zur Audioerzeugung und -bearbeitung integriert, sodass Benutzer dies frei tun können Generieren Sie den Ton, den Sie benötigen.
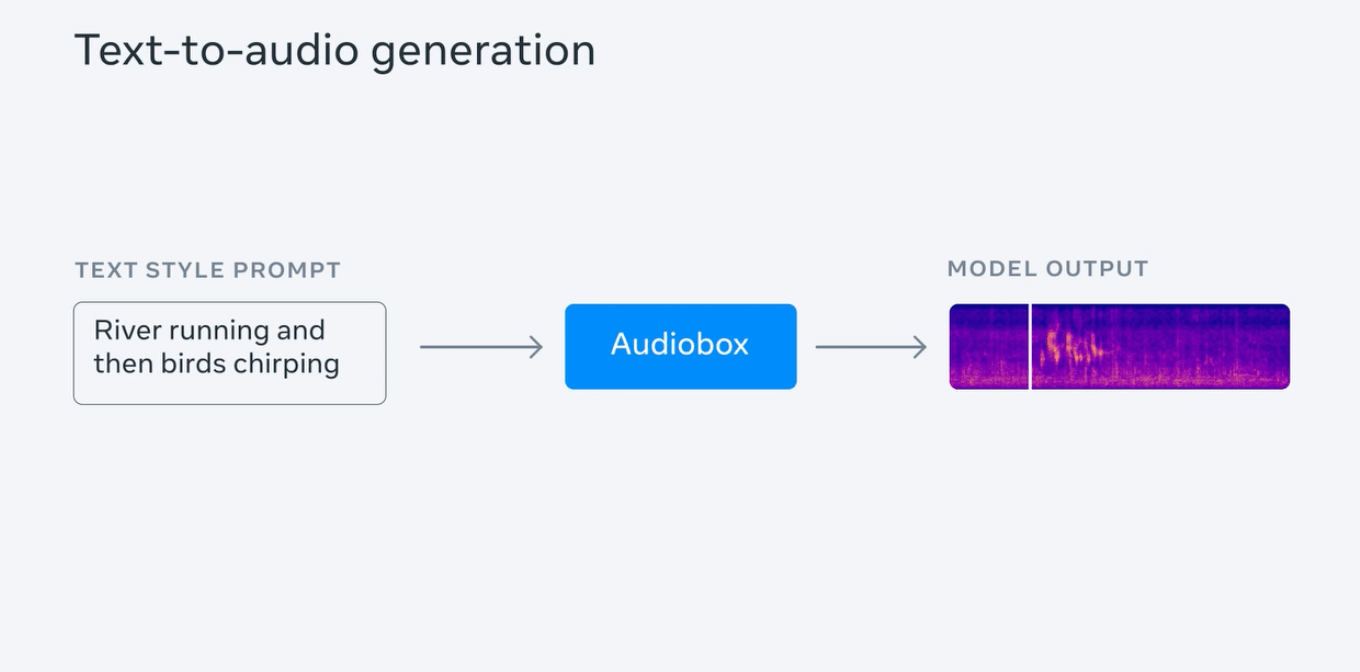
Meta sagte, dass die Erzeugung hochwertiger Audiodaten eine große Anzahl von Audiobibliotheken und umfassendes Fachwissen erfordert, es für die Öffentlichkeit jedoch schwierig ist, an diese Ressourcen zu gelangen. Das Unternehmen hat dieses Modell eingeführt, um die Schwelle für die Tonerzeugung zu senken und sie einfacher zu machen Jeder kann Videos und Spiele für andere Anwendungsszenarien erstellen.
IT House stellte fest, dass dieses Audiobox-Modell auf dem „Guided Sound“-Mechanismus von Voicebox basiert, um die Generierung von Zielaudio zu erleichtern, und mit der „Flow-Matching“-Diffusionsmodell-Generierungsmethode zusammenarbeitet, um eine „Audio-Infilling“-Funktion zur Generierung von Multi zu erreichen -geschichtetes Audio.
