


Multimodale Kontrastdarstellung (MCR) zielt darauf ab, Eingaben aus verschiedenen Modalitäten in einen semantisch ausgerichteten gemeinsamen Raum zu kodieren Erzielen Sie bei vielen nachgelagerten Aufgaben erhebliche Verbesserungen, diese Methoden basieren jedoch stark auf umfangreichen, qualitativ hochwertigen gepaarten Daten eine multimodale kontrastive Darstellungslernmethode, die keine gepaarten Daten erfordert und äußerst effizient im Training ist.
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2305.14381
C-MCR-Projekt-Homepage-Link: https://c-mcr.github.io /C- MCR/
Modell- und Codeadresse: https://github.com/MCR-PEFT/C-MCR
Diese Methode verbindet verschiedene Voreinstellungen durch Pivot-Modalitäten, ohne gepaarte Daten zu verwenden Darstellungen lernten wir leistungsstarke audiovisuelle und 3D-Punktwolken-Textdarstellungen und erzielten SOTA-Ergebnisse bei mehreren Aufgaben wie audiovisuellem Abruf, Schallquellenlokalisierung und 3D-Objektklassifizierung.
Einführung
Multimodale kontrastive Darstellung (MCR) zielt darauf ab, Daten aus verschiedenen Modalitäten in einem einheitlichen semantischen Raum abzubilden. Mit dem großen Erfolg von CLIP im visuell-linguistischen Bereich ist das Erlernen kontrastiver Darstellungen zwischen mehr modalen Kombinationen zu einem heißen Forschungsthema geworden, das immer mehr Aufmerksamkeit auf sich zieht.Die Generalisierungsfähigkeit bestehender multimodaler kontrastiver Darstellungen profitiert jedoch hauptsächlich von einer großen Anzahl hochwertiger Datenpaare. Dies schränkt die Entwicklung kontrastiver Darstellungen für Modalitäten, für die es an umfangreichen, qualitativ hochwertigen Daten mangelt, erheblich ein. Beispielsweise ist die semantische Korrelation zwischen Audio- und visuellen Datenpaaren oft nicht eindeutig, und gepaarte Daten zwischen 3D-Punktwolken und Text sind rar und schwer zu erhalten.
Wir haben jedoch beobachtet, dass diese Modalkombinationen, denen gepaarte Daten fehlen, häufig über eine große Menge hochwertiger gepaarter Daten mit demselben Zwischenmodus verfügen. Beispielsweise gibt es im audiovisuellen Bereich, obwohl die Qualität audiovisueller Daten unzuverlässig ist, eine große Menge hochwertiger gepaarter Daten zwischen Audiotext und Textvisuell.
Auch wenn die Verfügbarkeit von 3D-Punktwolken-Text-Paarungsdaten begrenzt ist, sind 3D-Punktwolken-Bild- und Bild-Text-Daten reichlich vorhanden. Diese Hub-Modi können weitere Verbindungen zwischen Modi herstellen.
Angesichts der Tatsache, dass Modalitäten mit einer großen Menge gepaarter Daten häufig bereits über vorab trainierte kontrastive Darstellungen verfügen, versucht dieser Artikel direkt, die kontrastiven Darstellungen zwischen verschiedenen Modalitäten über die Hub-Modalität zu verbinden und so eine bessere Darstellung für Modalitäten bereitzustellen, denen es an gepaarten Daten mangelt Daten. Kombinationen konstruieren neue kontrastierende Darstellungsräume.
Mit der Concatenated Multimodal Contrast Representation (C-MCR) können Sie durch überlappende Modi Verbindungen zu einer großen Anzahl vorhandener multimodaler Kontrastdarstellungen herstellen und so Ausrichtungsbeziehungen zwischen einem breiteren Spektrum von Modalitäten erlernen. Dieser Lernprozess erfordert keine gepaarten Daten und ist äußerst effizient.
