


Kürzlich hat GPT-4, das den Mathematiker Terence Tao inspiriert hat, damit begonnen, Robotern beizubringen, wie man in Chats Stifte dreht

Das Projekt heißt Agent Eureka und wurde von NVIDIA, der University of Pennsylvania und dem California Institute of Technology entwickelt Technology und der University of Texas at Austin Gemeinsam von den Zweigschulen entwickelt. Ihre Forschung kombiniert die Leistungsfähigkeit der GPT-4-Struktur mit den Vorteilen des verstärkenden Lernens und ermöglicht es Eureka, exquisite Belohnungsfunktionen zu entwerfen.
Die Programmierfunktionen von GPT-4 verleihen Eureka leistungsstarke Fähigkeiten beim Design von Belohnungsfunktionen. Das bedeutet, dass die Belohnungssysteme von Eureka bei den meisten Aufgaben sogar besser sind als die der menschlichen Experten. Dies ermöglicht es ihm, einige Aufgaben zu erledigen, die für Menschen schwierig zu erledigen sind, darunter das Drehen von Stiften, das Öffnen von Schubladen, das Anrichten von Walnüssen und noch komplexere Aufgaben, wie das Werfen und Fangen eines Balls, das Bedienen einer Schere usw.
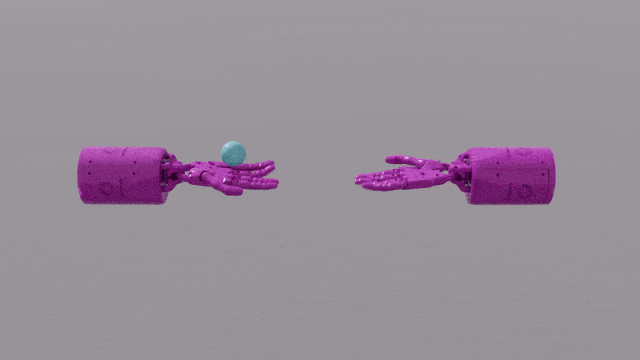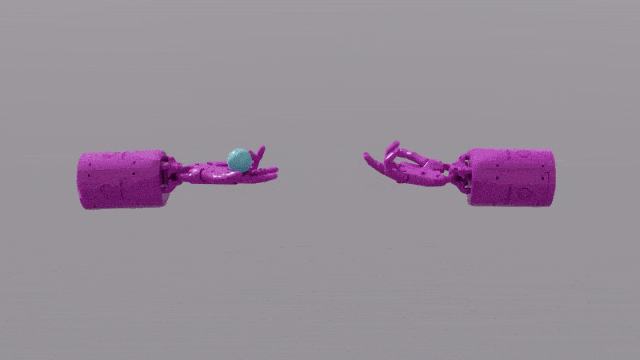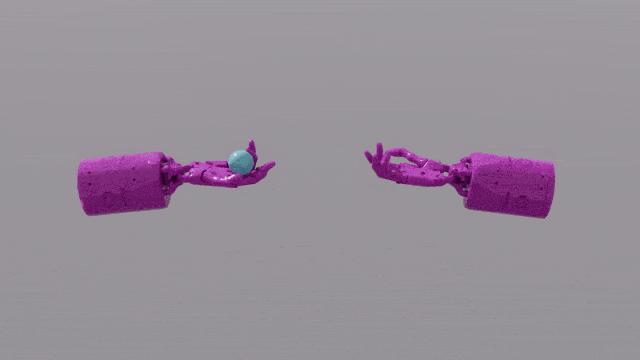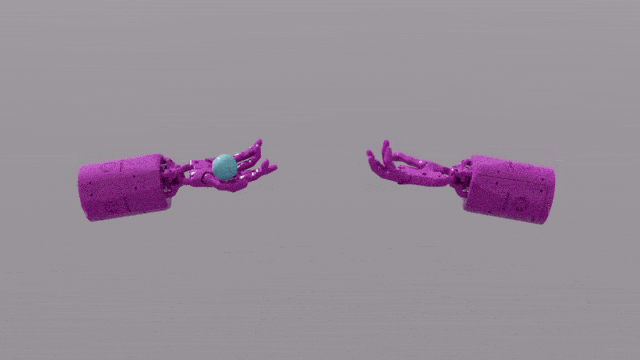 Bilder
Bilder
 Bilder
Bilder
Obwohl diese derzeit in einer simulierten Umgebung erstellt werden, ist dies bereits sehr leistungsstark.
Das Projekt ist Open Source und die Projektadresse und die Papieradresse wurden am Ende des Artikels platziert.
Eine kurze Zusammenfassung der Kernpunkte des Papiers.
In dem Artikel wird untersucht, wie große Sprachmodelle (LLM) verwendet werden können, um Belohnungsfunktionen beim maschinellen Lernen zu entwerfen und zu optimieren. Dies ist ein wichtiges Thema, da der Entwurf einer guten Belohnungsfunktion die Leistung von Modellen für maschinelles Lernen erheblich verbessern kann, der Entwurf einer solchen Funktion jedoch sehr schwierig ist.
Forscher haben einen neuen Algorithmus namens EUREKA vorgeschlagen. EUREKA übernimmt LLM, um Belohnungsfunktionen zu generieren und zu verbessern. Beim Testen erreichte EUREKA in 29 verschiedenen Lernumgebungen zur Verstärkung eine Leistung auf menschlichem Niveau und übertraf bei 83 % der Aufgaben die von menschlichen Experten entwickelten Belohnungsfunktionen B. die Simulation der Bedienung der „Schattenhand“, um einen Stift schnell zu drehen