Meta-Test generiert Regen-Audio mit Gewittergeräuschen und gibt eine Reihe von Aufforderungssätzen zur Demonstration ein, wie zum Beispiel „Das Geräusch von fließendem Wasser wird von Vogelgezwitscher begleitet“, „Eine junge Frau spricht in einem hohen und schnellen Rhythmus“ usw .; es testet auch die gleichzeitige Eingabe von Audio- und Textansagen von Personen, um Sprache mit Emotionen („traurig und langsam“) und Hintergrundgeräuschen (in einer Kirche) zu erzeugen.
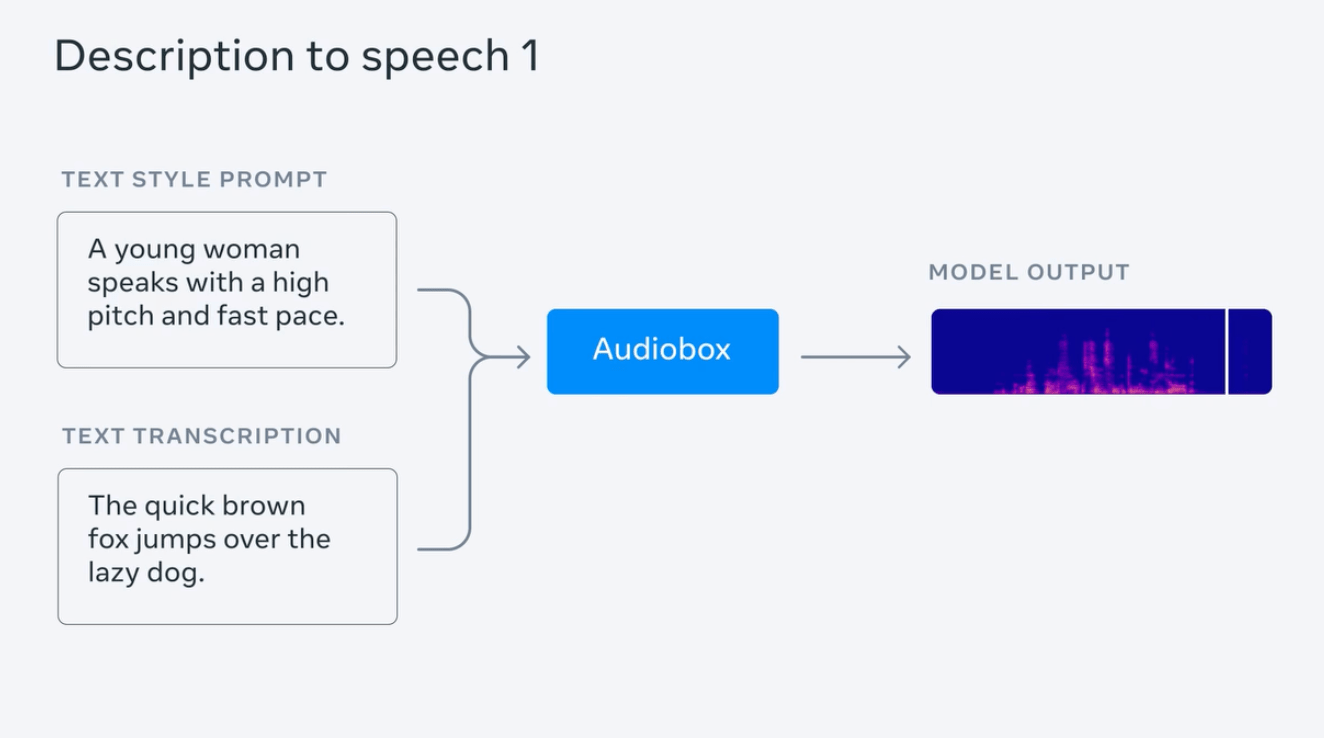
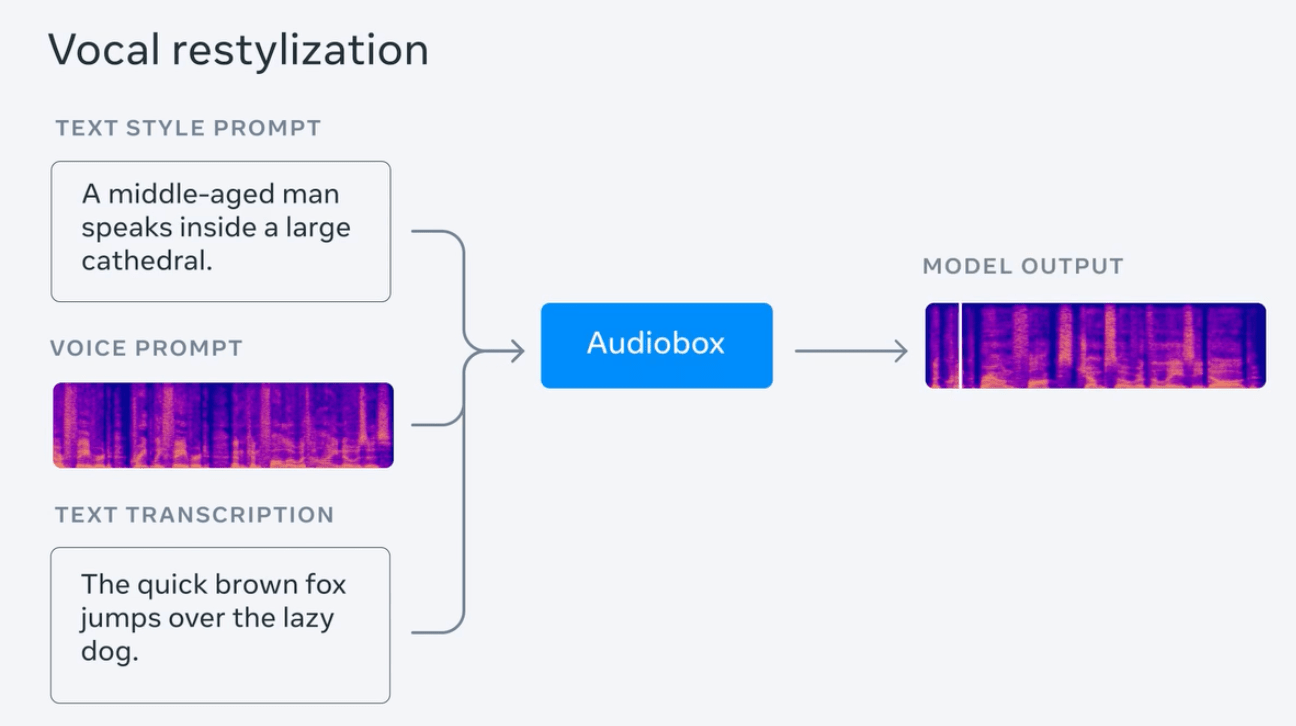
Meta behauptet, dass Audiobox AudioLDM2, VoiceLDM und TANGO in Bezug auf Klangqualität und „Genauigkeit der generierten Inhalte“ erfolgreich besiegt und damit die besten vorhandenen Modelle zur Audioerzeugung übertroffen hat.