C-MCR hat zwei wesentliche Vorteile:
Der Fokus liegt auf Flexibilität:
C-MCRs Fähigkeit liegt darin, Modalitätslernen bereitzustellen kontrastierende Darstellungen, denen direkte Paarungen fehlen. Aus einer anderen Perspektive behandelt C-MCR jeden vorhandenen multimodalen Kontrastdarstellungsraum als Knoten und überlappende Modalitäten als wichtige Hub-Modalitäten. Durch die Verbindung einzelner isolierter multimodaler Kontrastdarstellungsräume sind wir in der Lage um das erworbene multimodale Alignment-Wissen flexibel zu erweitern und ein breiteres Spektrum intermodaler Kontrastdarstellungen zu erschließen
2. Effizienz:
Da nur C-MCR Es ist notwendig, Verbindungen für die bestehende Darstellung aufzubauen Platz, sodass nur zwei einfache Mapper erlernt werden müssen und ihre Trainingsparameter und Trainingskosten äußerst niedrig sind.
In diesem Experiment haben wir Text als Drehscheibe verwendet, um die Darstellungsräume für visuellen Text (CLIP) und Text-Audio (CLAP) zu vergleichen und schließlich eine hochwertige visuelle Audio-Darstellung zu erhalten
Ähnlicherweise von Beim Vergleich der bildverbundenen Text-Visual- (CLIP) und der Visual-3D-Punktwolke (ULIP) zur Darstellung des Raums kann auch eine Reihe von 3D-Punktwolken-Text-Vergleichsdarstellungen erhalten werden
Methode
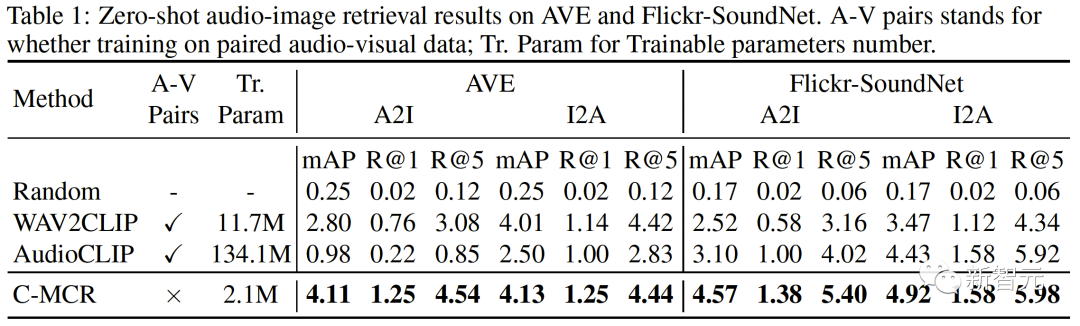
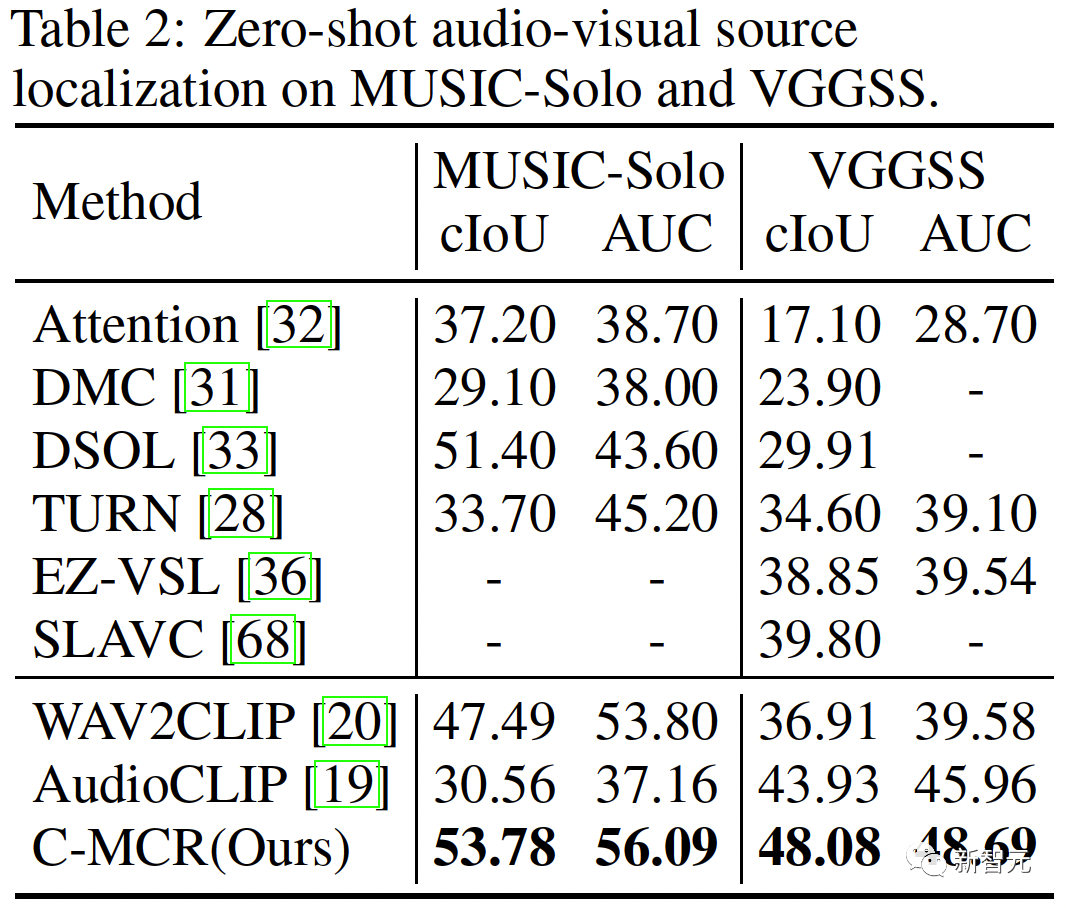
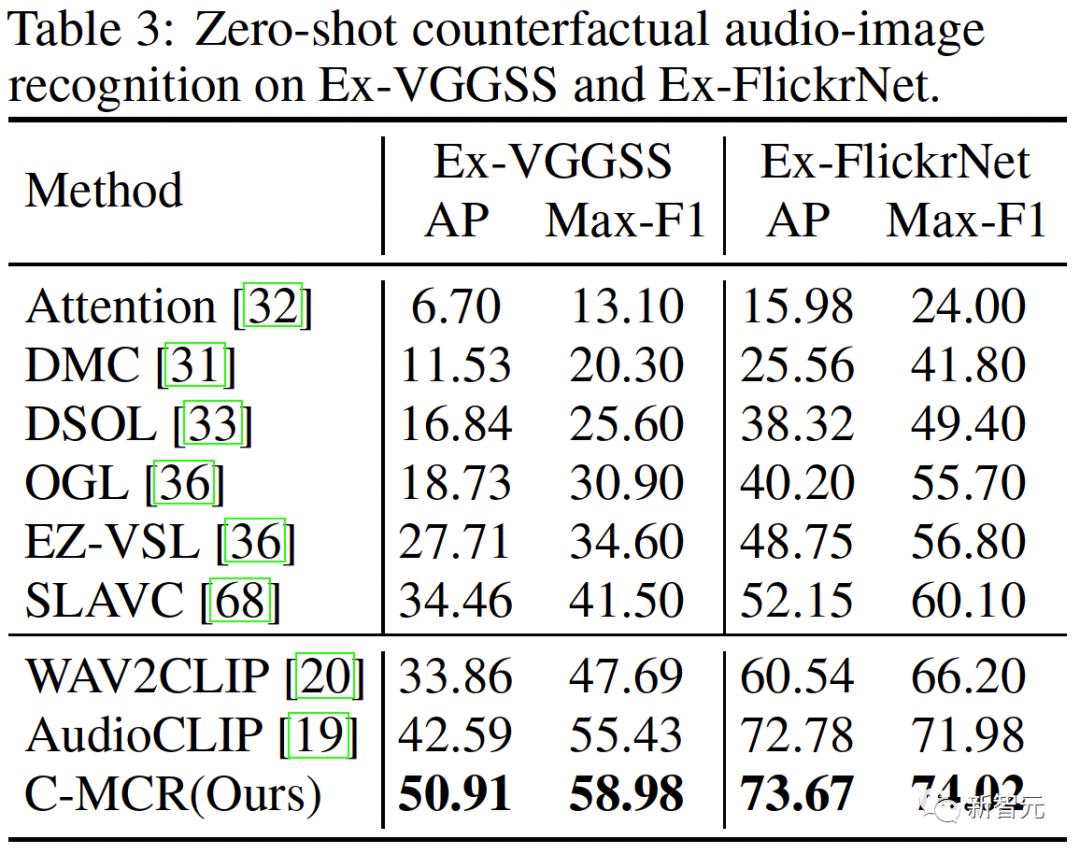
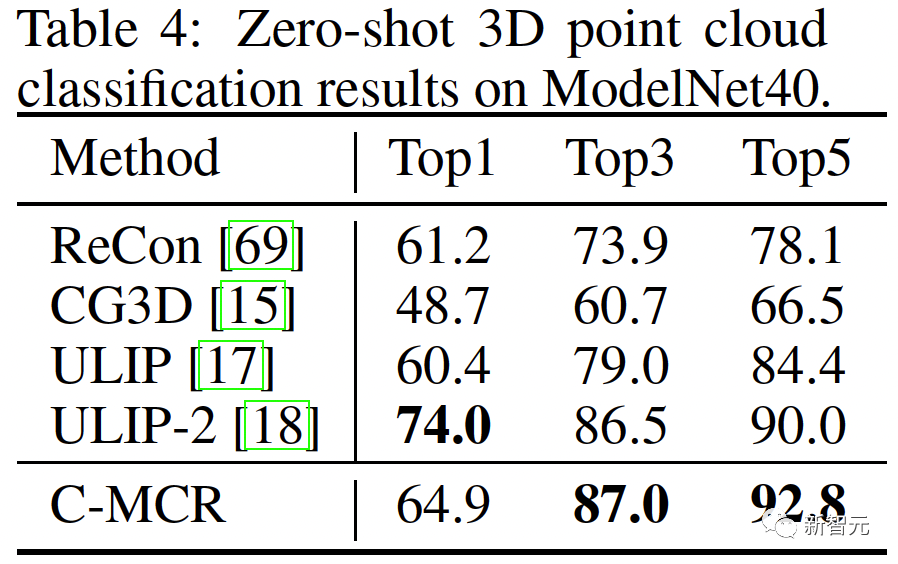