Darüber hinaus bietet EUREKA eine brandneue Methode, die eine effektivere Belohnungsfunktion generieren kann, die auf der Grundlage menschlicher Rückmeldungen besser den menschlichen Erwartungen entspricht
EUREKA funktioniert in drei Hauptschritten:
Umgebung als Kontext: EUREKA verwendet den Quellcode der Umgebung als Kontext, um ausführbare Belohnungsfunktionen zu generieren
2. Evolutionäre Suche: EUREKA schlägt kontinuierlich durch evolutionäre Suche vor und verbessert die Belohnungsfunktion
3 : EUREKA generiert textliche Zusammenfassungen der Belohnungsqualität auf Basis von Statistiken aus der Politikschulung und verbessert so automatisch und gezielt die Belohnungsfunktion. 3. Belohnungsreflexion: EUREKA generiert textliche Zusammenfassungen der Belohnungsqualität auf der Grundlage von Statistiken aus Richtlinienschulungen, um Belohnungsfunktionen automatisch und gezielt zu verbessern Es wird eine Methode zur automatischen Generierung und Verbesserung von Belohnungsfunktionen bereitgestellt, und die Leistung dieser Methode übertrifft in vielen Fällen die Leistung menschlicher Experten.
Projektadresse:
//m.sbmmt.com/link/e6b738eca0e6792ba8a9cbcba6c1881dPapierlink://m.sbmmt.com/link/ce128c3e8f0c0ae4b3e843dc7cbab0f7
Das obige ist der detaillierte Inhalt vonGPT4 bringt einem Roboter bei, einen Stift zu drehen, was als seidenweiche Glätte bezeichnet wird!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Algorithmus zum Ersetzen von Seiten
Algorithmus zum Ersetzen von Seiten
 WLAN Passwort
WLAN Passwort
 So löschen Sie eine Datei unter Linux
So löschen Sie eine Datei unter Linux
 So summieren Sie dreidimensionale Arrays in PHP
So summieren Sie dreidimensionale Arrays in PHP
 Python führt zwei Listen zusammen
Python führt zwei Listen zusammen
 Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
Gründe, warum der Touchscreen eines Mobiltelefons ausfällt
 So lösen Sie das Problem, dass der Scanf-Rückgabewert ignoriert wird
So lösen Sie das Problem, dass der Scanf-Rückgabewert ignoriert wird
 So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie
So laden Sie die heutigen Schlagzeilenvideos herunter und speichern sie








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