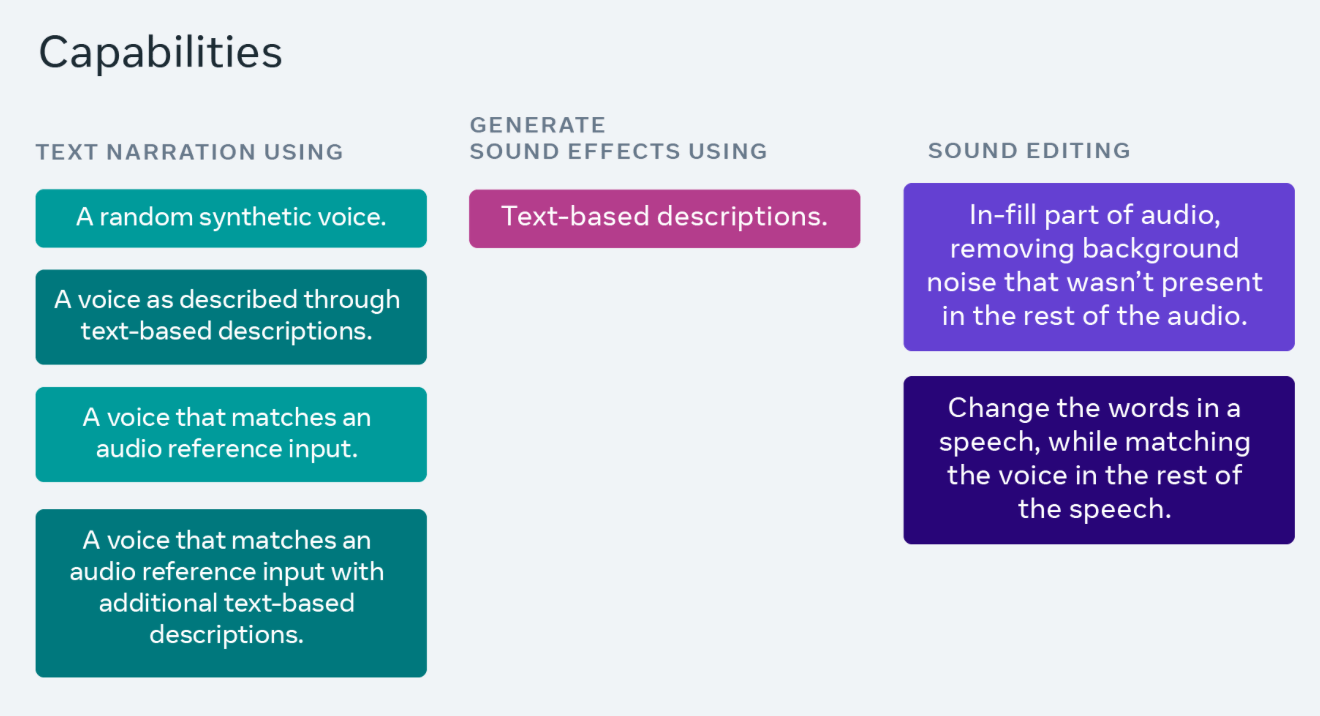
Audiobox steht derzeit bestimmten Forschern und Wissenschaftlern zur Testnutzung offen, um die Qualität und Sicherheit des Modells zu testen. Meta gibt an, dass sie planen, „das Modell in ein paar Wochen vollständig der Öffentlichkeit zugänglich zu machen“.
Das obige ist der detaillierte Inhalt vonMeta bringt das KI-Audiomodell Audiobox auf den Markt, das die gleichzeitige Sprach- und Texteingabe unterstützt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So laden Sie Binance herunter
So laden Sie Binance herunter
 Der Unterschied zwischen Win7 32-Bit und 64-Bit
Der Unterschied zwischen Win7 32-Bit und 64-Bit
 So verwenden Sie die Shift-Hintertür
So verwenden Sie die Shift-Hintertür
 Welche anmeldefreien Plätze gibt es in China?
Welche anmeldefreien Plätze gibt es in China?
 vlookup gleicht zwei Datenspalten ab
vlookup gleicht zwei Datenspalten ab
 Lösung für fehlgeschlagene Verbindung zwischen wsus und Microsoft-Server
Lösung für fehlgeschlagene Verbindung zwischen wsus und Microsoft-Server
 Welche Videoformate gibt es?
Welche Videoformate gibt es?
 Waffenkammerkiste
Waffenkammerkiste








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