Abbildung 1 ( a) Der Algorithmusablauf von C-MCR wird vorgestellt (am Beispiel der Verwendung von Text zur Verbindung von CLIP und CLAP).Die Textdaten (überlappende Modalitäten) werden von den Textkodierern von CLIP bzw. CLAP in Textmerkmale kodiert:,. Gleichzeitig wird eine große Menge ungepaarter Einzelmodaldaten in CLIP- bzw. CLAP-Räume codiert und bildet einen Bildspeicher und einen Audiospeicher. Die semantische Verbesserung von Funktionen bezieht sich auf die Verbesserung und Optimierung von Funktionen, der Reihe nach um seine Fähigkeit zum semantischen Ausdruck zu verbessern. Durch die entsprechende Anpassung der Funktionen kann die auszudrückende Bedeutung genauer wiedergegeben werden, wodurch die Wirkung des Sprachausdrucks verbessert wird. Die Technologie zur semantischen Verbesserung von Merkmalen hat einen wichtigen Anwendungswert im Bereich der Verarbeitung natürlicher Sprache. Sie kann Maschinen dabei helfen, Textinformationen zu verstehen und zu verarbeiten und die Fähigkeiten der Maschine beim semantischen Verständnis und der semantischen Generierung zu verbessern. Wir können mit der Verbesserung der semantischen Informationen beginnen Darstellung, um die Robustheit und Vollständigkeit räumlicher Verbindungen zu verbessern. In diesem Zusammenhang untersuchen wir zunächst die beiden Perspektiven semantische Konsistenz und semantische Vollständigkeit. Intermodale semantische Konsistenz. CLIP und CLAP haben eine zuverlässige ausgerichtete Bild-Text- und Text-Audio-Darstellung gelernt. Wir nutzen diese intrinsische Modalitätsausrichtung in CLIP und CLAP, um Bild- und Audiomerkmale zu generieren, die semantisch mit dem i-ten Text konsistent sind, was eine bessere Quantifizierung der Modalitätslücke im kontrastiven Darstellungsraum und eine direktere Mining-Korrelation zwischen nicht ermöglicht -überlappende Modalitäten: Semantische Integrität innerhalb der Modalität Unterschiedliche Darstellungsräume haben unterschiedliche Tendenzen für den semantischen Ausdruck von Daten, daher wird es in unterschiedlichen Räumen zwangsläufig zu semantischen Abweichungen kommen Verluste im Text. Diese semantische Tendenz wird bei der Verbindung von Repräsentationsräumen akkumuliert und verstärkt. Um die semantische Vollständigkeit jeder Darstellung zu verbessern, schlagen wir vor, den Darstellungen Gaußsches Rauschen mit dem Mittelwert Null hinzuzufügen und sie auf die Einheitshypersphäre zu renormieren: wie in Abbildung 1 gezeigt ( Wie in c ), im kontrastiven Darstellungsraum kann jede Darstellung als Darstellung eines Punktes auf der Einheitshypersphäre angesehen werden. Durch Hinzufügen von Gauß'schem Rauschen und Renormierung kann die Darstellung einen Kreis auf der Einheitskugel darstellen. Je der räumliche Abstand zwischen zwei Merkmalen geringer ist, ist ihre semantische Ähnlichkeit höher. Daher haben die Features innerhalb des Kreises eine ähnliche Semantik und der Kreis kann die Semantik vollständiger darstellen 2. Ausrichtung von Inter-MCR Nach der Charakterisierung der semantischen Verbesserung verwenden wir zwei Mapper und Remapping CLIP und CLAP-Darstellungen in einen neuen gemeinsamen Raum Der neue Raum erfordert die Sicherstellung, dass semantisch ähnliche Darstellungen aus verschiedenen Räumen nahe beieinander liegen. ( ( Um die beiden kontrastierenden Darstellungsräume umfassender zu verbinden, richten wir gleichzeitig ( 3 ment Neben der Verbindung zwischen Räumen gibt es auch ein Modalitätslückenphänomen innerhalb des Kontrastdarstellungsraums. Das heißt, im kontrastiven Repräsentationsraum sind die Repräsentationen unterschiedlicher Modalitäten zwar semantisch ausgerichtet, aber auf völlig unterschiedliche Unterräume verteilt. Dies bedeutet, dass die stabileren Verbindungen, die von ( Um dieses Problem zu lösen, schlagen wir vor, die verschiedenen modalen Darstellungen jedes kontrastiven Darstellungsraums neu auszurichten. Insbesondere entfernen wir die Negativbeispiel-Ausschlussstruktur in der Kontrastverlustfunktion, um eine Verlustfunktion zur Reduzierung der Modalitätslücke abzuleiten. Eine typische kontrastive Verlustfunktion kann wie folgt ausgedrückt werden: Nachdem wir den negativen Paarabstoßungsterm eliminiert haben, kann die endgültige Formel wie folgt vereinfacht werden: Experimentell verwenden wir Textverkettung Audio-Text-Raum (CLAP) und Text-Visual-Raum (CLIP), um audiovisuelle Darstellungen zu erhalten. Verwenden Sie Bilder, um den 3D-Punktwolken-Bildraum (ULIP) und den Bild-Text-Raum (CLIP) zu verketten, um 3D-Punktwolkentext zu erhalten Darstellung. Die Ergebnisse des Zero-Sample-Audiobildabrufs auf AVE und Flickr-SoundNet sind wie folgt: Die Zero-Sample-Ergebnisse der Schallquellenlokalisierung auf MUSIC-Solo und VGGSS lauten wie folgt: Die Zero-Sample-Ergebnisse der kontrafaktischen Audiobilderkennung auf Ex-VGGSS und Ex-FlickrNet lauten wie folgt : Die Zero-Shot-3D-Punktwolken-Klassifizierungsergebnisse auf ModelNet40 lauten wie folgt: 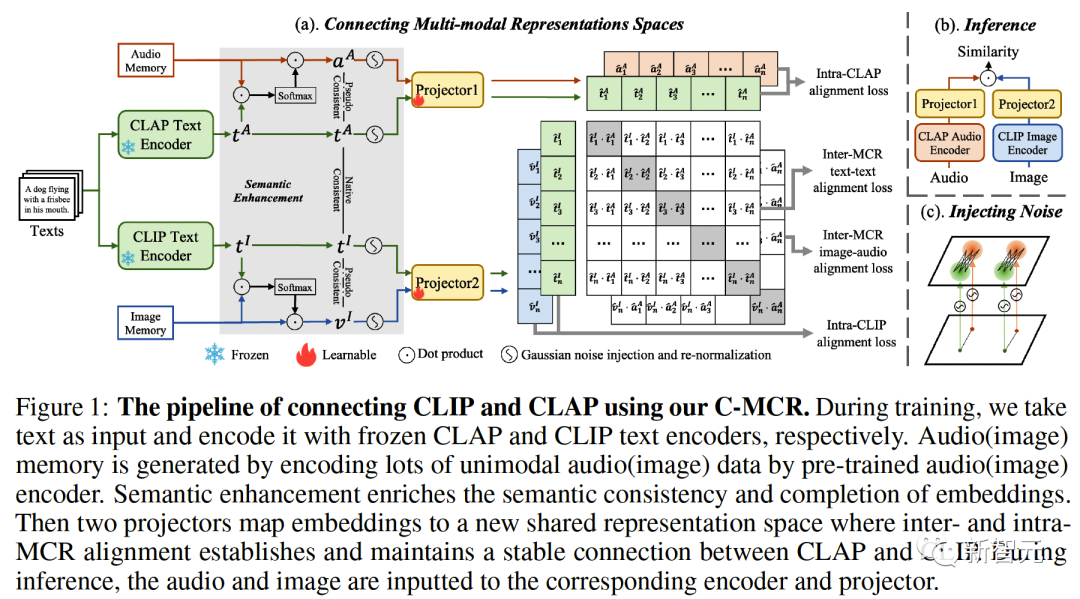
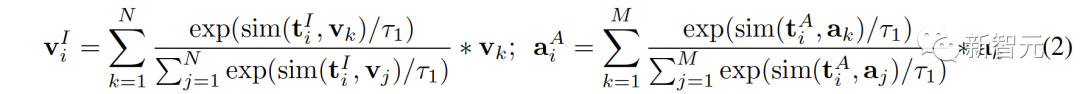
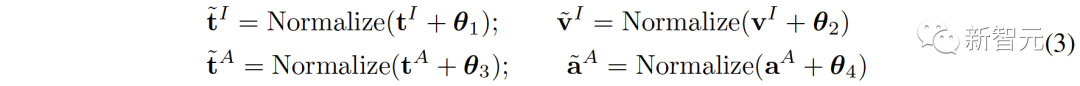
 ,
, ), die aus demselben Text stammen, sind von Natur aus semantisch konsistent und können als echte Tag-Paare angesehen werden, während (,) aus (
), die aus demselben Text stammen, sind von Natur aus semantisch konsistent und können als echte Tag-Paare angesehen werden, während (,) aus ( ,
, )
)  stammen ) können als Pseudo-Label-Paare betrachtet werden. Die Semantik zwischen
stammen ) können als Pseudo-Label-Paare betrachtet werden. Die Semantik zwischen  ,
, ) ist sehr konsistent, aber die daraus gelernten Verbindungen sind für audiovisuelle Medien indirekt. Obwohl die semantische Konsistenz des (
) ist sehr konsistent, aber die daraus gelernten Verbindungen sind für audiovisuelle Medien indirekt. Obwohl die semantische Konsistenz des ( ,
, )-Paares weniger zuverlässig ist, ist sie für die audiovisuelle Darstellung direkter von Vorteil.
)-Paares weniger zuverlässig ist, ist sie für die audiovisuelle Darstellung direkter von Vorteil.  ,
, ) und (
) und ( ,
, ) aus:
) aus: 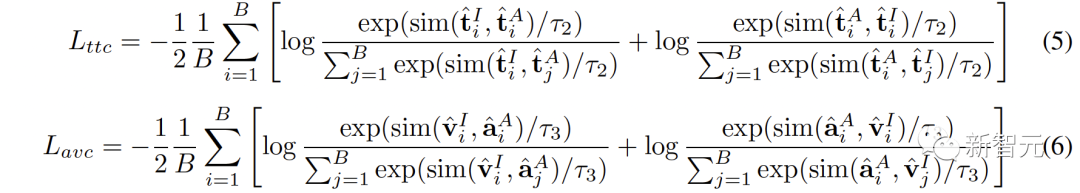 ,) gelernt wurden, möglicherweise nicht gut von audiovisuellen vererbt werden.
,) gelernt wurden, möglicherweise nicht gut von audiovisuellen vererbt werden. 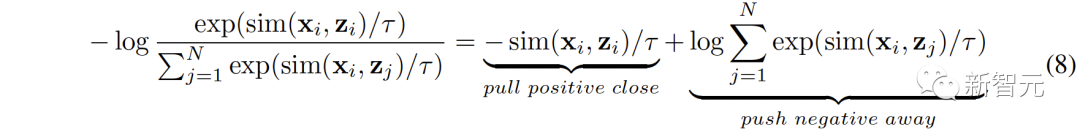
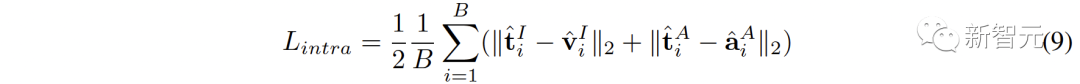
Experiment
Das obige ist der detaillierte Inhalt vonSie können „ohne übereinstimmende Daten' lernen! Die Universität Zhejiang und andere haben vorgeschlagen, die multimodale Kontrastdarstellung C-MCR zu verbinden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 window.prompt
window.prompt
 Was tun, wenn die Win8wifi-Verbindung nicht verfügbar ist?
Was tun, wenn die Win8wifi-Verbindung nicht verfügbar ist?
 So stellen Sie eine MySQL-Datenbank wieder her
So stellen Sie eine MySQL-Datenbank wieder her
 So beheben Sie das Problem „Zugriff verweigert'.
So beheben Sie das Problem „Zugriff verweigert'.
 So extrahieren Sie Audio aus Video in Java
So extrahieren Sie Audio aus Video in Java
 Lösung für den schwarzen Bildschirm beim Start von Ubuntu
Lösung für den schwarzen Bildschirm beim Start von Ubuntu
 Welche Karte ist eine TF-Karte?
Welche Karte ist eine TF-Karte?
 So ändern Sie phpmyadmin auf Chinesisch
So ändern Sie phpmyadmin auf Chinesisch








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



